Stream
Java 8에서 추가된 기능 중 하나인 Stream에 대해 살펴본다. stream은 컬렉션, list 등에 저장되어 있는 요소들을 하나씩 참조하며 반복적인 처리를 가능하게 하는 기능이다. stream을 사용하면 불필요한 for문과 그 안에서 이루어지는 if문 등의 분기처리 없이 깔끔하고 직관적인 코드로 개발이 가능하다. stream은 스트림 생성부, 중개 연산부, 종단 연산부로 나누어져 있다.

- 스트림 생성부 : 컬렉션 목록을 스트림 객체로 변환시킨다.
- 중개 연산부 : 스트림 객체를 전달받아 중간 연산을 수행하나, 아무런 값을 리턴하지 못한다. 주요 메소드는 다음과 같다.
stream 필터링 진행 : filter(), distinct()
stream 변환을 진행 : map()
stream 데이터 수 제한 : limit()
stream 정렬 : sorted()
stream 연산 결과 확인 : peek() - 종단 연산부 : 작업된 내용을 바탕으로 결과를 리턴해 준다. 주요 메소드는 다음과 같다.
stream 내부 요소 전부 출력 : forEach()
결과 취합 : reduce()
내부 요소 검색 : findFirst(), findAny()
매칭되는 값 리턴 : anyMatch(), allMatch(), noneMatch()
통계값 리턴 : count(), min(), max()
연산값 리턴 :sum(), average()
원하는 타입으로 데이터를 리턴 : collect()
Parallel Stream의 동작
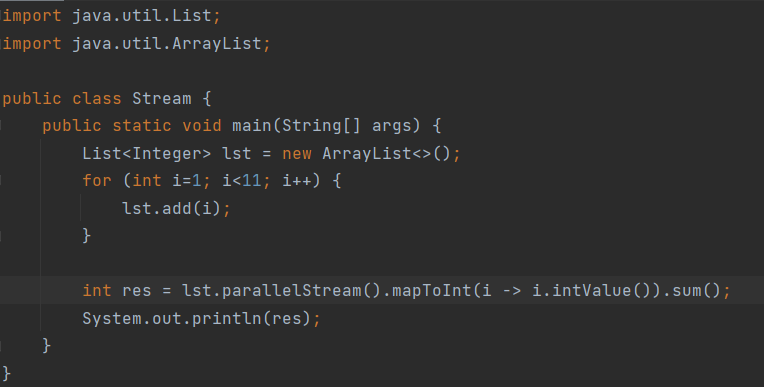
1부터 10까지의 값을 더하기 위해 parallel stream을 사용해 코드를 작성하였다. 이때, 1부터 10까지의 값을 더하기 위해 stream 내부는 어떻게 동작하고 있는지에 대해 살펴본다. stream의 연산이 시작되면 내부에서는 fork & join 방식으로 연산이 진행된다. fork & join 방식으로 동작한다는 말은 어떤 의미인가?
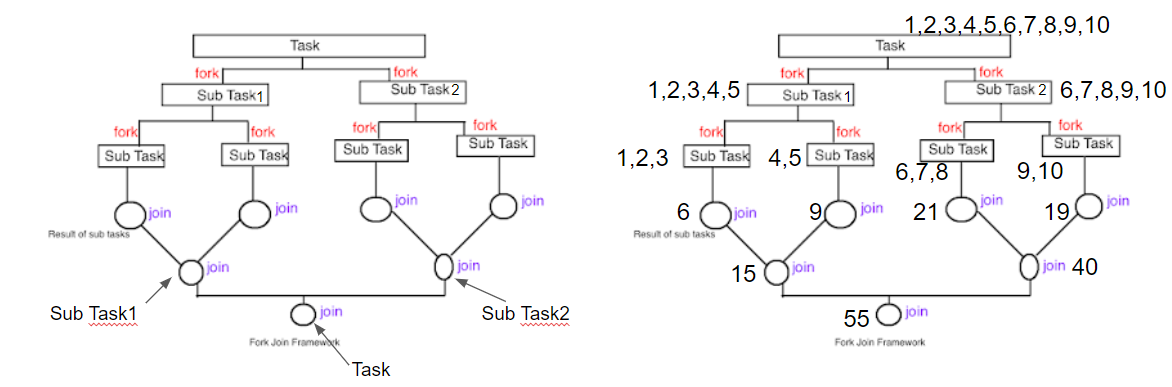
위의 좌측 그림을 보면 Task에서 subTask1과 subTask2로 쪼개지고 이 subTask들이 각각 또 다른 SubTask들로 쪼개지고 있는 것을 볼 수 있다. 이렇게 하나의 task가 쪼개질 수 있을 때까지 쪼개지는 과정이 fork이다. 이렇게 쪼개어 수행한 연산을 합치는 과정이 join 과정이다. 이렇게 fork & join을 이용하면 멀티 스레드로 실행이 가능하다.
