개요

인프런 강의 [스프링 핵심 원리 - 고급편] 강의를 기반으로 작성한 글 입니다.
프로세스 소개
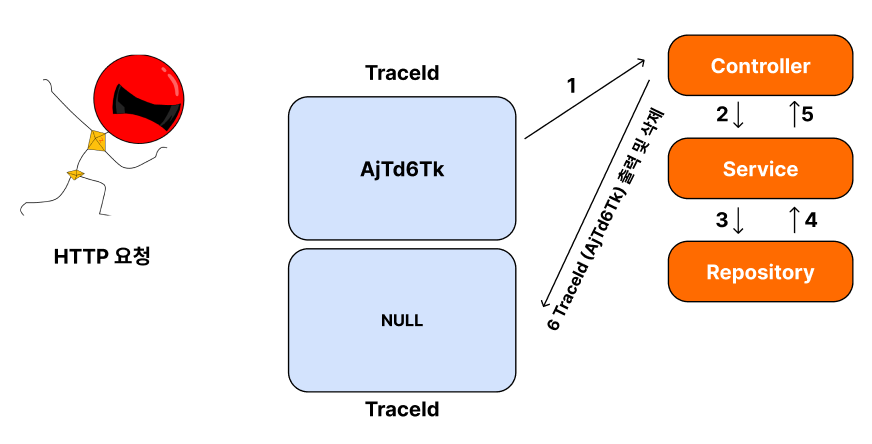
제가 Controller-Service-Repository 기반의 Rest API를 만들었습니다.
GET 메소드인 HTTP 통신은 인스턴스에 저장된 TraceId 값을 가져와서, 반환해주는 그런 기능으로 작성되어있습니다.
[Controller 기능]
1. GET HTTP Request가 들어옴
2. HTTP Request 마다 랜덤한 TraceId를 생성함
3. Controller ➜ Service ➜ Repository 로 이동하여TraceId를 저장함
4. 각 단(Controller / Service / Repository)에서 Log를 통해서 출력 되도록 함
➜TraceId와 현재 무슨 메소드(Service)인지 Log를 통해서 출력
TraceId
간단하죠?
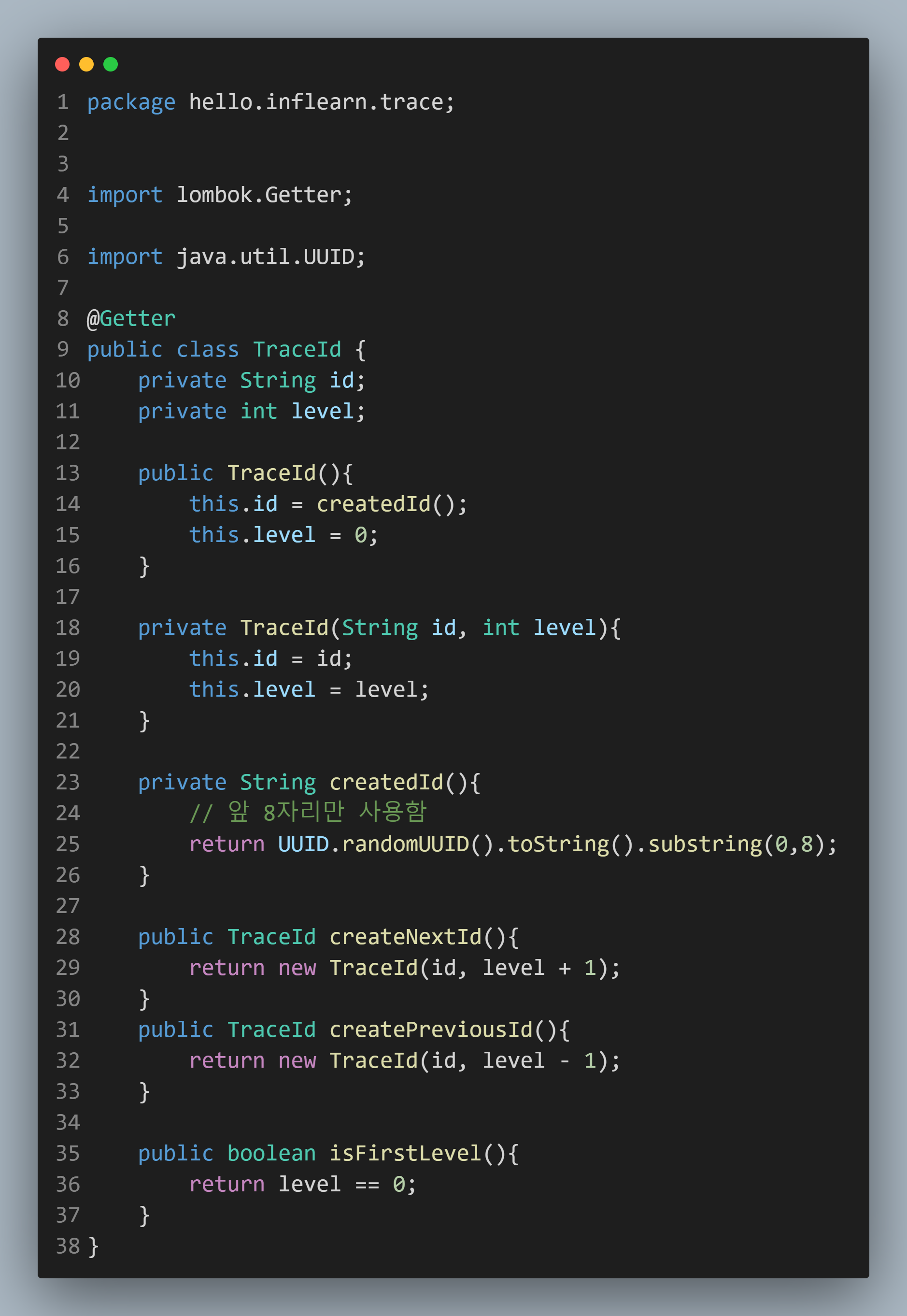
그래서 TraceId 클래스에 Level이라는 것이 존재하는데,
이 Level은 현재 얼마나 메소드가 호출되었는지 판단하는 그런 역할을 합니다.
이동 순서를 생각해봅시다.
