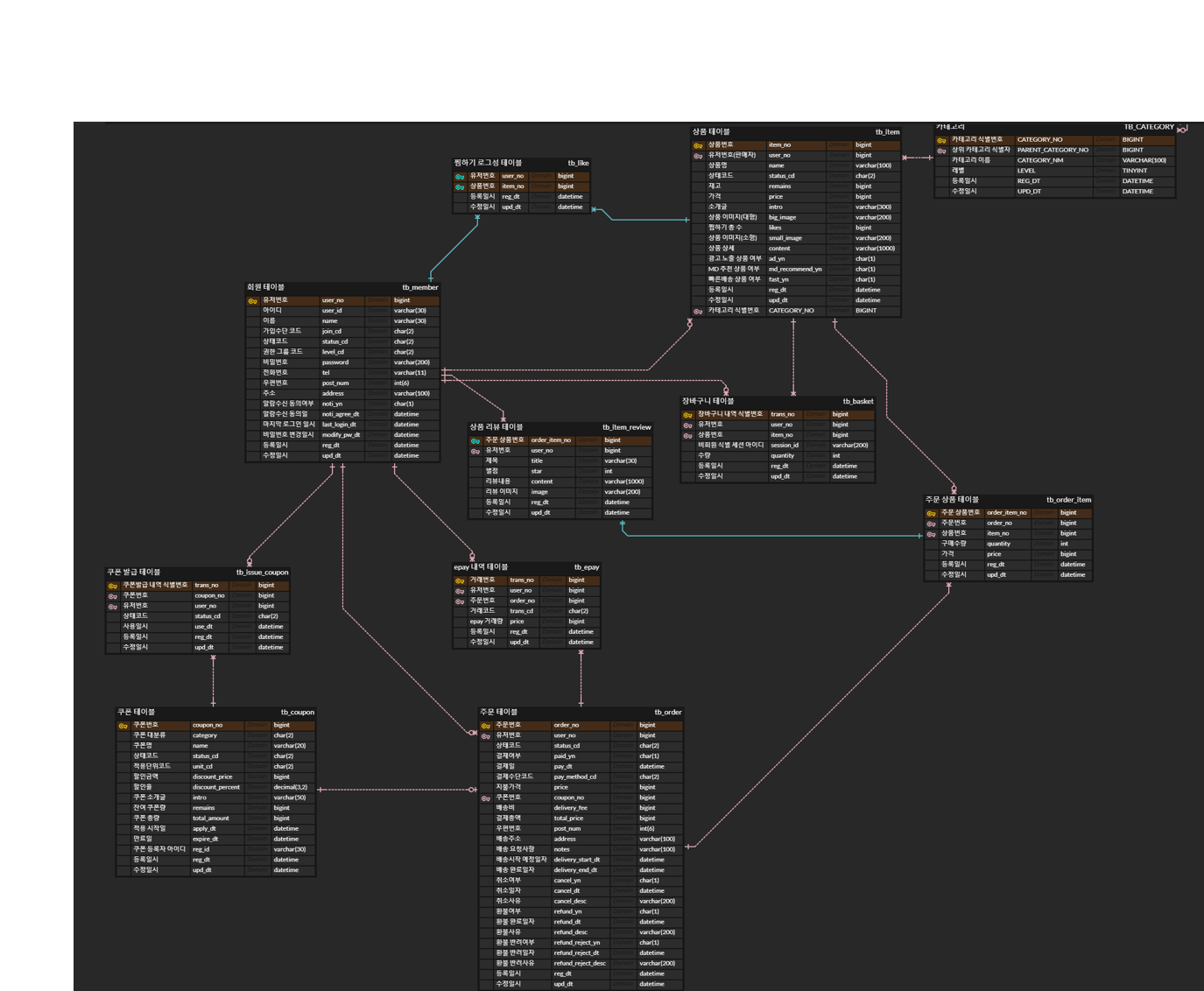
보통 회사에서는 시니어 개발자 분께서 DB 설계를 진행하시고 나와 같은 주니어 개발자는 구현을 맡는다. 그래도 이전 회사에서는 게시판과 흡사한 기능의 DB 설계를 내게 맡겨주시기도 하셨다. 그때 부담감이 좀 컸던 것으로 기억된다.
DB 설계는 건물의 설계도면과 같다고 생각한다. DB 설계가 잘 된다면 흔들리지 않는 견고한 소프트웨어를 개발할 수 있다. 하지만 DB 설계가 흔들리면 불안정한 소프트웨어를 개발하게 되어 계속 설계 단계로 되돌아가게 된다.
