
1. 서론
IntelliJ에선 UI를 통해 사용자와 수많은 상호작용을 다룬다.
예를 들어, 코드를 열어본다던가 혹은 위 사진과 같이 Settings에 들어가서 Build세팅을 바꾸는 일상적인 행동들이 모두 여기에 속한다.
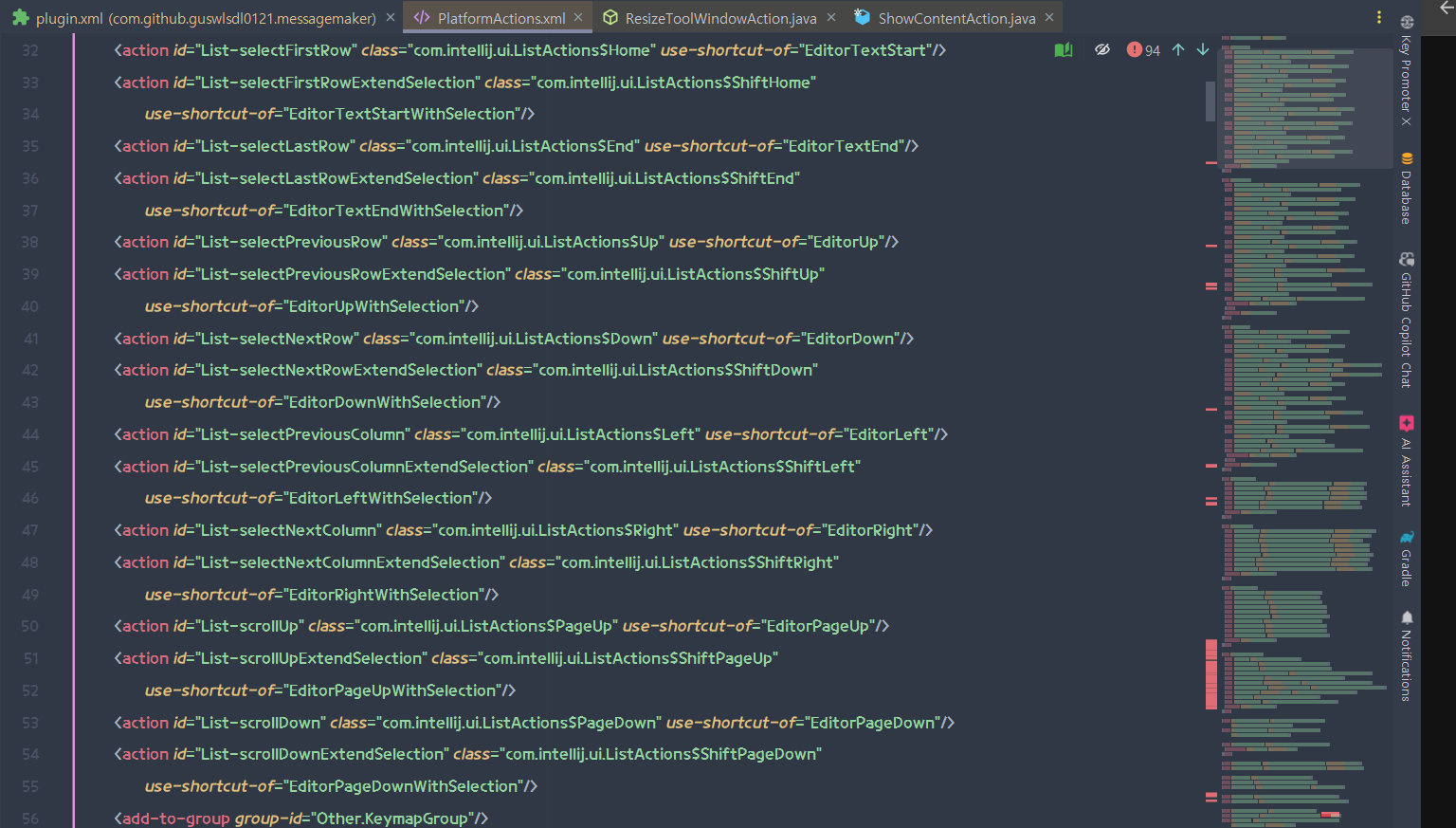
IntelliJ Platform에선 이러한 동작들을 Action이라고 칭한다. 그리고 이전 게시글에서 다룬 것 처럼 모든 Action은 Java/Kotlin코드로 구현되어 xml에 등록된다.
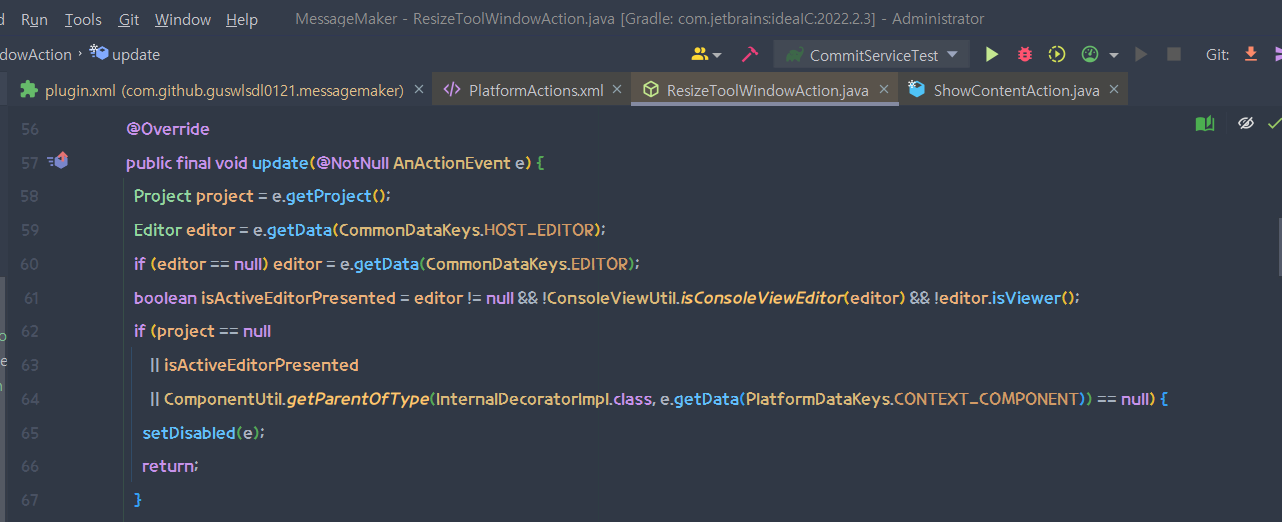
그리고 이 Action을 구현할 때, 현재 시점의 컨텍스트에서 필요한 정보를 가져오는 메서드가 getData()라는 메서드이다.
