
- Stream, lambda에 대해서 설명하기
Stream
- 스트림이란 '데이터의 흐름' 이다.
- 람다의 사용이 가능한 스트림 -> 배열과 콜렉션을 함수형으로 처리할 수 있게 해준다.
- 병렬처리가 가능한 스트림 -> 쓰레드를 이용하여 많은 요소들을 빠르게 처리해준다.
특징
- Stream은 데이터를 변경하지 않는다
- Stream은 1회용 이다
- Stream은 지연 연산을 수행한다
- Stream은 병렬 실행이 가능하다
종류
| 종류 | 내용 |
|---|---|
Stream <T> | 범용 Stream |
IntStream | 값 타입이 Int인 Stream |
LongStream | 값 타입이 Long인 Stream |
DoubleStream | 값 타입이 Double인 Stream |
Stream 생성
Stream 인스턴스 생성하기
- 스트림은 배열 또는 컬렉션 인스턴스로 생성할수 있다.
1. 배열 스트림 -> Arrays.stream 메소드
String[] arr = new String[]{"a","b","c"};
Stream<String> stream = Arrays.stream(arr);
Stream<String> streamOfArrayPart = Arrays.stream(arr,1,3); // [1]~[2] 요소를 의미 : [b,c]2. 컬렉션 스트림 -> 인터페이스에 추가된 디폴트 메소드인 stream 를 활용한다.
List<String> list = Array.asList("a","b","c");
Stream<String> stream = list.stream();
Stream<String> parallelStream = list.parallelStream(); // 병렬 처리가 가능한 stream 객체3. 비어있는 스트림 -> Stream.empty()
public Stream<String> streamOf(List<String> list) {
return list == null || list.isEmpty() ? Stream.empty() : list.stream();
}메소드로 Stream 생성하기
Stream.builder()
- 스트림에 직접 원하는 값을 넣을 수 있다.
Stream<String> builderStream =
Stream.<String>builder()
.add("a").add("b").add("c")
.build(); // builderStream는 ["a", "b", "c"] 이다.Stream.generate()
- 인자는 없고 리턴값만 존재하는 함수형 인터페이스인
Supplier<T>에 해당하는 람다로 값을 넣을 수 있다.
Stream<String> generatedStream =
Stream.genertate(() -> "a").limit(5);
// ["a","a","a","a","a"]() -> "a"부분이Supplier<T>에 해당한다.
String.iterate()
- 초기값과 해당 값을 다루는 람다를 이용하여 스트렘에 들어갈 요소를 만든다.
Stream<Integer> iteratedStream =
Stream.iterate(30, n -> n+2).limit(5);
// [30,32,34,36,38]- 초기값이 30이고, 2씩 값이 증가하되 스트림의 크기를 5로 제한한다.
Stream 종류
기본 타입형 Stream
- 제네릭을 사용하지 않고 기본타입 스트림을 생성할 수 있다.
IntStream intStream = IntStream.range(1,5); // [1,2,3,4]
LongStream longStream = LongStream.rangeClosed(1,5); // [1,2,3,4,5]range: 마지막 인덱스를 포함하지 않는다.rangeClosed: 마지막 인덱스를 포함한다.
DoubleStream doubles = new Random().doubles(3);
// double형 난수 3개를 가진 스트림을 생성한다.Random클래스는 난수를 가지고 3가지 타입의 스트림을 생성한다.- IntStream, LongStream, DoubleStream
문자열 스트링을 이용하여 Stream 생성
- 각 문자 char를 IntStream으로 변환할 수 있다.
- char는 본질적으로 숫자이므로 가능하다.
IntStream charsStream = "Stream".chars();
// [83, 116, 114, 101, 97, 109]- 정규표현식으로 문자열을 자르고 각 요소를 스트림으로 만들 수 있다.