이동 순서
1. [Level = 0] : Controller 에서 새 TraceId 생성
2. [Level = 1] : Service로 넘어가면서 TraceId를 받아오고, Level = 1
3. [Level = 2] : Repository로 넘어가면서 TraceId를 받아오고, Level = 2
4. [Level = 1] : Service로 Return
5. [Level = 0] : Controller로 Return
TraceStatus
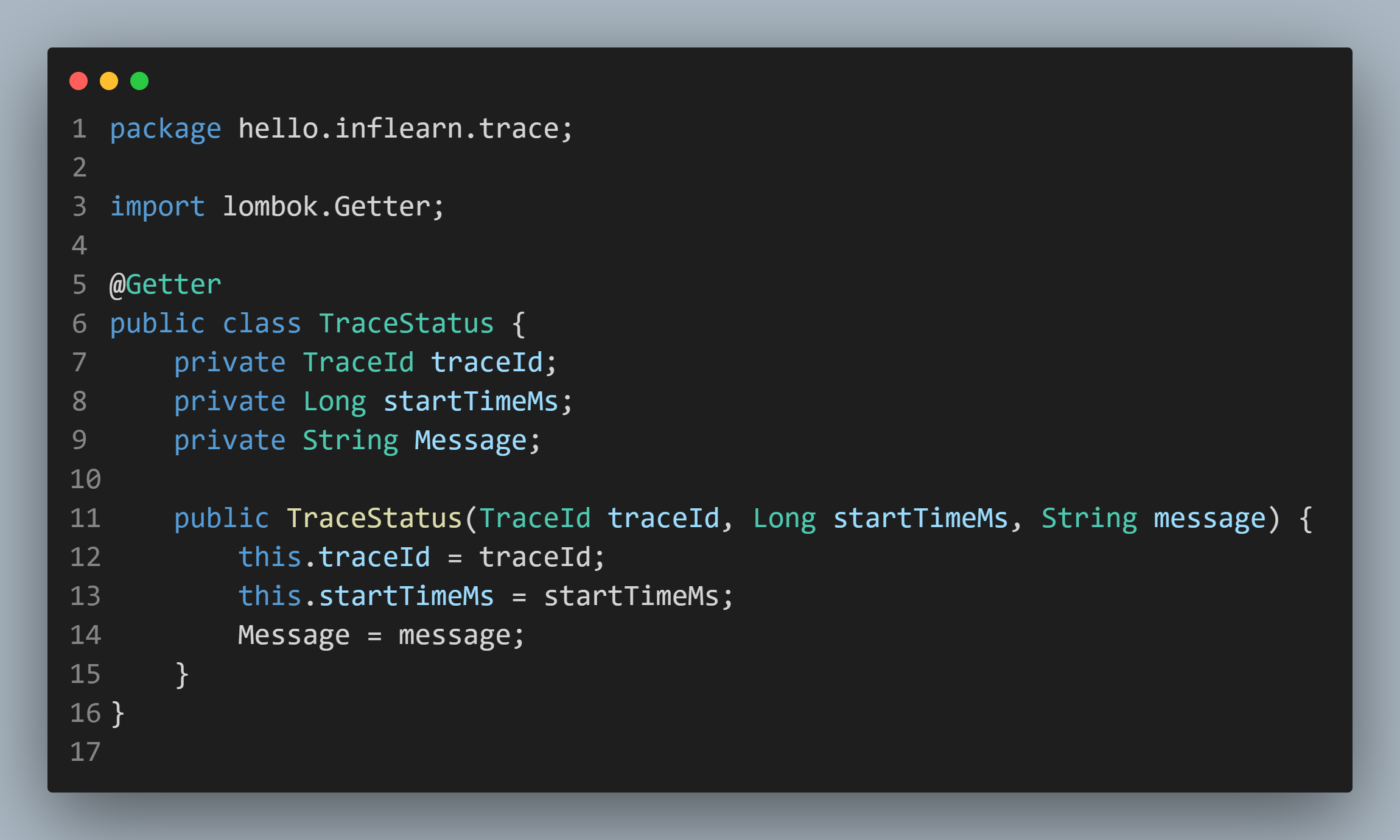
