[Java] Stream
스트림 사용
스트림이란?
-
한 번에 한 개씩 만들어지는 연속적인 데이터 항목들의 모임
-
Java 8에서java.util.stream패키지에 스트림 API가 추가됨 -
Stream<T>으로 구성된 일련의 항목을 의미함
⭐ 핵심 : 기존에는 한 번에 한 항목을 처리했지만, 자바 8에서는 우리가 하려는 작업을 고수준으로 추상화 해서 일련의 스트림으로 만들어 처리할 수 있다.
⭐ 스트림 파이프라인을 이용해서 입력 부분을 여러 CPU 코어에 쉽게 할당할 수 있다는 부가적인 이득
➜ 공짜로 병렬성 획득
어려운 멀티스레딩
-
멀티스레딩 코드를 구현해서 병렬성을 이용하는 것은 쉽지 않음.
-
멀티스레딩의 핵심은 공유 데이터의 접근을 막는 것
-
스트림은 "컬렉션을 처리하면서 발생하는 모호함과 반복적인 코드문제" 와 "멀티 코어 활용 어려움" 이라는 두 문제를 모두 해결함
스트림 활용
-
데이터 필터링
-
데이터 추출
-
데이터 그룹화
-
포킹 단계 : 두 CPU에게 데이터를 나누고(forking), 처리 후 합침
순차 처리 방식
import static java.util.stream.Collectors.toList
List<Apple> heavyApples =
inventory.stream().fliter((Apple a) -> a.getWeight() > 150)
.collect(toList());병렬 처리 방식
import static java.util.stream.Collectors.toList
List<Apple> heavyApples =
inventory.parallelStream().fliter((Apple a) -> a.getWeight() > 150)
.collect(toList());스트림 예시
[기존 방식] for문을 이용하여 반복문으로 필터링 하는 모습이다.
List<Dish> lowCaloricDishes = new ArrayList<>();
// 칼로리가 400 이하가 되는 메뉴를 찾음
for(Dish dish : menu){
if(dish.getCaories() < 400) {
lowCalricDishes.add(dish);
}
}
// 익명 클래스로 요리 정렬
Collections.sort(lowCaloricDishes, new Comparator<Dish>() {
public int compare(Dish dish1, Dish dish2){
return Integer.compare(dish1.getCalories(), dish2.getCalories())
}
});
// 정렬된 리스트에서 요리 이름을 선택함
List<String> lowCaloricDishesName = new ArrayList<> ();
for(Dish dish: lowCaloricDishes){
lowCaloricDishesName.add(dish.getName());
}[자바 8] 스트림을 사용하면, 필터링과 그룹화 하는 코드를 간결하게 작성할 수 있다.
import static java.util.Comparator.comparing;
import static java.util.stream.Collectors.toList;
List<String> lowCaloricDishesName =
menu.stream()
.filter(d -> d.getCalories < 400) // 400칼로리 이하의 요리 선택
.sorted(comparing(Dish::getCalories)) // 칼로리로 요리 정렬
.map(Dish::getName) // 요리명 추출
.collect(toList()); // 모든 요리명을 리스트에 저장여기서 stream()을 parallelStream()으로 바꾸면 멀티코어 아키텍처에서 병렬로 실행한다.
고수준 빌딩 블록

-
filter,sorted,map,collect의 연산은 특정 스레딩 모델에 제한되지 않고 자유롭게 어떤 상황에서든 사용할 수 있다. -
필터 → 정렬 → 변환 → 수집 의 단계로 이루어져, 이 순서를 지키면 병렬성을 보장 받는다.
스트림과 컬렉션
-
컬렉션 : 현재 자료구조가 포함하는 모든 값을 메모리에 저장하는 자료구조
-
스트림 : 요청할 때만 요소를 계산하는 고정된 자료구조
- 단 한번만 소비할 수 있다!!
