인터넷 네트워크
IP(Internet Protocol)
'IP 인터넷 프로토콜 역할'
* 지정한 IP 주소(IP Adress)에 데이터 전달
* 패킷(Packet)이라는 통신 단위로 데이터 전달
'IP 프로토콜의 한계'
* 비연결성
-> 패킷을 받을 대상이 없거나 서비스 불능 상태여도 패킷 전송
* 비신뢰성
-> 중간에 패킷이 사라지면?
-> 패킷이 순서대로 안오면?
* 프로그램 구분
-> 같은 IP를 사용하는 서버에서 통신하는 애플리케이션이 둘 이상이면?TCP,UDP
'인터넷 프로토콜 스택의 4계층'
애플리케이션 계층 - HTTP, FTP
전송 계층 - TCP<UDP
인터넷 계층 - IP
네트워크 인터페이스 계층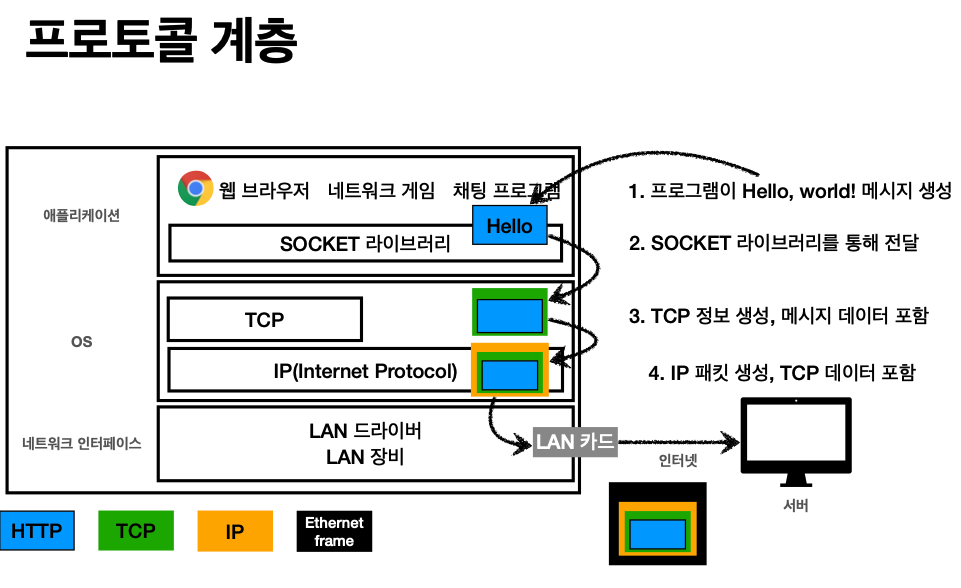
'TCP 특징'(전송 제어 프로토콜)(Transmission Control Protocol)
* 연결 지향 - TCP 3 way handshake(가상 연결)
* 데이터 전달 보증
* 순서 보장
* 신뢰할 수 있는 프로토콜
* 현재는 대부분 TCP 사용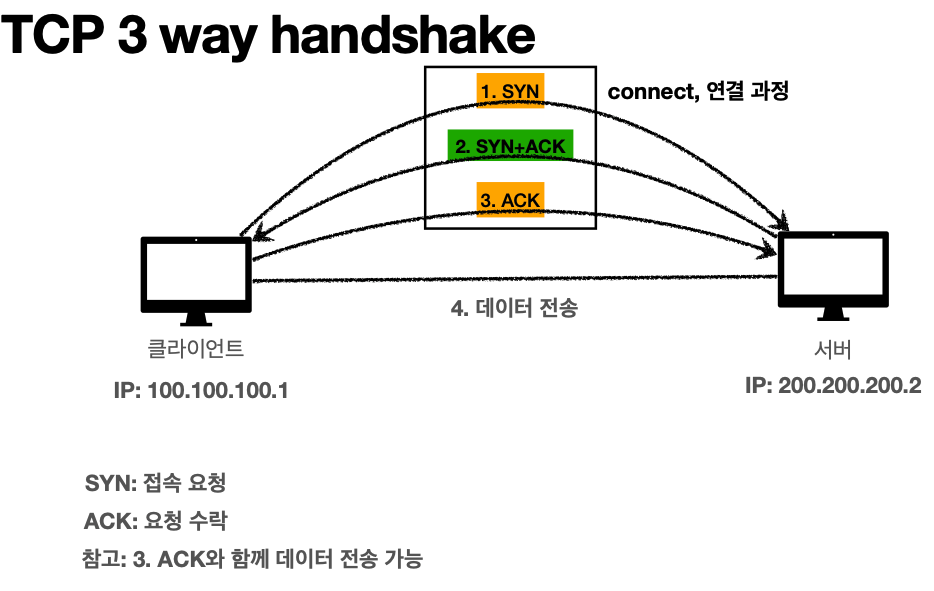
'UDP 특징'(사용자 데이터그램 프로토콜)(User Datagram Protocol)
* 하얀 도화지에 비유(기능이 거의 없음)
* 연결 지향 - TCP 3 way handshake X
* 데이터 전달 보증 X
* 순서 보장 X
* 데이터 전달 및 순서가 보장되지 않지만, 단순하고 빠름
'정리'
* IP와 거의 같다 + PORT + 체크섬 정도만 추가
* 애플리케이션에서 추가 작접 필요PORT
'한번에 둘 이상 연결해야 하면?'
패킷 정보 (아파트와 동 호수로 생각하자)
출발지 IP, PORT
목적지 IP, PORT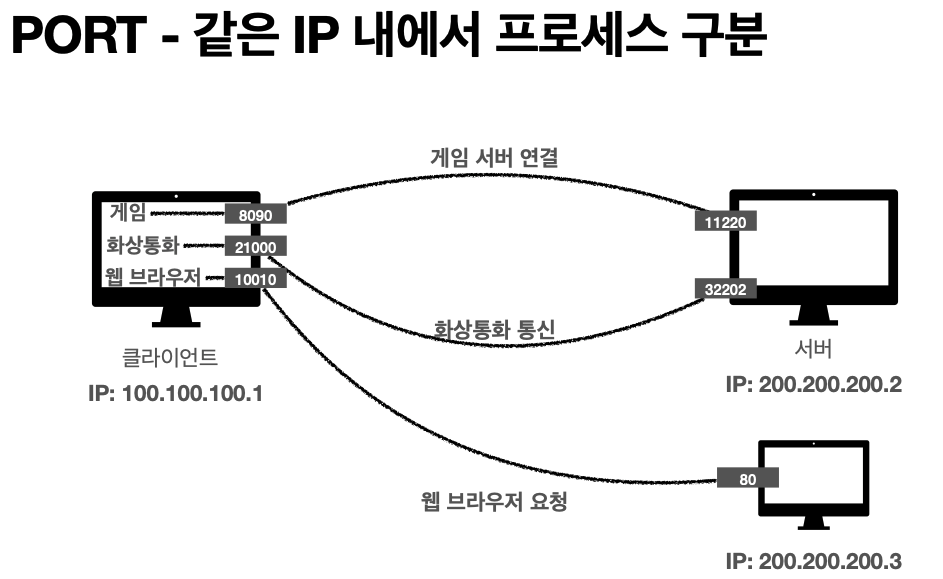
PORT 번호
* 0 ~ 65535 할당 가능
* 0 ~ 1023 : 잘 알려진 포트, 사용하지 않는 것이 좋음
* FTP - 20, 21
* TELNET - 23
* HTTP - 80
* HTTPS - 443DNS 도메인 네임 시스템(Domain Name System)
'IP는 기억하기 어렵다'
'IP는 변경될 수 있다.'