Stream<String> stringPattern =
Pattern.compile(", ").splitAsStream("A, B, C");
// ["A","B","C"]파일 Stream
- 자바 NIO의 Files클래스의 lines 메소드는 해당 파일의 각 라인을 스트링 타입의 스트림으로 만들어준다
Stream<String> lineStream =
Files.lines(Paths.get("file.txt"), Charset.forName("UTF-8"));병렬 Stream (parallel stream)
parallelStream 메소드로 병렬 Stream 생성
- 스트림 생성시
stream메소드 대신parallelStream메소드를 사용하여 병렬 스트림을 생성할 수 있다.
// 병렬 스트림 생성
Stream<Product> parallelStream = productList.parallelStream();
// 병렬 여부 확인하기
boolean isParallel = parallelStream.isParallel();- 병렬 스트림을 활용하여 각 작업을 쓰레드를 이용하여 병렬 처리할 수 있다.
boolean isMany = parallelStream
.map(product -> product.getAmount()*10)
.anyMatch(amount -> amount > 200);배열로 병렬 Stream 생성
Arrays.stream(arr).parallel();기타 병렬 Stream 생성
- 컬렉션과 배열이 아닌 경우
parallel메소드를 이용하여 병렬 스트림을 생성할 수 있다.
IntStream intStream = IntStream.range(1,150).parallel();
boolean isParallel = intStream.isParallel();병렬 Stream을 시퀀셜 Stream으로 되돌리기
sequential메소드를 활용하면 쓰레드를 이용한 병렬 처리가 불가능하다
IntStream intStream = intStream.sequential();
boolean isParallel = intStream.isParallel();Stream 연결하기
Stream.concat메소드로 두개의 스트림을 연결하여 새로운 하나의 스트림을 만들 수 있다.
Stream<String> stream1 = Stream.of("Java", "Scala", "Groovy");
Stream<String> stream2 = Stream.of("Python", "Go", "Swift");
Stream<String> concat = Stream.concat(stream1, stream2);
// [Java, Scala, Groovy, Python, Go, Swift]Stream 가공
-
필터링, 맴핑 등의 중간 작업을 통해 스트림 가공하기
-
API를 사용하여 원하는 데이터만 뽑는 작업을
중간작업이라고 한다.중간 작업은 중간 연산 명령어를 활용한다.

-
이 작업은 스트림을 리턴하므로
chaining이 가능하다.
-
-
기본 리스트
List<String> names = Arrays.asList("Eric", "Elena", "Java");filtering
- filter 메소드 : 스트림 내 요소들을 하나씩 평가 후 걸러내는 작업이다.
- 인자로 받는
Predicate는 boolean을 리턴하는 함수형 인터페이스 형태이다.
- 인자로 받는
Stream<T> filter(Predicate<? super T> predicate);- filter 작업으로
names리스트의 데이터중 "a"문자를 포함하는 데이터로만 이뤄진 스트림 생성하기
Stream<String> stream =
names.stream()
.filter(name -> name.contains("a");mapping
- map 메소드 : 스트림 내 요소들을 하나씩 특정 값으로 변환해준다.
- 값을 변환하기 위한 람다를 인자로 받는다.
<R> Stream<R> map(Function<? super T, ? extends R> mapper);- mapping 과정
- 스트림에 들어가있는 값이 input이 되고,
- map의 인자인 람다로 로직을 수행한 뒤,
- 그 output이 새로운 스트림에 담기게 된다.
Stream<Integer> stream =
productList.stream()
.map(String::toUpperCase);
// [ERIC, ELENA, JAVA]- Product 개체의 수량 꺼내오기
Stream<Integer> stream =
productList.stream()
.map(Product::getAmount);
// [23, 14, 13, 23, 13]
flatMap 메소드
- 인자를 mapper로 받는
flatMap메소드는 리턴타입이 Stream이다.- 새로운 스트림을 생성하여 리턴하는 람다를 넘겨야한다.
flatMap메소드는 중첩 구조를 한단계 제거하고 단일 컬렉션으로 만들어준다.