경력이 찰 수록 설계를 할 기회는 점점 많아지게 될 것이므로 그 때 다시 실수하지 않도록! 지금의 토이 프로젝트 ERD 설계를 하며 겪었던 실수들을 정리해보고자 한다.
설계 툴로는 erd cloud를 사용하였다. aqueryTool을 사용했었는데, 갑자기 유료 버전이 생기면서 table을 5개 이상 생성할 수 없게 되었다. 따라서 무료 버전인 erd cloud를 찾아 사용하였다.
복합키보단 단일키
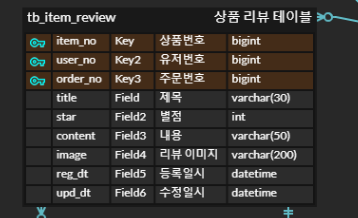
상품 리뷰 테이블에서 회원 테이블의 유저번호, 상품 테이블의 상품번호, 주문 테이블의 주문번호를 전부 KEY로 잡는 설계를 했다. 이 설계에는 여러 문제점이 존재한다.
상품번호와 유저번호, 주문번호는 다른 테이블로부터 오는 외래키이다. 이를 KEY로 잡은 상태에서 리뷰를 남긴 회원이 탈퇴했다. 이때 어떤 일이 벌어지게 되겠는가? 식별관계와 비식별 관계를 구분하지 못해 이런 설계를 진행하게 되었다.
>> 식별 비식별 관계?
두 번째로, 인덱스를 타지 않는 경우가 발생한다.
상품 리뷰 테이블에서 196번 회원이 작성한 리뷰를 가져오고자 한다.
SELECT * FROM TB_ITEM_REVIEW WHERE USER_NO = 196tb_item_review 테이블의 키는 유저번호, 상품번호, 주문번호이다. 따라서 유저번호로만 조회하는 위의 쿼리는 인덱스를 타지 않게 된다.
마지막으로, 상품 리뷰에 대한 대댓글 테이블이 만들어진 경우 불필요한 데이터를 저장하게 된다. 상품 리뷰에 대한 대댓글 테이블에는 이 대댓글이 어느 리뷰에 대한 대댓글인지에 대한 정보만 저장하면 된다. 하지만 리뷰 테이블인 tb_item_review에 유저번호, 상품번호, 주문번호가 복합키로 잡혀있어 대댓글 테이블이 유저번호, 상품번호, 주문번호를 모두 지녀야만 한다.
어떻게 고칠 수 있을까?
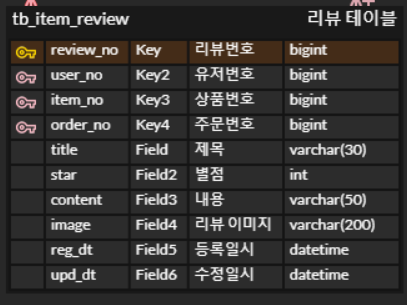
유저번호, 상품번호, 주문번호는 외래키로 두고(비식별) 리뷰번호라는 새로운 column을 PK로 두는 방식으로 변경할 수 있다.
복합키보다는 단일키를 사용하도록한다.
셀프참조 활용하기
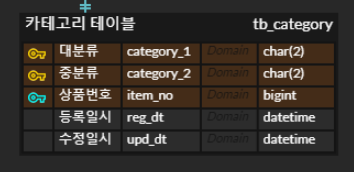
초반 카테고리 테이블을 아래와 같이 설계했다. 상품이 있고 해당 상품은 반드시 대분류와 중분류를 가질 것이라는 생각 때문이었다. 하지만 물품 중에서는 대분류만 갖는 경우도 존재했다. 이럴 경우 중분류에 null 값이 들어가야 하는데 중분류가 PK 값으로 잡혀 있어 에러가 발생한다.
또 문제가 되는 지점은 대분류, 중분류 외에 소분류, 소분류보다 더 하위 분류가 추가되었을 때 점점 PK column이 늘어난다는 점이다. 따라서 아래와 같이 테이블을 수정하였다.
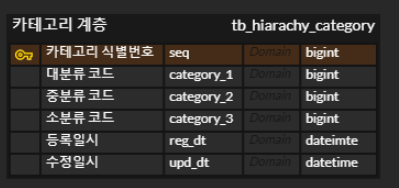
단일키가 잡혀 있어 이전보다는 나아졌으나 소분류보다 더 하위의 분류체계가 생길 경우 매번 column을 추가해야 한다.
분류코드를 100개 가진 상품이 딱 하나 존재하는 상황이 왔을 때를 가정해본다. 일단 분류코드를 100개 갖고 있으므로 category_3까지만 있는 위의 테이블에서 category_4~category_100 column을 추가하는 것도 1차적 문제다. 2차적 문제는 분류코드를 100개 가진 상품 외에는 전부 대분류까지만 갖는 상품들이 저장되어 있을 경우 카테고리 테이블은 필요없는 데이터를 너무 많이 저장하고 있게 된다.