위 사진은 실제 Tool창에 대한 사이즈 재조정 기능을 구현하는 Action 클래스의 일부분이다. 여기서도 Editor의 정보를 얻기 위해 e.getData()를 호출하고 있다.
인텔리제이에선 거의 대부분의 Action 순간순간마다 컨텍스트에서 정보를 가져온 후에 필요한 동작을 수행한다.
그리고 이 컨텍스트 정보는 DataContext라는 객체에서 전담하고 있으며 DataKey라는 키객체를 식별자로 사용해서 원하는 정보를 가져온다.
(이러한 동작은 플러그인 개발이 아닌 인텔리제이 플랫폼 내부의 대부분 구현에 사용되고 있다.)
이쯤 되니 다음과 같은 궁금증이 생겼다.
인텔리제이엔 수많은 UI컴포넌트들과 기능들이 있는데 어떻게 이런 수많은 이벤트들을 "잘"처리할 수 있을까?
오늘은 이것에 대해서 간단히 다뤄보고자 한다.
2. 디버깅 환경 구성
먼저 아주 간단하게 Tools의 어느 항목을 누르면 메시지박스를 생성하는 코드를 작성해보자.
물론 현재 구현한 파일에서 디버그를 수행하는 것이 제일 좋은 방법이지만, 아쉽게도 Git과 연동되어야하는 작업은 테스트 환경에서 동작하지 않는다.
그래서 아주 간단한 액션을 만든 후, e.getData()를 호출하는 부분에 디버깅을 찍어서 확인해볼 것이다.
이때 plugin.xml과 Action 구현체이외의 추가적인 파일은 필요 없다.
plugin.xml에 Action 등록
<!--<actions>태그 내부에 추가, 없으면 <actions>태그 생성 후 내부에 추가-->
<action id="com.github.guswlsdl0121.messagemaker.actions.DataKeyDebugAction"
class="com.github.guswlsdl0121.messagemaker.actions.DataKeyDebugAction" text="Debug DataKey"
description="Action to debug DataKey functionality">
<add-to-group group-id="ToolsMenu" anchor="last"/>
</action>DataKeyDebugAction 작성
import com.intellij.openapi.actionSystem.AnAction