TraceId도 필요하지만,시작 시간 메세지도 같이 Controller ➜ Service ➜ Repository 로 보내야 해서, TraceStatus 객체에 담아 한번에 전달하려 합니다.
Controller - Service - Repository
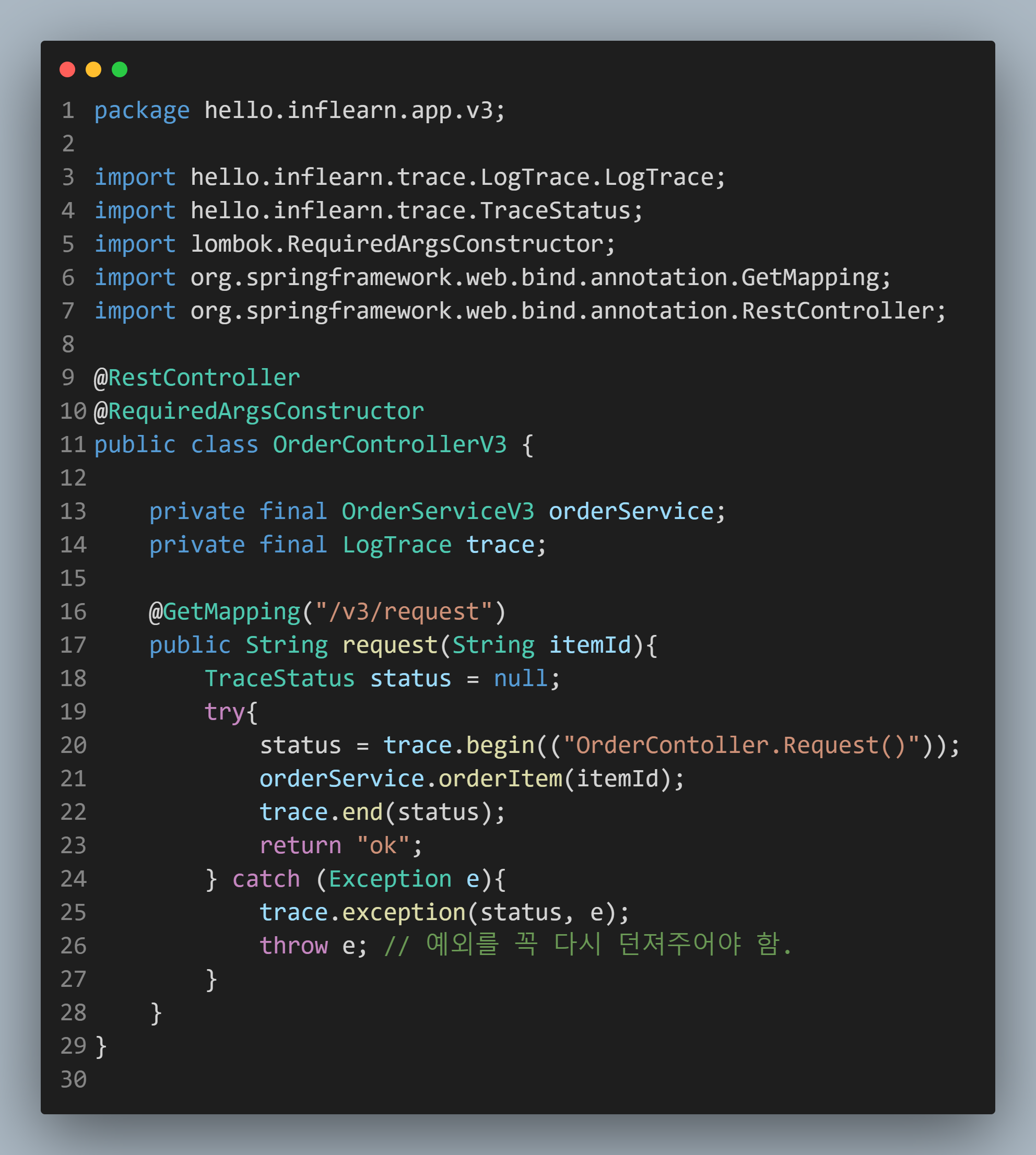
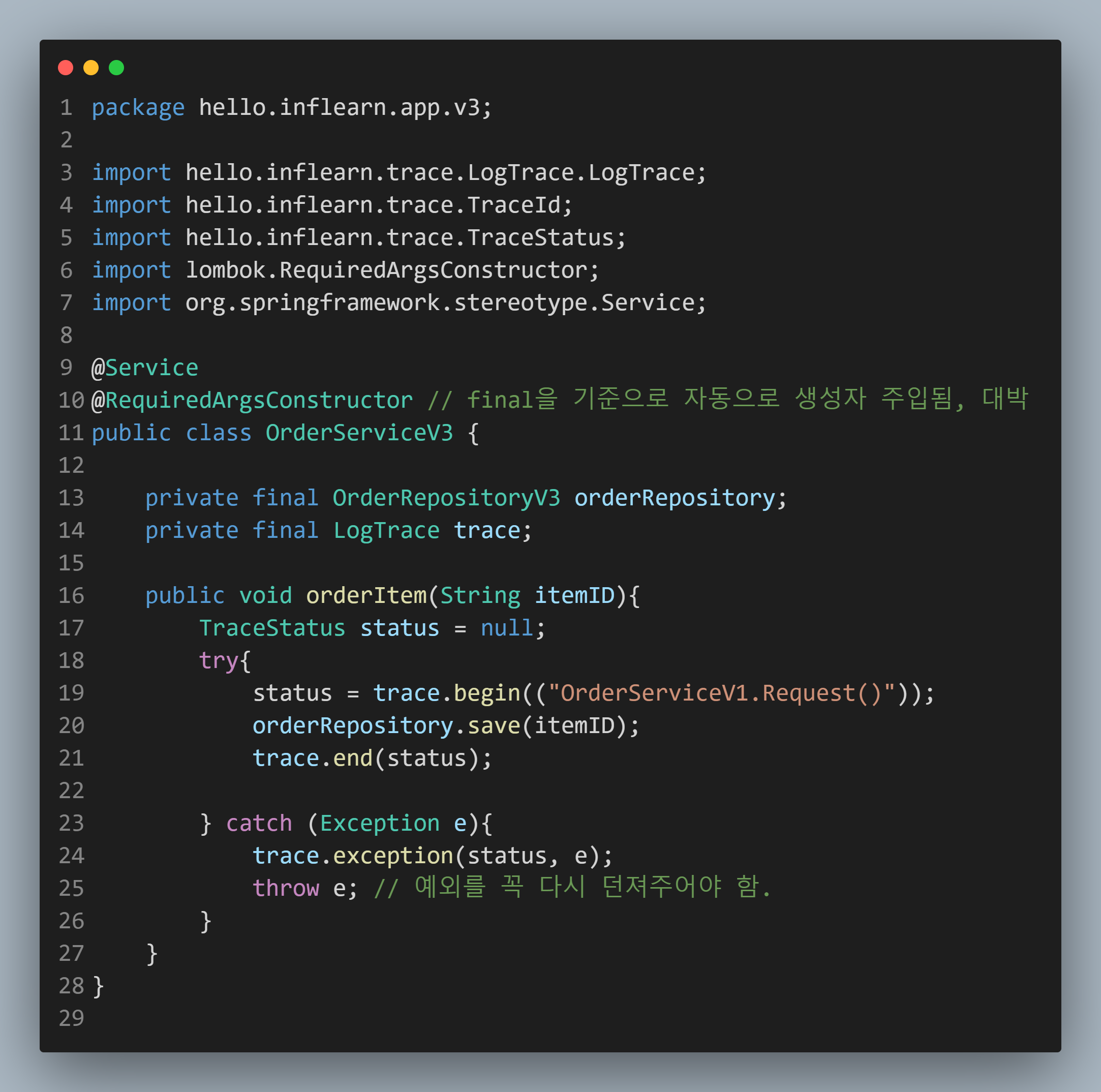
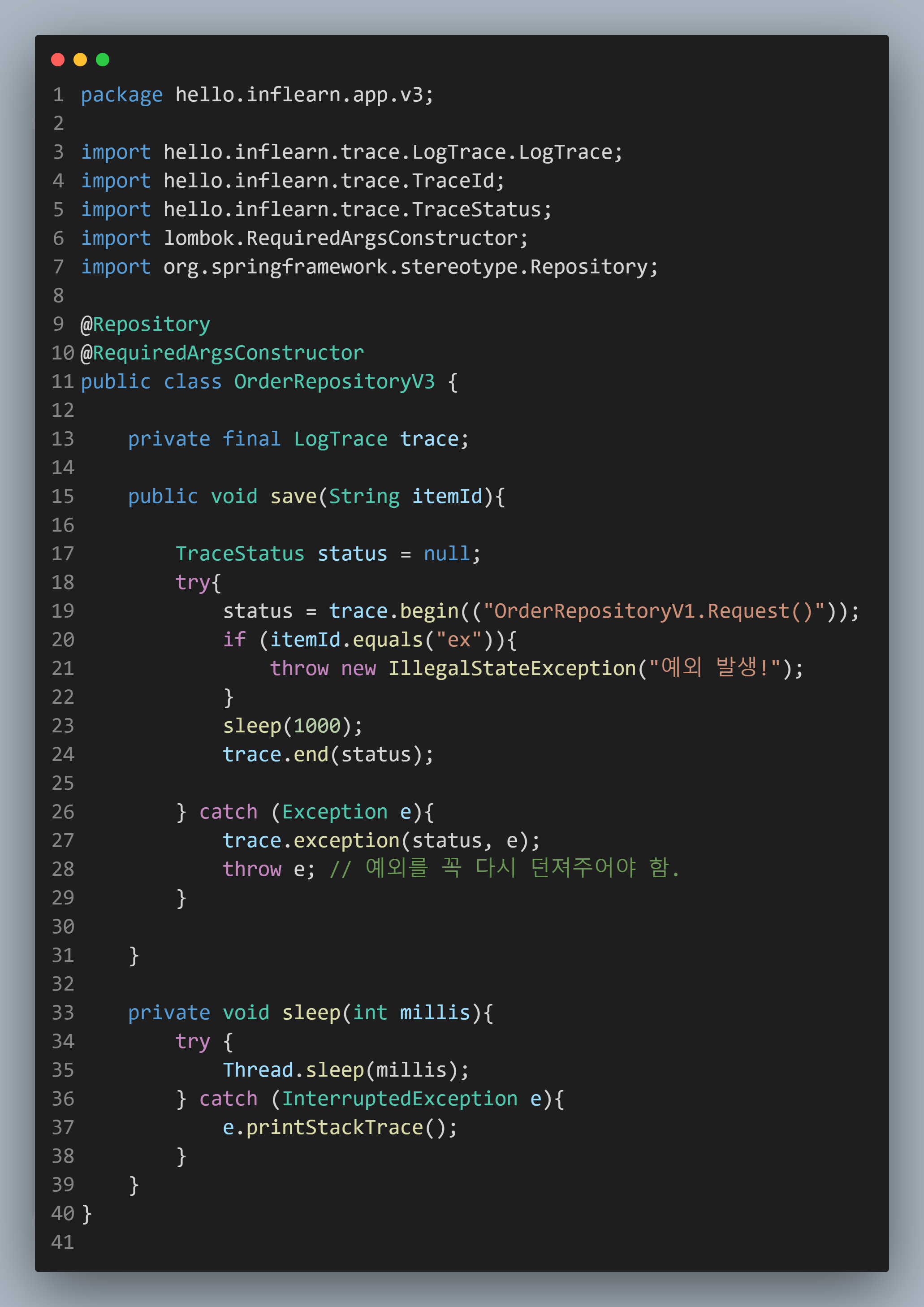
그러면 이제 Controller - Service - Repository를 살펴보겠습니다.
| Controller | Service | Repository |
|---|---|---|
 |  |  |
네.. 잘 안보이시죠?