외부 반복과 내부 반복
-
[외부 반복] : 사용자가 명시적으로 반복 (컬렉션에서 사용)
List<String> names = new ArrayList<> (); for(Dish dish : menu) { names.add(dish.getName()); } -
[내부 반복] : 반복을 알아서 처리하고 결과 스트림 값을 어딘가에 저장 (스트림에서 사용)
⭐ 내부 반복의 장점 : 자바가 작업을 투명하게 병렬로 처리하거나 더 최적화된 다양한 순서로 처리 가능
List<String> names = menu.stream() .map(Dish::getName()) .collect(toList());
스트림 이용하기
- 중간 연산
| 연산 | 형식 | 반환 형식 | 연산의 인수 | 함수 디스크립터 |
|---|---|---|---|---|
| filter | 중간 연산 | Stream<T> | Prediate<T> | T -> boolean |
| map | 중간 연산 | Stream<R> | Functional<T, R> | T -> R |
| limit | 중간 연산 | Stream<T> | ||
| sorted | 중간 연산 | Stream<T> | Comparator<T> | (T, T) -> int |
| distinct | 중간 연산 | Stream<T> |
- 최종 연산
| 연산 | 형식 | 반환 형식 | 목적 |
|---|---|---|---|
| forEach | 최종 연산 | void | 스트림의 각 요소를 소비하면서 람다를 적용 |
| count | 최종 연산 | long(generic) | 스트림의 요소 개수를 반환한다 |
| collect | 최종 연산 | 스트림을 리듀스해서 리스트, 맵, 정수 형식의 컬렉션을 만든다. |
스트림 활용
필터링
Predicate로 필터링
Predicate: 불리언을 반환하는 함수
List<Dish> vegeterianMenu =
menu.stream()
.filter(Dish::isVegetrian) // 프레디케이트로 필터링
.collect(toList());고유 요소 필터링
- 고유 여부는 스트림에서 만든 객체의
hashCode,equals로 결정됨
List<Integer> numbers = Arrays.asList(1, 2, 1, 3, 3, 2, 4);
numbers.stream()
.filter(i -> i % 2 == 0)
.distinct() // 고유 요소만 추출
.forEach(System.out::println);➜ filter에서 결과가 [2, 4, 4] 가 나왔다면 최종 결과는 [2, 4] 가 나올 것
스트림 슬라이싱
- 스트림의 요소를 선택하거나 스킵하는 다양한 방법
Predicate를 이용한 슬라이싱 (자바 9)
[
Dish("...", ..., 120, ...),
Dish("...", ..., 300, ...),
Dish("...", ..., 400, ...),
Dish("...", ..., 420, ...),
Dish("...", ..., 450, ...),
Dish("...", ..., 600, ...),
]이렇게 Dish가 ArrayList로 되어 있을 때, filter를 사용하면 320칼로리 이하의 요리를 선택할 수 있다.
하지만, 칼로리 순으로 정렬되어 있으므로 슬라이싱을 통해서 하는 것이 효과적이다
TAKEWHILE활용 : Predicate가 참이 되는 구간을 슬라이싱 (320보다 작은 구간 사용)
List<Dish> slicedMenu1 =
specialMenu.stream()
.takeWhile(dish -> dish.getCalories() < 320) // 프레디케이트로 슬라이싱
.collect(toList());DROPWHILE활용 : Predicate가 거짓이 되는 구간을 슬라이싱 (320보다 큰 구간 사용)
List<Dish> slicedMenu1 =
specialMenu.stream()
.dropWhile(dish -> dish.getCalories() < 320) // 프레디케이트로 슬라이싱
.collect(toList());스트림 축소
limit사용
List<Dish> vegeterianMenu =
menu.stream()
.filter(Dish::isVegetrian)
.limit(3) // 3개 까지만 선택함
.collect(toList());요소 건너뛰기
skip사용
List<Dish> vegeterianMenu =
menu.stream()
.filter(dish -> dish.getCalories() > 300)
.skip(2) // 300 칼로리 넘는 요리부터 2개는 뛰어넘음, 그 이후부터 출력함
.collect(toList());매핑
스트림 평면화
-
["Hello", "World"]리스트를 고유 문자로 반환해보자
→["H", "e", "l", "o", "W", "r", "d"] -
flatMap사용
List<String> uniqueCharacters =
words.stream()
.map(word -> word.split("")) // map의 리턴 타입은 `Stream<Array>`
.flatMap(Arrays::stream) // 위에서 생성된 스트림을 하나의 스트림으로 평면화
.distinct()
.collect(toList());검색과 매칭
Predicate가 적어도 한 요소와 일치하는지 확인
boolean isAnyMatch = menu.stream().anyMatch(Dish::isVegetarian);Predicate가 모든 요소와 일치하는지 확인
boolean isAllMatch = menu.stream().allMatch(dish -> dish.getCalories() < 1000);Predicate가 일치 하는 요소가 없는지 확인
boolean isNoneMatch = menu.stream().noneMatch(d -> d.getCalories() < 1000);아무거나 찾기 findAny
-
Optional<T>클래스를 이용하여 값의 존재나 부재 여부를 표현하는 컨테이너 클래스 -
null이 담길 수 있으니, 에러를 발생시키지 않는
Optional<T>클래스 사용
Optional<Dish> dish =
menu.stream()
.filter(Dish::isvegeterian)
.findAny();ifPresent: 값이 있으면 주어진 블록을 실행한다.