어떻게 고칠 수 있을까?
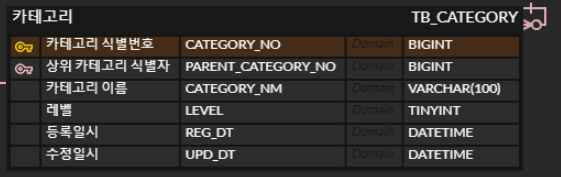
위와 같이 상위 카테고리 식별자를 두고 자기 자신을 참조하게 하는 방식이 있다. 위와 같은 방식으로 설계하게 되면 테이블 내에 불필요한 null 값을 저장하지 않을 수 있다. 또한 복합키였던 이전과 달리 카테고리 식별번호라는 단일키를 갖는다.
또한, 카테고리 테이블 내부에 상품 번호를 갖고 있었던 이전 구조는 잘못된 것이다. 카테고리는 상품에 대한 정보이지, 상품이 카테고리의 정보에 속하는 것은 아니기 때문이다. 따라서 카테고리는 상품정보를 담아둔 상품 테이블에 들어가는 것이 맞다. 이는 연관관계 매핑을 통해 해결할 수 있다. 수정된 설계는 아래와 같다.
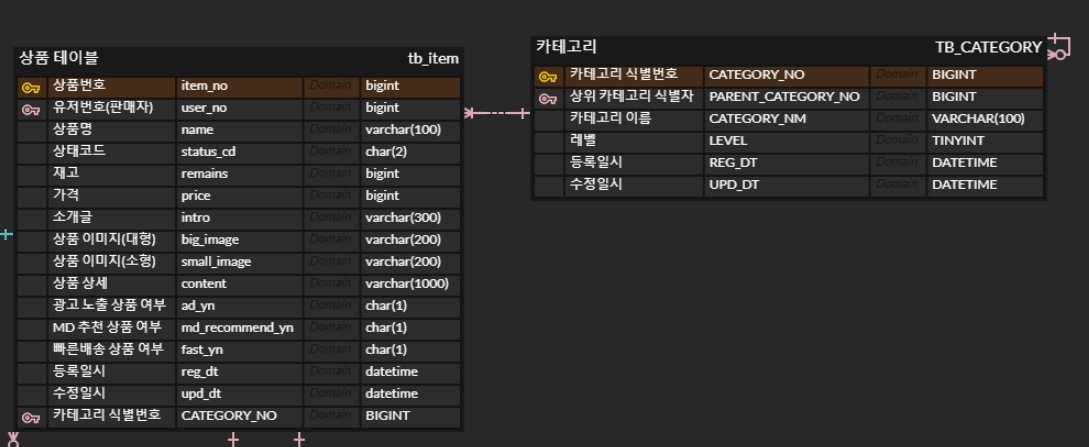
찜하기 기능 설계 비교
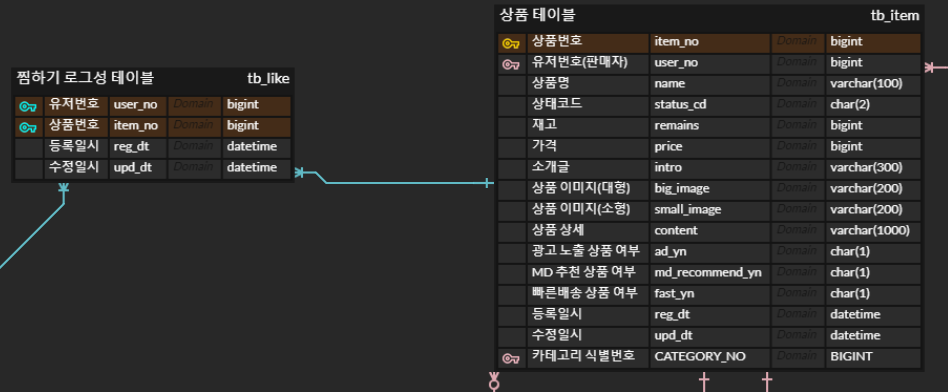
상품 찜하기는 on/off가 가능하다. 따라서 어떤 사용자가 어느 상품 번호를 찜했는지에 대한 정보를 담고 있어야 한다. 이를 찜하기 로그성 테이블로 만들었고 찜하기 기능이 on/off 될 때마다 이 테이블에 insert/delete를 반복하도록 구현하였다.
