QA MRC 모델을 위한 Retrieval 모델(tf-idf, BM25)
MRC 모델 구성 흐름도

- 질문(Query)에 대해 적합한 문서를 찾는 시스템
- Retrieval을 위한 방법으로 Dense vector와 Sparse vector방법이 존재 (faiss 같은 scaling up 방법도 존재)
- Sparse vector를 이용하는 대표적인 방법 2개 (TF-IDF, BM25)
TF-IDF 와 BM25
tf-idf 구성

- TF는 문서의 빈도 IDF는 문서의 역빈도
- 모든 문서들 중 특정 단어(토큰)이 자주 등장하면 중요도가 낮은 단어
- 모든 문서들 중 특정 단어(토큰)이 자주 등장하지 않으면 중요도가 높은 단어
- 중요도가 높으면 TF-IDF가 높다. 중요도가 낮으면 TF-IDF가 낮다.
BM25 구성

- tf-idf의 변형으로 각 문서들의 길이와 단어(토큰) 빈도수를 고려하여 score를 계산
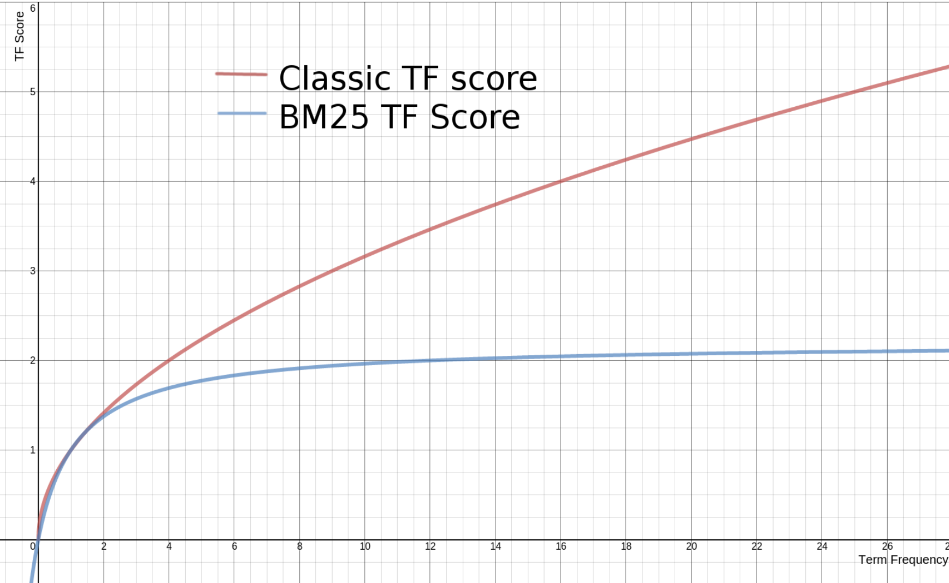
- BM25의 TF가 늘어나도 일정 빈도 이상 부터 score가 높아지지 않는다.
- BM25의 hyper parameter K1, b가 존재
k1은 단어의 빈도수를 고려하여 score에 영향을 결정(default=1.5 or 1.2)
b는 각 문서의 길이를 고려하여 score에 영향을 결정(default=0.75)
비교
- 2.0 보다 비교적 난이도가 낮은 KorQuAD 1.0 테스트 데이터셋으로 비교