menu.stream()
.filter(Dish::isvegeterian)
.findAny()
.ifPresent(dish -> System.out.println(dish.getName()));첫 번째 요소 찾기 findFirst
List<Integer> someNumbers = Arrays.asList(1, 2, 3, 4, 5);
Optional<Integer> fisrtSquareDivisibleByThree =
someNumbers.stream()
.map(n -> n * n)
.filter(n -> n % 3 == 0)
.findFirst(); // 9 리듀싱
- 스트림의 모든 요소를 반복적으로 처리하기 위함
요소의 합
int sum = numbers.stream().reduce(0, (a, b) -> a + b); // 모든 값 덧셈, 첫 번째 인수 0int sum = numbers.stream().reduce(0, Integer::sum); // Integer 클래스는 두 숫자를 더하는 정적 sum 메소드 제공요소의 곱
int sum = numbers.stream().reduce(1, (a, b) -> a * b); // 모든 값 곱셈, 첫 번째 인수 1초기 값 없음
Optional<Integer> sum = numbers.stream().reduce((a, b) -> (a + b)); // 초기 값이 없어서 Optional 클래스 사용최대값과 최솟값
Optional<Integer> max = numbers.stream().reduce(Integer::max); // 초기 값이 없어서 Optional 클래스 사용Optional<Integer> min = numbers.stream().reduce(Integer::min); // 초기 값이 없어서 Optional 클래스 사용리듀스의 장점
parallelStream으로 변경하면, 병렬화가 가능하다
병렬 데이터 처리와 성능
위에서 Stream을 ParallelStream으로 처리하면 병렬화가 가능하다고 했다.
그렇다면 얼마나 좋은 성능이 나올까?
포크/조인 프레임워크
자바 7 이전
자바 7 이전에는 데이터 컬렉션을 병렬로 처리하기 어려웠다.
데이터를 split하여 분할한 뒤에, 각각의 스레드에 할당한다.
스레드로 할당한 뒤에는 의도치 않은 레이스 컨디션을 방지하기 위해 적절한 동기화를 추가해야하며,
마지막으로 부분 결과를 합쳐야 한다.
자바 7 이후
더 쉽게 병렬화를 수행하면서 에러를 최소화 할 수 있도록 포크/조인 프레임워크 기능을 제공한다.
Stream.iterate(1L, i -> i+1)
.limit(n)
.parallel()
.reduce(0L, Long::sum);순차 스트림에 parallel 메소드를 호출하면 기존의 함수형 리듀싱 연산(숫자 합계 계산)이 병렬로 처리 된다.
병렬 스트림에서 사용하는 스레드 풀 설정
스트림의 parallel 메서드에서 병렬 스트림은 내부적으로 ForkJoinPool을 사용한다.
기본적으로 ForkJoinPool은 프로세서 수이다.
이 프로세서 수는 Runtime.getRuntime().availableProcessors()가 반환하는 값을 지정한다.
다음과 같은 방법으로 병렬 스트림의 프로세서의 수를 저종할 수 있다.
System.setProperty("java.util.consurrent.ForkJoinPool.common.parallelism","12")
이 명령어는 전역 설정 코드이므로 이후의 모든 병렬 스트림 연산에 영향을 준다.
스트림 성능 측정
과연 얼마나 성능이 좋아질 까?
자바 마이크로벤치마크 하니스(JMH) 라이브러리로 벤치마크를 구현할 수 있다.
어노테이션 방식을 지원하고, JVM을 대상으로 하는 다른 언어용 벤치마크도 구현할 수 있다.
하지만, JVM으로 동작하는 프로그램의 성능을 측정하는 것은 어렵다.
- Hotspot이 바이트 코드를 최적화 하는데 필요한 준비시간
- 가비지 컬렉터로 인한 오버헤드
등의 요소를 고려해야한다.
하지만 간단한 코드의 성능을 측정하고 비교하는데는 유용하다.
