Apollo 캐시 공식 문서
https://www.apollographql.com/docs/react/caching/cache-configuration/
이 글은 위 사이트의 캐시 관련 내용을 정리한 글입니다. 오타, 오역이 있으면 말해주세요 :)
Apollo 클라이언트는 GraphQL 쿼리를 로컬에 저장할 수 있는 캐시 기능을 제공한다. 클라이언트에서 서버로 GraphQL 쿼리를 요청하면 그 결과를 클라이언트 측 메모리에 특정 규칙에 따라 저장한다. 이렇게 캐시된 결과는 이후에 클라이언트 측에서 동일한 쿼리를 요청할 때 재사용할 수 있어 불필요한 데이터 요청을 줄일 수 있다.
Apollo 클라이언트 3.0부터 InMemoryCache를 기본적으로 제공하기 때문에 추가적인 라이브러리 설치는 필요하지 않다.
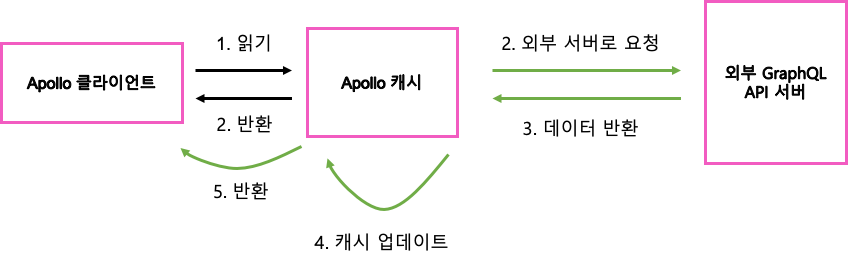
Apollo 캐시는 기본적으로 위 그림과 같이 동작한다. 먼저 캐시에 원하는 데이터가 있는지 확인하고 있으면 그대로 반환한다. 원하는 데이터가 없으면 외부 서버로 해당 데이터를 요청한 후 재사용을 위해 반환되는 값을 캐시에 쓰고 클라이언트에 넘겨준다. 만약 캐시가 없었다면 데이터가 필요할 때마다 매번 서버로 요청해서 받아오거나, React 컴포넌트 내부에서 직접 캐싱을 구현해야 했을 것이다.
기본 캐시 설정
import { InMemoryCache, ApolloClient } from '@apollo/client';
const client = new ApolloClient({
// ...other arguments...
cache: new InMemoryCache(options)
});위와 같이 ApolloClient를 생성할 때 캐시 객체를 생성해서 넘겨주면 된다. 그리고 InMemoryCache의 options 인수로 아래와 같은 세부적인 경우를 다룰 수 있다.
-
캐시 데이터의 기본키로 설정할 GraphQL 필드
TypePolicy.keyFields -
캐시 데이터를 읽는 방식 설정
TypePolicy.FieldPolicy.read -
캐시에 데이터를 쓰는 방식 설정
TypePolicy.FieldPolicy.merge -
Fragment 상위-하위 자료형 관계 설정?
-
페이지네이션 설정
-
클라이언트 측 상태 관리
@client
캐시 옵션
addTypename: boolean = true
true로 설정되면 모든 쿼리의 모든 객체 필드에 __typename 필드를 자동으로 추가해준다. 그래서 서버가 객체 데이터와 자료형을 같이 반환할 수 있도록 해준다.
query {
event(id: 973) {
id
name
hostOrganization {
id
name
}
...
}
}즉, 위와 같은 GraphQL 요청을
query {
event(id: 973) {
__typename
id
name
hostOrganization {
__typename
id
name
}
...
}
}위와 같이 자동으로 변환해서 요청한다. 이렇게 __typename 추가해야 서버로부터 반환된 객체들의 자료형을 알 수 있고 이를 UID 생성에 활용할 수 있기 때문이다.
typePolicies: { [typename: string]: TypePolicy }
서버 스키마에 있는 특정 자료형을 캐시 내부에서 관리할 방식을 정의할 수 있다. __typename 등에 따라 분류된 데이터를 읽고 쓰는 방식을 정의하거나 데이터 분류 기준을 직접 설정할 수 있다.
resultCaching: boolean = true
(예정)
possibleTypes: { [supertype: string]: string[] }
(예정)
TypePolicy
type TypePolicies = {
[__typename: string]: TypePolicy;
};TypePolicies는 여러 __typename: string-TypePolicy 쌍을 key-value로 가지는 객체로서 서버 스키마에 정의된 모든 자료형 이름을 TypePolicy의 key 값으로 설정할 수 있다. 서버 스키마 내용은 해당 서버의 GraphQL Playgroud SCHEMA 탭에서 확인할 수 있다. 확인해보면 기본적으로 Query와 Mutation 자료형은 정의되어 있을 것이고, 이외에도 다양한 자료형이 있을 수 있다.