[[a],[b]]to[a, b]
List<List<String>> list =
Arrays.asList(Arrays.asList("a"),
Arrays.asList("b"));
// [[a],[b]] <- 중첩된 구조flatMap메소드를 활용하여 중첩 리스트 구조를 제거한 뒤 작업할 수 있다.
List<String> flatList =
list.stream()
.flatMap(Collection::stream)
.collect(Collectors.toList());
// [a, b] <- 중첩구조가 제거됨- Student 객체에 활용하기
students.stream()
.flatMapToInt(student ->
IntStream.of(student.getKor(),
student.getEng(),
student.getMath())) // 국,영,수 점수를 뽑아내어
.average().ifPresent(avg ->
System.out.println(Math.round(avg * 10)/10.0)); // 평균을 구한다.map메소드 만으로 한번에 할 수 없는 기능을flatMap메소드는 가능케 한다.
sorting
- sorted 함수
Stream<T> sorted();
Stream<T> sorted(Comparator<? super T> comparator);인자 없는 sorted
- 그냥 오름차순 정렬한다.
IntStream.of(14, 11, 20, 39, 23)
.sorted()
.boxed()
.collect(Collectors.toList());
// [11, 14, 20, 23, 39]인자로서 Comparator을 받는 sorted
- 역순정렬 예제
List<String> lang =
Arrays.asList("Java", "Scala", "Groovy", "Python", "Go", "Swift");
lang.stream()
.sorted() // 단순히 오름차순 정렬
.collect(Collectors.toList());
// [Go, Groovy, Java, Python, Scala, Swift]
lang.stream()
.sorted(Comparator.reverseOrder()) // 내림차순 정렬
.collect(Collectors.toList());
// [Swift, Scala, Python, Java, Groovy, Go]- 문자열 기준으로 정렬하기
- Comparator의
compare메소드 활용하기int compare(T o1, T o2)
- Comparator의
lang.stream()
.sorted(Comparator.comparingInt(String::length))
.collect(Collectors.toList());
// [Go, Java, Scala, Swift, Groovy, Python]
lang.stream()
.sorted((s1, s2) -> s2.length() - s1.length()) // int compare(T o1, T o2) 메소드 활용
.collect(Collectors.toList());
// [Groovy, Python, Scala, Swift, Java, Go]iterating
peek메소드 : 스트림 내의 요소들을 그냥 확인만 하는 메소드이다.- Consumer를 인자로 받는다.
- 스트림 내 요소들에 대해 각각 특정 작업을 수행하기때문에 결과에 영향을 미치지 않는다.
Stream<T> peek(Consumer<? super T> action);- 예제
int sum = IntStream.of(1, 3, 5, 7, 9)
.peek(System.out::println)
.sum();Stream의 결과
- 가공한 스트림으로 결과값은 최종 연산 명령어로 만들 수 있다.
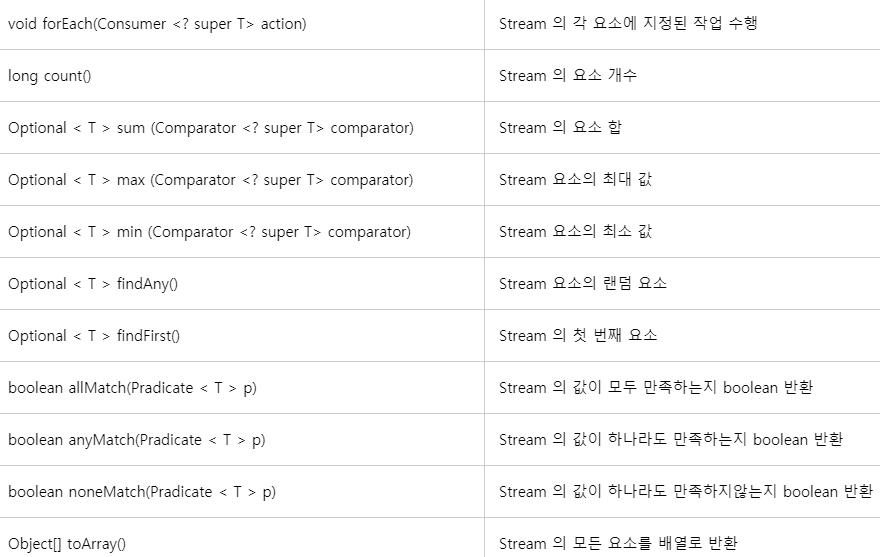
Calculating
- 스트림 API는 최소, 최대, 합, 평균과 같은 기본형 타입으로 결과를 만들어 낼 수 있다.
