이번주에 Google I/O에서 AI대해 얘기를 많이 했는데,
Gemini 1.5가 나왔다.
AI studio, project IDX (flutter,firebase 지원)등 다양하게 발표를 했는데, AI는 개발자에 있어 필수고 모델을 만들줄 알아야 할 것 같다.
Gpt-4o또한 발표되었는데, 일단 안드로이드 개발자이니 지원해주는 Gemini를 먼저 사용해보려 한다.

Android용 Google AI클라이언트 SDK를 이용해 REST API나 서버를 거치지 않고 Gemini API에 직접 액세스 할 수 있다.
하지만 아직은 안정화 되지않아 프로토 타입으로만 사용하는게 좋을 것 같다.
여기서 APi키를 받고 프로젝트의 local.properties에 저장해준다.
id 'com.google.android.libraries.mapsplatform.secrets-gradle-plugin'그런뒤 Android용 Secrets Gradle 플러그인을 사용해 API키를 buildConfig에 넣어준다.
val apiKey = BuildConfig.apiKeyimplementation("com.google.ai.client.generativeai:generativeai:0.6.0")그런뒤 dependency 를 추가 해준다.
@Composable
fun Main(viewmodel: MainViewModel = viewModel()) {
val state by viewmodel.state.collectAsState()
val (text, setText) = remember { mutableStateOf("") }
Scaffold(
bottomBar = {
TextField(
modifier = Modifier.fillMaxWidth()
.padding(4.dp),
value = text,
onValueChange = setText,
label = { Text(text = "input") },
keyboardActions = KeyboardActions(
onSearch = {}
),
trailingIcon = { Icon(imageVector = Icons.Default.Send, contentDescription = null) }
)
},
) { paddingValues ->
LazyColumn(
modifier = Modifier.padding(paddingValues)
) {
items(count = state.size) {
Card(
modifier = Modifier.padding(16.dp),
) {
Text(text = state[it])
}
Spacer(modifier = Modifier.height(8.dp))
}
}
}
}채팅을 입력하고 출력할 컴포저블을 만들어 줬다.
이제 GenerativeModel를 사용해 Gemini랑 연결할 준비를 한다.
val generativeModel = GenerativeModel(
modelName = "gemini-1.5-pro-latest",
apiKey = BuildConfig.VERSION_NAME,
)여기서 modelName에 gemini-1.5-pro-latest, gemini-1.5-flash-latest 등 Google AI Studio에서 모델명을 찾아서 넣어주고,
연결하기 위한 apiKey를 넣어준다.
모델 설정은 각 모델의 특징을 알아보고 목적에 알맞는 모델을 넣자
GenerativeModel은 그 밖에도 더 설정을 해 줄수 있는 옵션이 많은데
구성요소는 다음과 같다.
class GenerativeModel
internal constructor(
val modelName: String,
val apiKey: String,
val generationConfig: GenerationConfig? = null,
val safetySettings: List<SafetySetting>? = null,
val tools: List<Tool>? = null,
val toolConfig: ToolConfig? = null,
val systemInstruction: Content? = null,
val requestOptions: RequestOptions = RequestOptions(),
private val controller: APIController,
) {generationConfig: 콘텐츠 생성 시 사용할 구성 파라미터들입니다. 이 구성 요소들은 모델이 콘텐츠를 생성할 때 어떤 방식으로 동작할지를 정의한다.
safetySettings: 콘텐츠 생성 시 사용할 안전 경계 설정입니다. 이는 프롬프트와 함께 사용할 안전한 작업 범위를 지정합니다.
systemInstruction: 모델이 특정 방식으로 동작하도록 지시하는 내용을 담고 있습니다. 시스템 명령어는 모델의 동작 방식을 지정하는 데 사용됩니다.
requestOptions: 백엔드 통신 중에 사용할 구성 옵션들입니다. 이 옵션들은 요청을 보낼 때 적용되는 다양한 설정을 포함합니다.
하지만 여기선 간단하게 연결만 해볼 것이니 이부분은 일단 넘어가자
fun sendMessage(chat: String) {
viewModelScope.launch {
generativeModel.generateContent("한국어로 대답해줘: $chat").text?.let {
_state.value = state.value + listOf(it)
}
}
}그런뒤 생성된 모델에 프롬프트를 generateContent()를 통해 넣어준다.
그런 뒤 작업이 완료되면 .text를 통해 문장을 받아온다
generateContent()는 단순 텍스트 말고도 이미지를 틀어가 보자
suspend fun generateContent(prompt: String): GenerateContentResponse =
generateContent(content { text(prompt) })
suspend fun generateContent(vararg prompt: Content): GenerateContentResponse =
try {
controller.generateContent(constructRequest(*prompt)).toPublic().validate()
} catch (e: Throwable) {
throw GoogleGenerativeAIException.from(e)
}generateContent는 Content타입으로 받고 Flow로 반환하는 걸 볼 수 있다.