'DNS' (도메인 네임 시스템)
* 전화번호부
* 도메인 명을 IP 주소로 변환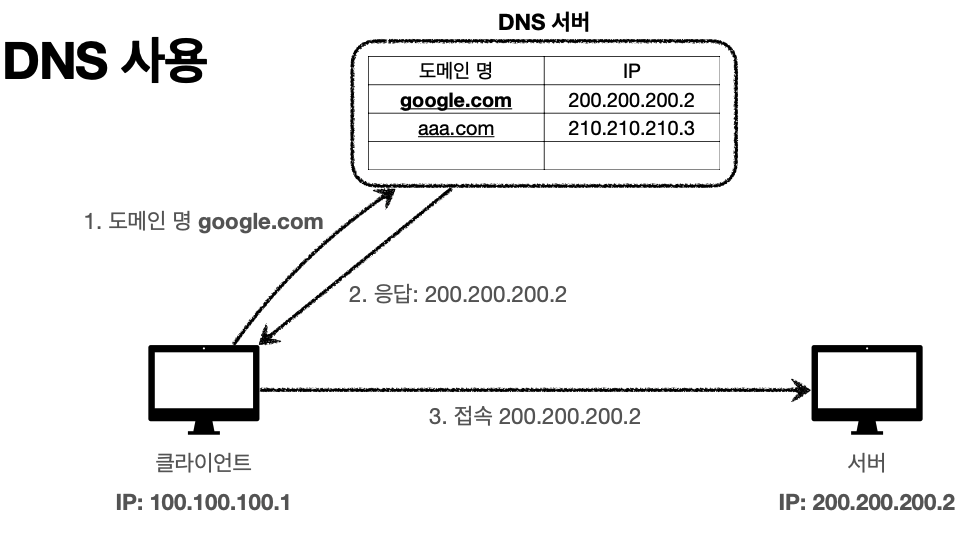
URI와 웹 브라우저 요청 흐름
URI(Uniform Resource Identifier)
'URI? URL? URN?'
-> URI는 로케이터(Locator), 이름(name)또는 둘다 추가로 분류 될 수 있다.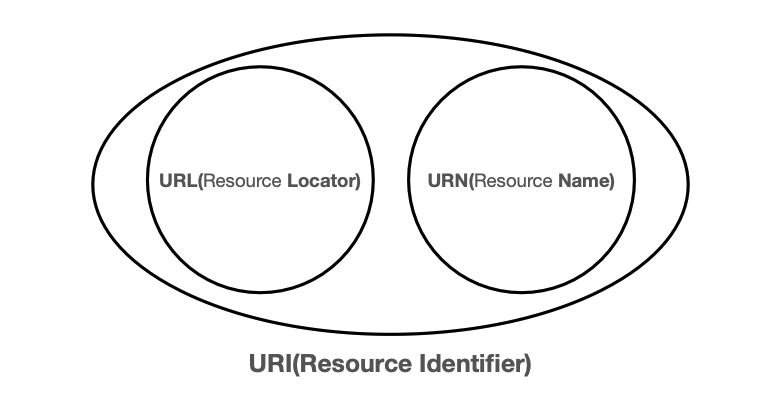
'URI 단어 뜻'
* Uniform : 리소스 식별하는 통일된 방식
* Resource : 자원, URI로식별할 수 있는 모든 것 (제한 없음)
* Identifier: 다른 항목과 구분하는데 필요한 정보
* URL: Uniform Resource Locator
* URN: Uniform Resource Name
'URL, URN 단어 뜻'
* URL - Locator : 리소그가 있는 위치를 지정
* URN - NAME : 리소스에 이름을 부여
* 위치는 변할 수 있지만, 이름은 변하지 않는다
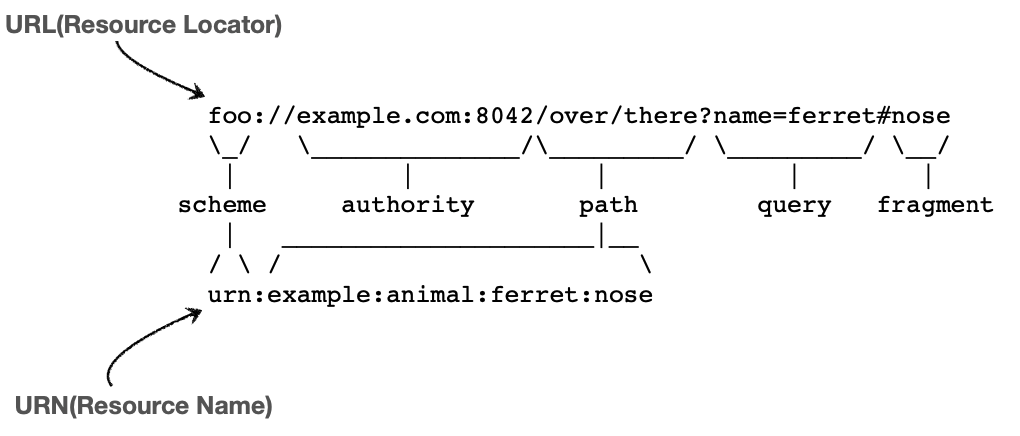
* urn:isbn:8960777331 (어떤 책의 isbn URN)
* URN 이름만으로 실제 리소스를 찾을 수 있는 방법이 보편화 되지 않음
* '앞으로 URI를 URL과 같은 의미로 이야기하겠음''URL 전체 문법'
* scheme://[userinfo@]host[:port][/path][?query][#fragment]
* https://www.google.com:443/search?q=hello&hl=ko
* 프로토콜(https)
* 호스트명(www.google.com)
* 포트 번호(443)
* 패스(/search)
* 쿼리 파라미터(q=hello&hl=ko)
'scheme'
* 주로 프로토콜 사용
* 프로토콜 : 어떤 방식으로 자원에 접근할 것인가 하는 약속 규칙
예) http, https, ftp 등등
* http는 80 포트, https는 443 포트를 주로 사용, 포트는 생략 가능
* https는 http에 보안 추가 (HTTP Secure)
'userinfo'
* URL에 사용자정보를 포함해서 인증
* 거의 사용하지 않음
'host'
* scheme://[userinfo@]'host'[:port][/path][?query][#fragment]
* https://'www.google.com':443/search?q=hello&hl=ko
* 호스트명
* 도메인명 또는 IP 주소를 직접 사용가능
'PORT'
* scheme://[userinfo@]host'[:port]'[/path][?query][#fragment]
* https://www.google.com:'443'/search?q=hello&hl=ko
* 포트(PROT)
* 접속 포트
* 일반적으로 생략, 생략시 http는 80, https는 443
'path'
* scheme://[userinfo@]host[:port]'[/path]'[?query][#fragment]
* https://www.google.com:443/'search'?q=hello&hl=ko
* 리소스 경로(path), 계층적 구초
* 예)
- /home/file1.jpg
- /members
- /members/100, items/iphone12
