Transaction을 쓰는 이유
A씨는 200만원을 지니고 있고 B씨는 0원을 지니고 있다. A씨는 B씨에게 100만원을 송금할 일이 생겼다고 가정한다. 해당 거래를 DB에 저장한다고 가정한다. 거래 완료 후 DB에 저장되어야 할 값은 A씨 100만원, B씨 100만원이다.
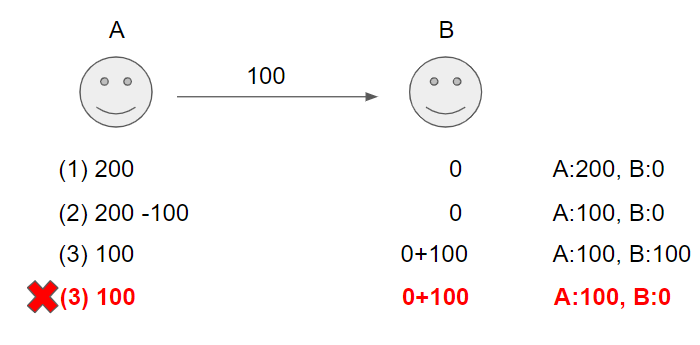
A씨가 B씨에게 100만원을 보내는 과정을 DB는 다음과 같이 처리한다. 우선 A의 잔액 정보를 200에서 100으로 update하는 쿼리가 발생(2)한다. 그리고 B의 잔액 정보를 0에서 100으로 update하는 쿼리가 발생(3)한다. (2)와 (3)의 과정 모두 성공하면 문제 없이 DB의 값이 A 100만원, B 100만원으로 업데이트된다. 하지만 위의 그림처럼 (3)의 과정에서 에러가 발생하는 경우에 대해 생각해본다.
(2)의 과정에서 A씨의 잔액은 B씨의 수신 여부에 관계없이 update된다. 따라서 (3)의 쿼리가 실패하게 되면 A 100만원, B 0원이라는 결과가 DB에 반영되어 100만원이 증발(?)되어버리는 현상이 발생한다.
이러한 현상은 발생하면 안되므로 DB에서는 항상 데이터 무결성을 보존하고자 한다. transaction은 이 데이터 무결성을 보장하기 위한 수단 중 하나이다. 위의 그림에서 (2)와 (3)을 한 번에 묶어 transaction으로 만들고 (2)와 (3) 두 과정 중 하나라도 실패하면 rollback을 하고, 두 과정 모두 성공했을 때 commit을 하게 하면 데이터 무결성이 보존된다.
Database ACID
데이터베이스 트랜잭션이 안전하게 수행된다는 것을 보장하기 위한 성질을 가르키는 약어 ACID에 대한 설명은 아래와 같다.
- 원자성(Atomicity) : 트랜잭션과 관련된 작업들이 부분적으로 실행되다가 중단되지 않는 것을 보장하는 성질
- 일관성(Consistency) : 트랜잭션이 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태를 유지하는 성질
- 독립성(Isolation): 트랜잭션 수행 시 다른 트랜잭션의 연산 작업이 끼어들지 못하도록 보장하는 성질
- 지속성(Durability): 성공적으로 수행된 트랜잭션은 영원히 반영되어야 함을 의미하는 성질
ACID의 원칙을 너무 타이트하게 지키면 동시성(Consistency)에 대한 퍼포먼스가 떨어지게 되어 Isolation Level 별로 차등을 두어 동시성에 대한 이점을 가질 수 있게 하였다.
B씨와 C씨는 초 단위로 A씨에게 송금을 하고 있다고 가정한다. 그리고 잔액 정보의 변화를 실시간으로 조회하고 싶어 하는 A씨가 존재한다고 가정한다. 이때, DB에서는 Isolation 성질에 따라 B씨가 송금하는 동안 C씨의 송금 거래를 DB에 반영하지 않는다. B씨와 C씨는 동시에 100만원씩 송금했고, 이때 A씨가 볼 수 있는 잔액 정보는 100만원이 추가된 정보이다. 원래는 C씨가 송금한 100만원까지 추가되어 200만원이 추가된 잔액 정보를 조회할 수 있었어야 하는데, 100만원이 추가된 정보밖에 보지 못하게 된다. 이를 '동시성에 대한 퍼포먼스가 떨어진다'고 한다.
MySQL DB에서는 Transaction Model마다 Isolation Level에 차등을 두어 동시성을 보장하고 있다. 다른 DB도 마찬가지로 Transaction Model이 존재한다. 하지만 필자는 MySQL에 대한 Transaction Model에 대한 내용만 서술하고자 한다.
