- 가상 면접 사례로 배우는 대규모 시스템 설계 기초
- MySQL 락, 트랜잭션 under the hood
가상 면접 사례로 배우는 대규모 시스템 설계 기초
개략적인 규모 추정
2의 제곱수
데이터 볼륨 단위
응답지연 값
34페이지
가용성에 관계된 수치
- 고가용성(high availability)
- 정의 : 시스템이 오랜 시간 동안 지속적으로 중단 없이 운영될 수 있는 능력을 지칭하는 용어
- % 로 표현한다.
- 대부분의 서비스는 99 ~100% 사이의 값을 가진다.
- QPS (Query Per Second)
설계 면접
- 요구사항 파악부터
- 시스템 구축에 필요한 정보 수집
- 설계안 제시 및 동의
- 사소한 세부사항을 설명하느라 정작 여러분의 능력을 보일 기회를 놓쳐버리게 될 수도 있다.
면접관에게 긍정적 신호를 전달하는 데 집중해야 된다.
- 마무리
- 병목구간, 개선점 탐구
- 오류 발생시 파생 문제 추측
- 미래 규모확장 대응 제시 Good
처리율 제한 장치 설계
- 처리율 제한 장치
- 정의 : 클라이언트 또는 서비스가 보내는 트래픽의 처리율을 제어하기 위한 장치
- 처리율 제한 알고리즘
- 토큰 버킷
- 누출 버킷
- 고정 윈도 카운터
- 이동 윈도 로그
- 이동 윈도 카운터
분산 키-값 저장소
CAP
- 데이터 일관성(consistency) : 분산 시스템에 접속하는 모든 클라이언트는 어떤 노드에 접속했느냐에 관계없이 언제나 같은 데이터를 보게 되어야 한다.
- 가용성(availability) : 분산 시스템에 접속하는 클라이언트는 일부 노드에 장애가 발생하더라도 항상 응답을 받을 수 있어야 한다.
- 파티션 감내(partition tolerance) :
- 파티션 : 두 노드 사이에 통신 장애가 발생하였음을 의미한다.
- 네트워크에 파티션이 생기더라도 시스템은 계속 동작하여야 한다.
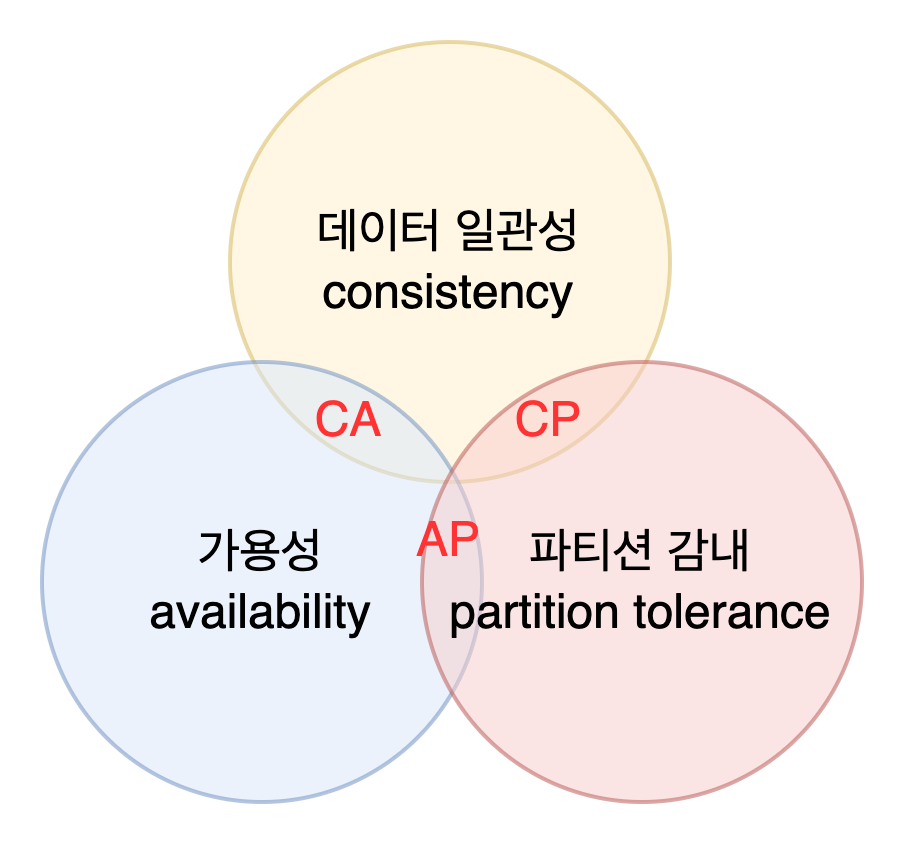
- CP 시스템 : 가용성을 희생한다.