Maven 추가
JMH 라이브리러와 자바 아카이브 (JAR) 파일을 만드는데 도움을 주는 어노테이션 프로세서를 포함한 라이브러리를 추가한다,
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>JHM</artifactId>
<version>1.0-SNAPSHOT</version>
<!-- 프로젝트 속성 정의 -->
<properties>
<maven.compiler.source>21</maven.compiler.source>
<maven.compiler.target>21</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<!-- 종속성 추가 -->
<dependencies>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>1.19</version>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>1.19</version>
</dependency>
</dependencies>
</project>벤치마크 성능 측정
package org.example;
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.io.IOException;
import java.util.stream.Stream;
import java.util.concurrent.TimeUnit;
@State(Scope.Benchmark) // 상태 객체를 벤치마크 전체 범위로 설정
@BenchmarkMode(Mode.AverageTime) // 벤치마크 대상 메소드를 실행하는데 걸린 평균 시간
@OutputTimeUnit(TimeUnit.MILLISECONDS) // 벤치마크 결과를 밀리초 단위로 출력
@Fork(value = 2, jvmArgs = {"-Xms4G", "-Xms4G"}) // 4GB의 힙 공간을 제공한 환경에서 두번 벤치마크를 수행해 결과의 신뢰성 확보
public class ParallelStreamBenchmark {
private static final long N = 10_000_000L;
@Benchmark
public long sequentialSum(){
return Stream.iterate(1L, i -> i + 1)
.limit(N)
.reduce(0L, Long::sum);
}
@TearDown(Level.Invocation)
public void tearDown(){ // 매번 벤치마크를 실행한 다음에는 가비지 컬렉터 동작 시도
System.gc();
}
public static void main(String[] args) throws IOException, RunnerException {
Options opt = new OptionsBuilder()
.include(ParallelStreamBenchmark.class.getSimpleName())
.warmupIterations(10) // 사전 테스트 횟수
.measurementIterations(10) // 실제 측정 횟수
.forks(2) //
.build();
new Runner(opt).run(); // 벤치마킹 시작
}
}클래스를 실행해보자
벤치마크가 가비지 컬렉터의 영향을 받지 않도록 힙의 크기를 충분하게 설정하고, 벤치마크가 끝날 때마다 가비지 컬렉터가 실행되도록 강제했다.
JHM은 핫스팟이 코드를 최적화 할 수 있도록 20번을 실행하며 벤치마크를 실행한다.
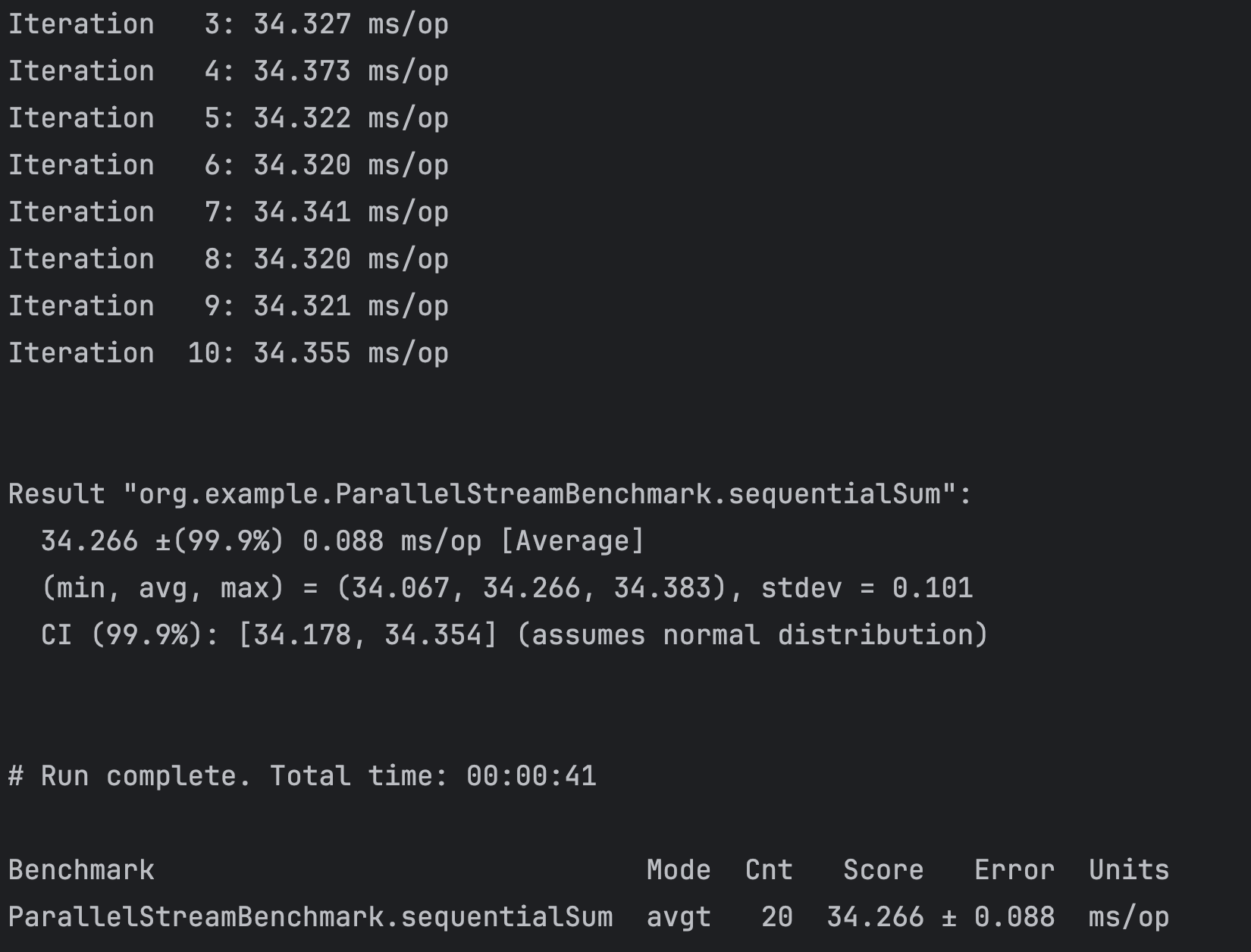
실행해보니 34밀리초가 걸렸다.