type TypePolicy = {
keyFields?: KeySpecifier | KeyFieldsFunction | false;
queryType?: true;
mutationType?: true;
subscriptionType?: true;
fields?: {
[fieldName: string]: FieldPolicy<any> | FieldReadFunction<any>;
};
};-
keyFields: 해당 자료형을 분류할 때 기본키(분류 기준)로 설정할 필드 -
fields: TypePolicy의 하위 필드로서 여러fieldName: string-FieldPolicy쌍을 key-value로 가진다. 이 FieldPolicy에서 해당 필드의 읽기-쓰기 등 여러 정책을 세부적으로 설정할 수 있다. 필드 이름은 서버 스키마에 명시된 필드뿐만 아니라 클라이언트 측에서만 사용될 필드 이름을 정의해도 된다. 이때는 클라이언트에서 보내는 쿼리의 해당 필드 옆에@client키워드를 넣어줘야 한다.
FieldPolicy
type FieldPolicy<TExisting = any, TIncoming = TExisting, TReadResult = TExisting> = {
keyArgs?: KeySpecifier | KeyArgsFunction | false;
read?: FieldReadFunction<TExisting, TReadResult>;
merge?: FieldMergeFunction<TExisting, TIncoming> | boolean;
};-
keyArgs:Query자료형의 하위 필드에서 자주 쓰이는 항목으로서 필드의 인수를 추가 분류 기준으로 설정할 수 있다.keyFields는 자료형을 구분하는 기준이고,keyArgs는 필드를 구분하는 기준으로 사용한다. -
read(), merge(): 이 함수를 통해 필드를 읽거나 필드에 새로운 값을 쓰는 과정을 세부적으로 설정할 수 있다.
캐시 데이터 관리
InMemoryCache는 쿼리 결과 객체에 UID(Unique IDentifier)를 부여해서 관리한다. 데이터가 캐시에 저장되는 기본적인 과정은 아래와 같다.
-
쿼리 결과에 있는 객체에 고유한 ID(UID)를 생성해서 부여한다.
-
동일한 UID를 가지는 객체는 서로 병합한다. 기본적으로 기존 객체의 필드 값은 새로운 값으로 덮어쓰인다. 병합하는 방식은 따로 설정할 수도 있다.
-
캐시된 데이터는 UID를 기준으로 key-value 형식으로 분류한다. 여기서 key는 UID이고 value는 해당 UID를 가진 객체이다.
캐시 상태 확인
(아직 몇몇 기능이 불안정하긴 하지만) 크롬에 Apollo Client Developer Tools 확장 프로그램이 있는데 이를 통해 현재 Apollo 클라이언트의 캐시 상태가 어떤지 확인해볼 수 있다.
캐시에는 기본적으로 ROOT_QUERY 공간이 존재하는데 이곳에 쿼리 결과가 캐싱된다. 아래 그림은 현재 me와 searchEvents의 쿼리 결과가 ROOT_QUERY 공간에 저장되어 있는 모습이다. 그리고 Event 자료형 데이터도 UID를 기준으로 분류돼서 저장되어 있다.
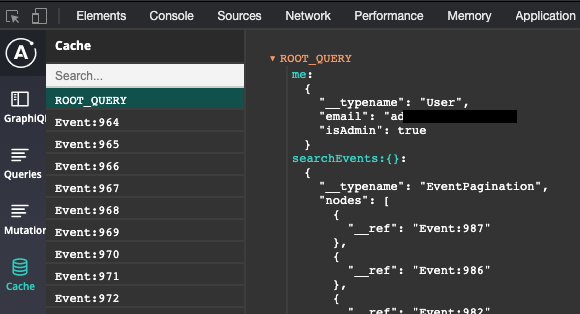
기본적으로 위 그림과 같이 캐시에 데이터가 저장될 때, 데이터 값은 ROOT_QUERY 밖에 UID를 기준으로 분류돼서 저장되고 ROOT_QUERY 안엔 해당 데이터의 UID가 __ref 항목으로 저장된다. 그래서 캐시에 레퍼런스로 저장된 데이터는 직접 읽을 순 없고, Apollo 클라이언트에서 제공하는 readField 함수를 사용해야 한다.
