데이터 동기화
동기화(synchronization)는 동시에 일어나는 사건(프로세스, 스레드)을 조정하는 일이다. 그래서 프로그램이 시작된 후 프로세스가 올바른 순서로 실행되는 것을 목표로 하고, race condition이 일어나지 않도록 한다. 실행 결과는 항상 정확하고 일정해야 하는데 공유 자원 접근 제어가 잘 이뤄지지 못해 race condition이 발생하면 프로그램 실행 결과가 상황에 따라 달라질 수 있다.
Barrier
코드 상에 존재하는 배리어에 도착한 스레드는 다른 모든 스레드가 도착할 때까지 기다려야 한다. 그리고 모든 스레드가 배리어에 도달하면 실행을 재개한다.
Lock
공유 자원을 동시에 사용할 때 발생하는 문제를 줄이기 위해 lock의 개념이 등장했다.
Lock은 특정 스레드가 공유 자원을 사용하고 있을 때 다른 스레드가 공유 자원을 사용하지 못하게 제한하는 역할을 한다. 또는 특정 스레드가 코드의 특정 부분을 처리하고 있을 때 다른 스레드가 그 코드에 접근하지 못하도록 제한하기도 한다. 이때 그 코드 부분을 critical section이라고 한다. 과정은 아래와 같다.
- 한 스레드가 공유 자원의 사용을 요청하면 공유 자원의 lock이 설정된다.
- Lock이 설정되면 이어서 온 스레드는 처음 온 스레드가 공유 자원을 다 사용할 때까지 기다려야 한다.
- 처음 온 스레드의 공유 자원 사용이 끝나면 공유 자원의 lock이 풀린다.
- 그럼 지금까지 기다린 스레드에게 공유 자원 사용 권한이 넘어가고, 마찬가지로 공유 자원의 lock이 설정된다.
Semaphore
Lock은 0 또는 1 밖에 못 가지지만, semaphore는 여러 값을 가질 수 있다. Semaphore의 숫자는 현재 공유 자원에 접근할 수 있는 스레드 개수를 의미한다. 공유 자원에 스레드가 접근할 때마다 semaphore의 값이 1씩 감소하고, 0이 되면 그때부터 다른 스레드의 공유 자원 접근이 제한된다. 그리고 스레드가 공유 자원을 다 사용할 때마다 semaphore의 값이 1씩 증가한다.
공유 메모리 시스템
모든 공유 메모리 시스템은 메모리를 1개로 취급한다. 따라서 데이터 교환 시 네트워크 통신이 들어가야 하는 분산 메모리 시스템에 비해, 공유 메모리 시스템은 프로그래밍이 쉽고 프로세서 간 데이터 교환이 빠르다. 하지만 분산 메모리 시스템에 비해 설계 비용이 많이 들어가고, 새로운 프로세서를 추가하는 등 확장하기가 어렵다.
공유 메모리 시스템의 형태는 아래와 같다.
UMA
Uniform Memory Access. 하나의 큰 메모리에 여러 프로세서가 접근하는 형태의 CPU-메모리 구조다. 각 프로세서와 메모리 사이의 물리적 거리가 동일해 각 프로세서가 메모리에 접근하는 시간이 모두 동일하다.
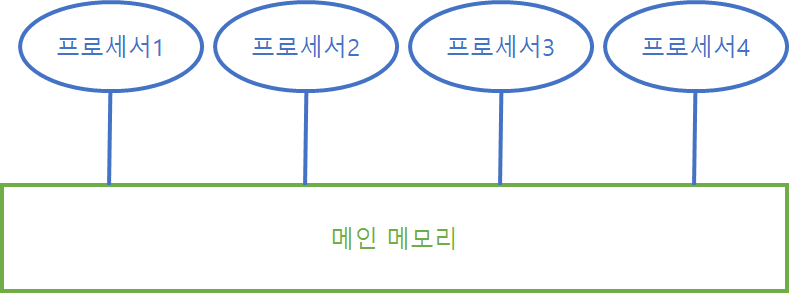
하지만 한 프로세서가 메모리에 접근 중일 때 다른 프로세서는 메모리에 접근할 수 없다는 단점이 있다. 즉, 한 번에 하나의 프로세서만 메모리에 접근할 수 있다.
NUMA
Non Uniform Memory Access. 메모리가 물리적으로 여러 개로 나뉘었지만, 메모리끼리 서로 연결되어 있어 논리적으로 1개로 생각할 수 있는 형태의 CPU-메모리 구조다. 자기 프로세서에게 할당된 메모리(local memory)에 접근하는 속도가 다른 프로세서의 메모리(remote memory)에 접근하는 속도보다 빠르다. 따라서 메모리 상 데이터의 위치에 따라 프로그램 성능이 달라질 수 있다. 자기 메모리 상에 존재하는 데이터를 처리할 때가 가장 빠를 것이다.