- 형태소 분석기로 okt와 mecab을 사용
- 명사만 추출 or 형태소 추출 사용
question과 context 전처리
#문서들 전처리
doc_list = preprocessing(dataset['context'].tolist()) #기본 전처리
doc_list = mecab_morphs(doc_list) #명사만
doc_list = remove_stop_words(doc_list) # 불용어처리
# 질문들 전처리
q_list = preprocessing(dataset['question'].tolist())
q_list = mecab_morphs(q_list)
q_list, _ = remove_stop_words(doc_list, q_list)만든 bm25에 적용
# 문서들 fit
bm25 = BM25()
bm25.fit(doc_list) #정제한 문서들
y_hat = [] #bm25 질의에 대한 적합한 문서 예측 리스트
for q_ in q_list:
scores = bm25.search(q_)
y_hat.append(scores.index(max(scores)))
#예측한 문서인덱스를 데이터프레임에 적재
dataset['bm25_y_hat'] = y_hat
tf-idf
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
len(q_list), len(doc_list)
output: (960, 960)tf-idf는 n-gram을 1~2로 정함
# 사이킷런의 tf-idf default인자에 맞추기위해 재조정
q_list = [','.join(q_).replace(',',' ') for q_ in q_list]
doc_list = [','.join(doc).replace(',',' ') for doc in doc_list]
# q_list와 doc_list 합쳐 fit 한다.
# n-gram은 1~2로 한다.
q_list.extend(doc_list) # 질의와 문서를 학습하기위해 잠시 합쳐놓음
tfidf = TfidfVectorizer(ngram_range=(1,2)).fit(q_list)
len(tfidf.vocabulary_)
output: 82763tfidf.vocabulary_
output:
{'일본': 58460,
'영유권': 50354,
'주장': 65378,
'당시': 19045,
'김영삼': 14087,
'당대': 18943,
'외교': 51689,
'활동': 81203,
'강력': 4993,
'비꼬': 35741,
'표현': 76462,
'상대': 38528,
'대통령': 20169,
'일본 영유권': 58587,
'영유권 주장': 50355,
'주장 당시': 65418,
'당시 김영삼': 19077,
'김영삼 당대': 14110,
'당대 외교': 18944,
'외교 활동': 51709,
'활동 강력': 81216,
'강력 비꼬': 4997,
'비꼬 표현': 35742,
'표현 상대': 76474,
'상대 대통령': 38547,
...
'상무': 38609,
'광고': 10007,
'통과': 73910,
'시킨': 44683,
...}tf-idf 벡터를 구한후 question의 matrix와 context의 matrix의 코사인유사도를 구하여 가장 높은 유사도를 y_hat 인덱스로 할당한다.
# q_list와 doc_list 다시 나눈다.
doc_list = q_list[int(len(q_list) / 2):]