Transaction Model
1. READ UNCOMMITTED
lock을 전혀 사용하지 않는다. 이 레벨의 경우 트랜젝션을 사용하는 의미 자체가 거의 없어 잘 사용되지 않는다. SELECT 쿼리 실행 시, 다른 트랜잭션에서 COMMIT 되지 않은 데이터를 읽어올 수 있다.
이렇게 COMMIT 되지 않고 읽어온 데이터를 dirty read라고 한다.
rollback 될 가능성이 있는 insert된 데이터를 읽어올 수 있으므로 유의해야 한다.
2. READ COMMITTED
COMMIT이 완료된 데이터만 SELECT로 조회 가능하다. 대부분의 DBMS에서 디폴트 값으로 설정한다. READ UNCOMMITTED에서 발생했던 dirty read가 발생하지 않도록 보장해준다.
select가 발생할 때마다 새로운 스냅샷을 생성해서 읽어오므로 phantom read(유령 읽기)가 발생할 수 있다. 다른 세션에서 insert를 했거나 delete를 했거나 해서 자신의 세션에서 조회한 자료세트 범위가 다른 세션에 의해서 변경될 경우 자신의 자료 세트를 자신이 변경하지 않았음에도 불구하고 유령처럼 바뀌는 것을 phantom read라고 한다.
postgreSQL의 디폴트 값이다.
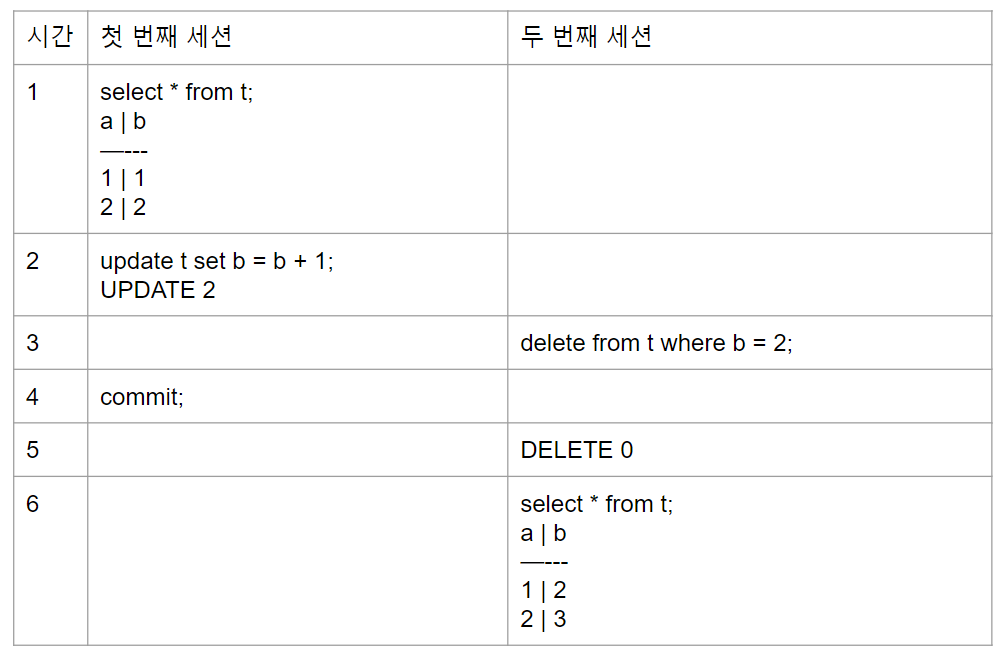
READ COMMITTED에서는 두 번째 세션에서 delete 연산이 발생하지 않는다. delete를 위해 자료를 읽어오는 시점은 commit이 일어나기 전인 첫 번째 세션의 시간 1에 해당하는 테이블이다. 따라서 delete를 위해 읽어온 테이블 중 a=2, b=2의 row를 삭제할 작업 대상으로 정해둔다.
delete 연산이 실제로 수행되는 시점은 첫 번째 세션으로부터 lock을 획득하는 시점(=첫 번째 세션이 commit을 한 시점)이다. 이때, REPEATABLE READ와는 달리 스냅샷을 한 번 더 뜨게 된다. 첫 번째 세션에서 commit이 발생하면서 작업 대상이었던 a=2, b=2의 row가 a=2, b=3으로 변경된다.
두 번째 세션은 작업 대상이었던 a=2, b=2의 row가 더이상 존재하지 않게 되어버려 그 어떤 row도 삭제하지 못하게 된다.