import com.intellij.openapi.actionSystem.AnActionEvent
import com.intellij.openapi.actionSystem.CommonDataKeys
import com.intellij.openapi.project.Project
import com.intellij.openapi.ui.Messages
class DataKeyDebugAction : AnAction() {
override fun actionPerformed(e: AnActionEvent) {
// 여기에 중단점을 설정
val project: Project? = e.getData(CommonDataKeys.PROJECT)
if (project != null) {
val message = "Project name: ${project.name}"
Messages.showInfoMessage(project, message, "DataKey Debug Info")
} else {
Messages.showInfoMessage("No project found", "DataKey Debug Info")
}
}
}
중단점 지정 후 디버그 모드로 Run Plugin 실행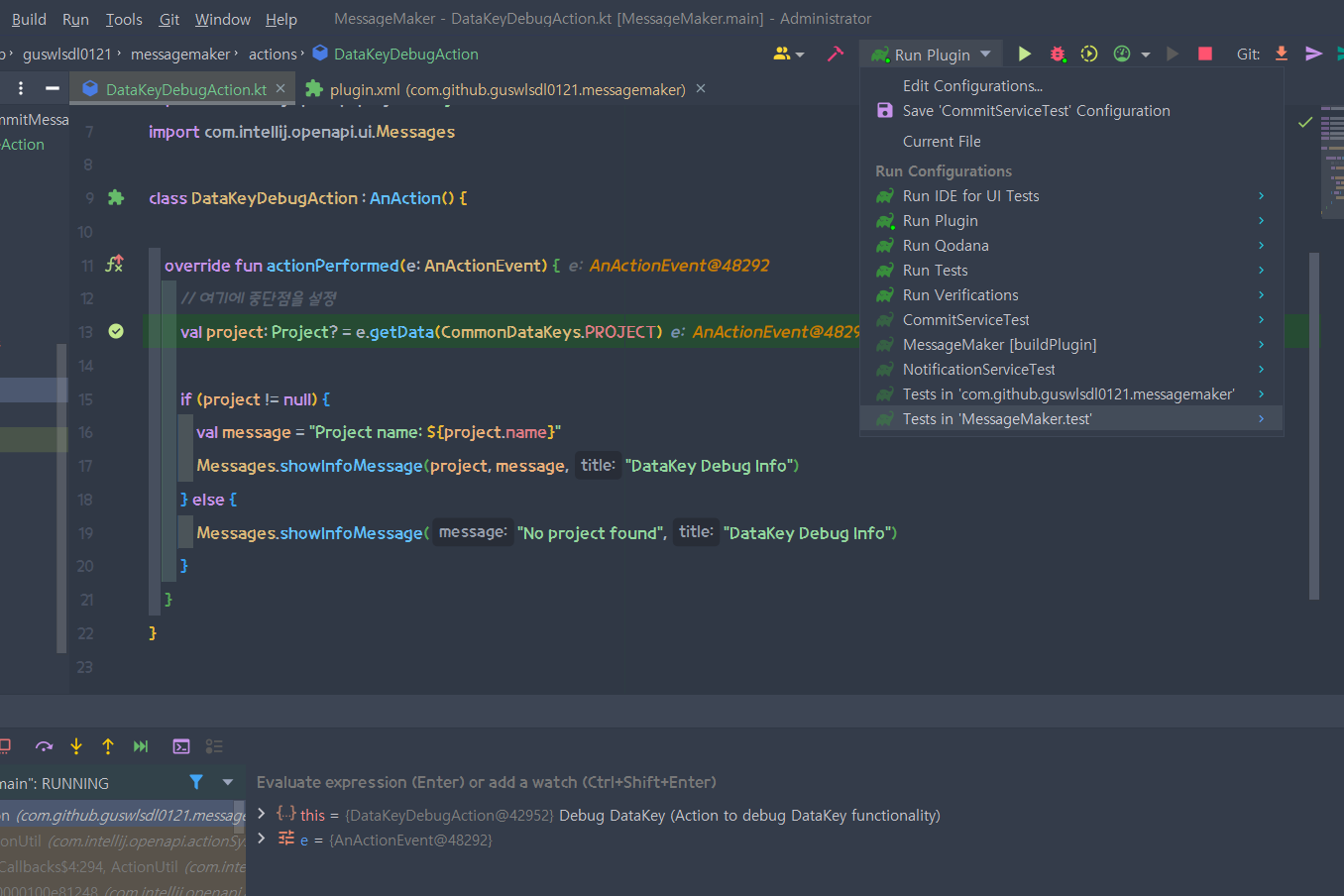
최초 실행 시, 관리자 페이지로 이동하게 된다. 이때 대충 아무 인텔리제이 프로젝트 잡아서 실행하면 된다. 만약 Run Plugin을 찾지 못한다면, Gradle창에서 IntelliJ > runIde를 수행하면 된다.
Tools > Debug DataKey 클릭
디버그 진행
Step into(F5)를 눌러가며 호출 스택을 따라가보자.
3. e.getData(dataKey)추적
이제 e.getData(dataKey)에 대해서 차근차근 호출 스택을 밟아보자.
DataKeyDebugAction #actionPerformed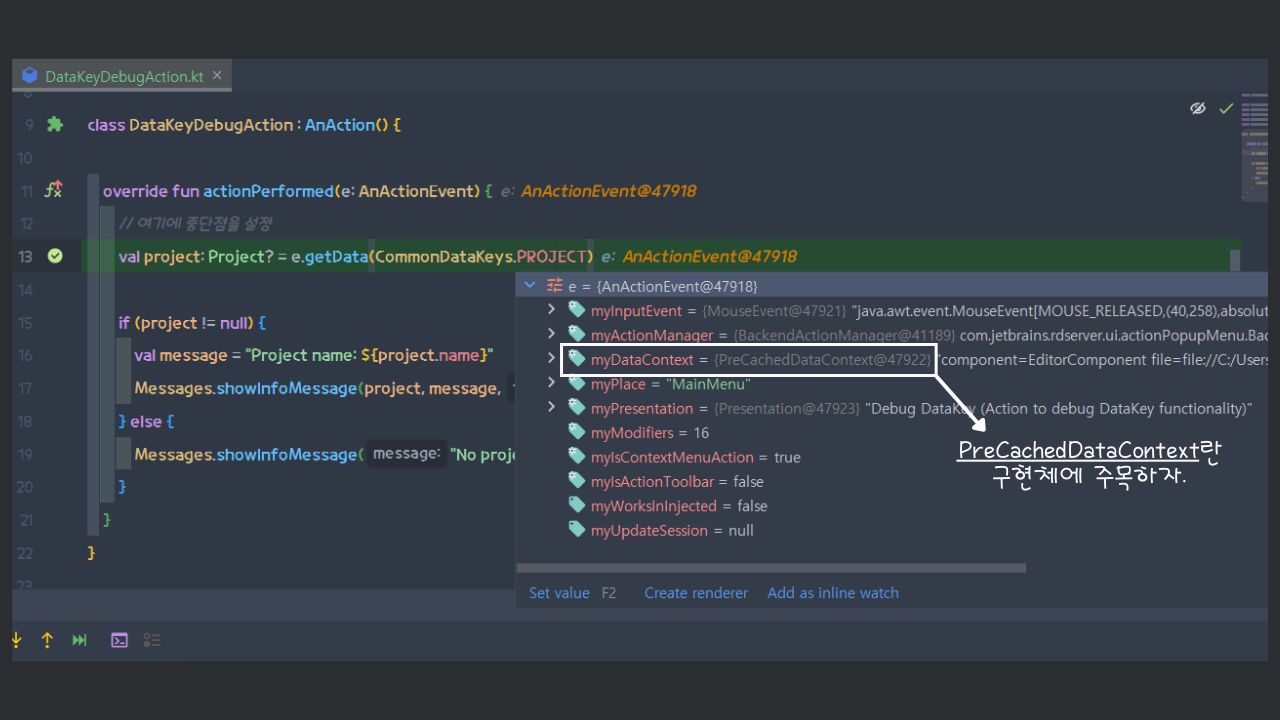
AnActionEvent의 필드를 살펴보니, DataContext는 PreCachedDataContext라는 인스턴스로 초기화되어 변수에 저장되어있는 것을 확인할 수 있다.