Controller
Service
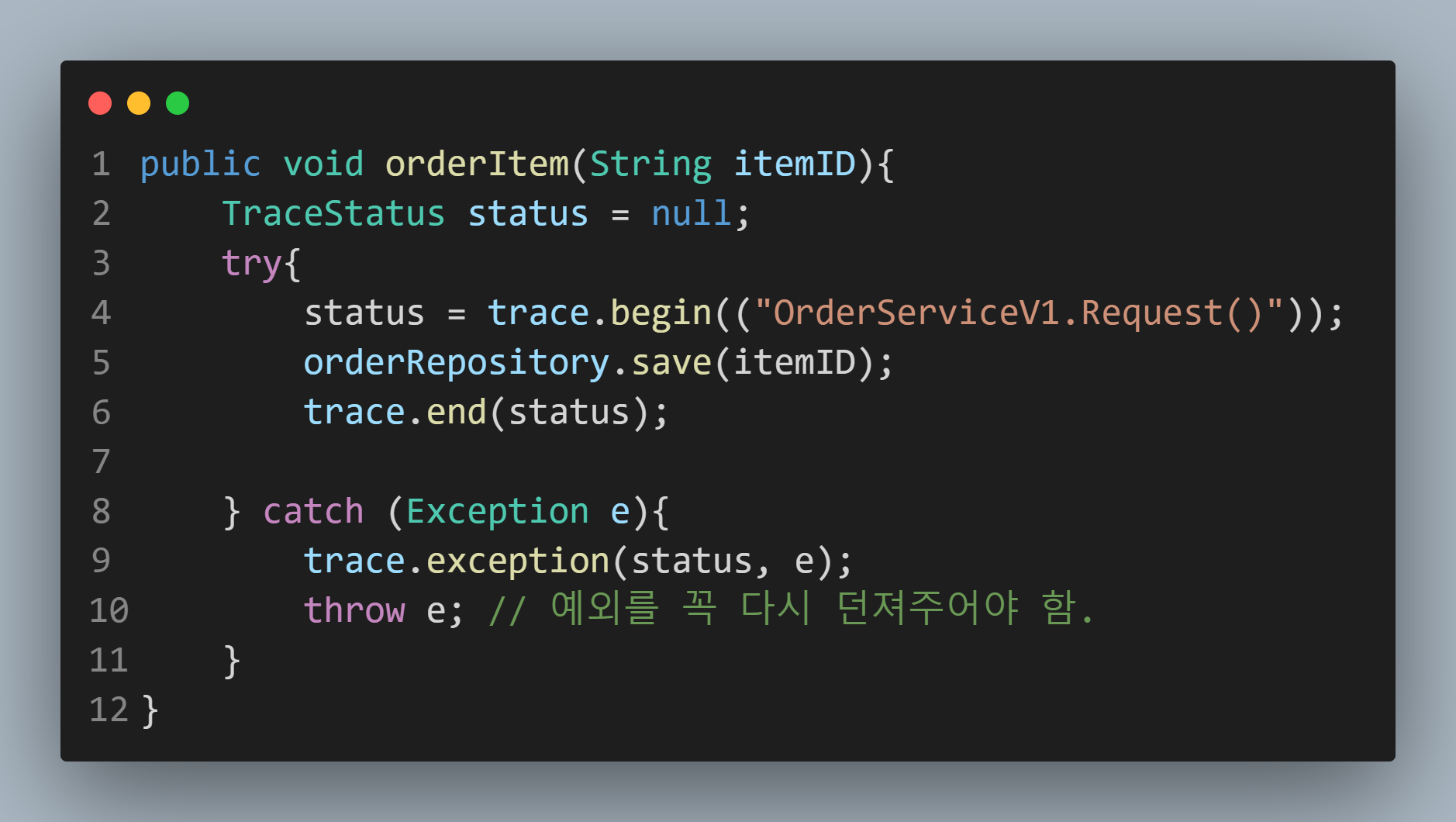
Repository
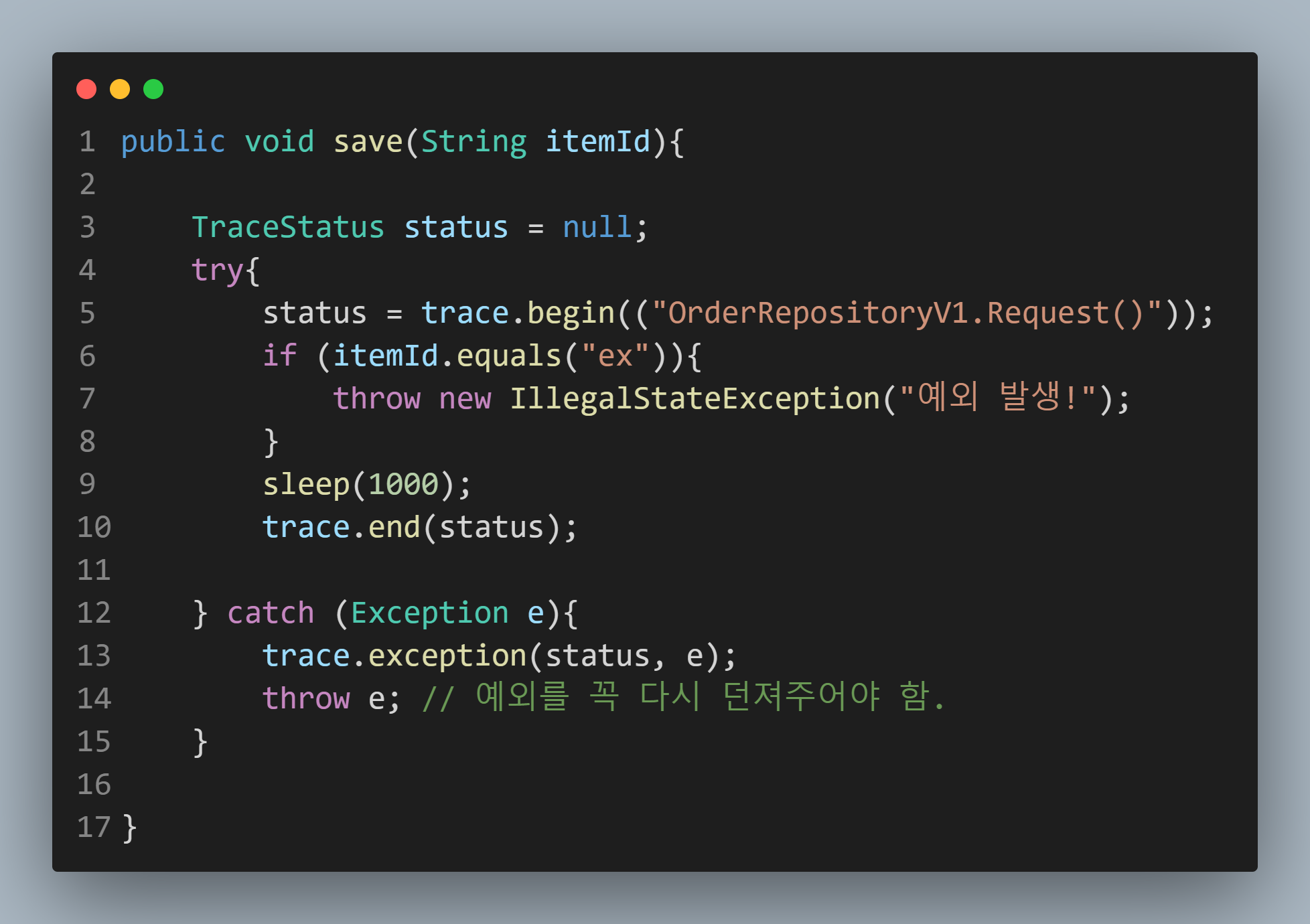
이러한 식으로 begin에서는 message를 보내고 있습니다.