그러면 Content를 들어가보면 내가 보낼수 있는 데이터들을 볼 수 있을 것이다.
class Content @JvmOverloads constructor(val role: String? = "user", val parts: List<Part>) {
class Builder {
var role: String? = "user"
var parts: MutableList<Part> = arrayListOf()
@JvmName("addPart") fun <T : Part> part(data: T) = apply { parts.add(data) }
@JvmName("addText") fun text(text: String) = part(TextPart(text))
@JvmName("addBlob") fun blob(mimeType: String, blob: ByteArray) = part(BlobPart(mimeType, blob))
@JvmName("addImage") fun image(image: Bitmap) = part(ImagePart(image))
@JvmName("addFileData")
fun fileData(uri: String, mimeType: String) = part(FileDataPart(uri, mimeType))
fun build(): Content = Content(role, parts)
}
}part는 각 파트별 기본 타입이다.
interface Part
/** Represents text or string based data sent to and received from requests. */
class TextPart(val text: String) : Part
/**
* Represents image data sent to and received from requests. When this is sent to the server it is
* converted to jpeg encoding at 80% quality.
*/
class ImagePart(val image: Bitmap) : Part
/** Represents binary data with an associated MIME type sent to and received from requests. */
class BlobPart(val mimeType: String, val blob: ByteArray) : Part
/** Represents an URI-based data with a specified media type. */
class FileDataPart(val uri: String, val mimeType: String) : Part파트 인터페이스를 들어가면 이렇게 나와있다.
텍스트파트와, 이미지 파트, 바이너리 데이터와, 파일 데이터가 있는걸 볼 수있다.
이는 AI에 보낼 데이터의 타입들인데,
단순 글자 뿐만 아니라, 비트맵 이미지, 음성 비디오와 같은 바이너리 데이터와 json,html,csv등 파일 또한 보낼 수 있다.
이미지도 보내보자
val imageUris = rememberSaveable(saver = UriSaver()) { mutableStateListOf() }
val bitMaps = remember { mutableStateListOf<Bitmap>() }
val pickMedia = rememberLauncherForActivityResult(
ActivityResultContracts.PickVisualMedia()
) { imageUri ->
imageUri?.let {
imageUris.add(it)
}
}
...
Row(
verticalAlignment = Alignment.CenterVertically,
modifier = Modifier
.fillMaxWidth()
.padding(8.dp)
) {
ImagePicker(imageUris = imageUris) {
bitMaps.add(it)
}
IconButton(
onClick = {
pickMedia.launch(
PickVisualMediaRequest(ActivityResultContracts.PickVisualMedia.ImageOnly)
)
},
modifier = Modifier.padding(start = 8.dp)
) {
Icon(
imageVector = Icons.Default.Add,
contentDescription = null
)
}
}이미지를 받아줄 컴포저블을 만들어주고 비트맵이 비워져 있지 않다면 이미지와 채팅을 함께 보낸다.
fun sendMessageWithImage(chat: String, images: List<Bitmap>) {
val prompt = "이미지를 보고 대답해줘: $chat"
viewModelScope.launch {
val inputContent = content {
images.forEach { bitmap ->
image(bitmap)
}
text(prompt)
}
generativeModel.generateContentStream(inputContent).collect { respone ->
_state.value = state.value + listOf(respone.text ?: "")
}
}
}뷰모델에선 content를 만들어 bitmap으로 변환한 이미지와 텍스트를 보내주고
값을 받아올 수 있다.
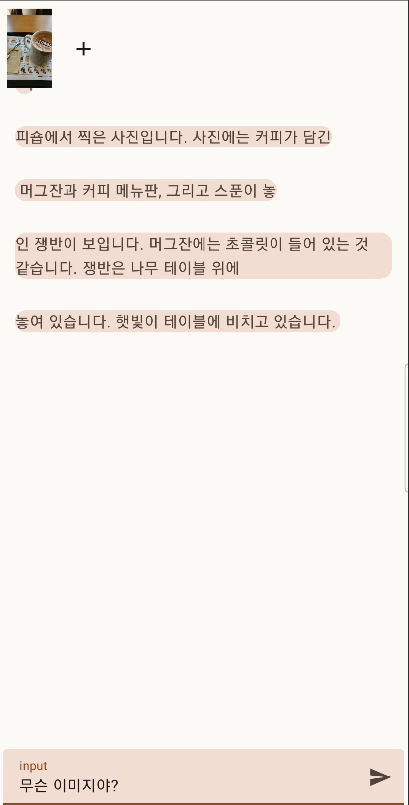
문장들을 나눠서 반응이 왔다.
아무래도 긴 문장인 경우 나눠서 보내는 것 같은데,
화자를 구별한뒤 화자가 변하지 않았다면 이전 문장에 이어서 붙여 넣는식으로 구현하면 좀더 자연스럽게 구현이 가능할것 같다.