AnActionEvent #getData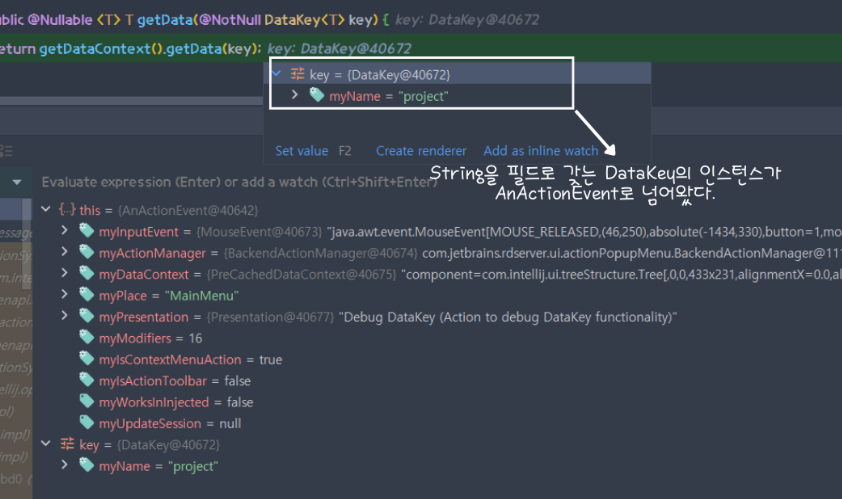

CommonDataKeys.PROJECT라는 객체는 컴파일 시점에 생성된 불변객체이다.
그리고 이 객체는 DataContext의 실제 구현체인 PreCachedDataContext의 getData를 호출할 때 Key로 사용된다.
변수 네이밍과 필드의 값으로 유추할 수 있는 내용은 아래와 같다.
"아!! 일단
CommonDataKeys.PROJECT내부의myName이라는 필드에는project라는 값이 할당되어있고, 이걸 실제로 데이터를 찾을 때 어디선가 사용하겠구나!"
이젠 실제로 PreCachedDataContext에서 어떻게 Key에 대한 데이터를 가져오는지 알아보자.
PreCachedDataContext #getData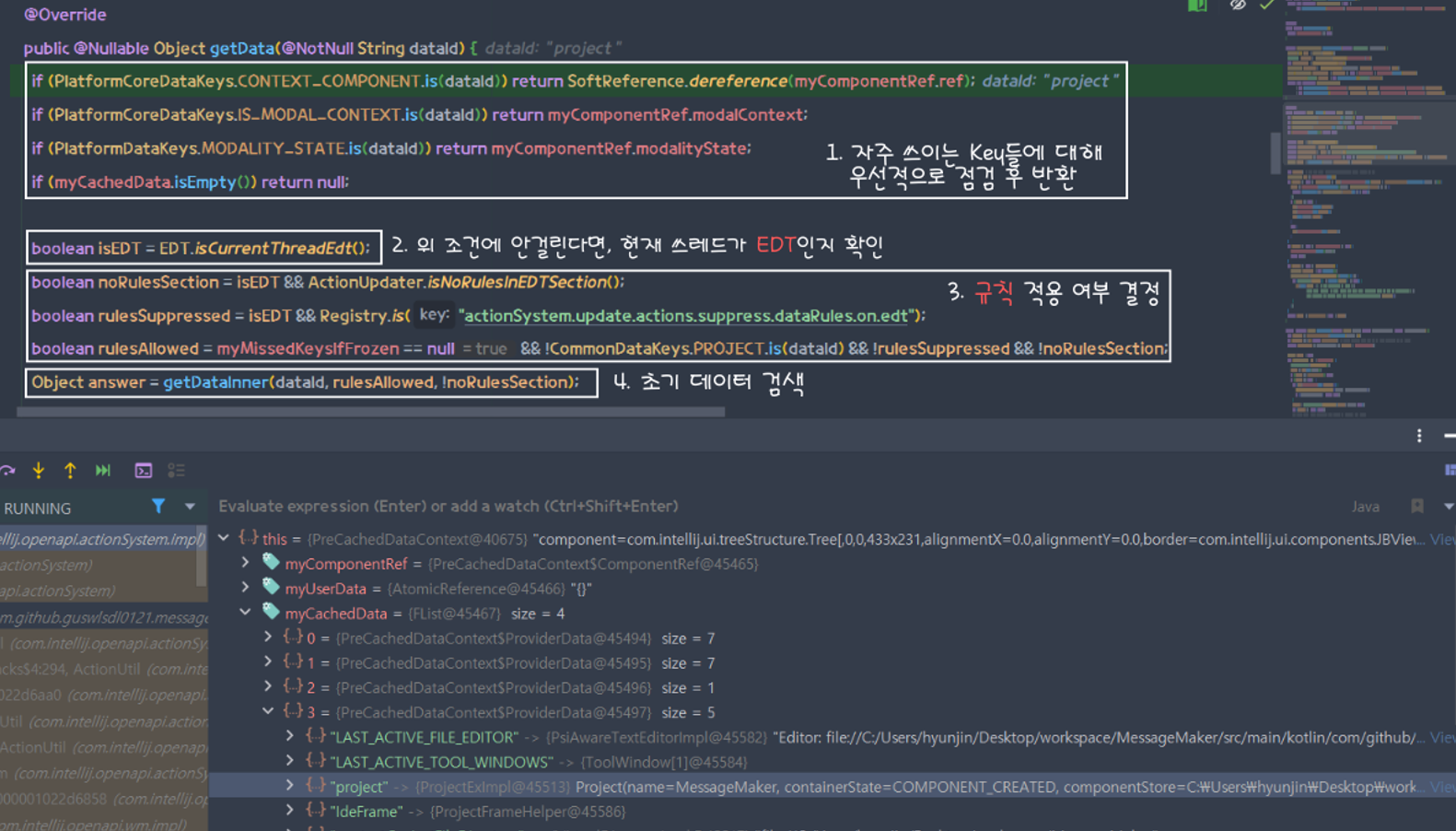
전체 코드는 여기에서 확인할 수 있다.
