- 어제 학습 부족했던 B-tree 인덱스 다시 정리
1. 학습 주제
- B-Tree 란
- 정렬 방법
- 데이터 조회 과정
- 장점&단전
2. 알게 된 내용
- 인덱스는 데이터를 찾을때 빠르게 찾기위해 사용하는 것이다.
- MySQL 의 인덱스 :
PRIMARY KEY,UNIQUE,INDEX, andFULLTEXT
- MySQL 의 인덱스 :
- MySQL이 인덱스를 사요하는 연산
Wherecluase- row 삭제 작업에서도 인덱스를 사용하는데 multiple 인덱스라면 MySQL은 row가 더 적은 인덱스를 사용한다
(col1, col2, col3)다중 인덱스를 생성하면col1),(col1, col2), and(col1, col2, col3)개의 인덱스를 사용할 수 있다.- join
- MIN(), MAX()
- sort, groupby
- B-Tree 란 인덱스를 정렬하는 알고리즘이다.
- B-Tree 의 인덱스 key, value 구조에서 key 에 사용되는 컬럼은 값을 변형하지 않고 항상 정렬된 상태로 유지한다.
- B-Tree 규칙
- 노드가 자녀를 x개 가졌다면 key 는 x-1개를 가진다.
- 파라미터
- M : 각 노드의 최대 자녀 노드 수
- M-1 : 각 노드의 최대 key(page) 수
- M/2 : 각 노드의 최소 자녀 노드 수
- M/2 -1 : 각 노드의 최소 key(page) 수
- B-Tree 는 루트 노드, 브랜치 노드, 리프 노드로 구성된다.
- 리프 노드는 데이터 파일에 저장된 레코드의 주소를 갖는다.
- MyISAM 엔진에서는 실제 물리 주소를 갖는다.
- InnoDB 에서는 논리 주소를 갖는데, 레코드의 ID 역할을 하는 PK 다
- B-Tree 데이터 삽입
- 추가는 항상 leaf 노드에 한다.
- 모든 leaf 노드들은 같은 레벨에 있다.
- balanced tree
- 검색 avg/worst case O(logN) 항상 같은 성능을 보인다.
- 모든 leaf 노드들은 같은 레벨에 있다.
- 노드가 넘치면 가운데 key를 기준으로 좌우 key들은 분할하고 가운데 key는 승진한다.
- 추가는 항상 leaf 노드에 한다.
- B-Tree 데이터 삭제
- 삭제는 항상 leaf 노드에서 발생
- 삭제 후 최소 key 수보다 적어졌다면 재조정한다
- B-tree 는 키 추가는 리프 노드부터 시작해 노드의 최대 키 개수가 초과되면 상위 노드까지 작업이 필요하기 때문에 비용이 큰 작업이다. 그래서 InnoDB 엔진은 키 추가를 바로바로 하지 않고 체인지 버퍼에 버퍼링 해둬 추가 작업을 지연시킨다.
- 인덱스 키 변경
- 인덱스는 항상 정렬된 상태를 유지해야하기 때문에 변경할 키를 먼저 삭제한 뒤 다시 새로운 키 값을 추가한다. 역시 InnoDB 엔진에서는 체인지 버퍼로 작업을 지연시킬 수 있다.
- 키 추가, 변경에 큰 비용필요해도 인덱스를 사용하는 이유는 검색에 있다.
- 100% 일치 또는 값의 앞부분만 일치하는 경우에 사용할 수 있음
- 인덱스를 구성하는 키 값의 뒷부분만 검색하는 용도로는 인덱스를 사용할 수 없다. WHY?
- 인덱스 키 값에 변형이 가해진 후 비교되는 경우에는 인덱스를 통한 빠른 검색을 사용할 수 없다.
- 데이터를 찾을 때 탐색 범위를 빠르게 좁힐 수 있다.
- B tree 노드는 block 단위의 저장 공간을 알차게 사용할 수 있다.
B-Tree 인덱스 사용에 영향을 미치는 요소
- 인덱스 키 값의 크기
- B-Tree 인덱스에서 Key-Value 쌍의 인덱스는 Page 또는 Block 단위로 저장된다. 이 Page 의 크기는 기본 16KB 다. 키의 크기에 따라서 담을 수 있는 키의 개수가 변한다.
- 키의 값이 커지면 하나의 페이지에 담을 수 있는 키의 개수가 줄어든다. 페이지는 버퍼링에서도 기본 단위인데 인덱스 키의 크기가 메모리에 캐시할 레코드 수도 줄어든다 → 메모리 효율이 떨어진다.