'query'
* scheme://[userinfo@]host[:port][/path]'[?query]'[#fragment]
* https://www.google.com:443/search'?q=hello&hl=ko'
* key=value 형태
* ?로 시작, &로 추가 가능 ?keyA=valueA&keyB=valueB
* query parameter, query string 등으로 불림, 웹서버에 제공하는 파라미터 문자형태
'fragment'
scheme://[userinfo@]host[:port][/path][?query]'[#fragment]'
https://docs.spring.io/spring-boot/docs/current/reference/html/
'getting-started.html#getting-started-introducing-spring-boot'
* fragment
* html 내부 북마크 등에 사용
* 서버에 전송하는 정보 아님웹 브라우저 요청 흐름




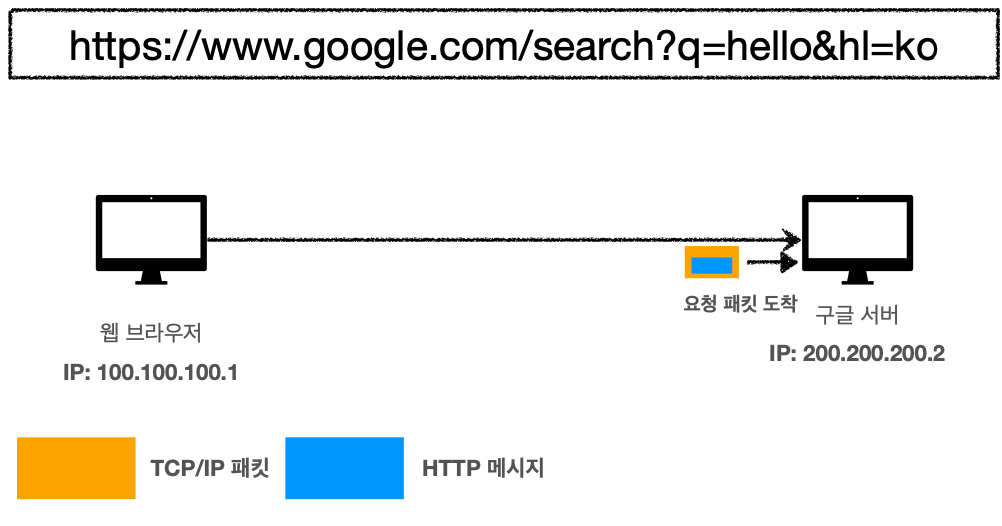




HTTP 기본
모든 것이 HTTP(HyperText Transfer Protocol)
'HTTP 메시지에 모든 것을 전송'
* HTML, TEXT
* IMAGE 음성, 영상, 파일
* JSON, XML(API)
* 거의 모든 형태의 데이터 전송 가능
* 서버간에 데이터를 주고 받을 때도 대부분 HTTP 사용
* '지금은 HTTP 시대'
'HTTP 역사'
* HTTP/0.9 1991년: GET 메서드만 지원, HTTP 헤더X
* HTTP/1.0 1996년: 메서드, 헤더 추가
* 'HTTP/1.1 1997년: 가장 많이 사용, 우리에게 가장 중요한 버전'
* RFC2068 (1997) -> RFC2616 (1999) -> RFC7230~7235 (2014)
* HTTP/2 2015년: 성능 개선
* HTTP/3 진행중: TCP 대신에 UDP 사용, 성능 개선
'기반 프로토콜'
* TCP : HTTP/1.1, HTTP/2
* UDP : HTTP/3
* 현재 HTTP/1.1 주로 사용
* HTTP/2, HTTP/3 도 점점 증가
'HTTP 특징'
* 클라이언트 서버 구조
* 무상태 프로토콜(스테이스리스), 비연결성
* HTTP 메시지
* 단순함, 확장 가능클라이언트 서버 구조
* Request Response 구조
* 클라이언트는 서버에 요청을 보내고, 응답을 댜기
* 서버에 요청에 대한 결과를 만들어서 응답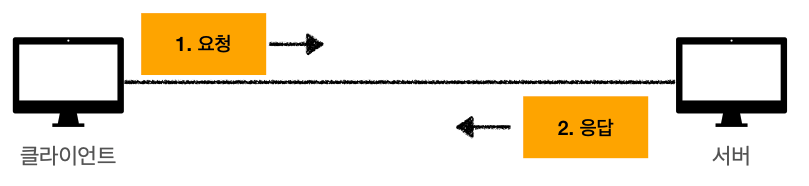
무상태 프로토콜 스테이스리스(Stateless)
* 서버가 클라이언트의 상태를 보존 X
* 장점 : 서버 확장성 높음(스케일 아웃)
* 단점 : 클라이언트가 추가 데이터 전송'Stateful, Stateless 차이'
'상태 유지 - Stateful'
고객: 이 노트북 얼마인가요?
점원: 100만원 입니다.
고객: 2개 구매하겠습니다.
점원: 200만원 입니다. 신용카드, 현금중에 어떤 걸로 구매 하시겠어요?
고객: 신용카드로 구매하겠습니다.
점원: 200만원 결제 완료되었습니다.
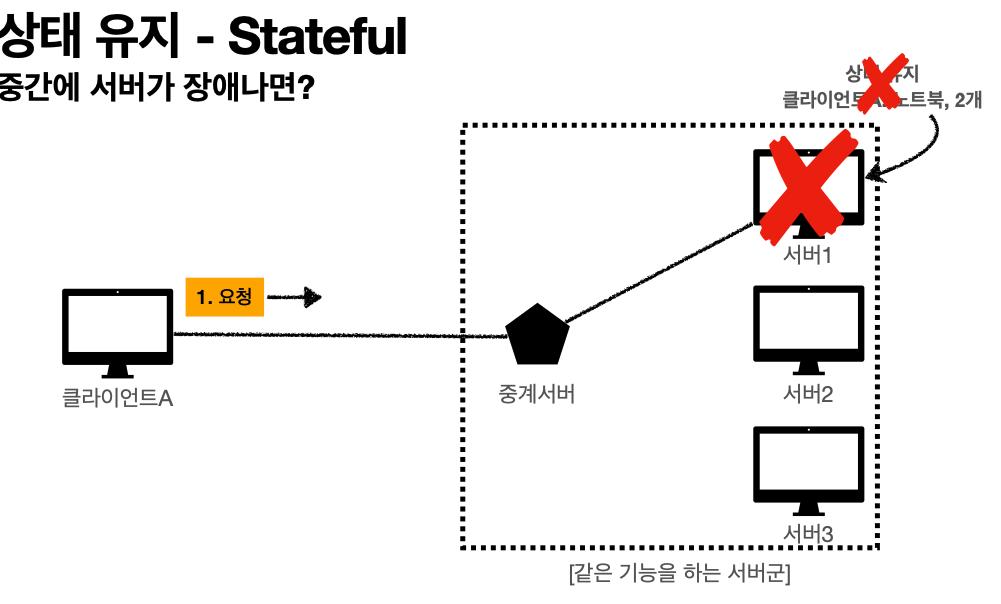
'상태 유지 - Stateful, 점원이 중간에 바뀌면?'
