
- https://github.com/JaeYeopHan/Interview_Question_for_Beginner/tree/master/Database#%EC%A0%95%EA%B7%9C%ED%99%94%EC%97%90-%EB%8C%80%ED%95%B4%EC%84%9C
- https://mangkyu.tistory.com/110
- https://itwiki.kr/w/%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4_%EC%A0%95%EA%B7%9C%ED%99%94
정규화는 데이터의 중복방지, 무결성을 충족시키기 위해 데이터베이스를 설계하는 것을 의미한다.
이상(Anomaly) 현상
정규화를 거치지 않은 데이터베이스에서 발생할 수 있는 현상이다.
이상 현상 종류
삽입 이상(Insertion Anomaly)
데이터 삽입 시 의도와 다른 값들도 삽입됨삭제 이상(Deletion Anomaly)
데이터 삭제 시 의도와 다른 값들도 연쇄 삭제됨갱신 이상(Modification Anomaly)
속성값 갱신 시 일부 튜플만 갱신되어 모순 발생
정규화란?
정규화는 관계형 데이터베이스에서 중복을 최소화하기 위해 데이터를 구조화하는 작업이다. 다시말해, 불만족스러운나쁜 Relation의 Attribute를 나누어좋은 작은 Relation으로 분해하는 작업이다.정규화 작업을 거치면
정규형을 만족하게 된다.
정규형이란 특정 조건을 만족하는 Relation의 Schema의 형태를 말하여제 1 정규형,제 2 정규형, .. 등이 존재한다.
나쁜 Relation
Entity를 구성하는 Attribute 간
함수적 종속성 (Functional Dependency)를 판단한다. 판단된 함수적 종속성은 좋은 Relation 설계의 정형적 기준으로 사용된다.만족하는 함수적 종속성에 따라 정규형이 정의되고, 그 정규형을 만족하지 못하는 Relation을 나쁜 Relation으로 파악한다.
함수적 종속성
함수적 종속성 (Functional Dependency)이란 Attribute 데이터들의 의미와 Attribute들 간의 상호 관계로부터 유도되는 제약조건의 일종이다.X와 Y를 임의의 Attribute 집합이라고 할 때, X의 값이 Y의 값을 유일하게(Unique) 결정하는 경우
X는 Y를 함수적으로 결정한다.라고 한다.함수적 종속성은 실세계에서 존재하는 Attribute들 사이으이 제약조건으로부터 유도된다. 또한 각종 추론 규칙에 따라서 Attribute들간의 함수적 종속성을 판단할 수 있다.
모든 정규형이 만족해야할 조건
- 분해의 대상인
분해 집합 D는 무손실 조인을 보장해야 한다.
분해 집합 D는 함수적 종속성을 보존해야 한다.
목적
- 중복을 배제하여 삽입, 삭제, 갱신 이상의 발생을 방지
- 데이터 삽입 시 릴레이션을 재구성할 필요성 감소
정규형
📌제 1정규형
테이블의 컬럼(도메인)이 원자값(Atomic Value, 하나의 값)을 갖도록 테이블을 분해하는 것
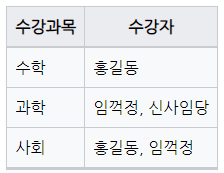
수강자 Attribute가 원자값이 아니다.
- 발생할 수 있는 이상
갱신이상
홍길동이사회->역사로 수강과목을 변경할 경우, 임꺽정의 수강과목까지 변경된다.UPDATE 과목 SET 수강과목 = '역사' WHERE 수강과목 = '사회' AND 수강자 = '홍길동'
삭제이상
임꺽정이과학수강과목을 삭제하면, 심사임당의 수강과목 정보까지 삭제된다.DELETE FROM 과목 WHERE 수강과목 = '과학' AND 수강자 = '임꺽정'
👇
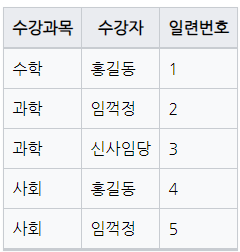
Attribute를 원자값으로 분해하고, Tuple로 구분하고, 다른 키를 추가한다.