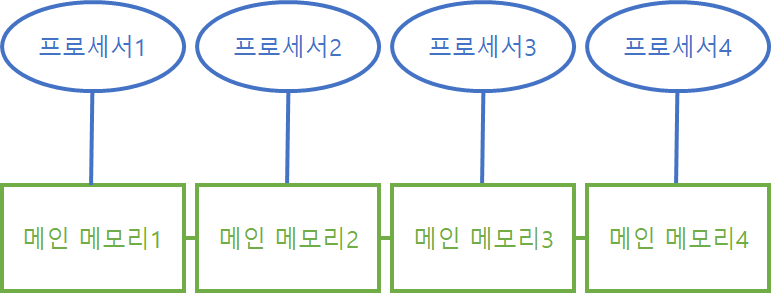
위와 같이 메인 메모리가 물리적으로 분리되어 있기 때문에 모든 프로세서가 동시에 자기 메모리에 접근할 수 있어 효율적인 병렬처리가 가능하다. 하지만 다른 프로세서 메모리에 접근하는 속도는 느리다는 것과, 자기 메모리가 꽉 차면 다른 프로세서 메모리에 데이터를 저장해야 한다는 단점이 있다.
CC-NUMA
Cache Coherence NUMA. NUMA 형태에 캐시 변경 사항이 다른 프로세서 캐시에 자동으로 반영되는 구조다.
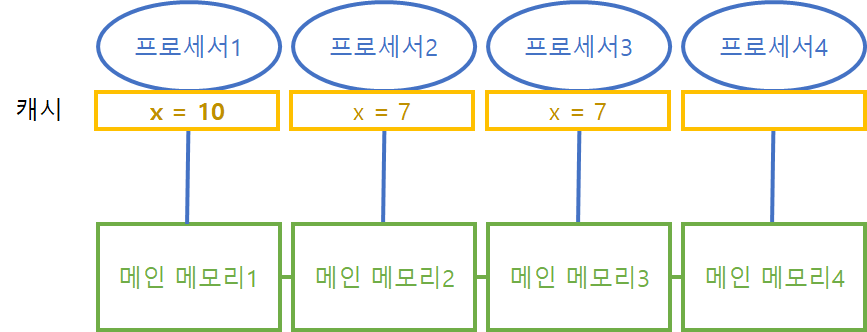
위와 같이 프로세서 1의 캐시에서 x의 값이 7에서 10으로 변경되면
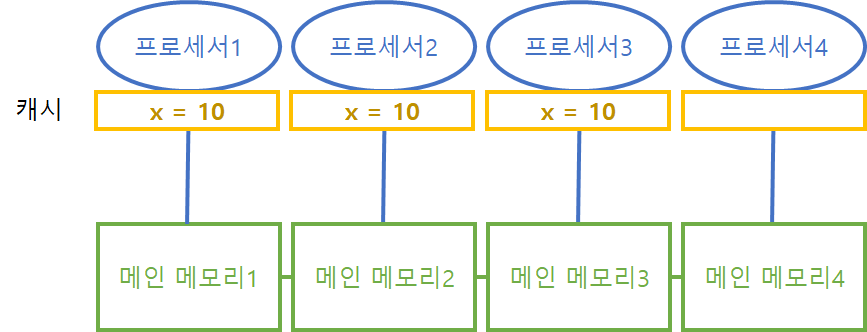
자동으로 x를 사용하고 있는 다른 프로세서의 캐시값도 10으로 변경된다. 하지만 이렇게 프로세서의 모든 캐시 데이터를 동기화하는 과정에서 약간의 오버헤드가 발생한다. 그래도 데이터 일관성 유지는 필수인 만큼 오버헤드는 감수해야 한다.
분산 메모리 시스템
여러 컴퓨터가 네트워크를 통해 연결된 형태다. 메모리를 공유하지 않아 네트워크를 통해 데이터를 교환해야 한다.
장점
- 시스템 구축 비용이 낮다. 여러 컴퓨터를 네트워크를 통해 연결하면 되기 때문에 간단하게 설계할 수 있다.
- 확장이 용이하다. 새로운 프로세서를 기존 시스템에 추가하기가 쉽다.
단점
- 데이터 교환 시 네트워크가 필요하기 때문에 이에 대한 네트워크 프로그래밍이 필요하고, 공유 메모리 시스템에 비해 데이터 교환이 느리다.
그래서 공유 메모리 시스템과 분산 메모리 시스템을 적절히 섞은 형태가 사용되기도 한다.
프로세스와 스레드
프로세스
프로그램을 실행하면 1개의 프로세스가 생성된다. 프로세스는 기본적으로 1개의 스레드를 포함하고 있고, CPU 스케줄링 단위가 스레드이기 때문에 실제론 CPU에서 스레드가 실행된다. 프로세스는 프로세스 제어 블록(PCB, Process Control Block)을 가지고 있고, 거기엔 아래와 같은 정보가 저장된다.