그렇다면 parallelStream은 얼마나 걸릴까?
package org.example;
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.io.IOException;
import java.util.stream.Stream;
import java.util.concurrent.TimeUnit;
@State(Scope.Benchmark) // 상태 객체를 벤치마크 전체 범위로 설정
@BenchmarkMode(Mode.AverageTime) // 벤치마크 대상 메소드를 실행하는데 걸린 평균 시간
@OutputTimeUnit(TimeUnit.MILLISECONDS) // 벤치마크 결과를 밀리초 단위로 출력
@Fork(value = 2, jvmArgs = {"-Xms4G", "-Xms4G"}) // 4GB의 힙 공간을 제공한 환경에서 두번 벤치마크를 수행해 결과의 신뢰성 확보
public class ParallelStreamBenchmark {
private static final long N = 10_000_000L;
// @Benchmark
public long sequentialSum(){
return Stream.iterate(1L, i -> i + 1)
.limit(N)
.reduce(0L, Long::sum);
}
@Benchmark
public long parallelSum(){
return Stream.iterate(1L, i -> i + 1)
.limit(N)
.reduce(0L, Long::sum);
}
@TearDown(Level.Invocation)
public void tearDown(){ // 매번 벤치마크를 실행한 다음에는 가비지 컬렉터 동작 시도