고객: 이 노트북 얼마인가요?
점원A: 100만원 입니다.
고객: 2개 구매하겠습니다.
점원B: ? 무엇을 2개 구매하시겠어요?
고객: 신용카드로 구매하겠습니다.
점원C: ? 무슨 제품을 몇 개 신용카드로 구매하시겠어요?
'상태 유지 - Stateful, 정리'
고객: 이 노트북 얼마인가요?
점원: 100만원 입니다. (노트북 상태 유지)
고객: 2개 구매하겠습니다.
점원: 200만원 입니다. 신용카드, 현금중에 어떤 걸로 구매 하시겠어요?
(노트북, 2개 상태 유지)
고객: 신용카드로 구매하겠습니다.
점원: 200만원 결제 완료되었습니다. (노트북, 2개, 신용카드 상태 유지)'Stateful, Stateless 차이'
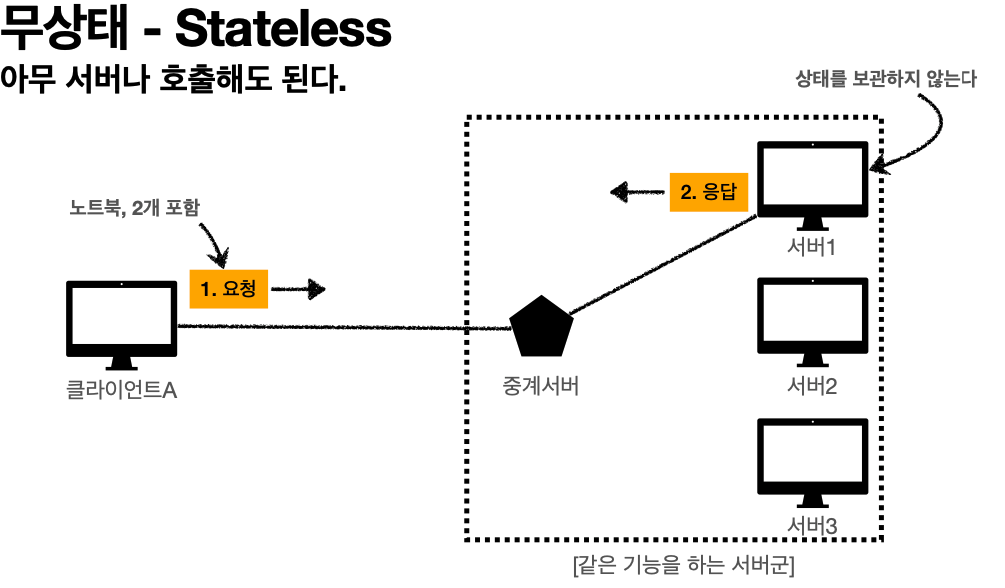
'무상태 - Stateless'
고객: 이 노트북 얼마인가요?
점원: 100만원 입니다.
고객: 노트북 2개 구매하겠습니다.
점원: 노트북 2개는 200만원 입니다. 신용카드, 현금중에 어떤 걸로 구매 하시겠어요?
고객: 노트북 2개를 신용카드로 구매하겠습니다.
점원: 200만원 결제 완료되었습니다.
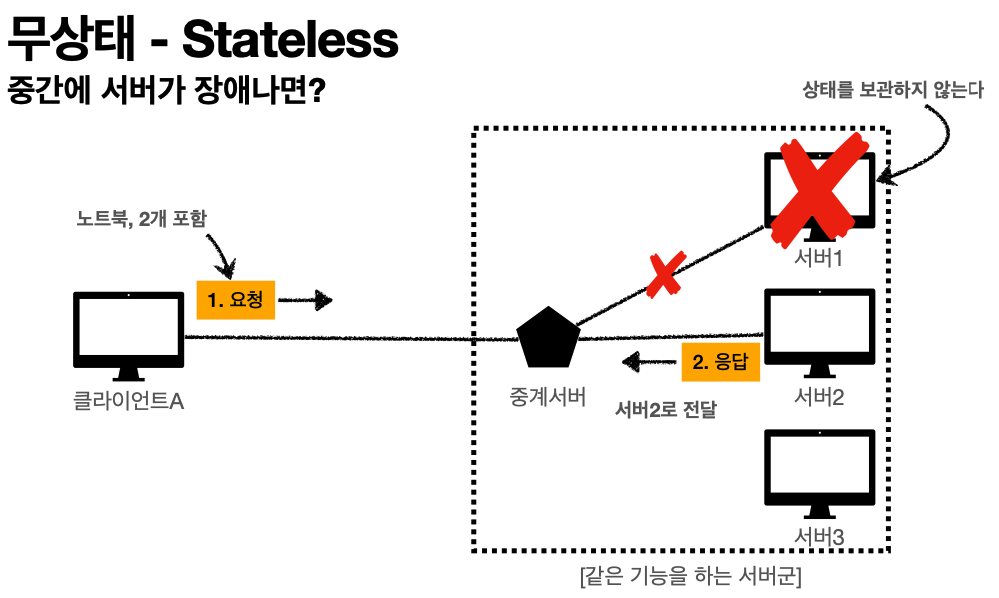
'무상태 - Stateless, 점원이 중간에 바뀌면?'
고객: 이 노트북 얼마인가요?
점원A: 100만원 입니다.
고객: 노트북 2개 구매하겠습니다.
점원B: 노트북 2개는 200만원 입니다. 신용카드, 현금중에 어떤 걸로 구매 하시겠어요?
고객: 노트북 2개를 신용카드로 구매하겠습니다.
점원C: 200만원 결제 완료되었습니다.
'정리'
* '상태 유지' : 중간에 다른 점원으로 바뀌면 안된다.(중간에 다른 점원으로 바뀔때 상태 정보를
다른 점원에게 미리 알려줘야 한다.)
* '무상태' : 중간에 다른 점원으로 바뀌어도 된다.
* 갑자기 고객이 증가해도 점원을 대거 투입할 수 있다.
* 갑자기 클라이언트 요청이 증가해도 서버를 대거 투입할 수 있다.
