회사에서 새로운 기능 개발 단계에서 도입할 DB를 고려하던 도중 Milvus라는 벡터 DB에 대해 정리하게되었다.
7월중에 정리한 내용이지만 생각난김에 지금(2024/08/17)이라도 기록으로 남겨둔다.
벡터 DB종류 비교
https://discuss.pytorch.kr/t/2023-picking-a-vector-database-a-comparison-and-guide-for-2023/2625
해당 주소에서 벡터DB를 비교한 자료를 근거로 Milvus을 선택하여 정리해보았다.
Milvus Docker 설치 방법
- 대부분의 사용자들이 milvus를 사용할때 주로 이용하는 설치 방법으로 알려져있다.
-
Milvus 도커 컴포즈 파일을 아래의 경로에서 설치해준다
https://github.com/milvus-io/milvus/releases -
다운받은 컴포즈 파일을 이용하여 컨테이너를 올려준다.
docker compose up -d -
도커 컴포즈 실행여부를 확인한다
docker compose ps
Python milvus SDK 설치
- 의존성 설치
Python version≥3.7
pip3 install protobuf==3.20.0
pip3 install grpcio-tools
python3 -m pip install pymilvus==2.4.4Milvus 샘플코드 설치
wget https://raw.githubusercontent.com/milvus-io/pymilvus/master/examples/hello_milvus.py샘플 코드로 설치된 예제를 보며 코드를 설명하겠다.
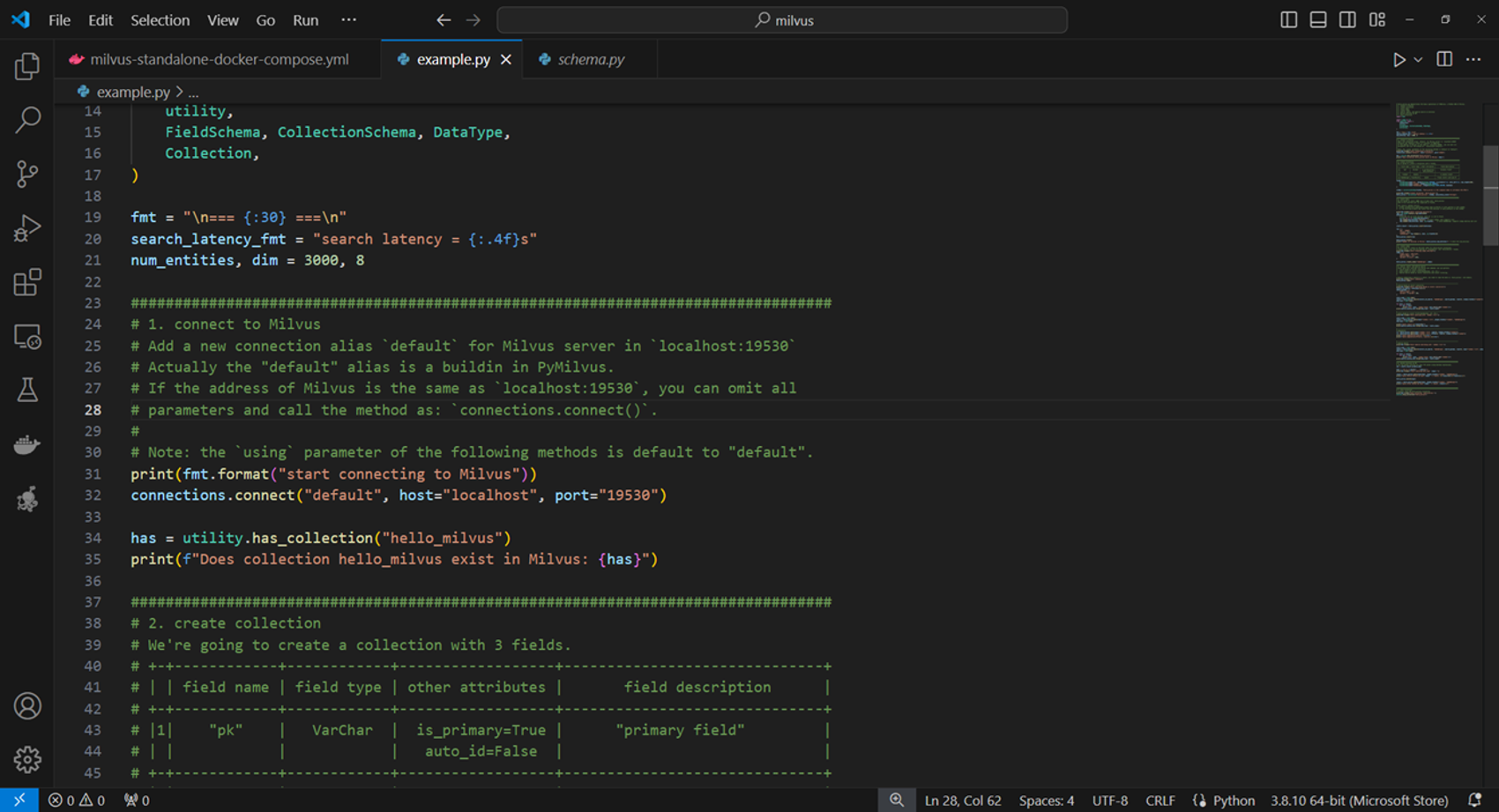
Milvus 연결
먼저 Milvus와 연결을 해준다. pymilvus의 connection 메서드를 사용하여 연결을 설정한다.