그러면 기존에 생성된 TraceId가 있으면 그 값을 사용하고
만약 생성된 값이 없으면 새로 생성하겠죠? (Controller일 가능성이 높겠죠)
begin과 end를 호출하는 객체인 trace로 선언된 LogTrace를 들여다볼까요?
LogTrace
인터페이스로 생성했습니다! 그 이유는 두개 이상 구현할 필요가 있다는 것이겠죠??
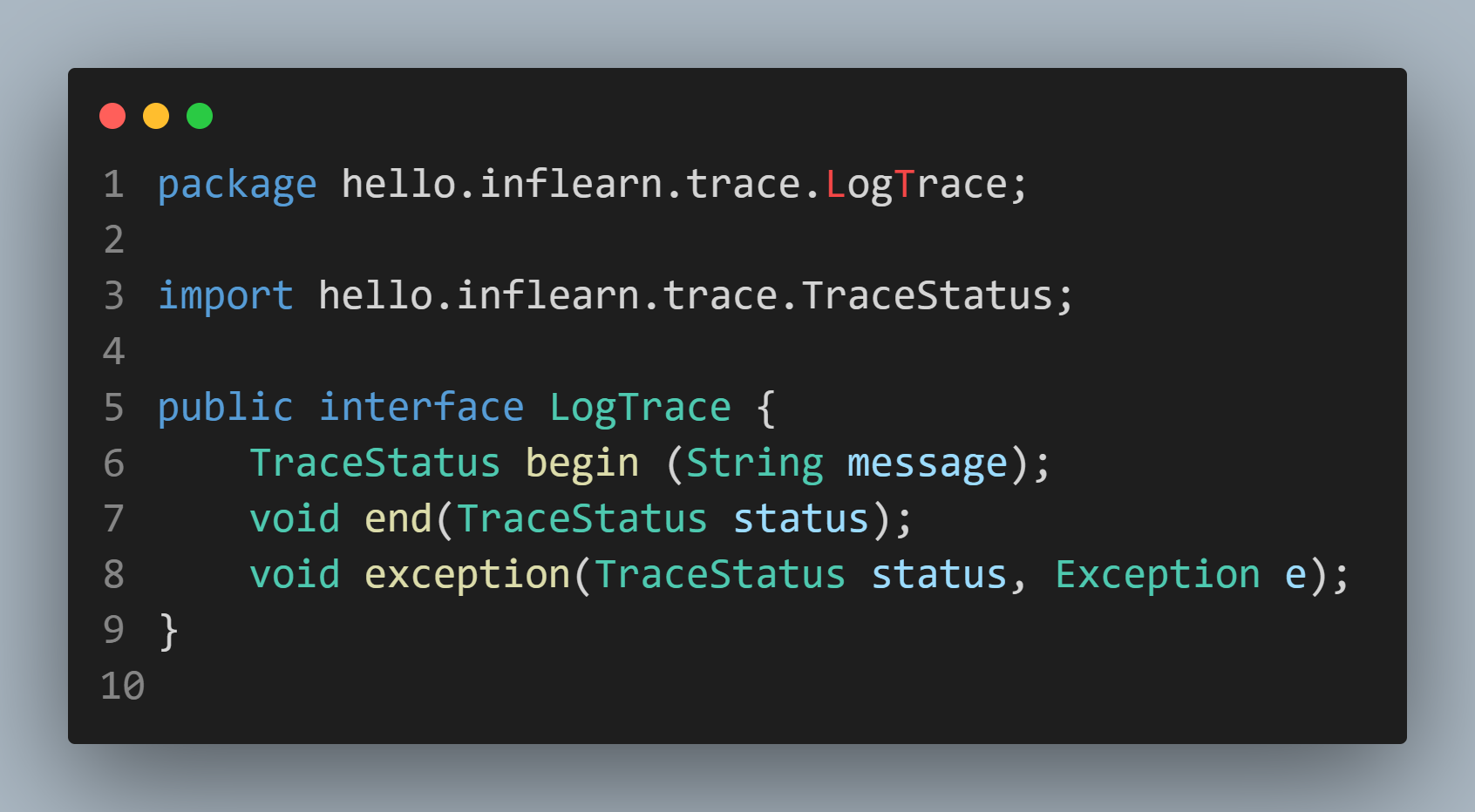
그럼 이 인터페이스의 구현체를 들여다 보겠습니다
FieldLogTrace
인터페이스로 생성해서, Controller / Service / Repository에서 처음에 begin 메소드를 호출합니다.
생성된 TraceId가 있으면, 기존 것을 쓰고, 없다면 새 TraceId를 할당하는 그런 내용이 담겨있습니다.
그리고 Controller / Service / Repository에서 마지막에 호출되는 end 메소드에는 Level = 0이면,(Controller이면) TraceId를 지우는 내용이 담겨있습니다.
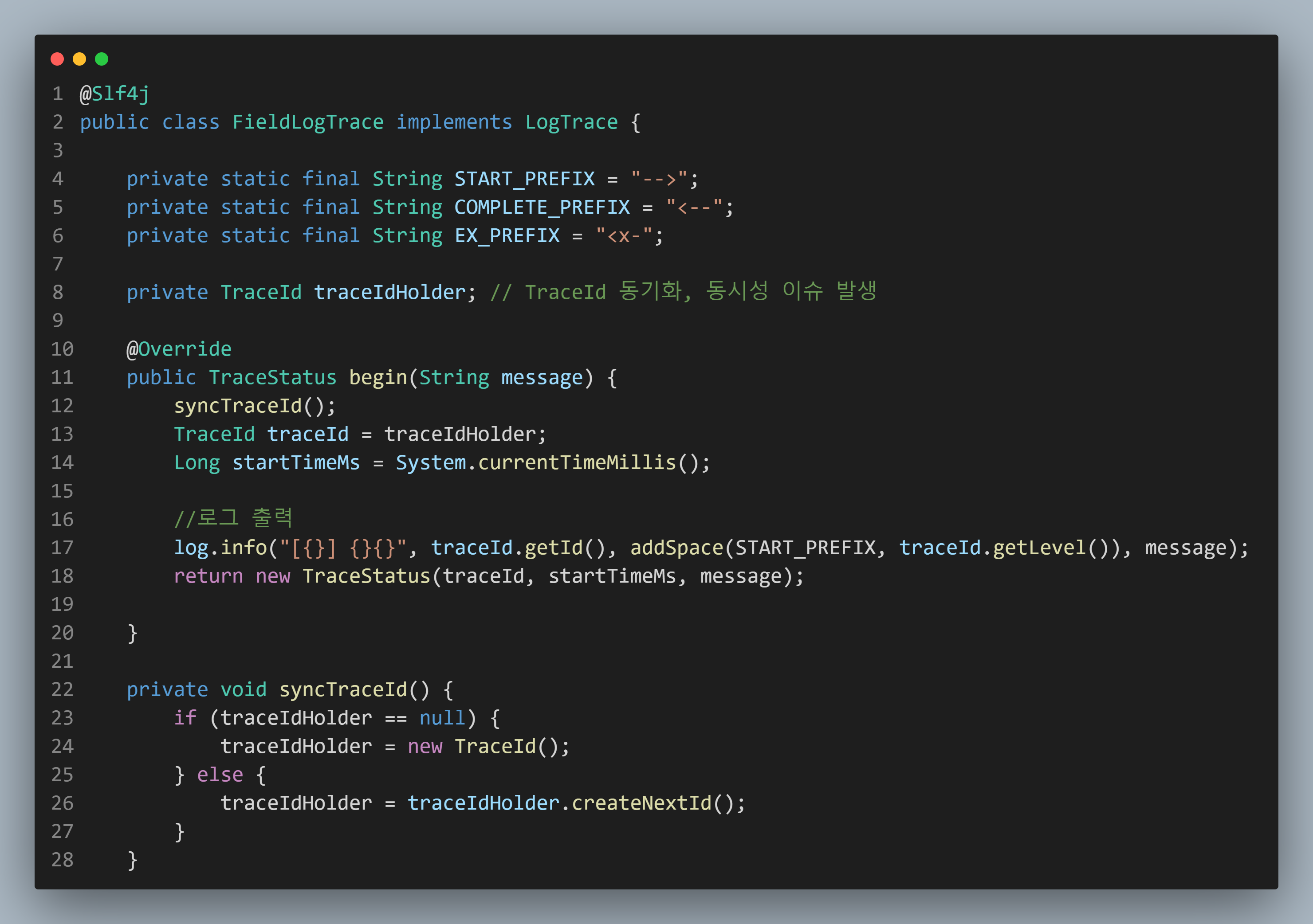
근데 여기 보면 TraceId가 변수로 선언이 되어있습니다.
