
- https://www.youtube.com/watch?v=tepgJEgit-E
- https://github.com/ksundong/backend-interview-question
- https://github.com/JaeYeopHan/Interview_Question_for_Beginner/tree/master/OS#%ED%94%84%EB%A1%9C%EC%84%B8%EC%8A%A4-%EB%8F%99%EA%B8%B0%ED%99%94
프로세스 동기화
- 협력하는 프로세스들 사이의 실행 순서 규칙을 보장한다.
- 공유되는 데이터의 일관성(Consistency)을 보장한다.
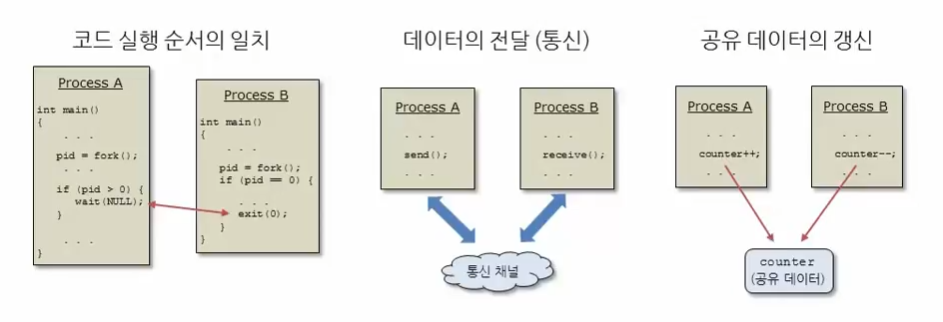
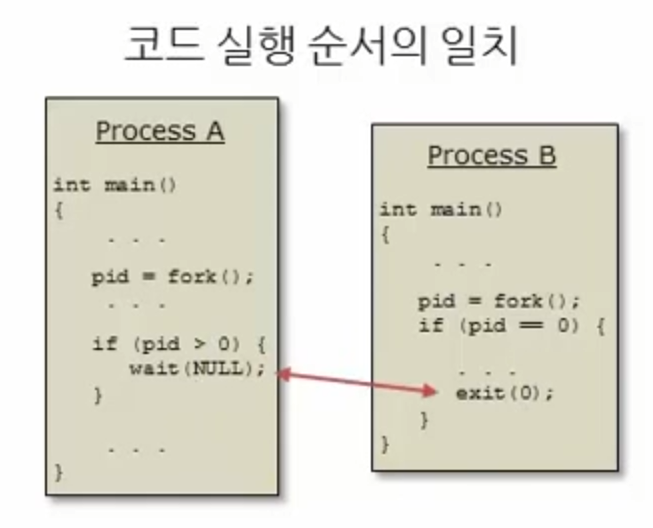
fork를 통해 자식 프로세스를 생성했을 때
자식 프로세스의exit(0)함수가 실행하는 시점과
부모 프로세스의wait(NULL)함수가 리턴되는 시점이 맞춰진다.
- exit 실행 -> wait 실행 순서를 일치시켜준다
= 두 프로세스의 동기화를 이룬다.- 데이터 통신 과정에서
프로세스 A의send와 프로세스 B의recieve가 각각 코드에서 실행되는 시점을 일치시키기 위해 (동기화를 위해) 어느 한 쪽에서 대기해야한다.
- 프로세스들 사이의 실행 순서를 맞춘다.
- 여러 프로세스가 독자적으로 공유 변수
counter의 값을 변경하게 되면 해당 공유 변수는 원하는 값을 갖지 않게된다.
부모 프로세스는 자식 프로세스가 종료되는 시점을 알아야한다. 어떻게 알 수 있을까?
부모 프로세스는 메모리 상의 값을 체크하고 자식 프로세스는 종료 시점에 그 값을 변경한다. 값을 체크하는 과정과 값을 변경하는 과정이 공유 변수에 접근하는 것이다.
⇨ 컴퓨터 시스템에서 말하는 프로세스 동기화는 공유되는 데이터의 일관성을 맞추는 과정이다.
공유되는 데이터의 일관성 문제
- 생산자 프로세스
while(true) {
while (counter == BUFFER_SIZE)
; // do nothing
buffer[in] = nextProduced;
in = (in + 1) % BUFFER_SIZE;
counter++;
}
counter++;부분을 기계어로 변환하면register1 = counter register1 = register1 + 1 counter = register1
- 소비자 프로세스
while(true) {
while (counter == 0)
;
nextProduced = buffer[out];
out = (out + 1) % BUFFER_SIZE;
counter--;
}
counter--;부분을 기계어로 변환하면register2 = counter register2 = register2 - 1 counter = register2
이 두개의 프로세스는 스케쥴링을 거친다.
예를 들면 생산자 프로세스가 실행을 하다 중단하고 소비자 프로세스가 실행하게 된다.
여기서 문제는 스케쥴링으로 인해 실행을 멈추는 단위가 소스 레벨에서의 코드 한 줄이 아니라는 점이다. CPU에서 실행하는 한 줄이 그 단위가 된다.
예를 들어 counter의 초기값이 5일 때,
생산자 프로세스에서 1증가 시키고, 소비자 프로세스에서 1감소 시키는 과정을 거친다고 예상해보자. 예상대로 이뤄진다면 counter의 결과값은 5가 된다.
하지만, 생산자 프로세스에서 counter 값을 1증가 시키려는 찰나에 스케쥴링이 일어나
// 레지스터1에 카운터 값 5를 저장하고
register1 = counter
// 레지스터1값을 1증가 시키려는 찰나에 스케쥴링이 일어난다.