상품을 찜하는 것이므로 상품 테이블에 들어가는 것이 맞다고 생각할 수 있으나 "누가" 찜했는지에 대한 정보까지 상품 테이블에 들어가게 되면 불필요한 데이터가 저장되게 된다. item1을 user1, user2, user3이 찜한 경우 로그성 테이블에는 (item1, user1), (item1, user2), (item1, user3)만 저장하면 되지만 상품 테이블에 들어가면 (item1, user_no, name, status_cd, ..., upd_dt, user1), (item1, user_no, ..., user2), (item1, user_no, ..., user3)로 저장되게 되어 item1부터 upd_dt까지 중복된 데이터가 3번이나 저장되는 것을 알 수 있다.
이렇듯 찜하기 on/off 기능에서는 로그성 테이블을 둔 설계가 도움이 된다. 하지만 모든 상품들의 총 찜 개수를 select 하는 경우에 단점이 존재한다. 찜하기의 경우 로그성 테이블에 몇몇 상품이 존재하지 않는다고 해서 상품을 누락시켜버리면 안된다. 즉, inner join이 아니라 left outer join과 같은 outer join을 사용해야 한다. 상품 수와 로그성 테이블의 데이터 수가 적을 때에는 문제가 되지 않겠지만 상품 수가 만 개, 로그성 테이블에 백만 개의 데이터가 있다고 가정해본다. 이 상황에서 outer join을 사용하게 되면 10,000 * 1,000,000 = 10,000,000,000, 총 백억번의 연산이 발생하게 되는 것이다. 이 연산 시간이 20초 정도 걸린다 가정하면 전체 상품의 찜 수를 구하는 쿼리는 20초 넘게 걸린다는 의미이다. group by 연산 속도까지 고려하면 쿼리의 연산 속도는 더 늦어진다.
대용량 데이터를 다루게 된다면 이와 같은 부분도 반드시 고려해야 함을 깨달을 수 있었다.
어떻게 고칠 수 있을까?
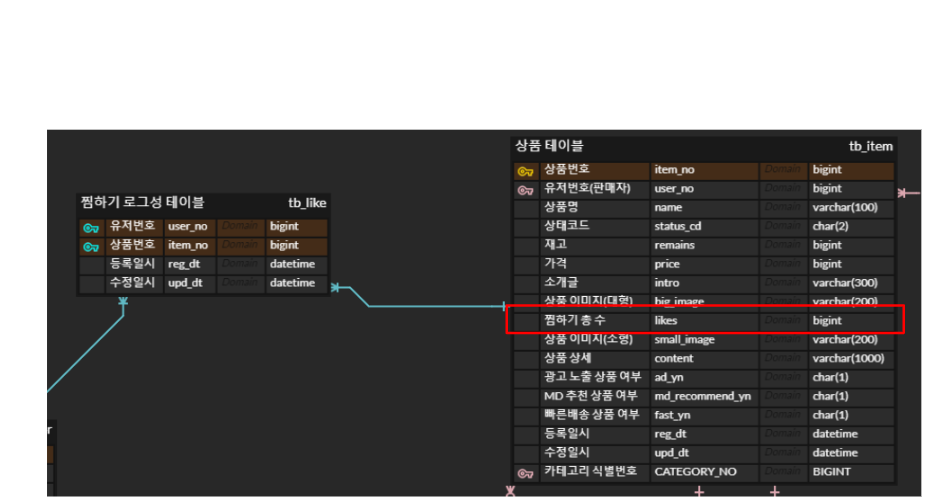
위와 같이 상품 테이블에 찜하기 총 수를 두는 방법이다. 찜하기 총 수를 상품 테이블에 같이 두게 된다면 select 쿼리 시에 outer join과 group by를 수행할 필요 없이 one table 내에서 조회만 하면 된다.
하지만 이 방법 역시 단점이 존재한다. 이 방법으로 테이블을 설계하면 유저가 찜하기를 클릭했을 때 로그성 테이블에 insert 하는 것과 상품 테이블에 찜하기 총 수를 +1 하는 것이 하나의 트랜잭션이 된다. 한 명의 유저가 아니라 10만명의 유저가 찜하기를 클릭했다면 어떤 일이 발생하게 될까? 트랜잭션 밀림 현상이 발생하게 될 수 있다. transaction isolation 때문에 lock이 걸리게 되어 유저의 대기시간이 길어지게 되는 것이다.
역시나 고려할 것이 많았던 ERD 설계였다. 대규모 트래픽, 대용량 데이터로 인해 발생할 수 있는 문제들, 이를 해결하기 위한 설계에 어느 장단점이 있을지 생각해보는 연습이 필요하다. 우선 완성한 ERD 설계는 아래와 같다.