3. REPEATABLE READ
Inno DB에서 별다른 설정을 하지 않으면 REPEATABLE READ가 기본 level로 설정된다. 즉, MySQL의 디폴트 값이다.
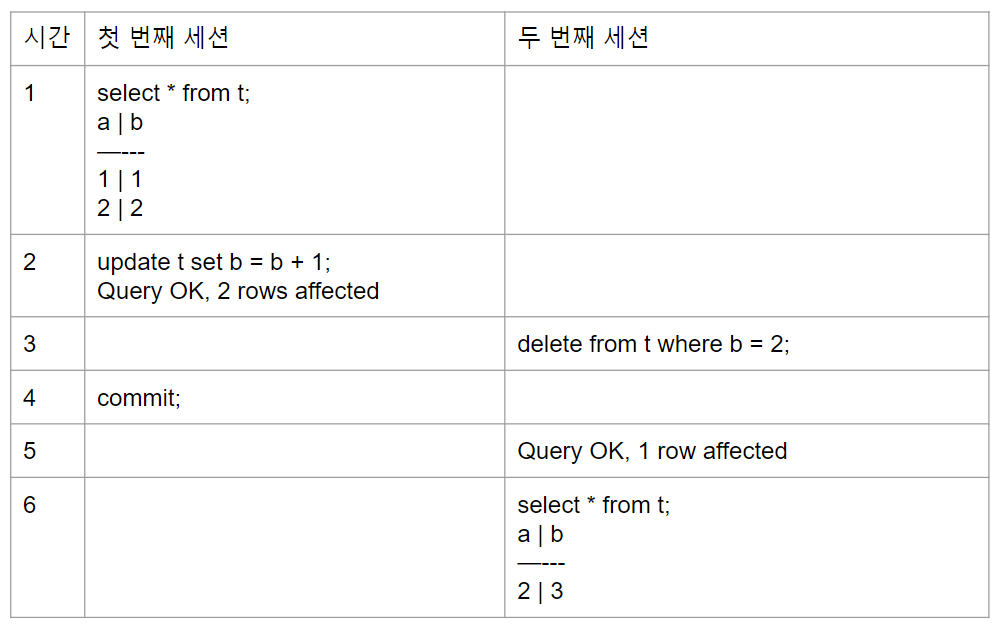
a=1, b=1의 자료가 첫 번째 세션 작업이 commit 되면서 a=1, b=2의 자료가 되었다. 따라서 a=1, b=2 자료가 삭제되었다.
매번 새로운 스냅샷을 생성하지 않고 특정 시점의 스냅샷을 이용하여 기존과 동일한 결과를 리턴할 수 있도록 해주는 isolate level이 REPEATABLE READ이다. 첫 번째 세션의 read operation이 수행된 시점의 데이터로 스냅샷이 생성된다.
따라서 두 번째 세션은 새로운 스냅샷을 떠와서 delete 연산을 진행하는 것이 아니라 첫 번째 세션의 스냅샷을 바라본다. 첫 번째 세션에서 commit이 일어나 변경된 데이터에 대해 두 번째 세션에서의 delete 연산이 일어난다.
4. SERIALIZABLE
모든 작업을 하나의 트랜잭션에서 처리하는 것과 같은 가장 높은 고립수준을 제공한다. 모든 SELECT 문을 SELECT ... FOR SHARE 문으로 바꾸어 실행한다. SELECT ... FOR SHARE 같은 것을 Locking READ라고 하는데 읽을 row에 미리 lock을 걸고 읽는 것이다. 해당 lock이 풀릴 때까지 대기하고 lock이 풀려야 값을 읽을 수 있다.
READ UNCOMMITED -> READ COMMITED -> REPEATABLE READ -> SERIALIZABLE위와 같은 순서로 속도와 Concurrency가 낮아진다. 반면 데이터 무결성은 높아진다. 따라서 이들의 균형을 잘 맞추어 isolation level을 맞추는 것이 중요하다. 또한 각 DBMS마다 설정되어 있는 isolate level이 다르므로 개발 중 isolate level을 설정을 건드릴 일이 존재할 것이다. (앞에서 살펴보았듯 MySQL의 디폴트 값은 REPEATABLE READ, postgreSQL의 디폴트 값은 READ COMMITED) 이때 해당 포스팅에 남긴 개념들에 유의하여 설정을 변경하도록 한다.
[참조] https://www.letmecompile.com/mysql-innodb-transaction-model/
[참조] https://www.postgresql.kr/blog/pg_phantom_read.html
[참조] https://osy0907.tistory.com/112
[참조] https://velog.io/@usaindream/2.-Transaction-Model