- B-Tree 의 깊이
- 인덱스 키 크기가 커져서 페이지가 담을 수 있는 키가 줄어들어 페이지 분할이 더 빨리 자주 발생하므로 트리의 깊이가 더 깊어진다. 이는 인덱스를 탐색에 더 많은 단계가 필요하다. 즉, 디스크 읽기가 더 많이 필요하게 된다.
- 선택도
- 모든 인덱스 키 값 가운데 유니크한 값의 수를 의미한다.
- 인덱스 키 값 가운데 중복된 값이 많을수록 기수성은 낮아지고 동시에 선택도 또한 떨어진다.
- 인덱스는 선택도가 높을수록(유니크한 값이 많을수록) 검색 대상이 줄어든다
주소에서 도시명 vs 행정동 서울시 광진구 성수동을 찾을 때 서울시 검색결과 1000개 내에서 1개찾냐 성수동 검색결과 10개 내에서 찾냐
- 읽어야 하는 레코드 건수
- 인덱스를 이용한 읽기의 손익 분기점이 얼마인지 판단하자
- 20~25% 이하일 경우 유리
B-Tree 인덱스를 통한 읽기에서 레코드를 찾아가는 방법
스캔 : 차례대로 읽는 것
- 인덱스 레인지 스캔
- 검색해야 할 인덱스의 범위가 결정됐을 때 사용하는 방식
- 리프 노드에서 시작해야 할 위치를 찾으면 그때부터 순서대로 읽다가 멈춰야할 위치에 도달하면 멈춘다. (인덱스 탐색)
- 리프 노드에서 시작해야 할 위치를 찾으면 그때부터 순서대로 읽다가 멈춰야할 위치에 도달하면 멈춘다. (인덱스 탐색)
- 다음 리프 노드를 읽어야하면 포인터로 다음 리프 노드를 찾아가서 스캔한다. (인덱스 스캔)
- 인덱스 자체의 정렬 특성때문에 실제 레코드는 인덱스 키 컬럼의 정순 또는 역순으로 읽어오게 된다.
- 인덱스 풀 스캔
- 인덱스 처음부터 끝까지 모두 읽는 방식
- 인덱스가 (a, b, c) 컬럼으로 만들어져 있지만 조건절이 b나 c로 검색하는 경우
- 테이블 풀 스캔보다는 효율적이다.
- 인덱스에 포함된 컬럼으로만 쿼리를 처리할 수 있는 경우 테이블의 레코드를 읽을 필요가 없기 때문
- 루스 인덱스 스캔
3. 설명하기 어려운 부분
- B-tree self balanced tree
- B-Tree CURD 설명
- B-tree 의 각 노드를 설명하기 어렵다
- ROWID
- 인덱스 크기가 미치는 영향
4. 다시 정리
- 인덱스란 파일 시스템에 있는 데이터를 찾을 때 디스크를 풀 스캔하지 않고 데이터의 위치 정보를 따로 저장하여 이 위치 정보를 참조해 검색 속도를 높이기 위해 사용하는 key, value 쌍으로 된 데이터다.
- key, value 쌍에서 key 는 레코드의 특정 컬럼 데이터, value 는 레코드의 주소를 저장한다.
- 인덱스도 한 row 마다 생성되는데 항상 정렬되어 저장한다. 레코드의 주소를 찾기 위해 인덱스 역시 검색이 필요한에 검색 시간 복잡도를 향상시키기 위한 알고리즘을 사용한다. 대표적으로 B-Tree가 있다.
- B-Tree 는 self Balanced Tree 라고 한다. Balanced Tree 라고 부르는 이유는 B-Tree 의 자식 노드들은 항상 균형된 상태를 유지한다. B-Tree와 유사한 이진 탐색 트리는 비대칭 노드도 생겨날 수 있다.
 이진 탐색트리의 경우 한쪽으로 쏠리게되면 최악의 경우 O(n)의 시간복잡도가 걸린다.
이진 탐색트리의 경우 한쪽으로 쏠리게되면 최악의 경우 O(n)의 시간복잡도가 걸린다. 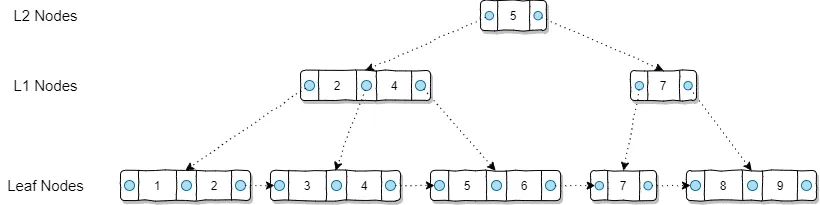 B-Tree 는 항상 양쪽 균형있는 트리를 유지하면서 O(logN) 을 보장한다.
B-Tree 는 항상 양쪽 균형있는 트리를 유지하면서 O(logN) 을 보장한다.