System.gc();
}
public static void main(String[] args) throws IOException, RunnerException {
Options opt = new OptionsBuilder()
.include(ParallelStreamBenchmark.class.getSimpleName())
.warmupIterations(10) // 사전 테스트 횟수
.measurementIterations(10) // 실제 측정 횟수
.forks(1) //
.build();
new Runner(opt).run(); // 벤치마킹 시작
}
}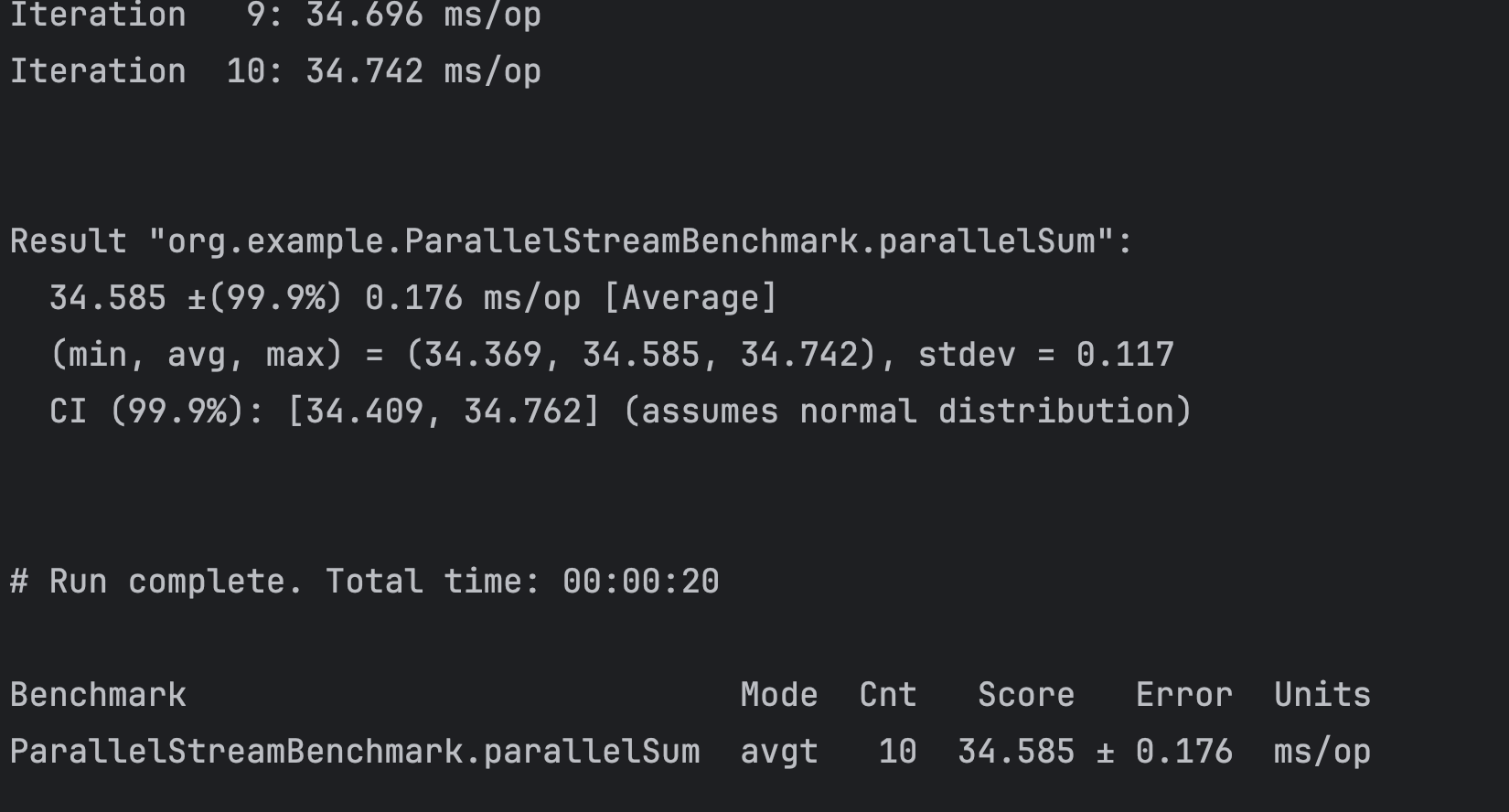
예상보다 비슷했다. 아니 병렬처리 한 것이 더 느렸다.
왜 그럴까?
그 이유가 반복 작업은 병렬로 수행할 수 있는 독립 단위로 나누기가 어렵다는 것이다.
어짜피 순차적으로 하나씩 처리해야하는데, 병렬 처리가 불가는 하다는 것이다.
그래서 스레드를 더 할당할 수록 parallel 메소드가 더 오래걸릴 수도 있다.
그렇다면 이 순차처리 시스템을 더 빠르게 처리하려면 어떻게 해야할까?
LongStream.rangeClosed
LongStream.rangeClosed는 쉽게 청크로 분할할 수 있는 숫자 범위를 생산한다.
예를 들어 1~20이라면, 1~5, 6~10, 11~15, 16~20으로 숫자를 분할한다.
@Benchmark
public long rangedSum(){
return LongStream.rangeClosed(1, N)
.reduce(0L, Long::sum);
}과연 성능은 어떨까?