참고로 이 구현체는 Configuration을 통해서 빈으로 등록되어 있습니다.
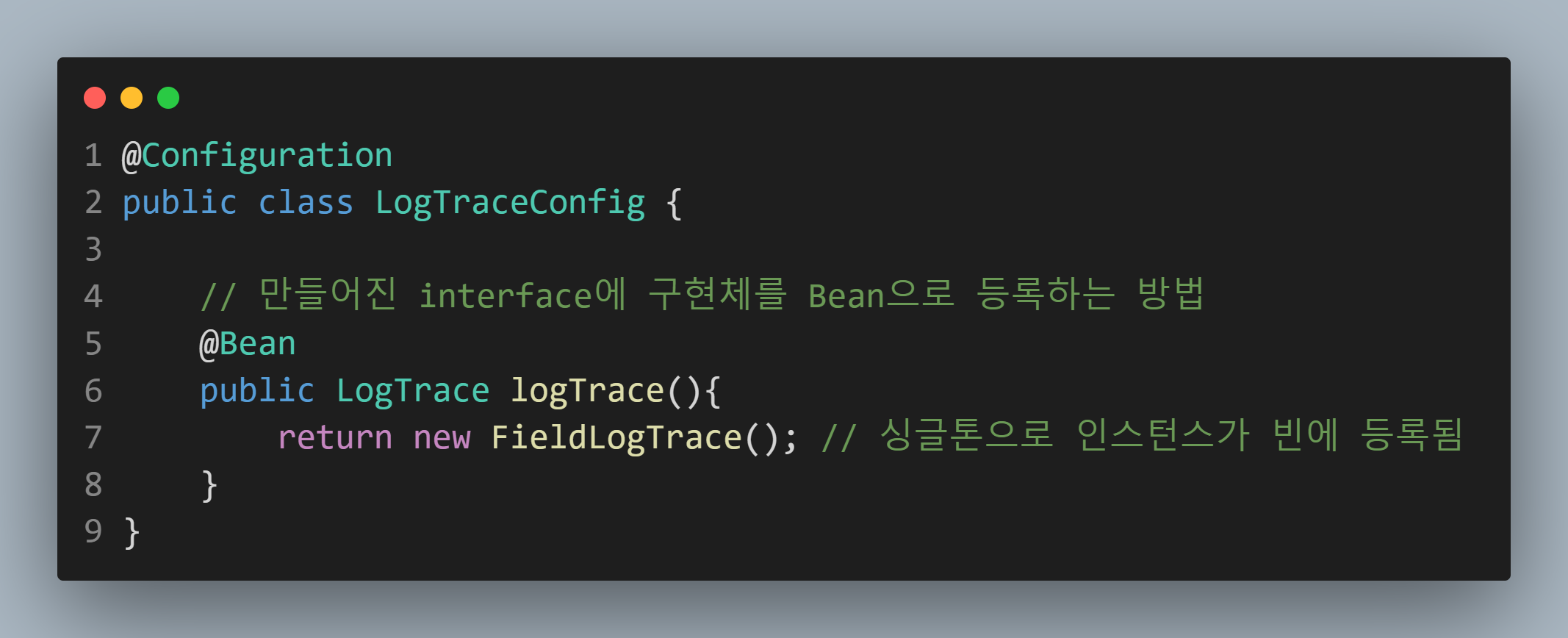
저 이렇게 등록하는 거 처음 알았어요. 개발 지식 +1
구현체 VS 인터페이스
참고로 빈으로 등록하는 인스턴스는 싱글톤으로 생성된다고 합니다.
싱글톤으로 생성되면 무슨 문제가 생길까요? 🤔
맞습니다! 동시성 오류가 발생합니다.
동시성 오류
저는 이런 방식을 기대했습니다.
각기 다른 사용자의 요청은 TraceId를 분리하여 처리하는 것이죠.
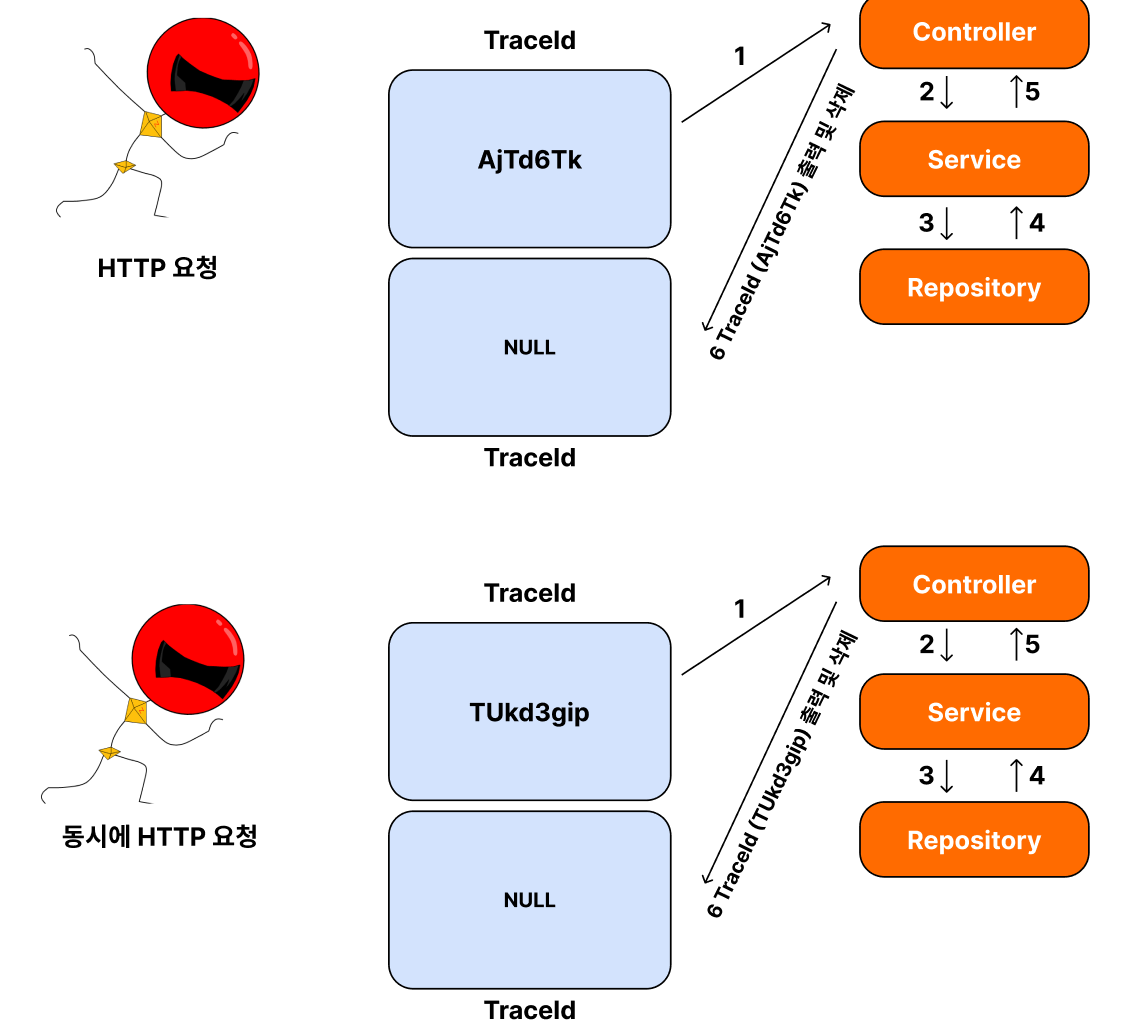
하지만 현실은 제 생각과 달랐습니다.