- AP 시스템 : 데이터 일관성을 희생한다.
- CA 시스템 : 일관성과 가용성을 지원하는 키-값 저장소. 파티션 감내를 희생한다. 그러나 네트워크 장애는 반드시 감내해야 하므로 실세계에 CA 시스템은 존재하지 않는다.
점핏 [토스뱅크 기업문화와 성장하는 주니어 특징]

업무 범위의 제약
- 팀, 조직이 잘 나뉜 회사에 가면 업무 범위의 제약이 생긴다.
그럼 어떻게 성장해야 하나?
-
BEST : 조직문화가 좋은 곳. 그러나 현실적으로 이런 회사는 별로 없음
-
요청, 설득을 끊임없이 해야된다.
-
주위에서 안 한다고 해서 나도 가만히 있지 말아라.
- 맥락 & 목표를 제시하고 설득해라
품질 책임 조직
- 본질적 목표는 좋은 서비스 제공을 빠르게 하는 것.
- [출시 일정 & 테스트 가능한 상황] : 그러나 테스트를 진행할 수 있는 환경을 만드는 것이 목표가 되어 버린다.
- 이 악순환은 개발 완성도, 책임감이 점점 떨어진다.
내 성장에 도움이 되는 방향은?
- 역시나 설득, 주장해라
조직 전체의 목표 Align & 조직 OKR 인센티브
-
토스 문화

원팀의 목표 / 같은 인센티브
부서별 인센티브가 아니라 목표 달성하면 관련된 모든 부서가 같은 인센티브를 받는다.
개인에게 맞는 환경
- 나한테 맞는 회사 찾아라…. (어렵네)
어떤 간헐적인 문제
- 단순하게 문제를 해소하고 그냥 넘어가면 안된다!!! 끝까지 파본다
- 오픈소스 환경 : 학습하기 너무 좋다.
조직의 성과관리를 위한 OKR, 제대로 쓰려면 어떻게 해야 할까? | 패스트캠퍼스
책 추천
Q&A
- 스페셜리스트 & 제너럴리스트 견해
- 지금은 다 해야된다……
- 학습에 시간을 엄청나게 쏟아야 한다……
- 찔끔 찔끔 오래 공부하지 말고 전투적으로 공부해라…..
- MSA 아키텍처. 어느 규모에 적당하냐
- 토스도 처음엔 MSA 아니였음. 중간에 필요에 의해서 전환했음
- 모바일은 MSA 로 시작했음
- MSA 는 조직의 규모나 특성에 맞춰야한다.
- 높은 엔지니어 역량이 필요한 이유는 MSA 로 전환했을때 발생하는 이슈에 대응할 수 있어야하기 때문
혼.공.컴.운
명령어 : 연산 코드 + 오퍼랜드
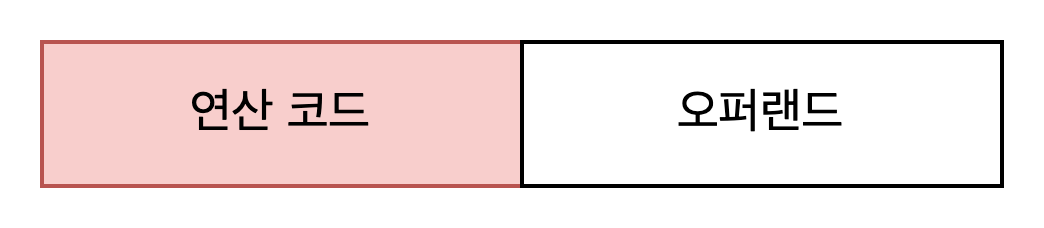
연산 코드
명령어가 수행할 연산 / 연산자
종류
- 데이터 전송
- 산술/논리 연산
- 제어 흐름 변경
- 입출력 제어
명령어의 종류와 생김새는 CPU 마다 다르기 때문에 연산 코드의 종류와 생김새 또한 CPU 마다 다르다.