* 무상태는 응답 서버를 쉽게 바꿀 수 있다. -> '무한한 서버 증설 가능'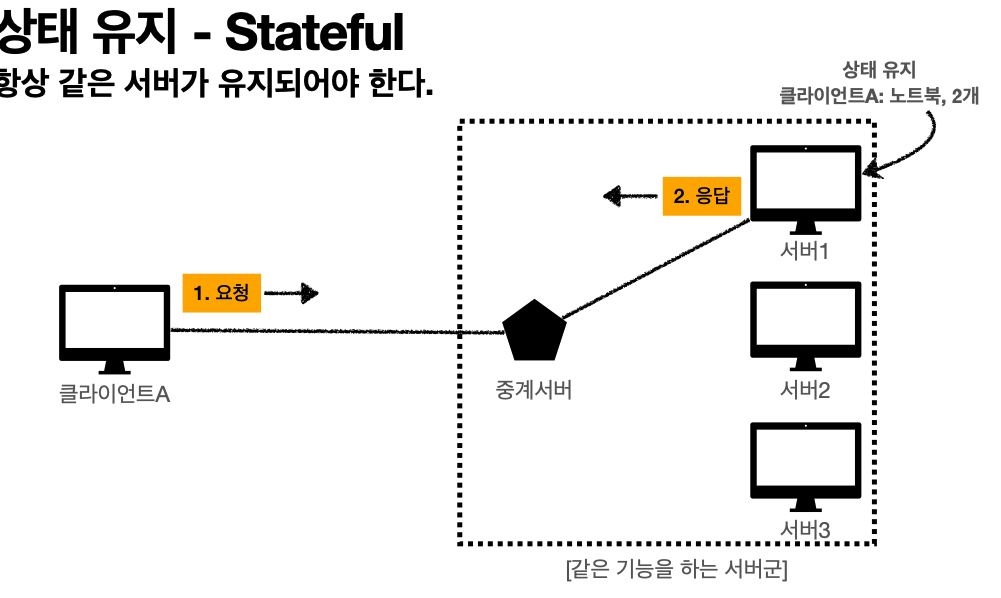
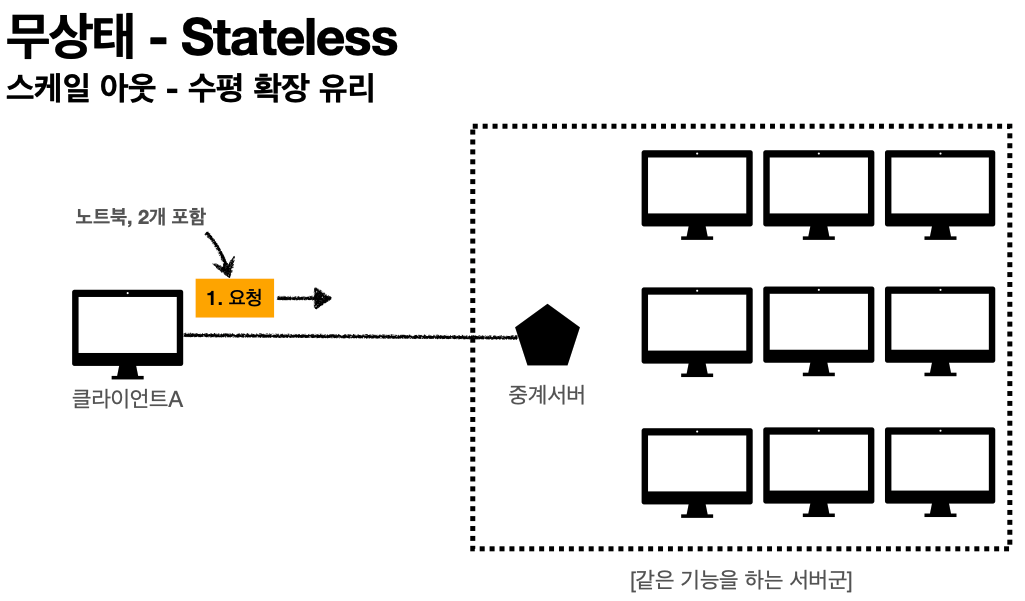
'Stateless 실무 한계'
* 모든 것을 무상태로 설계 할 수 있는 경우도 있고 없는 경우도 있다.
* 무상태
예) 로그인이 필요 없는 단순한 서비스 소개 화면
* 상태 유지
예) 로그인
* 로그인한 사용자의 경우 로그인 했다는 상태를 서버에 유지
* 일반적으로 브라우저 쿠키와 서버 세션등을 사용해서 상태 유지