UID 생성 규칙
Apollo 캐시는 기본적으로 __typename 필드를 가진 객체마다 UID를 자동으로 생성해준다. 만약 해당 객체에 id나 _id 필드가 존재하면 UID는 __typename:id로 설정되고, 그런 필드가 없으면서 keyFields도 정의되지 않았으면 캐시에 따로 저장되지 않고 ROOT_QUERY에 값으로 저장된다. 반환된 데이터의 효율적인 캐싱을 위해 (GraphQL 서버에서 지원한다면) 요청할 때 클라이언트 측에서 각 객체 필드에 이 id 필드를 넣어주는 것이 좋다.
{
__typename: "Event",
id: 973,
name: "타입 테스트",
...
}
예를 들어 서버로부터 위와 같이 반환된 객체의 UID는 Event:973로 설정된다.
keyFields
만약 서버에서 각 자료형에 대해 id 필드를 지원하지 않거나 데이터 분류 기준(UID)을 세부적으로 설정하고 싶으면 TypePolicy의 keyFields를 이용할 수 있다. keyFields는 기본적으로 ["id"] 또는 ["_id"]로 설정되어 있다고 생각하면 된다. 이를 다른 필드 이름으로 변경하면 __typename:해당필드값을 기준으로 캐시 데이터가 분류된다. 그리고 동일한 UID를 가지는 객체는 서로 병합된다.
keyFields는 문자열 배열, 문자열 배열을 반환하는 함수, false로 설정할 수 있다. 그리고 해당 필드가 분류 기준이라고 명시했기 때문에 당연하게도 쿼리 요청 시 쿼리문 안에 keyFields로 지정된 필드를 항상 포함해야 한다.
빈 배열
keyFields: []으로 설정하면 해당 자료형의 캐시 공간이 아래와 같이 1개만 생성된다. 어떤 자료형의 객체가 1개만 존재할 때 사용할 수 있다.
__typename:{}문자열 배열
keyFields: ["id", "name"]으로 설정하면 해당 자료형의 캐시 공간이 아래와 같이 구분된다.
__typename:{"id":...,"name":...}하위 문자열 배열
keyFields: ["id", "name", ["firstName"]]와 같이 keyFields 배열 안에 배열을 넣을 수도 있다. 이 규칙이 유효하기 위해선 name 필드가 firstName을 필드로 가지는 객체여야 한다. 캐시 공간은 아래와 같이 구분된다.
__typename:{"id":...,"name":{"firstName":...}}false
시간에 따라 변하는 일시적인 데이터나 재사용하지 않을 데이터는 캐시에 저장하지 않아도 된다. 이러한 자료형의 객체는 딱히 일정한 기준으로 구분해서 캐시에 저장하지 않아도 된다. 만약 어떤 자료형을 keyFields: false로 설정하면 해당 자료형은 캐시에 따로 저장되지 않고, 상위 객체가 있다면 상위 객체에 레퍼런스가 아닌 값으로 저장된다.
예시
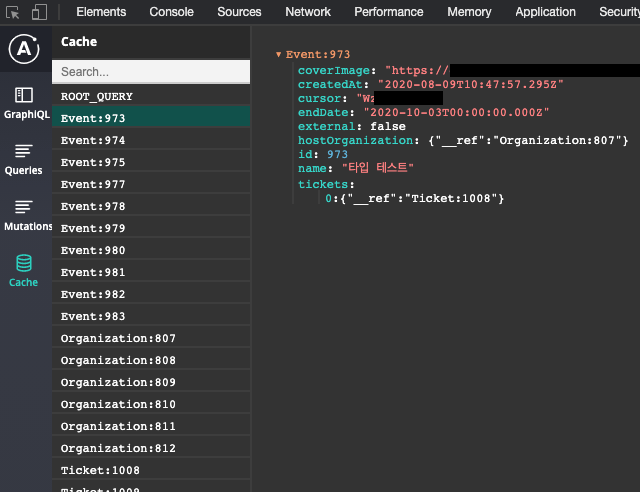
위 그림에서 보이듯이 Apollo 클라이언트는 GraphQL 응답 데이터로부터 UID를 생성한 후 이에 따라 데이터를 분류해서 캐싱한다. 위는 자료형이 Event이고 id가 973인 데이터가 Event:973 공간에 캐시된 그림이다.
그리고 위 그림처럼 Event 객체가 내부에 다른 객체(Organization, Ticket)를 가진다면, Apollo 클라이언트는 해당 객체 데이터를 Event 객체 안에 저장하지 않고 캐시 내부에 따로 저장한 후 그 데이터를 __ref를 통해 가리키는 방식으로 데이터를 관리한다. 만약 Organization 자료형이 keyFields: false이면 해당 데이터는Event:973의 hostOrganization 필드에 값으로 직접 저장된다. 그리고 캐시 내부에 Organization:807 등 그 자료형과 관련된 항목이 없을 것이다.