-
B-Tree 의 구조는 Root Node, 브랜치 노드, leaf Node 로 구성된다.
-
루트 노드 : 트리의 시작이 되는 노드
-
브랜치 노드 : 루트 노드와 리프 노드 사이의 모든 노드
-
리프 노드 : 트리의 맨 마지막 층 노드로 레코드의 주소값을 가지고 있다.
-
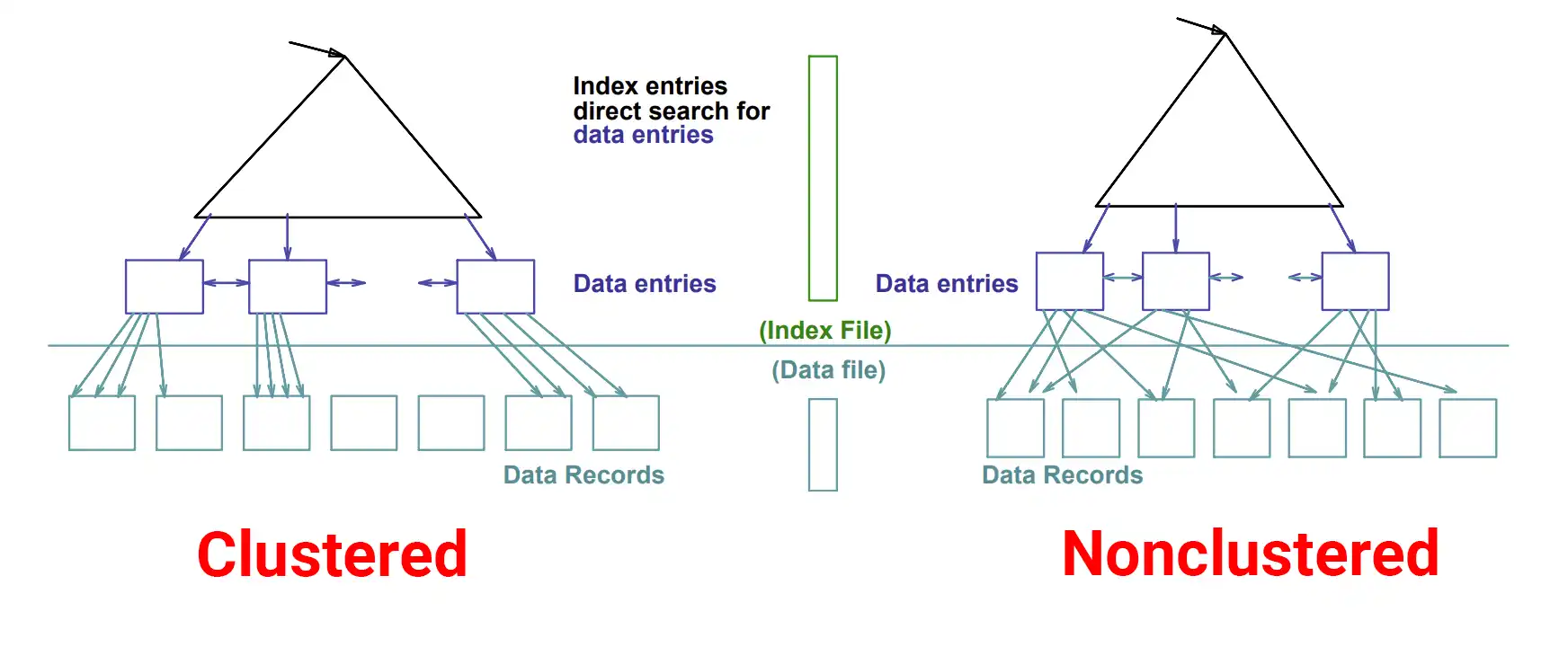
리프 노드의 데이터 페이지가 실제 레코드인 경우를 clustered 인덱스
-
리프 노드의 데이터 페이지가 레코드의 주소인 경우는 Nonclustered 인덱스라 한다.
- MyISAM은 물리적 주소를 저장한다
- InnoDB는 pk 로 논리적 주소를 갖는다. -
위에서 인덱스는 항상 정렬된 상태를 유지한다고 했다.
- clustered 인덱스에서는 리프 노드의 페이지가 실제 레코드이므로 레코드들이 물리적으로 정렬되어있다.
- Nonclustered 인덱스의 리프 노드는 레코드의 주소값을 가진다. 실제 레코드들은 정렬되어 있지 않다.
💡 InnoDB 에서는 기본적으로 테이블의 레코드는 프라이머리 키 순서대로 저장된다. - clustered 인덱스에서는 리프 노드의 페이지가 실제 레코드이므로 레코드들이 물리적으로 정렬되어있다.
-

개발자