* 상태 유지는 최소한만 사용비 연결성(connectionless)
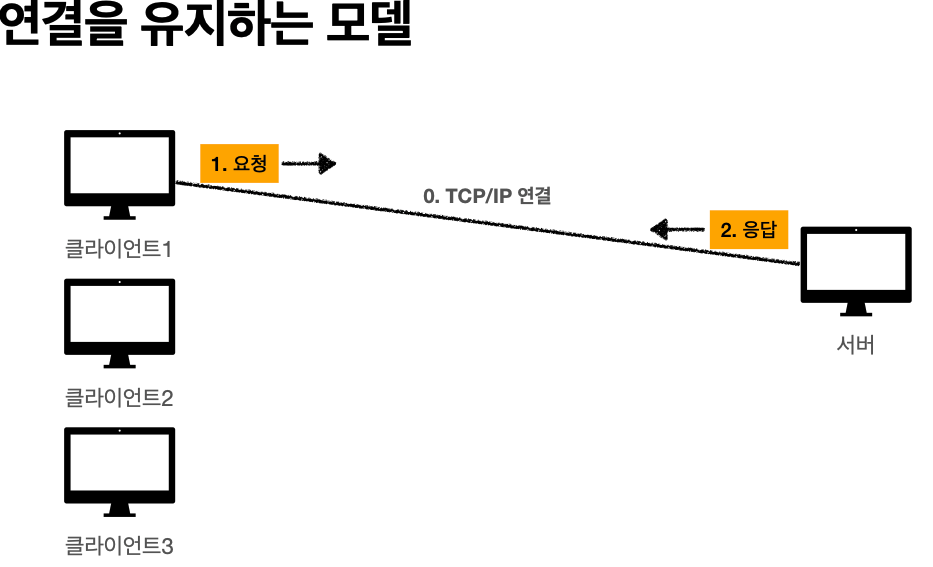
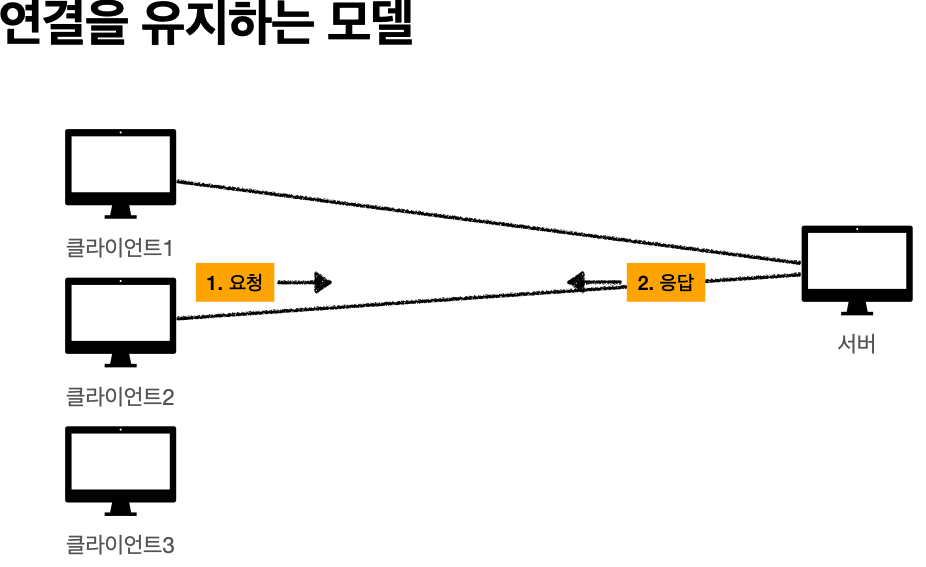
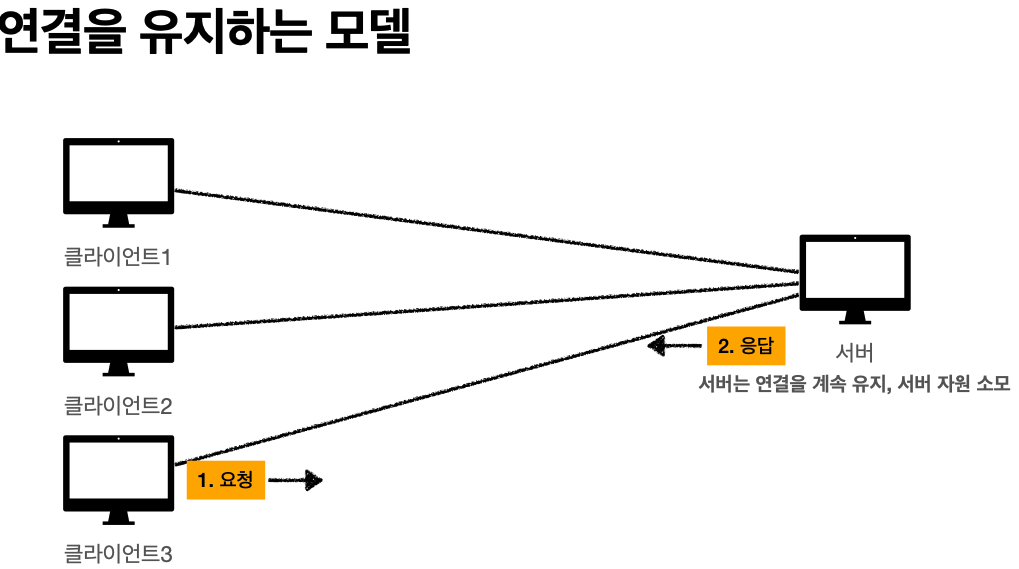
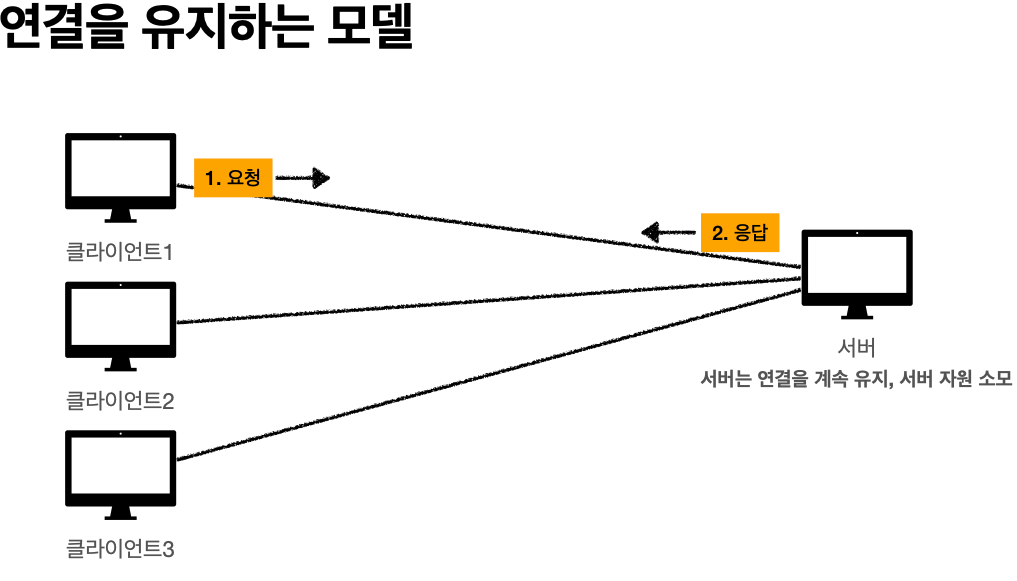
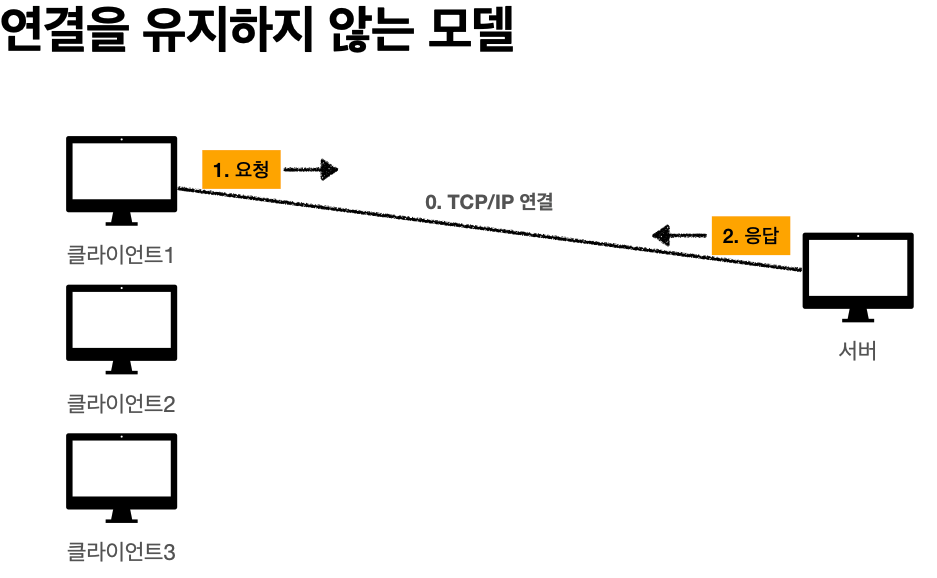
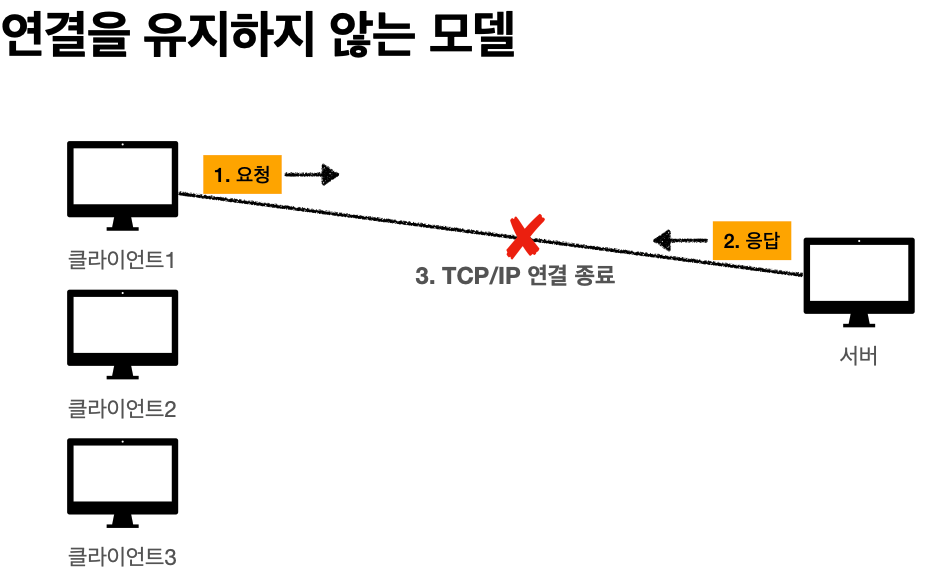