캐시 데이터 읽기
쿼리 요청 시 캐시에 저장된 특정 자료형의 필드값을 읽는 방식을 설정할 수 있다. 만약에 특정 자료형 필드의 read() 함수를 정의하면, Apollo 클라이언트가 쿼리를 요청할 때 쿼리에 해당 필드가 담겨 있으면 정의된 read() 함수가 실행된다. 그리고 응답 데이터에는 캐시에 저장된 기존 필드값 대신 read() 함수가 반환한 값이 담긴다.
TypePolicy 하위 항목인 FieldPolicy에서 read() 함수를 정의할 수 있다. 모든 필드에서 read() 함수를 정의할 수 있기 때문에 여러 필드값을 읽는 방식을 전부 다르게 설정할 수도 있다.
type FieldReadFunction<TExisting = any, TReadResult = TExisting> =
(existing: SafeReadonly<TExisting> | undefined, options: FieldFunctionOptions)
=> TReadResult | undefined;위는 read() 함수의 원형이다. read() 함수는 위와 같이 2개의 인수를 받아 값을 반환한다. 첫번째 인수엔 현재 캐시에 저장된 값이 읽기 전용으로 넘어오고, 두번째 인수엔 쿼리 인수나 여러 유용한 함수가 넘어온다. 그리고 제네릭을 통해 캐시에 저장된 값과 반환될 값의 자료형을 설정할 수 있다.
read(existing) {
return existing
}read() 함수의 기본 정의는 위와 같다. 현재 캐시에 저장된 값을 그대로 반환한다. 그리고 이 함수가 반환한 값이 해당 필드 값으로 설정된다.
const cache = new InMemoryCache({
typePolicies: {
Person: {
fields: {
name: {
read(name) {
// Return the cached `name`, transformed to upper case
return name.toUpperCase();
},
},
},
},
},
});위와 같이 요청 쿼리에 Person 자료형의 name 필드가 포함되어 있을 때, 캐시에 저장된 name 필드값이 항상 대문자로 읽히도록 설정할 수 있다. 그리고 FieldPolicy에 read 함수만 정의되어 있으면 아래와 같이 코드를 줄여 쓸 수도 있다.
const cache = new InMemoryCache({
typePolicies: {
Person: {
fields: {
name(name) {
// Return the cached `name`, transformed to upper case
return name.toUpperCase();
},
},
},
},
});예시
// Person:1
{
id: 1,
name: "asdf",
}예를 들어 캐시 내부 Person:1 공간에 위와 같은 데이터가 존재하고, getPerson 쿼리가 이 Person 객체를 반환한다고 가정하면
query {
getPerson {
name
}
}이렇게 요청했을 때
{
data: {
getPerson: {
__typename: "Person",
name: "ASDF",
}
}
}위와 같이 반환된다.
클라이언트 측 필드
클라이언트 측 상태 관리를 위해 캐시 FieldPolicy에 서버에 명시되지 않은 필드를 정의할 수도 있다. 그리고 클라이언트 측에서 쿼리를 요청할 때 서버에 정의되지 않은 필드 옆에 @client를 붙이면 해당 필드를 클라이언트에서 읽을 수 있다. 이는 클라이언트 측 전역 상태 관리에 활용할 수 있다.
캐시 데이터 쓰기
쿼리 응답을 받았을 때 특정 자료형의 필드값을 캐시에 쓰는 방식을 설정할 수 있다. 만약에 특정 TypePolicy 하위 FieldPolicy에 merge() 함수를 정의하면, Apollo 클라이언트가 서버로부터 받은 쿼리 응답에 해당 필드가 담겨 있을 때 사전에 정의된 merge() 함수가 실행된다. 그리고 캐시에는 merge() 함수가 반환한 값이 담긴다.