long count = IntStream.of(1, 3, 5, 7, 9).count();
long sum = LongStream.of(1, 3, 5, 7, 9).sum();- 만약, 스트림이 비어있다면
count,sum의 결과는 0이 된다.
OptionalInt min = IntStream.of(1, 3, 5, 7, 9).min();
OptionalInt max = IntStream.of(1, 3, 5, 7, 9).max();- 평균, 최대, 최소의 경우는 Optional을 이용하여 리턴한다.
Optional<T>클래스는 null 이 올 수 있는 값을 감싸는 래퍼 클래스로 참조하더라도 null 이 일어나지 않도록 해주는 클래스이다.ifPresent메소드를 이용해서 Optional 을 처리할 수 있다
DoubleStream.of(1.1, 2.2, 3.3, 4.4, 5.5)
.average()
.ifPresent(System.out::println);Reduction
reduce메소드 : 스트림은 이 메소드를 이용하여 결과를 만들어낸다.
// 1개 (accumulator)
Optional<T> reduce(BinaryOperator<T> accumulator);
// 2개 (identity)
T reduce(T identity, BinaryOperator<T> accumulator);
// 3개 (combiner)
<U> U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);reduce메소드는 3가지 파라미터를 받을 수 있다.- accumulator : 각 요소를 처리하는 계산 로직이다. 각 요소가 올 때마다 중간 결과를 생성하는 로직이다.
- identity : 계산을 위한 초기값이다. 스트림이 비어서 계산할 내용이 없어도 이 값은 리턴한다.
- combiner : 병렬 스트림에서 나눠 계산한 결과를 하나로 합치는 동작을 하는 로직이다.
accumulator 파라미터
Optional<T> reduce(BinaryOperator<T> accumulator);BinaryOperator<T>: 같은 타입의 인자 두개를 받아 같은 타입의 결과를 반환하는 함수형 인터페이스이다.
OptionalInt reduced =
IntStream.range(1, 4) // [1, 2, 3]
.reduce((a, b) -> {
return Integer.sum(a, b);
});
// 결과는 1+2+3 = 6이 된다.identity 파라미터
T reduce(T identity, BinaryOperator<T> accumulator);- 예제
int reducedTwoParams =
IntStream.range(1, 4) // [1, 2, 3]
.reduce(10, Integer::sum);
// 결과는 10 + 1+ 2 +3 = 16 이 된다.
// 10은 초기값이다.combiner 파라미터
<U> U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);- 예제
Integer reducedParams = Stream.of(1, 2, 3)
.reduce(10, // identity
Integer::sum, // accumulator
(a, b) -> {
System.out.println("combiner was called"); // combiner는 실행되지 않는다
return a + b;
});- combiner는 실행되지 않는다
- Combiner 는 병렬 처리 시 각자 다른 쓰레드에서 실행한 결과를 마지막에 합치는 단계입니다.
- 따라서 병렬 스트림에서만 동작하기 때문에 해당 예제에서는 실행되지 않는다.
