Select
형식
SELECT (값, 컬럼명, 함수, sub query) FROM( table명, sub query)
✅ 출력하기
--EMPLOYEES의 모든 행 출력 select * from EMPLOYEES; --현재계정의 모든 table 출력 select * from tab; -- EMPLOYEE_ID, first_name, salary만 출력 select EMPLOYEE_ID, first_name, salary from EMPLOYEES; -- last_name, salary, salary + 300만 출력 -- salary + 300인 값도 출력 가능 select last_name, salary, salary + 300 from EMPLOYEES; -- last_name, salary * 12 출력 select last_name, salary * 12 from EMPLOYEES; -- 두 문자열을 합쳐서 출력 SELECT FIRST_NAME || ' ' || sysdate || SALARY FROM EMPLOYEES; --alias: employee_id를 사원번호로 출력 select employee_id as 사원번호, salary as 월급, first_name 이름 from EMPLOYEES; -- distinct : 중복행을 삭제 select distinct job_id from EMPLOYEES; -- NVL : null인 경우 설정값으로 처리하기 select employee_id, first_name, salary, NVL(salary * commission_pct, 0) from EMPLOYEES;
✅ 출력하기 #2
where은 조건절로 사용
- 기본 연산자
-- dual : 임시테이블, 가상테이블 select 1, 'a' from dual; -- where 을 이용해서 조건을 만들어줌, first_name이 Julia인 사람만 찾기 select first_name, last_name, salary from EMPLOYEES where first_name = 'Julia'; -- salary가 9000이상인 사람만 찾기 select first_name, salary from EMPLOYEES where salary >= 9000; -- Shanta보다 큰 이름만 찾기 select first_name from EMPLOYEES where first_name >= 'Shanta'; -- is null을 이용해서 찾음, = null이 아님 select first_name from EMPLOYEES where manager_id IS NULL; --and 연산자 select * from EMPLOYEES where first_name = 'John' and salary >= 5000; -- 부등호 select first_name, hire_date from EMPLOYEES where hire_date > '07/12/31'; --all(and), any(or) select * from EMPLOYEES where first_name = all('Julia', 'John'); -- 출력 결과 없음 select first_name, salary from EMPLOYEES where salary = any(8000, 3200, 6000); --in, not in select first_name from EMPLOYEES where first_name in ('Julia', 'John'); select first_name, salary from EMPLOYEES where salary not in (8000, 3200, 6000); -- between select first_name, salary from EMPLOYEES --where salary >= 3200 and salary <= 9000; where salary between 3200 and 9000; select first_name, salary from EMPLOYEES where salary not between 3200 and 9000; -- not select first_name, salary from EMPLOYEES where salary <> 9000;
- like
- _는 한 글자 자리 표시
- %는 글자수 상관 없이 포함여부 검사
-- like -- 언더바(_)는 한 글자 select first_name from EMPLOYEES where first_name like 'G_ra_d'; -- %는 글자수 상관 없음 select first_name from EMPLOYEES where first_name like 'K%y'; select first_name from EMPLOYEES where first_name like 'A%'; select first_name from EMPLOYEES where first_name like '%y'; select first_name from EMPLOYEES where first_name like '%e%'; select first_name, hire_date from EMPLOYEES where hire_date like '06%';
✅ 출력하기 #3
정렬하기(order by)
- asc: 오름차순 정렬(생략가능)
- desc: 내림차순 정렬
select first_name, salary from EMPLOYEES order by salary asc; select first_name, salary from EMPLOYEES order by salary desc; -- 여러개로 한 번에 정렬 가능 select hire_date, salary from EMPLOYEES order by hire_date asc, salary desc;
- nulls first: null을 먼저 출력
- nulls last: null을 가장 마지막에 출력
select commission_pct, salary from EMPLOYEES --order by commission_pct NULLS FIRST; --order by commission_pct NULLS LAST; order by commission_pct NULLS LAST, salary desc;
- group by: 그룹으로 묶는 기능
- having: 그룹으로 묶은 후의 조건
-- department_id가 같은 것 끼리 묶고 정렬 select department_id from EMPLOYEES group by department_id order by department_id;
- count, sum, avg, max, min
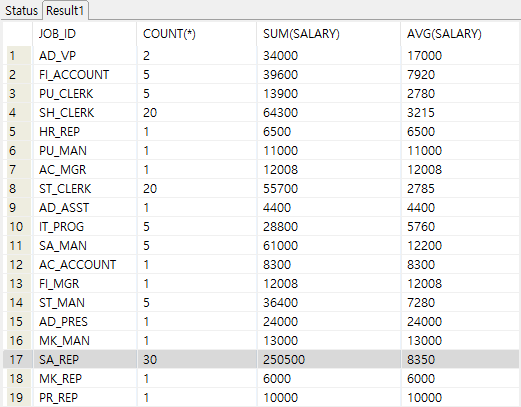
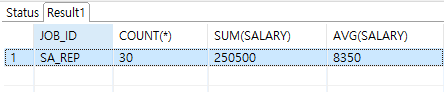
-- job_id가 같은 것으로 묶어서 각 수와 합계, 평균 출력 --having이 있으므로 합계가 100000이상만 출력됨 select job_id, count(*), sum(salary), avg(salary) from EMPLOYEES group by job_id having sum(salary) >= 100000;
- having 조건 없는 경우
- having 조건 있는 경우