오퍼랜드
연산에 사용할 데이터
또는
연산에 사용할 데이터가 저장된 위치 / 피연산자
- 오퍼랜드에 주로 데이터가 저장된 위치를 담는 이유
하나의 명령어가 n 비트로 구성되어 있을 경우 오퍼랜드의 데이터 범위가 제한된다.
주소를 담음으로써 메모리 주소에 저장할 수 있는 공간만큼 커진다.
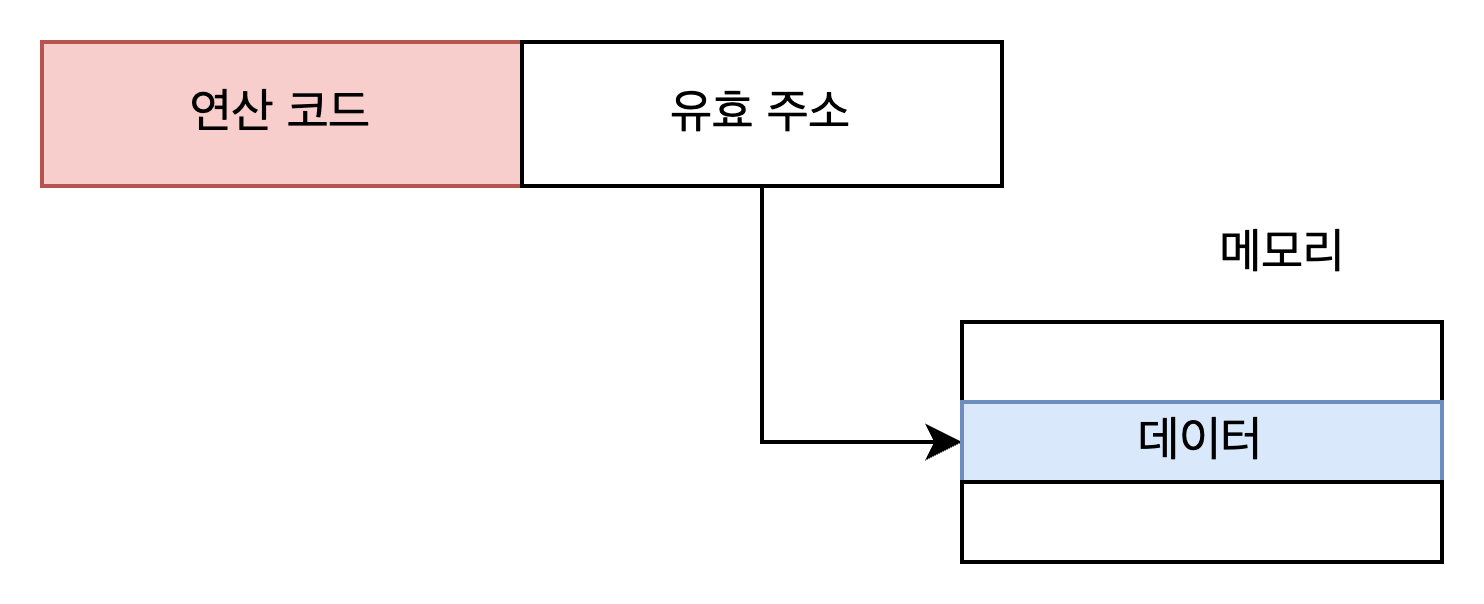
유효 주소 (effective address)
연산의 대상이 되는 데이터가 저장된 위치
주소 지정 방식
오퍼랜드 필드에 데이터가 저장된 위치를 명시할 때 연산에 사용할 데이터 위치를 찾는 방법
-
즉시 주소 지정 방식
연산에 사용할 데이터를 오퍼랜드 필드에 직접 명시하는 방식 -