이 함수도 read() 함수와 마찬가지로 각 필드마다 정의할 수 있기 때문에 필드값을 저장하는 방식을 전부 다르게 설정할 수도 있다.
type FieldMergeFunction<TExisting = any, TIncoming = TExisting> =
(existing: SafeReadonly<TExisting> | undefined, incoming: SafeReadonly<TIncoming>, options: FieldFunctionOptions)
=> SafeReadonly<TExisting>;위는 merge() 함수의 원형이다. merge() 함수는 위와 같이 3개의 인수를 받아 값을 반환한다. 첫번째 인수엔 현재 캐시에 저장된 필드값이 읽기 전용으로 넘어오고, 두번째 인수엔 (서버로부터 받은) 새로운 필드값이 읽기 전용으로 넘어오고, 세번째 인수엔 쿼리 인수나 여러 유용한 함수가 넘어온다. 그리고 제네릭을 통해 캐시에 저장된 값과 반환될 값의 자료형을 설정할 수 있다.
merge(existing, incoming) {
return incoming
}merge() 함수의 기본 정의는 위와 같다. Apollo 캐시는 기본적으로 현재 캐시에 저장된 값을 항상 새로운 값으로 대체한다. 이는 아래와 같이 줄여 쓸 수 있다.
merge: false그리고 필드는 여러 가지 형태의 데이터를 가질 수 있다. 값이 기본 자료형(string, number, boolean 등)이면 그냥 다룰 수 있지만 배열이나 객체면 약간 더 고려할 점이 생긴다. 그리고 merge() 함수에서 레퍼런스로 관리되는 데이터(객체, 배열 등)를 다룰 땐 데이터 일관성을 위해 기존 데이터를 변경하기보다 새로운 객체(배열)를 생성해서 반환하는 것이 좋다.
배열
const cache = new InMemoryCache({
typePolicies: {
Person: {
fields: {
jobs: {
merge(existing, incoming) {
if (!existing) {
return incoming
} else {
return [...existing, ...incoming]
}
},
},
},
},
},
});필드값이 배열이라면, 캐시에 아무 값이 없는 초기엔 새로운 배열(incoming)을 반환하고 그 다음부턴 기존 배열(existing)과 새로운 배열을 합쳐서 반환한다. [...existing, ...incoming]만 쓰면 처음에 ...undefined를 할 수 없다고 오류가 발생하기 때문에 조건문을 넣었다. 또는 existing = []와 같이 초기값을 빈 배열로 설정할 수도 있다.
작성 중
객체
const cache = new InMemoryCache({
typePolicies: {
Person: {
fields: {
jobs: {
merge(existing, incoming) {
// 얕은 병합
return { ...existing, ...incoming }
},
},
},
},
},
});필드값이 객체라면 고려할 점이 생긴다. 얕은 복사, 깊은 복사 문제와 비슷하게 그 필드에 하위 자료형이 있고, 또 그 하위 자료형에 하위 자료형이 있을 수 있기 때문에 위와 같이 그냥 합칠 수는 없다.
{
__typename: 'Person',
id: 1,
name: 'Person name a',
jobs: [
{
__typename: 'Company',
id: 1,
name: 'Company name a',
},
{
__typename: 'Company',
id: 2,
name: 'Company name a2',
},
],
}{
__typename: 'Person',
id: 1,
name: 'Person name b',
jobs: [
{
__typename: 'Company',
id: 1,
location: 'Company location',
},
{
__typename: 'Company',
id: 2,
location: 'Company location',
},
],
}예를 들어 위의 personA와 personB 객체를 합치고 싶을 때 { ...personA, ...personB }와 같이 그냥 합치면 캐시에 저장된 Company:1과 Company:2의 name 필드값이 없어지고 location 필드값만 저장된다.
우리는 Company 자료형에 id 필드가 있기 때문에 이에 따라 UID를 생성할 수 있다.
UID가 부여되지 않은 객체, 즉 id 필드가 없거나 keyFields가 정의되지 않아 ROOT_QUERY에 값으로 저장된 객체가 삭제될 때 경고가 발생한다.
const cache = new InMemoryCache({
typePolicies: {
Person: {
fields: {
jobs: {
merge(existing, incoming) {
if (!existing) {
return incoming
} else {
return [...existing, ...incoming]
}
},
},
},
},
},
});객체와 배열
const cache = new InMemoryCache({
typePolicies: {
Person: {
fields: {
name: {
read(name) {
// Return the cached `name`, transformed to upper case
return name.toUpperCase();
}
}
},
},
},
});위와 같이 요청 쿼리에 Person 자료형의 name 필드가 포함되어 있을 때, 캐시에 저장된 name 필드값이 항상 대문자로 읽히도록 설정할 수 있다.
예시
// Person:1
{
id: 1,
name: "asdf",
}예를 들어 캐시 내부 Person:1 공간에 위와 같은 데이터가 존재하고, getPerson 쿼리가 이 Person 객체를 반환한다고 가정하면
query {
getPerson {
name
}
}이렇게 요청했을 때
{
data: {
getPerson: {
__typename: "Person",
name: "ASDF",
}
}
}위와 같이 반환된다.

잘 읽었습니다. 마지막에 '객체와 배열' 문단은 잘못 들어간것같아요