// (카운터 값은 여전히 5이다.)
register1 = register1 + 1
counter = register1CPU 점유권이 소비자 프로세스에 간 경우
// 카운터 값은 아직 5이다.
register2 = counter
register2 = register2 - 1
counter = register2
// 정사적으로 위 과정을 마치면, 카운터 값은 4가 된다.counter의 결과값은 5가 아닌 4가 된다.
⇨ 데이터의 일관성이 깨진다.
데이터의 일관성이 깨지는 이유
1. 두 프로세스가 공유 변수에 접근하고
2. Context Switching이 일어나는 시점을 알 수 없기 때문이다.
- 생산자 프로세스, 소비자 프로세스가 같은 레지스터를 사용하더라도 Context Switching이 일어나면 레지스터에 각자의 PCB에 저장된 값이 채워진다.
이런 상황에서 어떤 방법으로 데이터 일관성을 유지할 수 있을까?
생산자 프로세스에서
counter변수 값을 증가시키는 로직을 완료하기 전까지 소비자 프로세스에서counter변수에 접근하지 못하도록 보장시켜준다.
그런데 왜 이게 시간을 맞춰준다는 의미로써 동기화일까?
counter값을 증가시키는 로직을 완료하는 시점과
counter값을 감소시키는 로직을 시작하는 시점을 일치시킨다는 점(시간을 맞춘다는 점)에서 동기화라고 할 수 있다.
- 스케쥴링에 의해 두 로직의 실행시점이 겹칠 수 있지만, 겹쳐져서 실행되는 것을 허용하지 않는다.
경쟁 조건
경쟁 조건(Race Condition)
여러 프로세스가 공유 데이터를 동시에 조작할 때, 실행의 특정 순서에 따라 데이터의 결과가 달라지는 상황이다.
프로세스 동기화가 필요하다- 공유 데이터 조작을
원자적 연산(Atomic Operation)으로 처리하면 경쟁 조건은 발생하지 않는다.
경쟁 조건은 공유 데이터 조작 연산 과정이 비원자적이기 때문에 발생한다.
원자적 연산(Atomic Operation)
어떤 연산의 결과가 외부의 간섭에 관계없이 전체가 완료되든지 전혀 실행되지 않은 상태로만 나타나는 연산이다. (All or Nothing)
- CPU 레벨에서 가상적으로 쪼갤 수 없는 원자적 연산인 것 처럼 공유 데이터를 조작하게 되면
공유되는 데이터의 일관성 문제를 해결할 수 있다. - 원자적 연산이 필요한 예
counter변수를 조작하는 생산자, 소비자 프로세스- 데이터베이스 시스템의 트랜잭션 처리
임계 영역(Critical Section)
경쟁 조건이 발생할 수 있는 프로그램 코드 부분이다.
- 다른 프로세스와 공유하는 변수나 파일을 변경하는 부분이다.
- 임계 영역을 포함하는 프로그램의 구성은 다음과 같다.
- Entry Section : 임계 영역 진입 허가 요청 부분
- Critical Section
- Exit Section
- Remainder Section

임계 영역(Critical Section)을 변경할 수 없기 때문에
Entry Section과Exit Section에 동기화를 이룰 수 있는 코드를 삽입해야 한다.
임계 영역 문제
임계 영역을 안전하게 처리하는 문제를 말한다.
- 임계 영역 문제를 해결하는 방법
- 한번에 하나의 프로세스만 임계영역을 실행하도록 보장해야 한다.
- 적절한
동기화(synchronization)기법을 설계하여 프로세스들 사이의 실행 흐름을 제어(blocking)한다. 이는 임계 영역 전체를 원자적으로 처리하는 효과를 가진다.
- 적절한
- 한번에 하나의 프로세스만 임계영역을 실행하도록 보장해야 한다.
임계 영역 문제 해결을 위한 요구 조건
다음 세가지 조건을 만족하는 코드를 Entry Section과 Exit Section에 삽입해야만 동기화 문제를 해결할 수 있다.
1. 상호 배제(Mutual Exclusion)
어떤 프로세스가 자신의 임계 영역 내에서 실행 중일 때
다른 프로세스는 각자의 임계 영역으로 진입할 수 없다
- 한 프로세스가 임계 영역에서 실행중이면 다른 프로세스를 밀쳐낸다.
- 임계 영역에서 한 순간에는 하나의 프로세스만 동작하게 한다.
- 공유 flag 변수를 사용하는 등 상호 배체 조건을 만족시킬 수 있다.
- 임계 영역 문제를 해결하는 주된 방법이다.
우선순위 스케쥴링에서
상호 배제조건만 만족시키게 되면
우선순위가 낮은 프로세스는 무한정 대기하게 되는 불공정한 상황이 발생할 수 있다.
- 단편적인 동기화 문제 해결 방법은
상호 배제조건이지만 - 운영체제의 전체적인 동작을 고려할 때, 이론적으로 동기화 문제를 해결하기 위해서
진행,유한 대기조건이 필요하다.
2. 진행(Progress)
임계 영역에서 실행중인 프로세스가 없다면
임계 영역으로 진입하려는 프로세스들 중 하나는 유한한 시간 내에 진입할 수 있어야 한다.
- 임계 구역에 접근하려는 프로세스가 없음에도 불구하고
잘못된 코드로 인해 접근할 수 없는 상황이 발생하면 안된다.
3. 유한 대기(Bounced Waiting)
한 프로세스가 임계 영역에 대한 진입을 요청한 후에는
다른 프로세스의 임계 영역 진입이 유한한 횟수로 제한되어야 한다.
즉, 임계 영역에 대한 진입 요청 후 무한히 기다리지 않는다.