📌제 2 정규형
제1 정규화를 진행한 테이블에 대해
부분적 함수 종속을 제거하여완전 함수 종속을 만족하도록 테이블을 분해하는 것
완전 함수 종속
기본키의 부분집합이 결정자가 되어선 안된다는 것을 의미한다.- key가 아닌 각각의 rows들이 후보키에 의해 결정되는 Relation 형태를 의미한다.
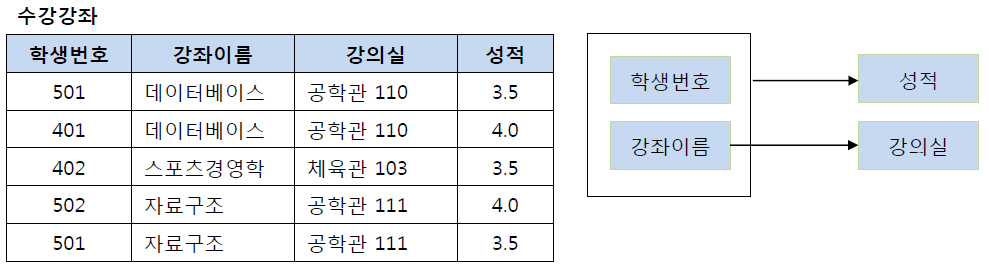
(학생번호, 강좌이름)라는 복합키가 기본키이다.
이 복합키는성적이란 Attribute를 결정한다.
복합키의 부분집합인(강좌이름)은 동시에강의실이란 Attribute를 결정한다.
- 발생할 수 있는 이상
삽입이상
데이터베이스 강좌를 수강하는 학생을 추가할 때, 불필요한 중복 정보 (강의실)가 삽입된다.갱신이상
데이터베이스의 강의실이 변경된 경우, 1,2번째 tuple의 강의실 정보를 모두 찾아서 변경하지 않으면 모순이 발생한다.삭제이상
402번 학생이 자퇴를 하여 삭제할 경우, 스포츠경영학의 강의실 정보가 사라진다.
👇
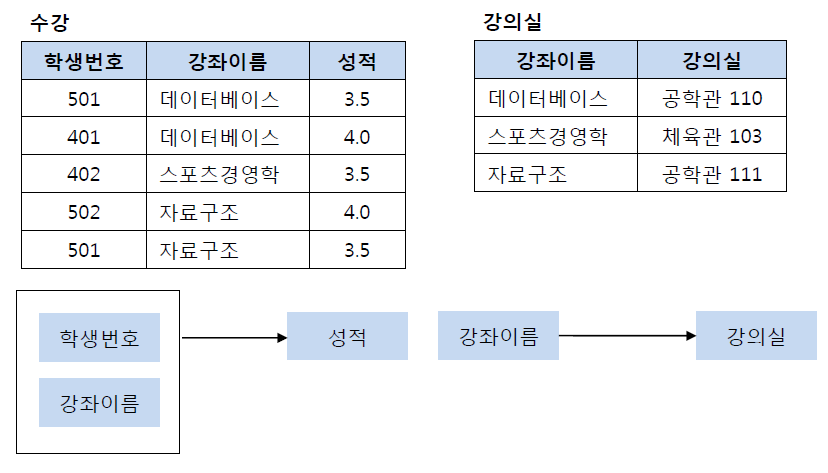
(학생번호, 강좌이름)라는 기본키(복합키)를 가지는수강 테이블과(강좌이름)이라는 기본키를 가지는강의실 테이블으로 분해하여 제 2정규형을 만족시킨다.
📌제 3 정규형
제2 정규화를 진행한 테이블에 대해
이행적 함수 종속을 없애도록 테이블을 분해하는 것
이행적 함수 종속
X -> Y,Y -> Z가 성립할 때X -> Z가 성립하는 것을 말한다.