초반 단계에 대해서 요약하면 다음과 같다.
- 자주 사용되는 특정
Key에 대해 즉시 값을 반환한다. 해당되지 않으면 다음 단계로 진행한다.
- 현재 스레드가
EDT인지 확인한다.
EDT여부, 그리고 특정 조건을 고려하여데이터 검색 규칙적용 여부를 결정한다.
- 기본적인 데이터 검색을 수행한다.
여러 키워드가 등장하다보니, 다소 와닿지 않는 설명들이 많다. 우선 EDT라는 키워드와
데이터 검색 규칙에 대해서 알아볼 필요가 있을 것 같다.
4. EDT가 무엇이고, 왜 검사하는 것일까?
Swing에서의 EDT
EDT는 Event Dispatch Thread의 줄임말로, Java Swing Application에서 대부분의 UI 관련 작업을 담당하는 싱글 스레드를 의미한다. 이에 대해선 오라클의 공식문서에서도 자세히 설명하고 있으며, 이를 간단히 요약하면 다음과 같다.
EDT란?
EDT는 Swing과 관련된 모든 동작을 수행하는 특별한 싱글 스레드이다.
- Swing 객체의 대부분 메서드는 "thread-safe"하지 않다.
따라서, 여러 스레드에서 이들을 호출하면스레드 간섭이나메모리 일관성 오류같은 위험이 있다.
EDT에서 실행되는 코드는 일련의 짧은 작업들로 구성된다.
대부분은 이벤트 처리 메서드의 호출이며, 일부는 예약된 작업이다.
EDT의 작업은 빠르게 완료되어야 한다.
그렇지 않으면 처리되지 않은 이벤트가 쌓여 사용자 인터페이스가 응답하지 않게 된다.
쉽게 말해, EDT란 말 그대로 이벤트 전담 처리 싱글 Thread이며, 빠른 UI동작을 위해선 가벼운 작업만을 수행해야된다는 것이다.
IntelliJ 플랫폼에서의 EDT 활용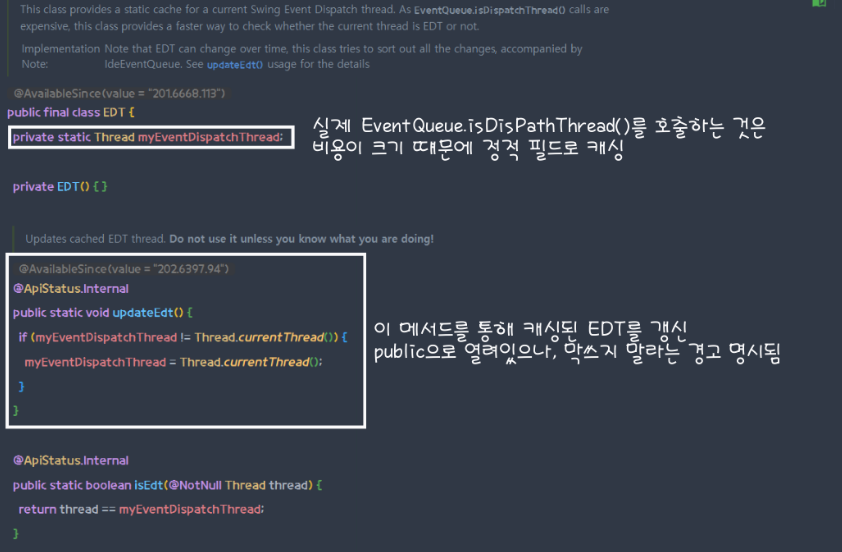
IntelliJ 플랫폼 역시 Swing의 EDT 개념을 사용하였다.
이때 IntelliJ에선 EDT 여부를 확인할 때 마다 EventQueue를 조회하는 것이 아닌 정적필드에 미리 캐싱을 하고 사용한다. EDT의 경우 싱글 스레드이기 때문에 한 개의 정적 쓰레드 필드로도 캐싱이 가능하다.
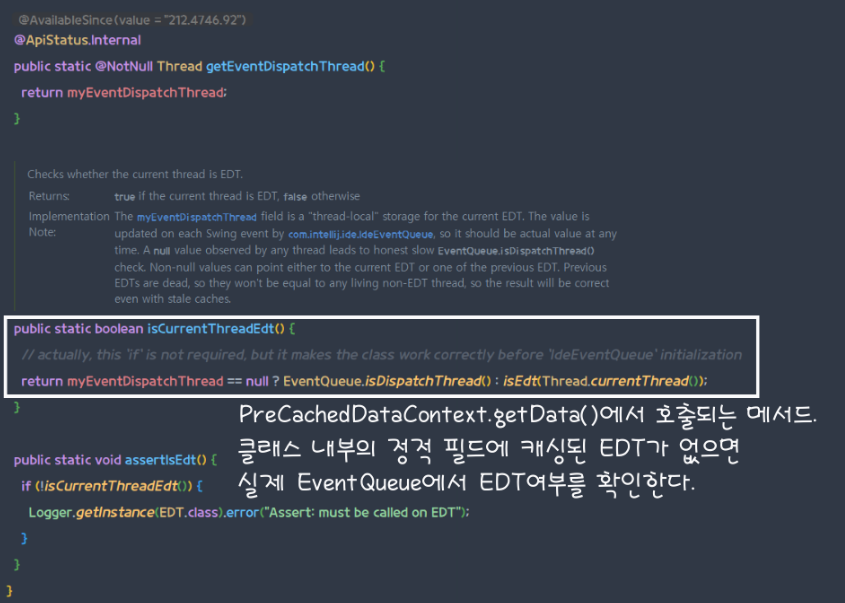
이러한 구현을 통해, 외부에서 isCurrentThreadEdt()호출 시 내부에 캐싱된 EDT를 우선적으로 현재 쓰레드와 비교하기 때문에, EventQueue.isDispatchThread()의 호출 수를 줄이는 최적화를 이루어내었다.