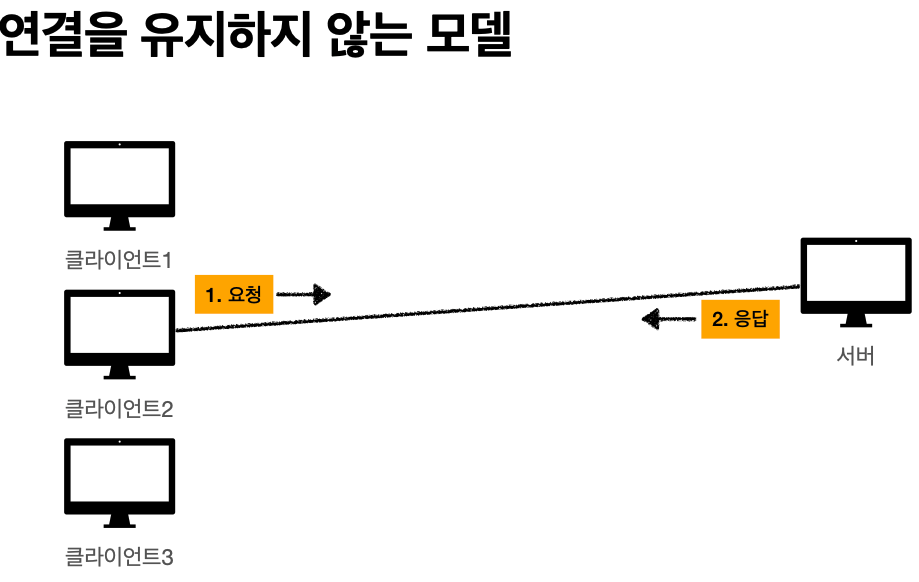
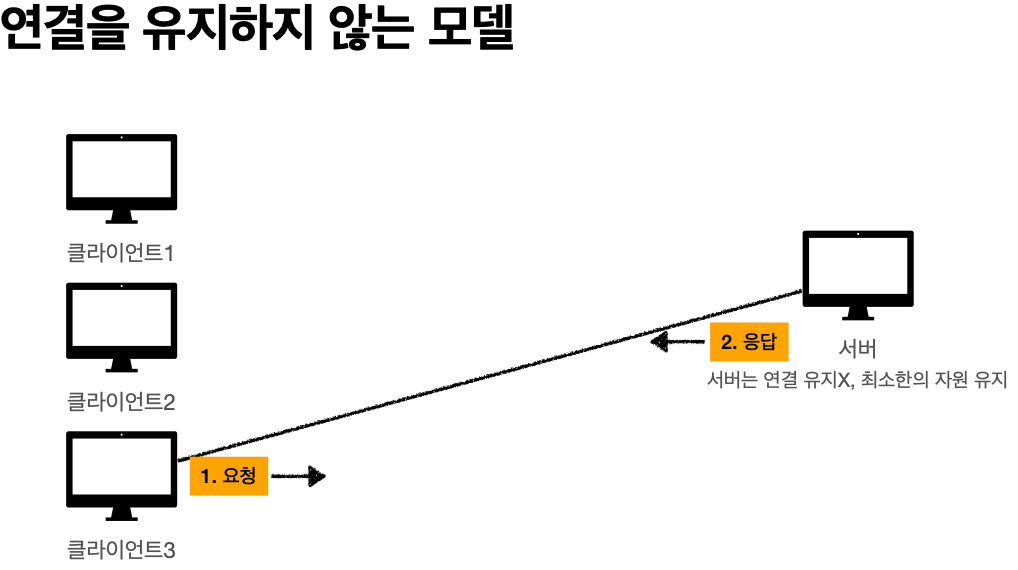
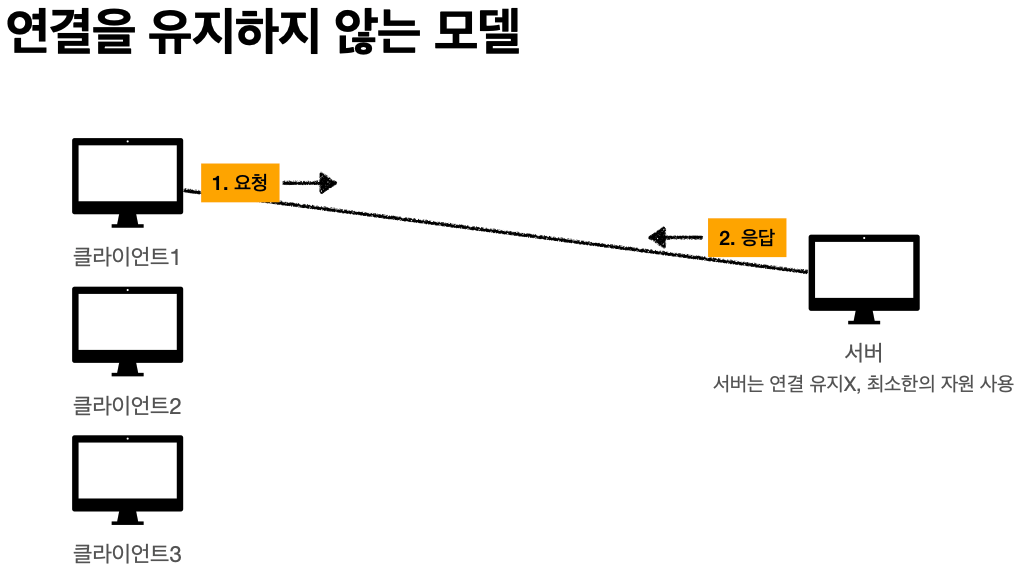
'비 연결성'
* HTTP는 기본이 연결을 유지하지 않는 모델
* 일반적으로 초 단위의 이하의 빠른 속도로 응답
* 1시간 동안 수천명이 서비스를 사용해도 실제 서버에서 동시에 처리하는 요청은 수십개 이하로
매우 작음 -> 예) 브라우저에서 계속 연속해서 검색 버튼을 누르지는 않는다
* 서버 자원을 매우 효율적으로 사용할 수 있음.