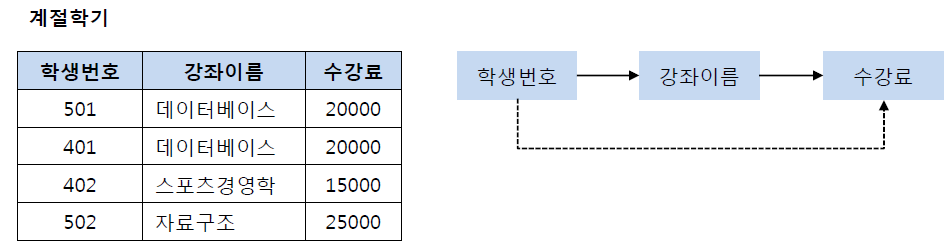
(학생번호)는(강좌이름)을 결정하고 있고,(강좌이름)은(수강료)를 결정하고 있다.
- 해당 Relation의 Attribute들은 이행적 함수 종속 관계를 만족한다
- 발생할 수 있는 이상
삽입이상
데이터베이스 강좌를 수강하는 학생을 추가할 때, 불필요한 중복 정보 (수강료)가 삽입된다.갱신이상
데이터베이스의 수강료가 변경된 경우, 1,2번째 tuple의 수강료 정보를 모두 찾아서 변경하지 않으면 모순이 발생한다.삭제이상
402번 학생이 자퇴를 하여 삭제할 경우, 스포츠경영학의 수강료 정보가 사라진다.
👇
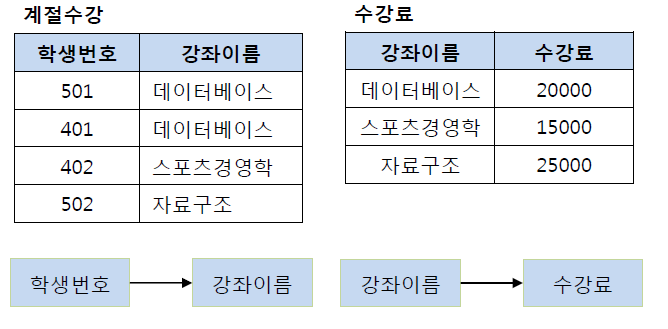
(학생 번호, 강좌 이름) 테이블과 (강좌 이름, 수강료) 테이블로 분해한다.
📌BCNF(Boyce-Codd) 정규형
제3 정규화를 진행한 테이블에 대해 모든 결정자가 후보키가 되도록 테이블을 분해하는 것
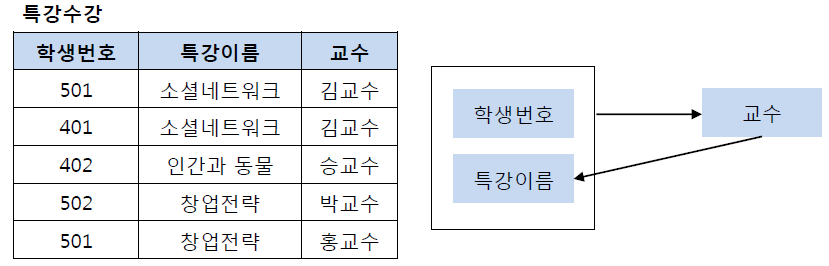
특강수강 Table의 기본키는(학생번호, 특강이름)이고교수 Attribute를 결정하고 있다.
동시에교수 Attribute는 기본키의 부분집합인(특강이름)을 결정하고 있다.
교수 Attribute는(특강이름)을 결정하는 결정자이지만, 후보키가 아니다.
후보 키: 관계형 데이터베이스의 관계형 모델에서 슈퍼 키 중 더 이상 줄일 수 없는(irreducible) 형태를 가진 것을 말한다.
- 행의 식별을 위해 필요한 특성 또는 그 특성들의 집합이다. 후보 키는 행의
식별자라고 생각할 수도 있다.- 발생할 수 있는 이상
삽입이상
501번 학생이 인간과 동물 특강을 수강할 경우, 불필요한 정보(교수)가 한번 더 삽입된다.갱신이상
소셜네트워크 담당 교수가 변경될 경우, 1,2번 tuple의 교수 정보를 모두 찾아서 변경하지 않으면 모순이 발생한다.삭제이상
402번 학생이 자퇴를 하여 삭제할 경우, 인간과 동물 과목을 승교수가 담당하고 있다는 정보가 사라진다.