하지만, 언뜻 보았을 때도 updateEDT()가 적재적소에 호출되어 내부의 캐시가 현재의 상태를 잘 반영해야 될것으로 보인다. 이러한 주의사항은 첫번째 사진의 updateEDT()의 주석에도 잘 적혀있다.
5. EDT 여부 확인 이후의 동작
 우리가 살펴볼 시점은 현재 쓰레드가
우리가 살펴볼 시점은 현재 쓰레드가 EDT라는 것을 확인한 이후의 동작이다.
현재 쓰레드는 Tools > Debug DataKey라는 IntelliJ의 상단 항목을 "클릭"함으로써 발생하는 이벤트를 처리하기 때문에 EDT가 맞다.
만약 백그라운드에 Action이 일어나도록 구현했다면, 아마도 EDT가 아니었을 것이다.
ActionUpdater #isNoRulesInEDTSection
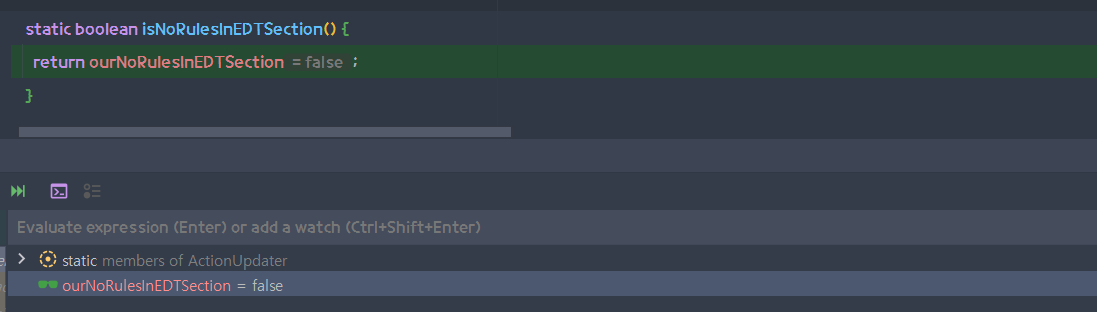
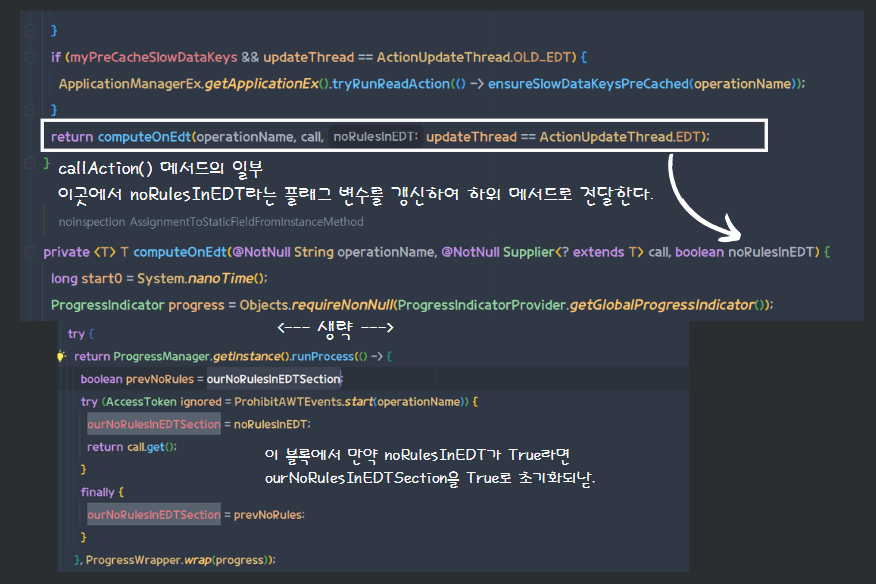
isRulesInEDTSection메서드를 보면 ActionUpdater의 ourNoRulesInEDTSection이라는 변수를 조회하여 반환한다.
이 변수에 대해서 대략 추적해보면, callAction 메서드가 ActionUpdateThread.EDT를 updateThread의 파라미터로 받았을 때 true가 되어 전달된다.
이로 인해 ourNoRulesInEDTSection는 true가 되어 외부에선 Rule 적용 불가 상태가 되는 것이다.
말이 약간 어려운데, 한줄로 요약하면 다음과 같다.
"Action이 발생했을 때 update되는 Thread가 EDT라면 Rule을 적용하지 않는다."
변경 중엔, 당연히 복잡한 데이터 검색 규칙을 적용한 연산을 수행할 수 없을 것이다.
따라서 규칙을 적용하는 것 대신 update에 더 초점을 맞춘다는 의미이다.
이 작업은 매우 일시적인 동작이며, 변경을 마치면 플래그가 다시 false가 되어 규칙을 적용할 수 있는 상태가 된다.
현재 시점은 EDT의 update가 일어나지 않기 때문에 데이터 검색 규칙을 적용할 수 있는 상태이다.