'비 연결성 한계와 극복'
* TCP/IP 연결을 새로 맺어야 함 - 3 way handshake 시간 추가
* 웹 브라우저로 사이트를 요청하면 HTML 뿐만 아니라 자바스크립트, css, 추가 이미지 등등
수 많은 자원이 함께 다운로드
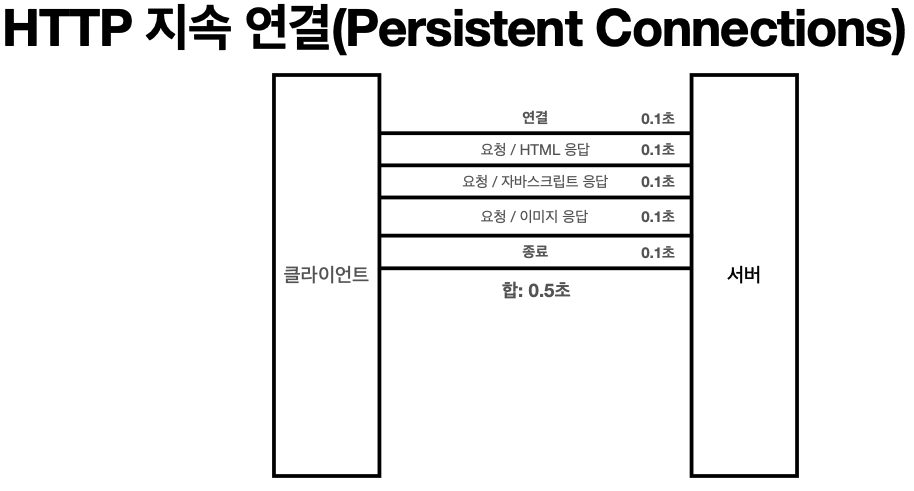
* 지금은 HTTP 지속 연결(Persistent Connections)로 문제 해결
* HTTP/2, HTTP/3에서 더 많은 최적화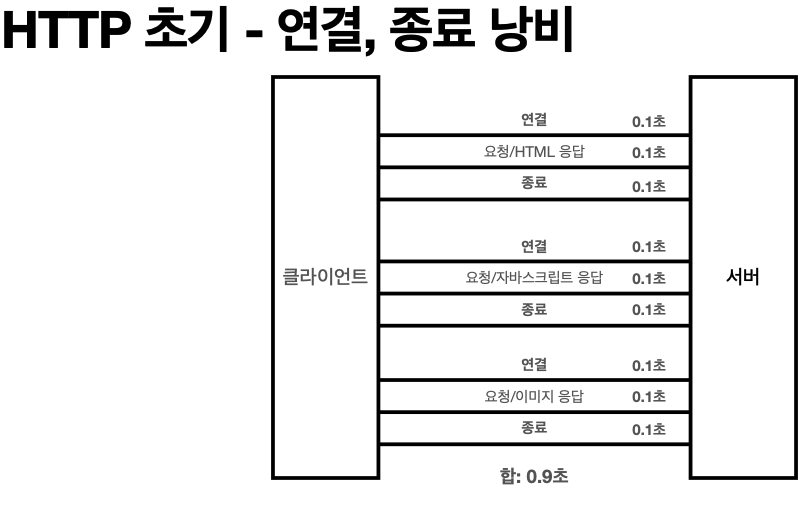
'스테이스리스를 기억하자 (서버 개발자들이 어려워하는 업무)'
* 정말 같은 시간에 딱 맞추어 발생하는 대용량 트래픽
* 예) 선착순 이벤트, 명절 KTX 예약, 학과 수업 등록HTTP 메시지
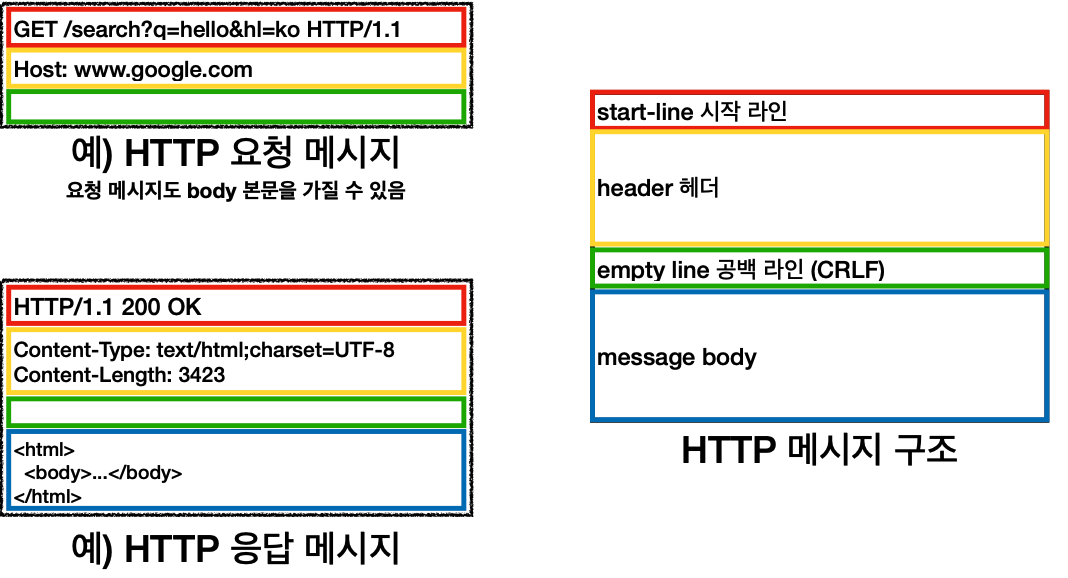





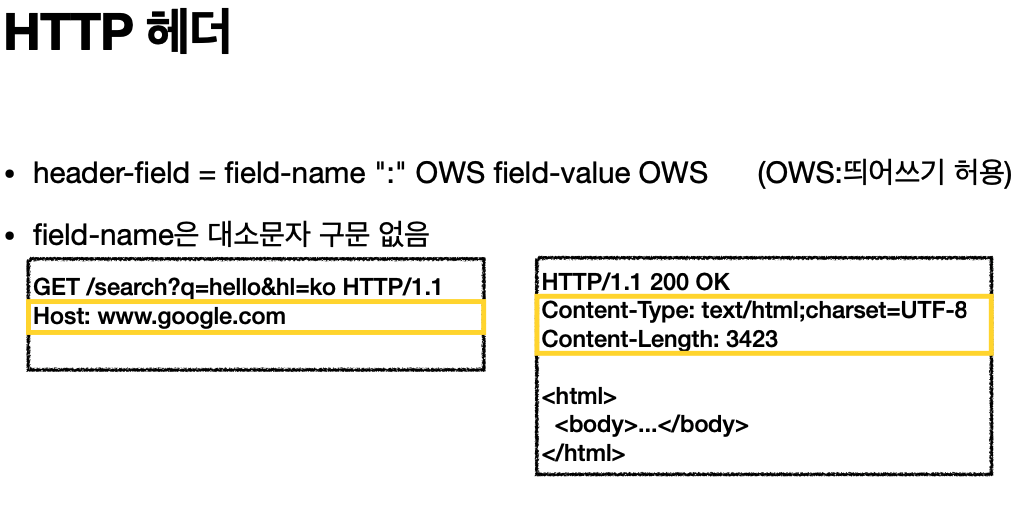


'단순함 확장 가능'
* HTTP는 단순하다. HTTP 메시지도 매우 단순
* 크게 성공하는 표준 기술은 단순하지만 확장 가능한 기술HTTP 정리
* HTTP 메시지에 모든 것을 전송
* HTTP 역사 HTTP/1.1을 기준으로 학슴
* 클라이언트 서버 구조
* 무상태 프로토콜(스테이스리스)
* HTTP 메시지
* 단순함, 확장 가능
* '지금은 HTTP 시대'
반갑습니다