👇
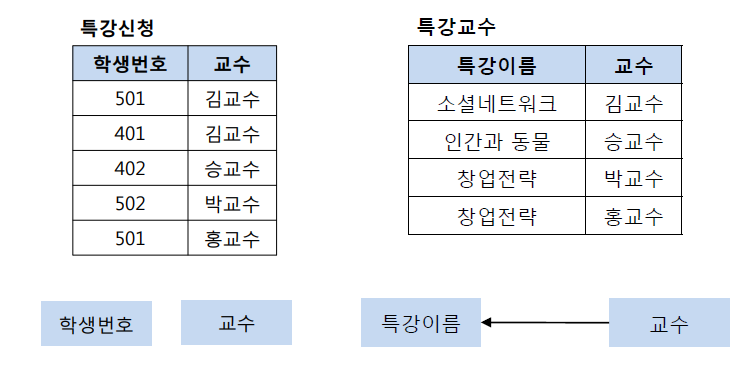
BCNF 정규화를 만족시키기 위해서
특강신청 테이블과특강교수 테이블로 분해한다.
정규화의 장점
- 데이터베이스 변경 시
이상 (Anomaly) 현상들을 제거한다.
- 데이터베이스 구조에서 새로운 데이터 형을 추가할 경우, 구조에 대한 병경을 최소화할 수 있다.
이는 데이터베이스와 연동된 응용 프로그램에 최소한의 영향만 미쳐 응용 프로그램의 생명을 연장시킨다.
정규화의 단점
Relation 분해로 인해 JOIN 연산이 많아진다. 이로 인해 질의에 대한 응답 시간이 느려질 수 있다. (무조건 느려지는게 아니다!)
데이터의 중복 속성을 제거하고 결정자에 의해 동일한 의미의 일반 속성이 하나의 테이블로 집약되므로 한 테이블의 데이터 용량이 최소화되는 효과가 있다.
그러므로 무조건 느려진다는게 아니라 데이터를 처리할 때 속도가 빨라질 수도 있고 느려질 수도 있는 특성을 가진다.
정규화의 단점에 대한 대응책
조회하는 SQL 문장에서 JOIN 연산이 많이 사용되어 성능저하가 나타나는 경우
반정규화/비정규화를 적용할 수 있다.
반정규화/비정규화 (De-Normalization)
시스템의 성능 향상 및 개발과 운영의 단순화를 위해서
정규화된 엔티티, 속성, 관계를 중복 통합, 분리하여 의도적으로 정규형을 위배한 데이터 구조로 만드는 행위이다.
반정규화의 대상
- 자주 사용되는 테이블에서 항상 일정 범위만 조회하는 경우
- 테이블에 대량 데이터가 있고, 대량의 범위를 자주 처리하는 경우
- 테이블에 지나치게 JOIN 연산을 많이 사용하게 되어 데이터 조회시 기술적으로 어려울 경우
반정규화 주요 기법
테이블 합병
논리적으로 구분된 엔티티들을 하나의 테이블로 합친다.
- Join 없이 하나의 테이블로 관리하는 것이 성능 측면에서 유리할 수 있다.
중복 칼럼 추가
게시판 테이블에 회원 정보를 일부 저장한다.
- 일부 중복 데이터만으로 Join 없이 처리한다면 더 유리할 수 있다.
계산된 칼럼 추가
평균치, 계량값을 특저 필드에 추가한다.
- 바로바로 계산할 수 있는 값이지만, 자주 참조되는 값이라면 DB에 저장해두는 것이 유리할 수 있다.
코드 명칭 칼럼 추가
남자 여자를 F, M이 아니라 그냥 남자, 여자로 저장한다.
- 출력 시 '남자' '여자'로 보여줘야 하는 경우 연산을 줄일 수 있다.
반정규화 주의점
- 과도한 반정규화는 데이터의 무결성을 깨뜨린다.
- 또한 입력, 수정, 삭제의 질의문에 대한 응답 시간이 늦어진다.
- 반드시 정규화 수행 후 반정규화 수행해야한다.
다음에는 key에 대해서 정리할 것