현실은 TraceId가 싱글톤 객체로 생성되어, 동시에 요청을 하면 같은 값을 공유한다는 것입니다.
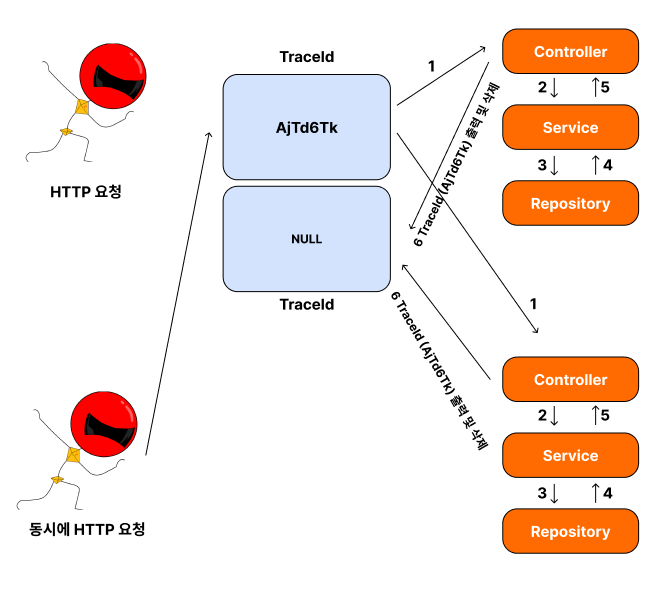
심지어, 먼저 들어온 요청이 다 끝나서 Null이 되어버리면,
두 번째 요청에서 한창 Service에서 처리하고 있는데 NULL이 되어버려서,
작업이 Service 에서 Repository로 TraceId를 넘기지 못할 수도 있습니다.
이렇게 싱글톤으로 생성한 인스턴스 객체는 그 값을 공유합니다.

그러면 값을 따로 분리하려면 어떻게 해야할까요?
이제 ThreadLocal을 사용할 차례입니다.
ThreadLocal
ThreadLocal : 스레드(Thread)마다의 고유한 지역(Local) 변수를 넣어서 사용하는 클래스
ThreadLocal이 알아서 관리해주므로, Thread 별로 데이터가 중복 될 일이 없음
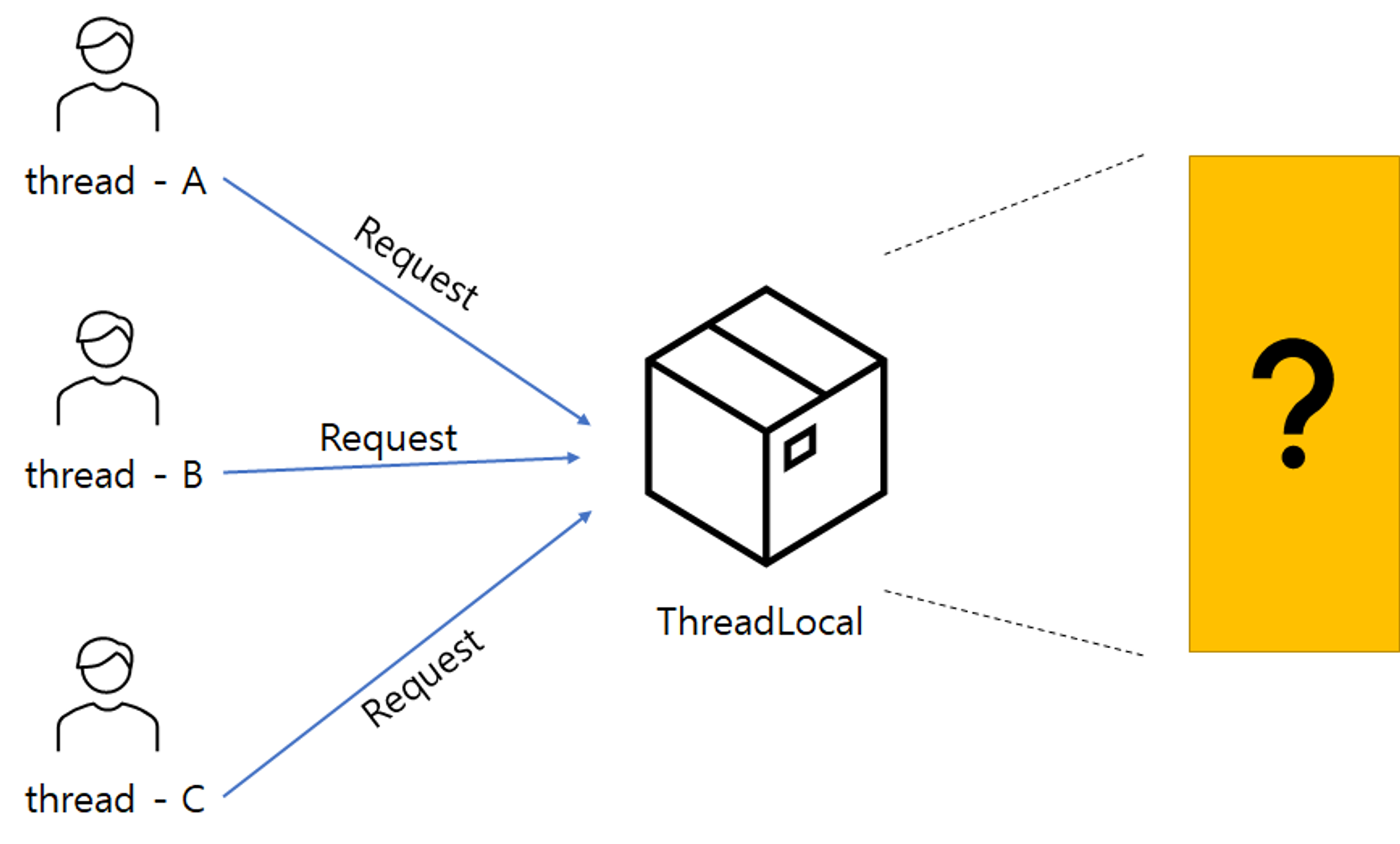
우리의 HTTP 요청마다 다른 스레드들이 처리하는 것 알고 계셨나요?