Java는 이미 멀티 스레드 환경인데 fork & join을 이용하면 멀티 스레드로 실행이 가능하다는 말이 의아하게 들릴 수 있다. fork & join을 이용했을 때 멀티 스레드로 실행이 가능하다는 의미는 class 내부의 메소드 동작과 연관지어 설명이 가능하다. class 내부의 메소드는 단일 스레드에서 동작하는 반면, fork & join은 하나의 thread 내에서 sub thread들을 계속계속 생성하며 동작하기 때문이다. 즉, 위의 좌측 그림에 나타난 sub Task라 되어 있는 부분들이 전부 하나의 thread가 되는 것이다.
위의 우측 그림은 1부터 10까지 더하는 연산을 실행하는 과정을 나타낸 그림이다. 1부터 10까지 연산해야 하는 task를 1부터 5까지, 5부터 10까지 연산하는 sub task1과 sub task2로 쪼개고 1부터 5까지 연산하는 sub task1을 또 다시 1부터 3까지, 4부터 5까지 연산하는 sub task들로 쪼갠다. sub task2에서도 마찬가지로 쪼갠다. 보통 쪼갤 때에는 균등 분할을 원칙으로 하고 있다. 123/45/678/910으로 쪼갠 후에는 합 연산을 시작한다. 각각의 sub task가 완료되면 부모 task에 그 값을 돌려준다. 이때, 1+2+3이 먼저 완료될지, 4+5가 먼저 완료될지, 6+7+8이 먼저 완료될지, 9+10이 먼저 완료될지는 알 수 없다.
parallel stream은 이렇듯 fork & join을 사용하여 멀티 쓰레드 연산을 진행하므로 훨씬 빠른 속도를 지닌다. 하지만 parallel stream을 사용한다고 무조건 빠른 연산이 가능한 것은 아니다. parallel stream을 사용했을 때 오히려 성능이 저하되는 경우도 빈번히 발생하므로 parallel stream을 사용할 때에는 성능에 대해 생각해본 뒤 사용여부를 결정해야만 한다.
Parallel Stream 사용 시 성능 저하를 일으키는 경우
Case 1. boxing / unboxing이 일어나는 경우
자바의 제네릭 타입은 참조형만 사용이 가능하다. 따라서 자바에서는 기본형을 참조형으로 변환하는 기능을 제공하는데, 이를 boxing이라 한고 반대의 과정은 unboxing이라 한다. byte는 Byte, char는 Character, int는 Integer, double은 Double이란 Wrapper class를 갖는다. 기본형 값을 내부에 두고 포장한다 하여 wrapper(포장) 객체라고 부른다. 자바에서는 프로그래머가 편리하게 코드를 작성할 수 있는 auto boxing을 제공하는데 boxing과 unboxing이 자동으로 이루어진다.
List<Integer> list = new ArrayList<>();
list.add(1); // int -> Integer (boxing)
Integer number = new Integer(100);
int sum = 10 + number; // Integer -> int (unboxing)이러한 변환 과정은 편리한 반면 비용이 소모된다. boxing 된 값이 heap 영역에 저장되어 보다 많은 메모리를 소모하며 가져올 때에도 메모리 탐색 과정이 필요하다.
Stream(stream과 parallel stream 모두 해당되는 부분이므로 stream으로 통칭하여 서술)에서는 이러한 제네릭 타입이 사용되고 있어 int, double과 같은 기본형 변수가 있는 collection에 대해 stream을 사용하려 할 때 auto boxing이 발생한다. 이 과정에서 boxing & unboxing을 수행하는데 소요되는 시간과 메모리 소모로 인해 stream의 성능이 오히려 저하되는 경우가 발생할 수 있다.