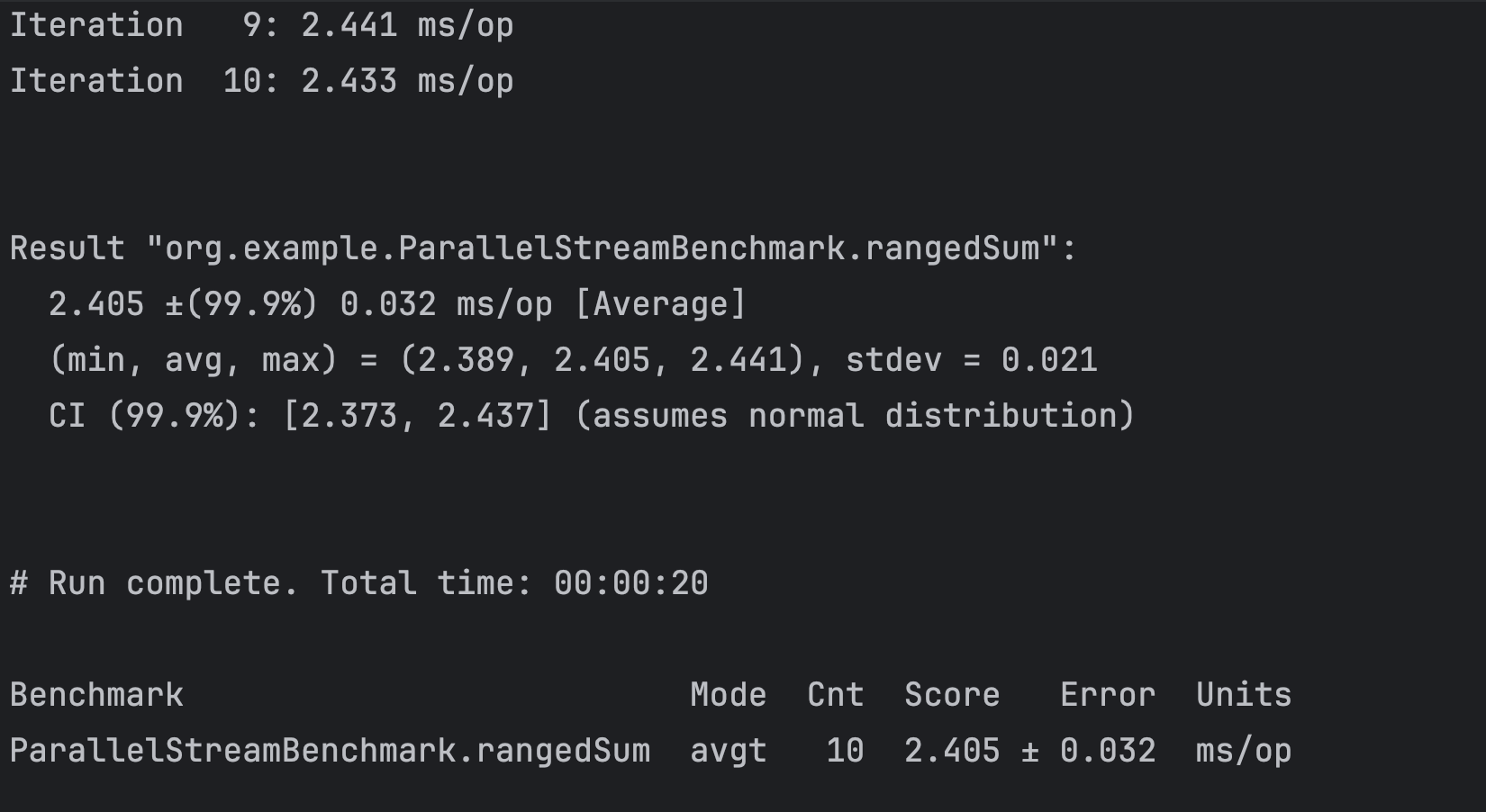
2.405ms로 엄청난 속도를 보여주었다.
그렇다면 여기에 병렬처리 .parallel을 하면 어떻게 될까?
@Benchmark
public long rangedSum(){
return LongStream.rangeClosed(1, N)
.parallel()
.reduce(0L, Long::sum);
}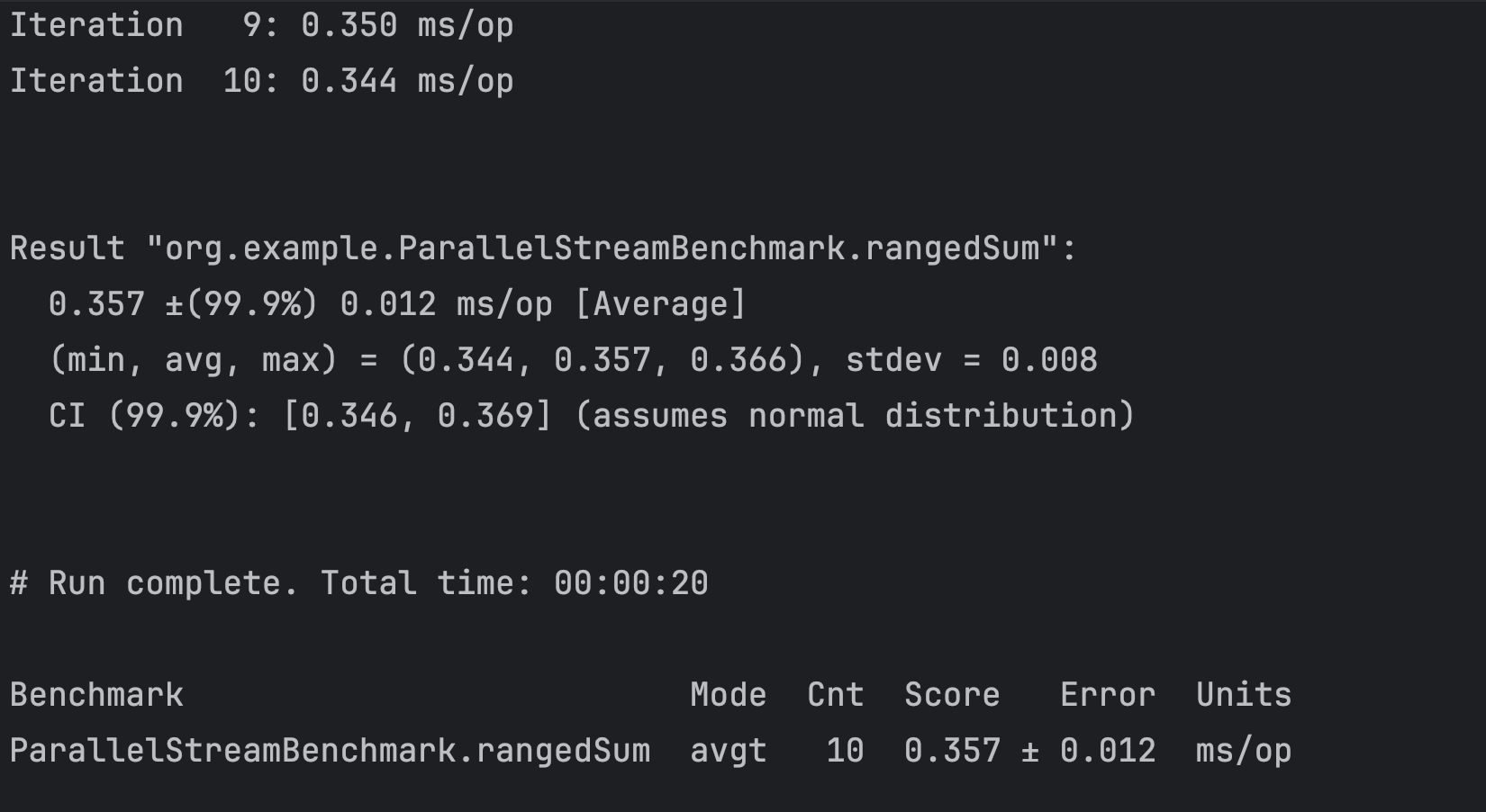
엄청난 속도가 나왔다.
하지만 병렬화가 모든 장점이 있는 것은 아니다.
병렬화 단점
-
스트림을 재귀적으로 분할, 리듀싱 연산을 한 뒤에 하나의 값으로 합쳐야 한다.
-
이 과정에서 멀티코어 간의 데이터 이동에 대한 오버헤드가 크다.
스트림 사용시 주의할 점
-
순차가 빠른지, 병렬이 빠른지 모른다. 속도는 직접 측정하여 확인하자
-
박싱을 주의하자. 자동 박싱과 언박싱은 성능을 크게 저하시킬 수 있는 요소다.
자바 8은 박싱 동작을 피할 수 있도록 기본형 특화 스트림(IntStream,LongStream,DoubleStream)을 제공한다. -