Application 실행하고, Log가 찍히는 곳을 보면 스레드 번호를 확인 할 수 있습니다.
- 요청 1 : 주황색
- 요청 2 : 보라색 부분
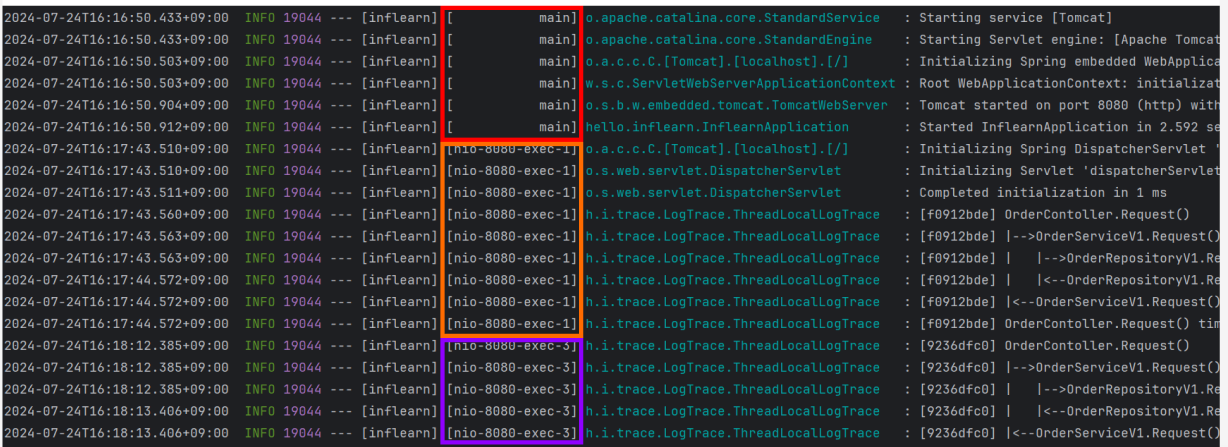
HTTP 요청이 끝나기 전까지는(ThreadId가 유지되는 기간) 하나의 Thread가 계속 관리하므로,
그래서 TraceId를 공유하는 것이 아닌, TraceId를 Thread 별로 관리하면 어떻게 될까?
ThreadLocal 선언
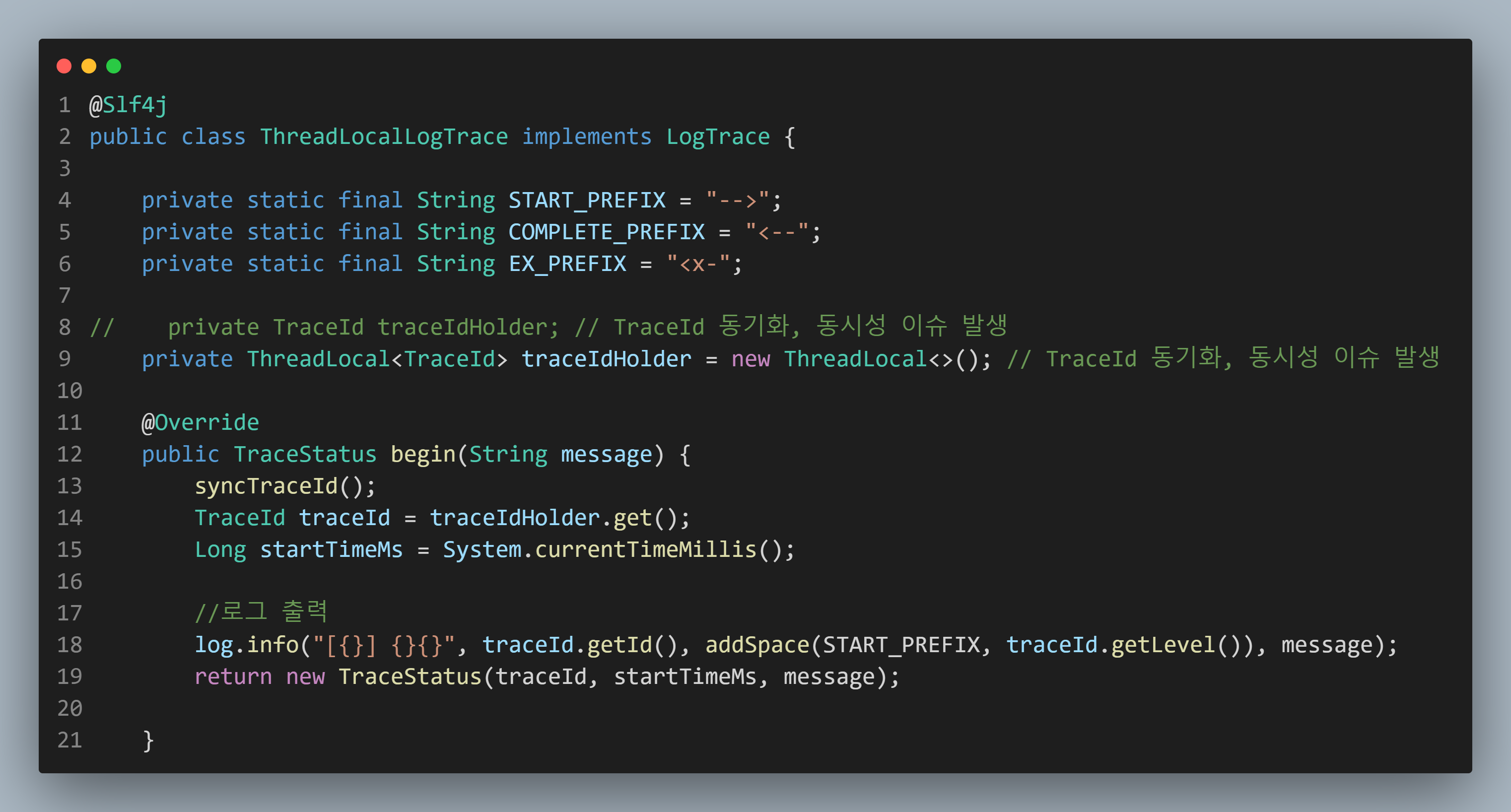
바뀐점은 8번째 Line을 9번째 Line으로 변경한 점입니다.
기존에 그냥 사용하던 클래스 객체를 ThreadLocal로 관리합니다.
사용법
private ThreadLocal<TraceId> traceIdHolder = new ThreadLocal<>();
// 값 가져오기
TraceId traceId = traceIdHolder.get();
// 값 설정하기
traceIdHolder.set(traceId);
// 값 삭제하기
traceIdHolder.remove(); // 이 스레드가 저장한 데이터를 삭제ThreadLocal 주의사항
꼭 값을 다 사용하고 나면 traceIdHolder.remove();을 통해서 값을 지워주어야 합니다.
스레드는 계속 돌려서 쓰기 때문에, 값을 지우지 않는다면 다른 요청이 들어올 때 남겨진 값을 사용할 수도 있습니다.
그러니 ❗꼭❗ 값을 다 사용했다면 지워야 합니다!