직접 주소 지정 방식
오퍼랜드 필드에 유효 주소를 직접적으로 명시하는 방식
-
간접 주소 지정 방식
유효 주소의 주소를 오퍼랜드 필드에 명시
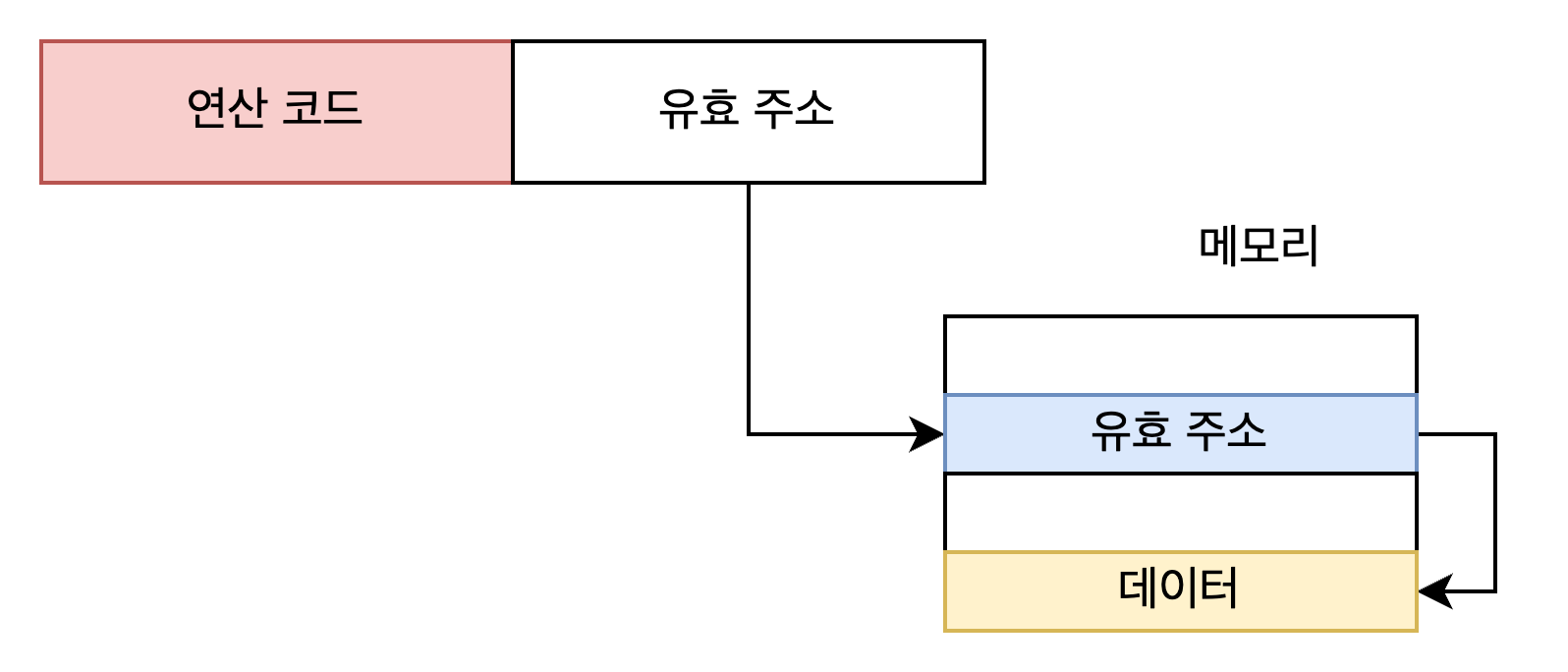
두 번의 메모리 접근이 필요하다 -
레지스터 주소 지정 방식
직접 주소 지정 방식과 비슷하다. 차이점은 데이터의 주소가 CPU 내부에 있는 레지스터를 참조한다. -
레지스터 간접 주소 지정 방식
연산에 사용할 데이터를 메모리에 저장하고, 그 주소를 저장한 레지스터를 오퍼랜드 필드에 명시하는 방법
간접 주소 지정 방식과 차이점은 메모리에 한 번만 접근한다. 그래서 더 빠르다.

개발자