Registry.is("actionSystem.update.actions.suppress.dataRules.on.edt");
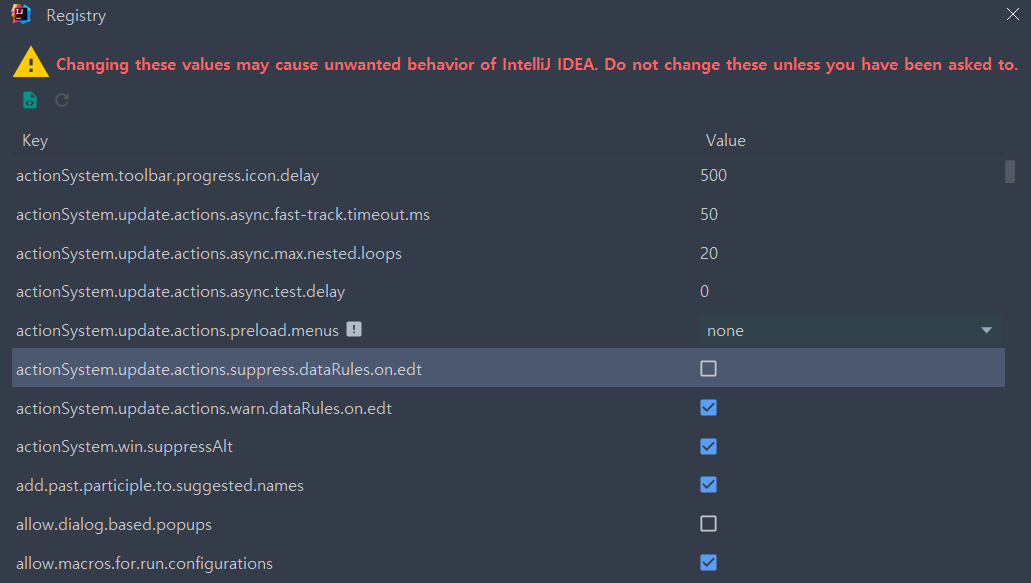
Registry라는게 문자열로 그대로 넘어가는 형태가 매우 생소했다.
하지만, 서칭을 해보니 Registry는 IntelliJ가 제공하는 "고급 설정"같은 느낌이었다.
화면을 보면 파라미터에 들어간 문자열이 그대로 Registry의 세팅에 존재하는 것을 알 수 있다.
직관적으로 "EDT가 데이터 검색 규칙을 적용하는 것을 억제하는 커스텀 옵션이 true인 경우"로 이해할 수 있다.
myMissedKeysIfFrozen == null
myMissedKeysIfFrozen는 "Frozen상태에서 누락된 Key를 저장하는 필드"이다.
기본적으로 Frozen이라는 상태에서 유효한 필드인데, 이 Field가 null이라는 것은 현재가 Frozen상태가 아니라는 것이다.
Frozen상태란 특정 시점의 DataContext의 상태를 스냅샷으로 고정시킨 것으로, 특정 시점에서의 성능 최적화를 위해 사용되는 상태라고 한다. 때문에, 모든 Key에 대한 데이터를 조회하는 것이 제한되는 상태를 의미한다.
!CommonDataKeys.PROJECT.is(dataId)
이외에 DataId가 프로젝트가 아닌 경우에 대해서도 제외한다. 프로젝트 키에 대해선 특별한 처리가 필요할 수 있기 때문이다.
이 부분에서 우리의 액션은 PROJECT 키를 사용하고 있기 때문에 이 조건에 해당된다.
즉, CommonDataKeys.PROJECT.is(dataId)가 true가 되어, 전체 조건에서 제외된다.
정리
Registry설정에서EDT의 데이터 규칙 억제가 비활성화되어 있고,- 현재
EDT에서Action Update가 진행 중이 아니며, DataContext가Frozen상태가 아니고,- 요청된 DataKey가
PROJECT가 아닐 때,
이 4개의 조건을 만족할 때, 데이터 검색 규칙을 적용하여 데이터를 찾는다.
이는 EDT의 성능을 위해 특정 상황에서 복잡한 연산을 피하기 위한 조건이라고 할 수 있다.
6. 데이터 탐색은 어떻게 이루어지지?
이제 대망의 마지막 단계이다.
DataContext에서 데이터를 꺼내기 위해서 많은 조건 검사 절차를 지나쳐왔다. 이젠 이런 조건에 맞게 데이터를 검색할 차례다.
디버깅 과정을 간단히 요약하자면 우리의 아주 간단한 액션은 EDT이며 특정 조건을 만족하는지 확인을 한 다음에 데이터 탐색을 시작한다는 것이다.
그렇다면, 이제 데이터가 어떻게 탐색되는지 살펴볼 필요가 있을 것이다.
PreCachedDataContext #getDataInner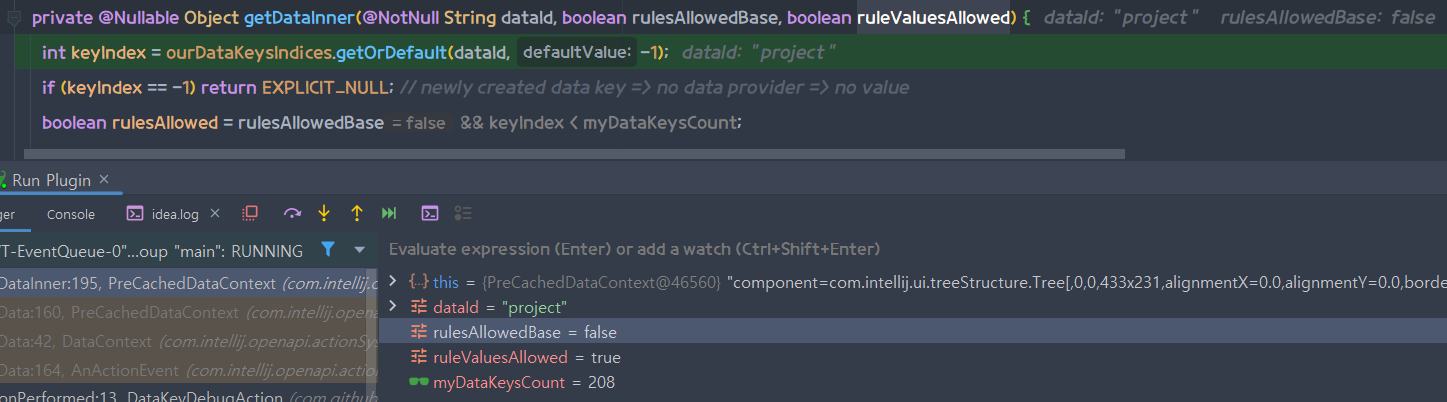
getDataInner로 넘어온 rulesAllowedBase는 false이고 ruleValuesAllowed는 true로 되어있다.
