행개수 구하기(COUNT)
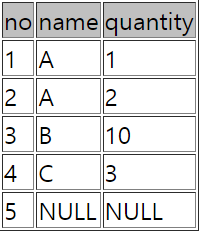
select count(*) from sample51; # ->5출력
select count(*) from sample51 where name = 'A'
#name이 A인것 -> 2 출력
select count(*),count(no),count(name) from sample51;
마지막 SQL문의 결과
- (*)애스터리스크는 null값이 있어도 모든 열의 행수를 count한다
- 개별적으로 count할때는 null은 count하지 않고 4가 출력된다
중복제거(DISTINCT)
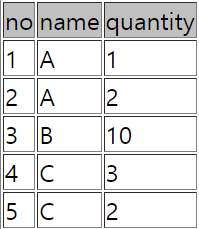
select distinct quantity from sample51;# -> 1,2,10,3
select distinct name from sample51;# -> 'A','B','C'중복을 없애고 보여준다
(DELETE)하는것이 아님.
select count(all name),count(distinct name) from sample51;
#중복을 없애고 카운트도 할수 있다
#각각 5와 3 출력합계(SUM)
select sum(name) from sample51;
select sum(quantity) from sample51;
#문자열 합계는 0이 나온다
#sum함수로 모든값 더하기, null은 무시한다평균(AVG)
select avg(quantity), sum(quantity)/count(quantity) from sample51;
#AVG함수와 SUM/COUNT의 값은 똑같다- 마찬가지로 NULL값은 무시하고 연산되지만
COALESCE를 이용해서 NULL값을 0으로 치환해서 연산하면 COUNT의 갯수가 늘어난다
-> 연산결과가 달라질수 있으므로 판단 잘하자
최대/최소 (MIN/MAX)
select MIN(quantity),MAX(quantity),
MIN(name),MAX(name) from sample51;- 문자형도 아스키코드로 연산하여 최대/최소값을 산출한다
- 날짜형 데이터도 연산해준다
- 마찬가지로 null값은 무시하지만 0으로 치환할경우 당연히 결과도 바뀐다
그룹화(GROUP BY)
select name, count(name), sum(quantity)
from sample51
group by name;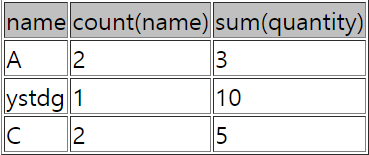
name으로 그루핑을 하였고
A는 2개가 그룹화 C도 2개 데이터가 그룹화되었다
마찬가지로 그룹화된 데이터끼리 합계도 구해보았다
select sum(a) as foo from table_name where foo = 1;
# -> 에러 내부처리 순서!해결방법 : Alias(별칭)을 인지할 수 있는건 GROUP BY 이후 절부터 별칭을 인지
HAVING
GROUP BY로 그룹화를 했을경우
조건지정은 HAVING구를 사용해야한다
그렇지 않을경우는 WHERE
그 이유는 내부처리 순서와 관계있기 때문
내부처리 순서
- WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY
- WHERE은 GROUP BY보다 먼저 처리 되므로 전혀 다른값이 나올수있다
- 별칭(AS)은 SELECT구 이고 그룹화된 후에 별칭을 지정해주면 Oracle같은 DBMS의 경우에는 처리할수 없다
(MYSQL은 가능하다고 함)
select name, count(name), sum(quantity)
from sample51
group by name having count(name) = 1;
#having으로 name행이 한개인것만 조전지정 출력-> 정리하자면 GROUP BY에서 지정한 열 이외에 다른 열은 집계함수를 사용하지 않으면 SELECT구를 사용할수없다.
SELECT MIN(no),name,SUM(quantity)
FROM sample51 GROUP BY name
ORDER BY SUM(quantity) DESC;CHAT GPT한테 물어본 MYSQL 내부처리 순서
1. FROM : FROM 절에 지정된 테이블이나 뷰에서 데이터를 가져옵니다.
-
JOIN : JOIN 절에 지정된 조건에 따라 테이블을 조인합니다.
-
WHERE : WHERE 절에 지정된 조건에 부합하는 데이터를 찾습니다.
-
GROUP BY : GROUP BY 절에 지정된 열(컬럼)로 데이터를 그룹화합니다.
-
HAVING : GROUP BY 절과 함께 사용되며, GROUP BY 절에 지정된 그룹 중에서 HAVING 절에 지정된 조건에 부합하는 그룹을 찾습니다.
-
SELECT : SELECT 절에 지정된 열(컬럼)을 선택하고, 계산 및 변환을 수행합니다.
-
DISTINCT : 중복된 데이터를 제거합니다.
-
ORDER BY : ORDER BY 절에 지정된 열(컬럼)로 데이터를 정렬합니다.
-
LIMIT/OFFSET : 결과 집합에서 지정된 개수만큼 데이터를 선택합니다.
MySQL의 경우, JOIN이 FROM 이후에 처리되기 때문에, JOIN 조건에 따라 데이터를 필터링하는 것이 가능합니다. 또한, DISTINCT 절이 SELECT 절보다 먼저 실행되는 것에 주의해야 합니다. 이를 고려하지 않을 경우, DISTINCT 절에서 원하지 않는 결과가 나올 수 있습니다. 이처럼, 데이터베이스 시스템마다 내부 처리 순서에 대한 구현 방법이 조금씩 다를 수 있으므로, 적절한 쿼리 작성을 위해서는 각 데이터베이스 시스템의 동작 방식에 대한 이해가 필요합니다.