q_list = q_list[:int(len(q_list) / 2)]
# 질문 리스트 fit
tfidf_q_list = tfidf.transform(q_list).toarray()
# 문서 리스트 fit
tfidf_doc_list = tfidf.transform(doc_list).toarray()
tfidf_q_list.shape, tfidf_doc_list.shape # -> output: ((960, 82763), (960, 82763))
# 코사인 유사도로 가장 높은 인덱스 추출
sim_matrix = cosine_similarity(tfidf_q_list, tfidf_doc_list)
sim_matrix.shape # -> output: (960, 960)
#idf 질의에 대한 적합한 문서 예측
y_hat = np.zeros((sim_matrix.shape[0]))
for i, q_ in enumerate(sim_matrix):
y_hat[i] = (np.argmax(q_))
#예측한 문서인덱스를 데이터프레임에 적재
dataset['tfidf_y_hat'] = y_hat.astype(int)
성능평가
print("tf-idf 정확도: ",round(dataset[dataset['y'] == dataset['tfidf_y_hat']].shape[0] /dataset.shape[0], 2))
print("bm25 정확도: ",round(dataset[dataset['y'] == dataset['bm25_y_hat']].shape[0] /dataset.shape[0], 2))
# output:
# tf-idf 정확도: 0.71
# bm25 정확도: 0.7#TF-IDF 성능 검사
acc = accuracy_score(dataset['tfidf_y_hat'], dataset['y'])
print(acc)
cr = classification_report(dataset['y'], dataset['tfidf_y_hat'])
print(cr)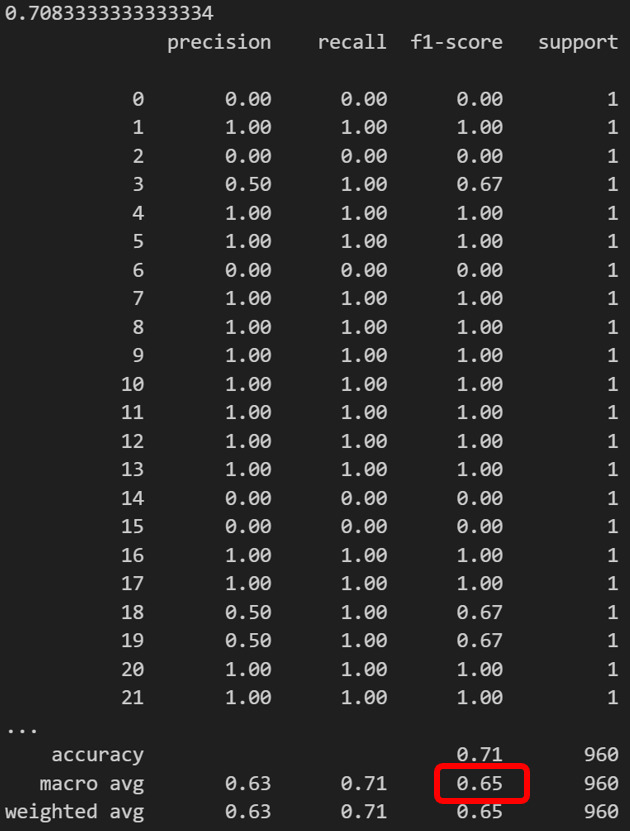
#BM25 성능 검사
acc = accuracy_score(dataset['bm25_y_hat'], dataset['y'])
print(acc)
cr = classification_report(dataset['y'], dataset['bm25_y_hat'])
print(cr)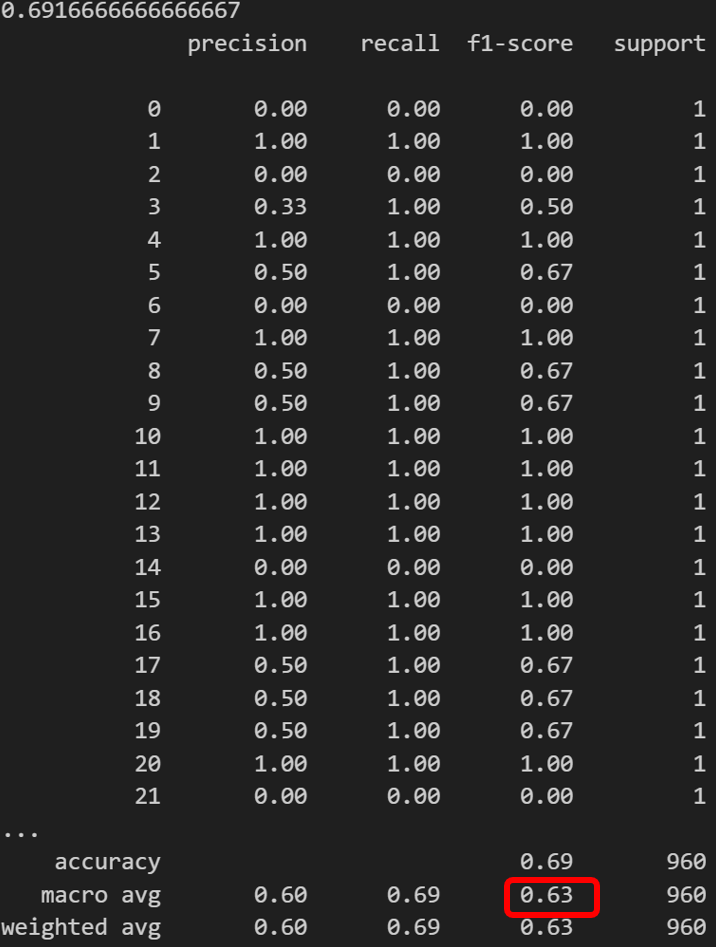
결론
- 예상과 다르게 tf-idf가 bm25 보다 정확도와 macro f1-score점수가 더 높았다.
- 형태소 분석기와 명사와 형태소 추출 방법을 여러가지 써보면 점수면에서는 크게 차이는 보이지않았으나 bm25가 조금 더 높을때도 있었다.
- tf-idf는 n-gram으로 튜닝이 가능하고 bm25는 k1,b로 성능 조정이 가능하다.
- 비록 요즘은 DPR같은 dense vector를 활용하여 Retrieval을 사용하는 경우가 많지만 간단하며 별도의 학습 구축없이 사용가능한 방법으로써 이점이 있다.
- tf-idf 방법이 bm25보다 성능면에서 떨어지지 않는다는 것을 확인
https://github.com/lee513/Wiki_Retrieval_BM25/blob/main/TFIDF_BM25.ipynb

데이터로 쾌적한 세상을 만들고싶어요.