학습 목표
- Map
학습 결과 요약
- HashMap 의 버킷의 자료구조는 LinkedList 와 BST 를 혼합해서 사용한다.
- HashMap 와 HashTable 의 차이는 HashMap 은 동기화를 지원하지 않고 해시 보조 함수를 사용한다.
- load-factor 는 버킷의 적재율을 나타나는데 적재율에 도달하면 bucket 의 용량을 늘리고 rehash과정을 거친다. 이 과정이 빈번하게 발생되지 않도록 초기 용량 설정과 적절한 load-factor 설정이 중요하다.
학습 내용
Map
특징
-
key 와 value 를 맵핑하는 자료구조
-
key 는 중복될 수 없다.
-
key 는 최소한 하나의 value 를 가져야 한다.
-
3가지 collection view 를 제공한다. 데이터가 넣어진 순서를 보장하지 않는다. (TreeMap 제외)
- a set of key
- a set of key-value
- a collection of values
-
equals()Compares the specified object with this map for equality. Returns true if the given object is also a map and the two maps represent the same mappings. More formally, two maps m1 and m2 represent the same mappings if m1.entrySet().equals(m2.entrySet()). This ensures that the equals method works properly across different implementations of the Map interface.
-
hashCode()Returns the hash code value for this map. The hash code of a map is defined to be the sum of the hash codes of each entry in the map's entrySet() view. This ensures that m1.equals(m2) implies that m1.hashCode()==m2.hashCode() for any two maps m1 and m2, as required by the general contract of Object.hashCode.
HashMap
Map 인터페이스의 구현 클래스
특징
- key 에 하나의 null 을 허용한다.
- Hashtable 클래스와의 차이점은 다음과 같다:
- 동기화를 지원하지 않는다.
- key 가 null 인 경우는 한 개만 허용하며, value는 여러 개의 null을 허용한다.
- HashMap 은 보조 해시함수를 사용하기 때문에 보조 해시 함수를 사용하지 않는 HashTable 에 비해서 해시 충돌이 덜 방생할 수 있어 성능상 이점이 있다.
- hash 메서드가 key 에 대해 해시값을 생성해 요소들을 적절하게 bucket 에 적절하게 분배한다는 전제하에
get(), put()메서드는 constant time 의 시간복잡도를 제공해야한다. - HashMap 성능에 영향을 미치는 두 요소 :
- initial capacity : capacity 는 hash table 의 bucket 의 개수이며, initial capacity 는 해시 테이블이 생성될 때 초기 bucket 수
- load factor
- hash table 의 적재율.
적재율에 도달하면 해시 테이블은 capacity(bucket 수) 를 늘리면서
기존 데이터의 해시값을 재생성하는 rehash 과정을 거친다. - 기본 load factor는 0.75인데, 공간이나 시간에서 적절한 트레이드 오프를 보이기 때문이다.
- 적재율을 높게 잡으면 기존 buckets 들에 데이터를 더 많이 적재해야 하므로 space 비용을 낮추는 대신 lookup 비용이 높아진다.
- hash table 의 적재율.
- static inner class 로 Node<K, V> 이 선언되어 있는데 Map 의 엔트리를 저장하는 용도로 사용한다.
buckets ( or bins)
- HashMap 은 여러 bucket 을 보관하고 있다.
- 각 bucket 은 단방향 링크드 리스트 형태로 head Node 의 참조값을 저장한다.