- 병렬 스트림에서 활용해 보자
Integer reducedParallel = Arrays.asList(1, 2, 3)
.parallelStream()
.reduce(10, // identity
Integer::sum, // accumulator
(a, b) -> {
System.out.println("combiner was called");
return a + b;
});
// 결과
combiner was called
combiner was called
36- 36이라는 결과가 나온 이유
- accumulator가 총 3번 동작하기 때문이다.
- 초기값 identity를 더한 3개의 값 : 11,12,13 에 대해서 계산을 수행한다.
- combiner는 2번 호출된다.
- combiner는 identity 와 accumulator 를 가지고 여러 쓰레드에서 나눠 계산한 결과(11,12,13)를 합치는 역할을 수행한다.
- 12+13 = 25 -> 25 + 11 = 36 이 된다.
- accumulator가 총 3번 동작하기 때문이다.
Collecting
collect메소드 : 또다른 종료 작업Collector타입의 인자를 받아서 처리한다.- 스트림의 요소를 수집하여 요소를 그룹화 하거나 결과를 담아 반환하는데 사용한다.
- 예제
List<Product> productList =
Arrays.asList(new Product(23, "potatoes"),
new Product(14, "orange"),
new Product(13, "lemon"),
new Product(23, "bread"),
new Product(13, "sugar"));Collectors.toList()
- 스트림에서 작업한 결과를 담은 리스트로 반환한다.
List<String> collectorCollection =
productList.stream()
.map(Product::getName)
.collect(Collectors.toList());
// [potatoes, orange, lemon, bread, sugar]
- map으로 각각의 요소의 이름을 가져온뒤 ->
Collectors.toList()를 통해 리스트로 결과를 가져온다.
Collectors.joining()
- 스트림에서 작업한 결과를 하나의 스트링으로 이어 붙인다
String listToString =
productList.stream()
.map(Product::getName)
.collect(Collectors.joining());
// potatoesorangelemonbreadsugarCollectors.joining()메소드는 3개의 인자를 받을 수 있다.- delimiter : 각 요소 중간에 들어가 요소를 구분시켜주는 구분자
- prefix : 결과 맨 앞에 붙는 문자
- suffix : 결과 맨 뒤에 붙는 문자
String listToString =
productList.stream()
.map(Product::getName)
.collect(Collectors.joining(", ", "<", ">"));
// <potatoes, orange, lemon, bread, sugar>Collectors.averageingInt()
- 숫자 값(Integer value )의 평균(arithmetic mean)을 낸다.
Double averageAmount =
productList.stream()
.collect(Collectors.averagingInt(Product::getAmount));
// 17.2Collectors.summingInt()
- 숫자값의 합(sum)을 낸다
Integer summingAmount =
productList.stream()
.collect(Collectors.summingInt(Product::getAmount));
// 86
Integer summingAmount =
productList.stream()
.mapToInt(Product::getAmount) // mapToInt 메소드를 사용한 간결한 표현
.sum(); // 86Matching
boolean anyMatch(Predicate<? super T> predicate);
boolean allMatch(Predicate<? super T> predicate);
boolean noneMatch(Predicate<? super T> predicate);-
조건식 람다 Predicate 를 받아서 해당 조건을 만족하는 요소가 있는지 체크한 결과를 리턴한다.
- anyMatch : 하나라도 조건을 만족하는 요소가 있는지
- allMatch : 모두 조건을 만족하는지
- noneMatch : 모두 조건을 만족하지 않는지
-
예제
List<String> names = Arrays.asList("Eric", "Elena", "Java");
boolean anyMatch = names.stream()
.anyMatch(name -> name.contains("a")); // true
boolean allMatch = names.stream()
.allMatch(name -> name.length() > 3); // true
boolean noneMatch = names.stream()
.noneMatch(name -> name.endsWith("s")); // trueIterating : forEach
forEach: 스트림 내 요소를 돌면서 실행되는 최종 작업- 보통 결과를 출력할 떄 사용된다
names.stream().forEach(System.out::println);