rulesAllowedBase가 false인 이유는 PROJECT가 특수하고 자주 쓰이는 키이기 때문이다. 만약 이 값이 true라면, 즉 캐싱된 데이터가 아니었다면 규칙을 적용해서 찾아야 했을 것이다.
ourDataKeysIndices 조회
먼저 DataKey에 대한 인덱스를 조회한다. ourDataKeysIndices는 ConCurrentHashMap으로 static 변수로 필드에 선언되어있다.
이 변수에는 자주 쓰이는 데이터 키의 인덱스가 저장되어있는 것으로 보이며, "project"라는 key에 대해선 10번 인덱스를 반환하고 있는 것을 볼 수 있다.
만약 키가 없으면, NULL을 반환한다.
규칙 적용여부 결정
이제 rulesAllowedBaseKey가 true이면서, Key에 대한 인덱스가 올바른 범위에 위치한다면(208보다 작다면), 데이터 검색 규칙을 적용한다.
우리의 예시에서는 DataKey가 "project"이기 때문에 데이터 검색 규칙을 적용하지 않았다. 이 말은 즉, 가까운 거리에 캐싱된 project데이터가 있다는 것을 의미하며, 불필요한 절차를 들어가지 않는다.
캐시된 DataProvider에서 데이터 조회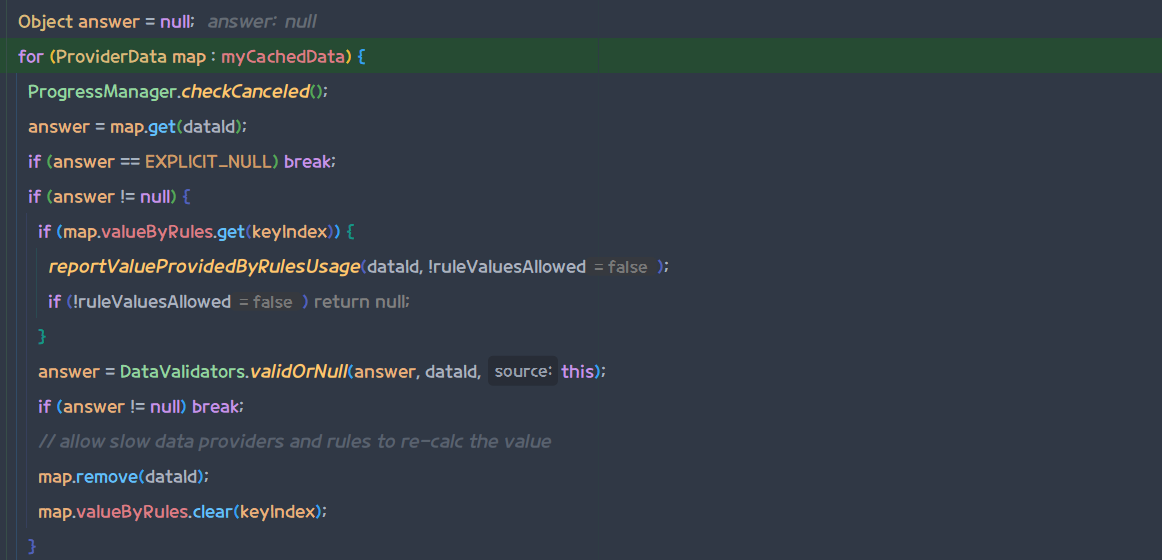
이제 실제 캐시된 데이터들 중 에서 DataKey에 대한 데이터를 찾아서 바로 반환하고, getData(CommonDataKeys.PROJECT)는 끝난다.
7. 총정리
이렇게 실제 인텔리제이에서는 어떻게 액션에 대한 데이터를 관리하고, 또 가져오는지에 대해서 알아보았다.
나의 예시에선 실제 어떠한 데이터 검색 규칙을 적용해서 탐색을 하는 케이스는 아니었다. 왜냐하면 자주 쓰이는 데이터들은 애초에 정적 필드로 캐싱이 되어있기 때문이었다.
하지만, 실제 캐싱을 적용한 PreCachedDataContext를 따라가며 많은 것들을 보고 배울 수 있었다.
- 정적필드를 활용해서 무거운 작업들에 대해서는 미리 캐싱해두는 방법들을 실제 코드를 보고 이해할 수 있었다.
EDT의 존재와 그 의의에 대해 알 수 있었다. 여기선 다루지 않았지만, UI 상호작용에서 비동기의 역할이 크다는 것도 체감할 수 있었다.
- 디버깅을 하면서 핵심적인 로직을 파악하는 능력을 기를 수 있었다.
- 잘 짜여진 오픈 소스를 보며, 코드를 해석하는 능력을 기를 수 있었다.
사실 이렇게 정리를 하면서 들었던 생각이 "너무 깊게 들어가는거 같은데?? 나는 몰라도 다른 사람들은 이거보고 하나도 모르겠다."라는 생각이 들었다.
하지만, 이런 글도 써봐야 글을 적는 능력이 향상된다고 생각한다. 이 부분에서 생각보다 깊게 정리하다보니 이틀 이상 시간을 쏟았던 것 같은데, 다음 글부터는 다시 내 플러그인 프로젝트에 관한 글을 다뤄보고자 한다.