- HashMap 클래스에서 buckets 은
Node<K, V> table필드다./** * The table, initialized on first use, and resized as * necessary. When allocated, length is always a power of two. * (We also tolerate length zero in some operations to allow * bootstrapping mechanics that are currently not needed.) */ transient Node<K,V>[] table;
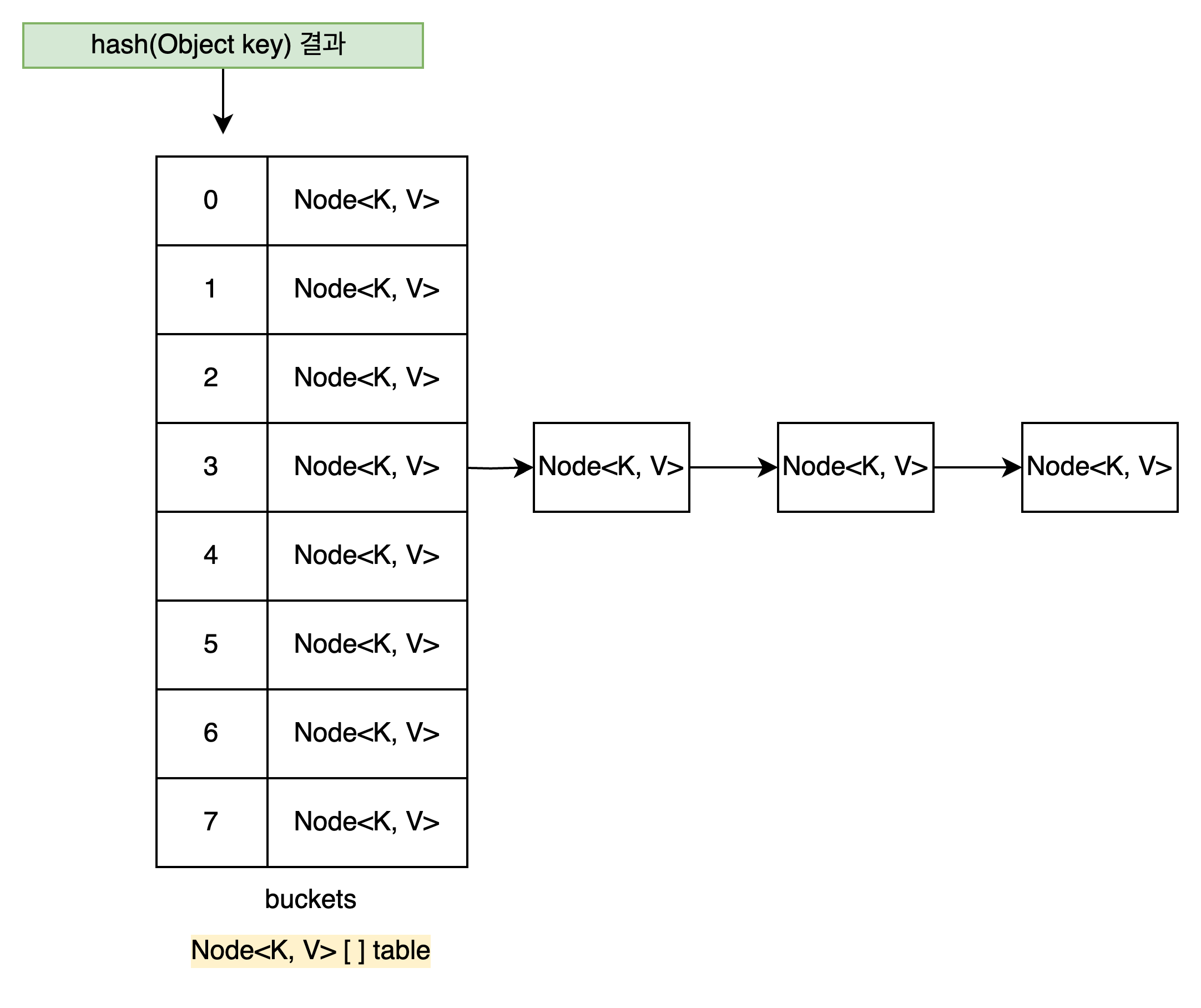
singly-linked-list
- bucket 의 자료구조는 singly-linked-list 에서 Tree 로 변환된다.

한 bucket 의 Node 수가 TREEIFY_THRESHOLD 에 도달하면 bucket 의 자료구조가 singly-linked-list 에서 Tree 로 변환된다.
Linked-List 의 검색 시간 복잡도는 O(n) 이기 때문에 검색 성능 개선을 위해 Java8 부터 변경 되었다고 한다.
잘못된 해싱 함수로 인해 하나의 버킷에 많은 데이터가 저장되어도 트리 구조에서는 검색 시간 복잡도가 O(logn) 이기 때문에 어느 정도 상쇄될 수 있다고 한다.