limit나findFirst같이 요소의 순서에 의존하는 연산은 병렬 스트림에서 성능이 떨어진다.findAny가 요소의 순서와 상관없이 연산하므로findFirst보다 성능이 좋다. -
스트림에서 수행하는 전체 파이프라인 연산 비용을 고려하라.
-
소량의 데이터에서는 병렬 스트림이 도움되지 않는다.
-
스트림의 자료구조를 중요시하라.
LinkedList를 분할하려면 모든 요소를 탐색해야하지만,ArrayList는 요소를 탐색하지 않고도 리스트를 분할할 수 있다.LinkedList에서의 비용이 더 들어간다. -
파이프라인의 중간 연산이 분해 과정의 성능이 달라질 수 있다.
SIZED스트림은 정확히 같은 크기의 두 스트림으로 분할할 수 있어 효과적으로 스트림을 병렬 처리가 가능하다. 하지만,filter연산은 스트림의 길이를 예측할 수 없어, 스트림을 병렬 처리에 어려움이 있다.
| 소스 | 분해성 |
|---|---|
| ArrayList | 훌륭함 |
| LinkedList | 나쁨 |
| IntStream.range | 훌륭함 |
| Stream.iterate | 나쁨 |
| HashSet | 좋음 |
| TreeSet | 좋음 |