-
프로세스 상태
실행/대기 등 프로세스의 현재 상태 -
프로세스 식별 번호 (PID)
개별 프로세스마다 고유한 번호가 부여된다. -
프로그램 카운터(PC, Program Counter)
해당 프로세스가 실행할 다음 명령어의 메모리 상 위치 -
레지스터 값
-
프로세스에 할당된 메모리 공간 및 범위
-
열려 있는 파일 스트림 목록
-
부모/자식 프로세스 목록
유닉스 계열 운영체제는 부팅 시 최초로 실행되는 프로세스(0번 프로세스)를 제외한 모든 프로세스는 fork()라는 시스템 호출로 생성된다.
- 기타 등
fork()
일반적으로 fork() 시스템 호출을 사용할 땐 아래와 같은 코드 패턴을 활용한다.
int main()
{
printf("Fork Start");
int process_id = fork();
if (process_id == 0)
{
// 자식 프로세스 실행 부분
{
else if (process_id > 0)
{
// 부모 프로세스 실행 부분
}
else
{
// fork 오류 발생 처리 부분
}
return 0;
}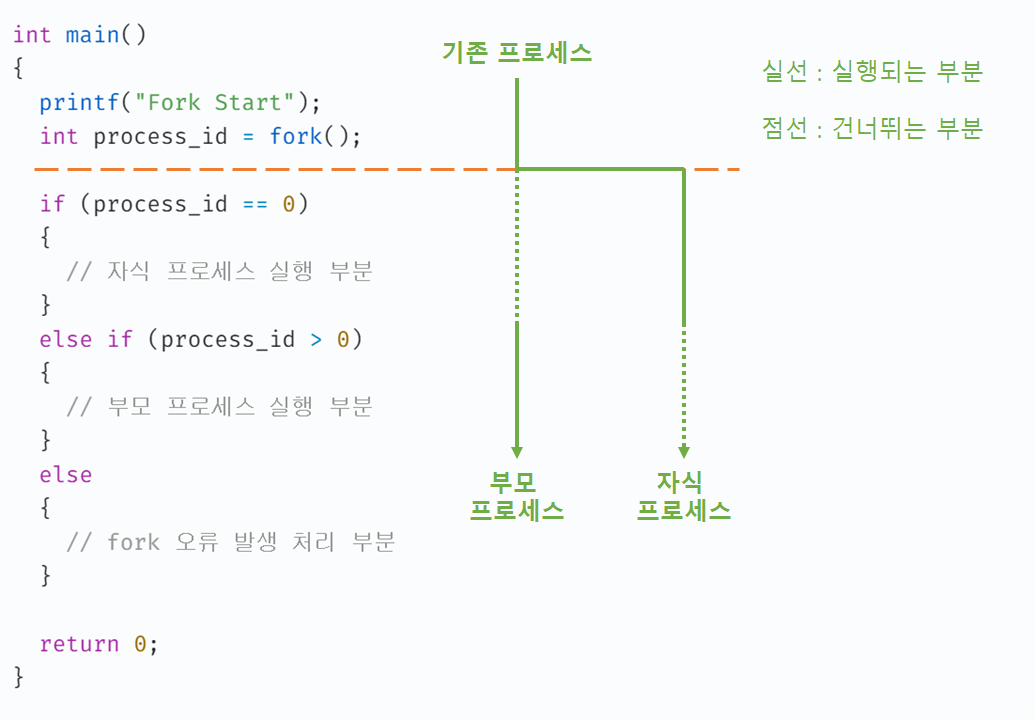
fork()가 실행되면 기존 프로세스는 fork() 바로 아래 주황색 점선을 기준으로 부모 프로세스와 자식 프로세스로 나뉜다. 그리고 fork()로부터 정수 값이 반환되는데 자식 프로세스에선 0이 반환되고 부모 프로세스에선 자식 프로세스의 ID(프로세스 번호)가 반환된다. 또는 포크 도중 오류가 발생하면 부모/자식 프로세스 모두 음수가 반환된다. 따라서 위와 같은 코드 패턴으로 부모 프로세스와 자식 프로세스를 구분하고 포크 오류를 처리할 수 있다.
스레드
프로세스보다 작은 실행 단위로서 프로세스에 속한다. 한 프로세스에는 여러 스레드가 속할 수 있다. 스레드의 구성 요소는 아래와 같다.
-
프로그램 카운터(PC)
해당 스레드가 실행할 다음 명령어의 메모리 상 위치 -
레지스터 값
-
스택
지역변수 등
프로그램 코드와 데이터(i.e. 동적 할당 데이터), 파일 스트림은 같은 프로세스 내 스레드끼리 공유한다.