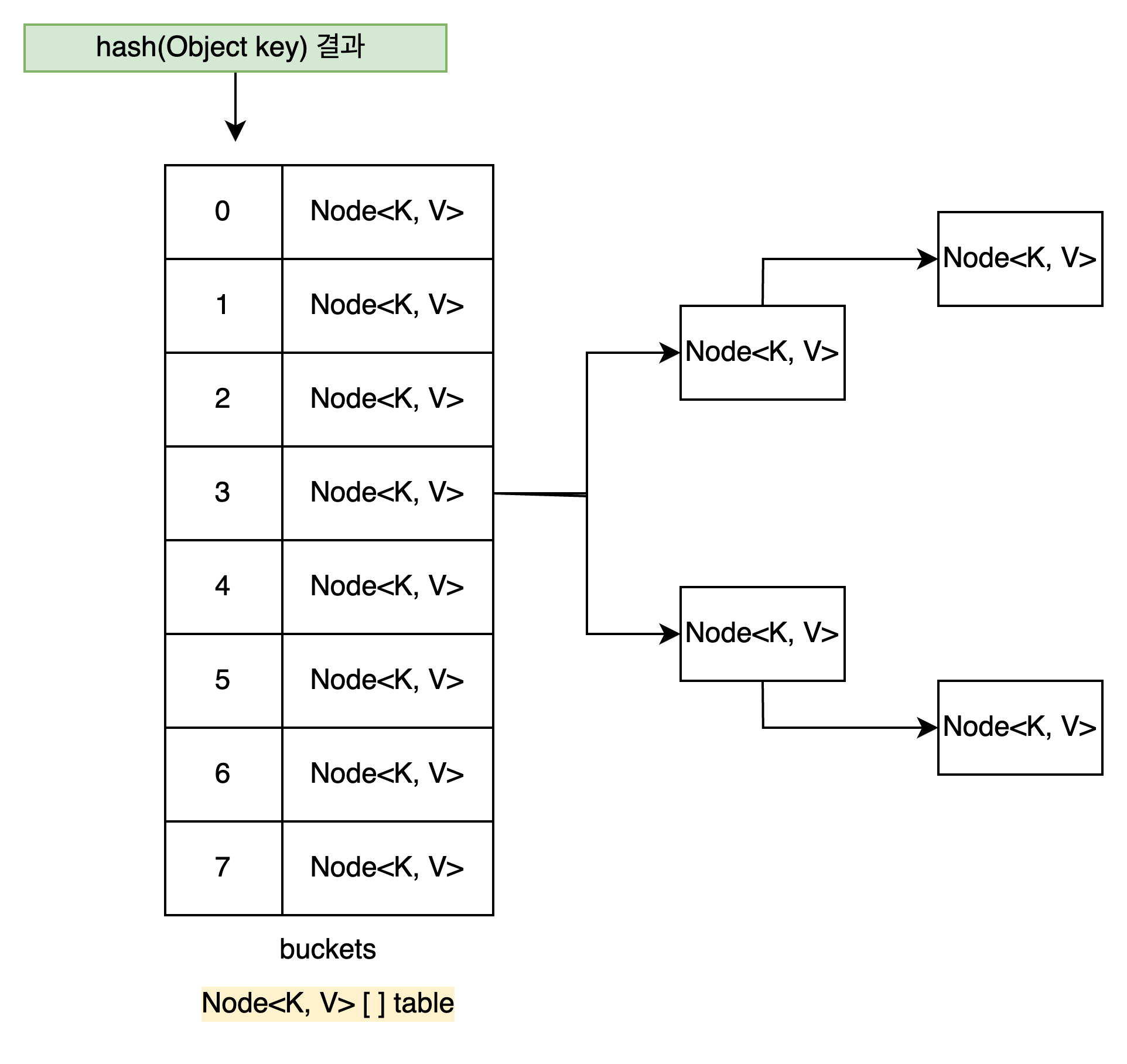
Binary-Search-Tree
putVal , HashMap 이 데이터를 넣기 처리하는 메서드
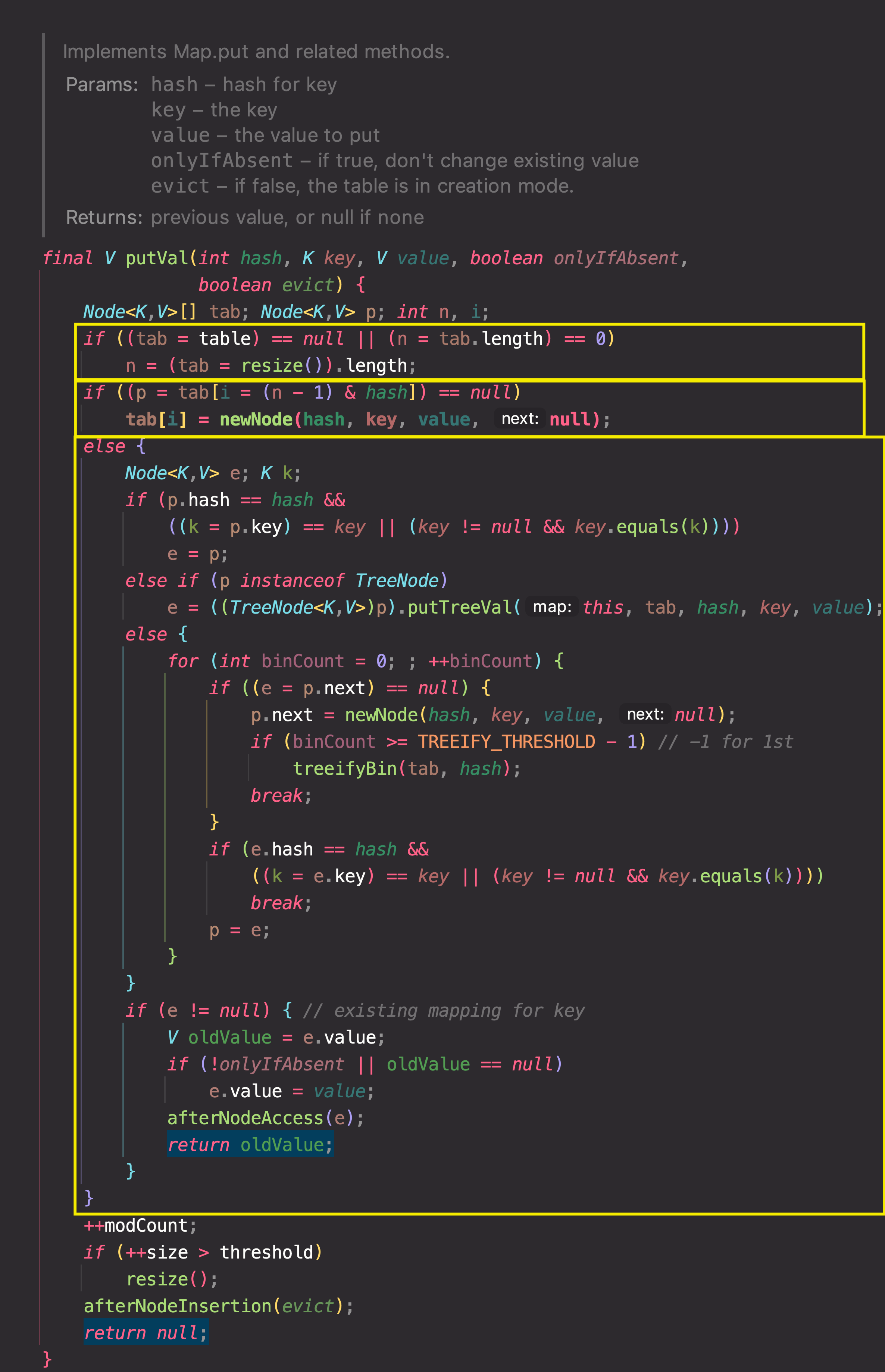
지역변수
Node<K, V>[] tab : bucket 배열
Node<K, V> p :
bucket 배열에 넣어야할 Node
int n :
bucket 배열의 길이
- bucket 배열이 초기화 전(
tab==null) 이거나length == 0이면
resize() 를 호출하고 지역 변수n에 초기화된 bucket 배열의 사이즈를 할당한다. - 매개변수 hash 값으로 bucket 배열의 인덱스에 있는 Node 를 찾아
p에 할당한다.
**p == null**이면 Node 를 생성하고 bucket 배열에 할당한다. - else 구문은 2번과 달리 hash 로 검색한 bucket 배열에 이미 할당된 Node 가 있는 경우를 처리한다.
-
지역변수 -
Node<K,V> e,K k: Key 객체 참조값 -
bucket 배열에 이미 있는
Node p와 새로 넣을 K-V 쌍에서 동등한 Key 객체인지 확인한다.동등한 Key 객체일 경우
e에 기존Node p를 할당한다. -
동등한 Key 객체가 아닌 경우 bucket 에 Node 를 추가해야 하는데,
HashMap 은 bucket 의 사이즈가 임계치를 넘으면 Linked-list → Tree 로 변환하기 때문에
Node 가 TreeNode 인지 아닌지 검사한 뒤 분기 처리한다.
-
hash(Object key)
buckets 의 인덱스를 계산하는 메서드
/**
* Computes key.hashCode() and spreads (XORs) higher bits of hash
* to lower. Because the table uses power-of-two masking, sets of
* hashes that vary only in bits above the current mask will
* always collide. (Among known examples are sets of Float keys
* holding consecutive whole numbers in small tables.) So we
* apply a transform that spreads the impact of higher bits
* downward. There is a tradeoff between speed, utility, and
* quality of bit-spreading. Because many common sets of hashes
* are already reasonably distributed (so don't benefit from
* spreading), and because we use trees to handle large sets of
* collisions in bins, we just XOR some shifted bits in the
* cheapest possible way to reduce systematic lossage, as well as
* to incorporate impact of the highest bits that would otherwise
* never be used in index calculations because of table bounds.
*/
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}resize(), bucket 동적 확장을 처리하는 메서드
- Node<K, V>[ ] 을 증가된 용량으로 초기한 뒤,
table필드에 할당한다.