해당 case를 해결하기 위해 자바에서는 기본형만 다루는 스트림인 IntStream, LongStream, DoubleStream 인터페이스를 제공하고 있다.
case 2. 순서가 중요한 연산하는 경우
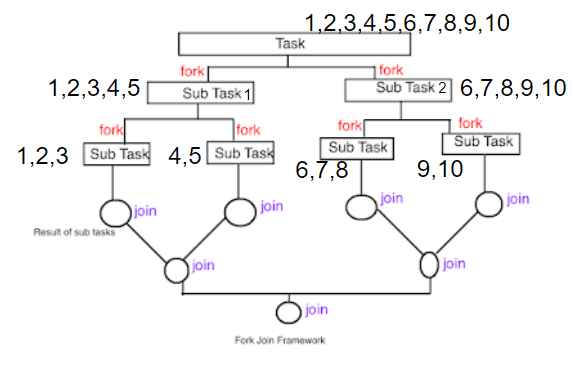
위의 그림에서 123/45/678/910으로 데이터가 쪼개어졌다고 할 때, 1,2,3에 대한 연산이 먼저 끝날지, 4,5에 대한 연산이 먼저 끝날지, 6,7,8에 대한 연산이 먼저 끝날지, 9,10에 대한 연산이 먼저 끝날지는 알 수 없다고 하였다. sum() 연산의 경우는 어떠한 연산이 먼저 끝나는지 여부에 관계없이 먼저 완료된 sub task순서대로 값을 더해나가면 된다. 따라서 단일 쓰레드로 처리할 때보다 성능을 높일 수 있다.
하지만 순서가 중요한 연산을 하는 경우는 성능이 오히려 낮아질 수 있다. findFirst() 연산을 하거나 정렬 연산을 하는 경우에는 어떠한 sub task가 먼저 끝나더라도 전체 sub task가 완료 되어야 연산을 진행할 수 있다. 맨 첫번째 요소를 얻으려 하거나 정렬을 하는 것과 같이 순서가 중요한 연산을 진행하기 위해서는 전체 데이터가 필요하기 때문이다. 전체 데이터에서 특정 데이터가 몇 번째인지 알아야만 한다. 따라서 먼저 완료된 sub task는 다른 sub task들이 전부 완료될 때까지 작업을 마칠 수 없다.
이렇듯 순서가 중요한 연산에서는 parallel stream을 사용한다고 해서 크게 시간적으로 이득을 얻을 수 없다.
case 3. limit() 연산하는 경우
limit(n)은 전체 데이터 중 n만큼의 데이터를 끊어 가져오는 메소드이다. 10개의 숫자가 있을 때 limit(5)를 수행했을 경우에 대해 생각해 본다. sub task는 JVM이 판단하기에 효율적이라고 판단되는 데이터 개수가 나올 때까지 sub task를 나눈다. 그렇게 해서 나눠진 데이터들이 sub task 각각 123/45/678/910으로 쪼개졌다고 가정한다. 이후 limit를 걸어 5개의 데이터만 가져오는 연산이 이루어진다. 이때, 123/45 그룹을 가져오면 limit(5)를 맞출 수 있다. 하지만 JVM이 쪼개둔 그룹이 123/456/789/10으로 쪼개어져 있다면 limit(5)를 걸어 가져올 때 애매한 상황이 발생하게 된다. 123/45까지만 가져와야 하는데 6까지 가져와 종단연산을 수행해버릴 수도 있다. 이 경우 정확한 값을 리턴하지 못하는 상황이 발생하므로 성능이 낮아진다.
case 4. fork 하는 시간보다 짧은 수행시간이 걸리는 경우
실행시간이 fork 하는 데 걸리는 시간보다 짧다면 fork 하는 데 걸리는 시간만 소요되고 성능상으로 나아진 것이 없다. 이런 경우에는 병렬 수행의 의미가 없으므로 parallel stream을 사용하지 않는 것이 더 유리하다. 마찬가지로 소량의 데이터만 존재하는 경우도 parallel stream을 사용하지 않는 것이 더 유리할 수 있다. 소량의 데이터에서는 병렬화 과정에서 생기는 부가 비용을 상쇄할 수 있을 만큼의 이득을 얻지 못하기 때문이다.
case 5. stream을 구성하는 자료구조가 linkedList인 경우
parallel stream을 사용하면 fork가 발생하여 분할 과정이 이루어진다. 이때, ArrayList는 list 전체를 탐색하지 않고도 분할이 가능하다. 하지만 linkedList의 경우 분할하려면 데이터 전체를 탐색해야 분할이 가능하다.
[참조] https://ahndding.tistory.com/23
[참조] https://self-learning-java-tutorial.blogspot.com/2015/07/java-fork-join-framework.html
[참조] https://girawhale.tistory.com/123
[참조] https://yongho1037.tistory.com/705