hello_milvus라는 컬렉션의 존재여부를 확인한다.
Collection 생성
Milvus에서의Collection은RDBMS의Table과 유사한 개념이다.Collection또한 스키마의 설계가 필요하다- 스키마를 생성할때 각 필드는
FieldSchema라는 메서드를 이용한다.FieldSchema에 필요한 매개변수는 다음과 같다.name: 필드명dtype: 필드 변수 타입is_primary: PK 여부auto_id: 자동 생성 여부max_length: 길이 제한 설정dim: 벡터 필드의 차원 설정
- 이렇게 만들어진
FieldSchema배열을 사용하여 스키마를 만들어주고, 만들어진 스키마를 사용하여Collection을 생성한다.
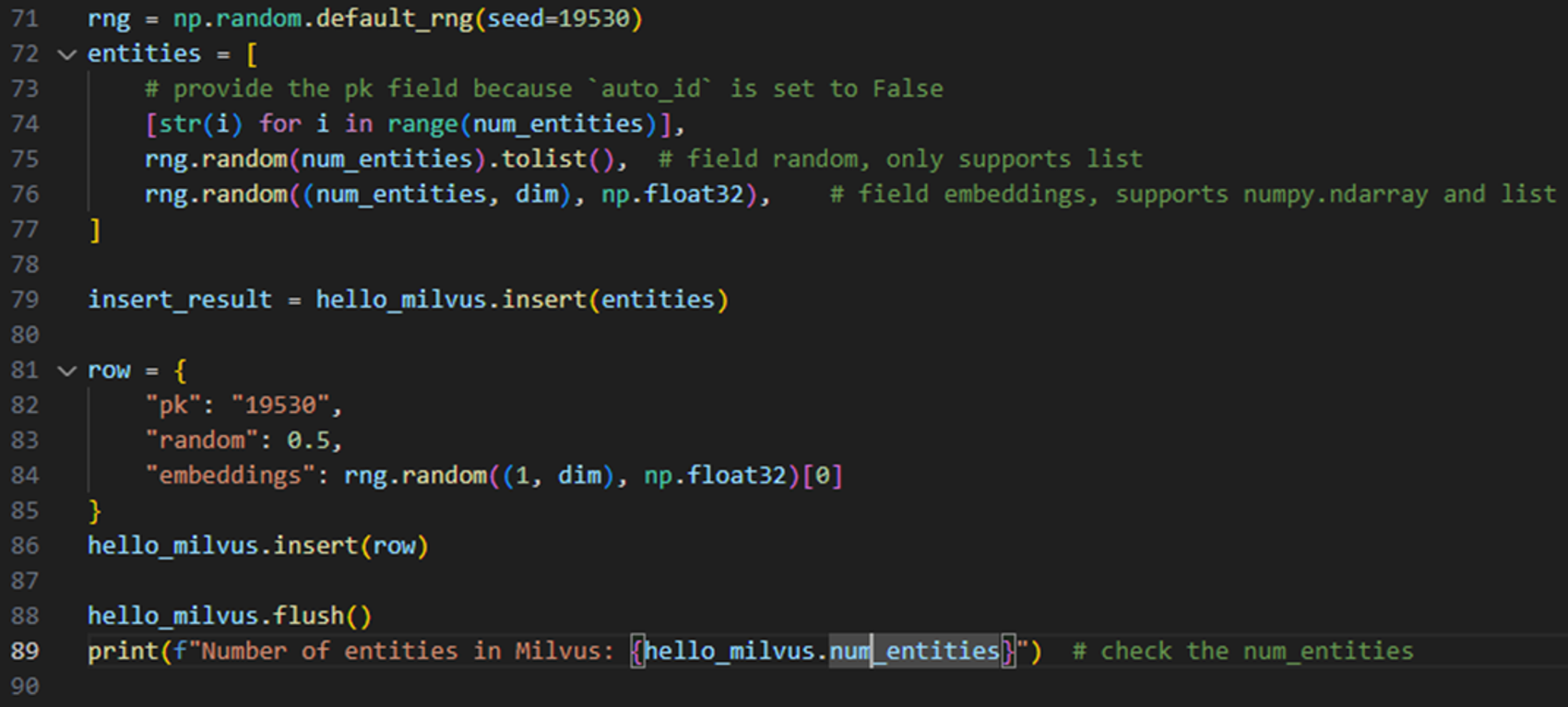
데이터 삽입
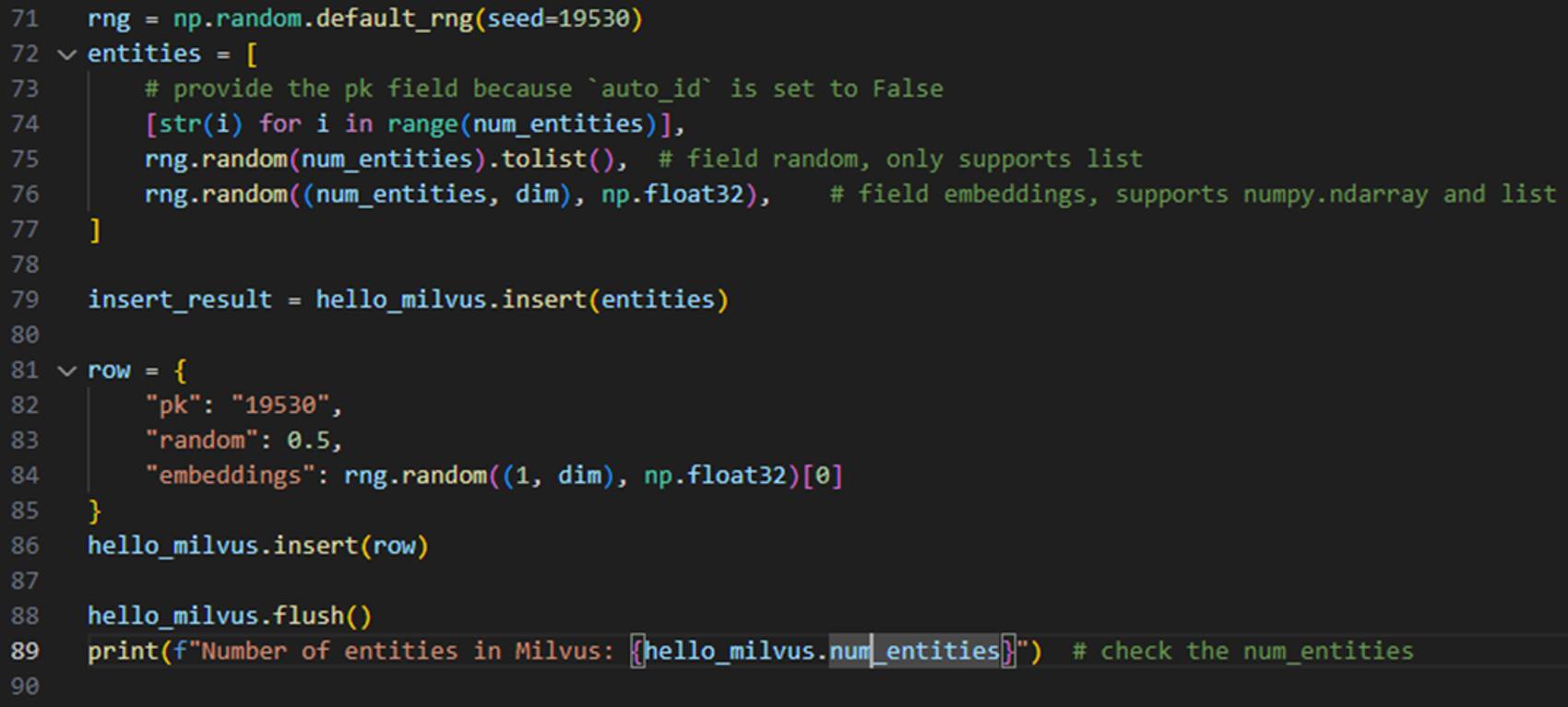
- 만들어진
Collection에 삽입할 데이터를 만들 수 있다. - 전통적인 RDBMS의 행 단위 데이터의 각각을 순차 삽입하는 방식과 달리 vector DB에서는 삽입할 데이터를 column단위로 만들어 놓고 삽입하는 것을 확인할 수 있었다.
Indexing
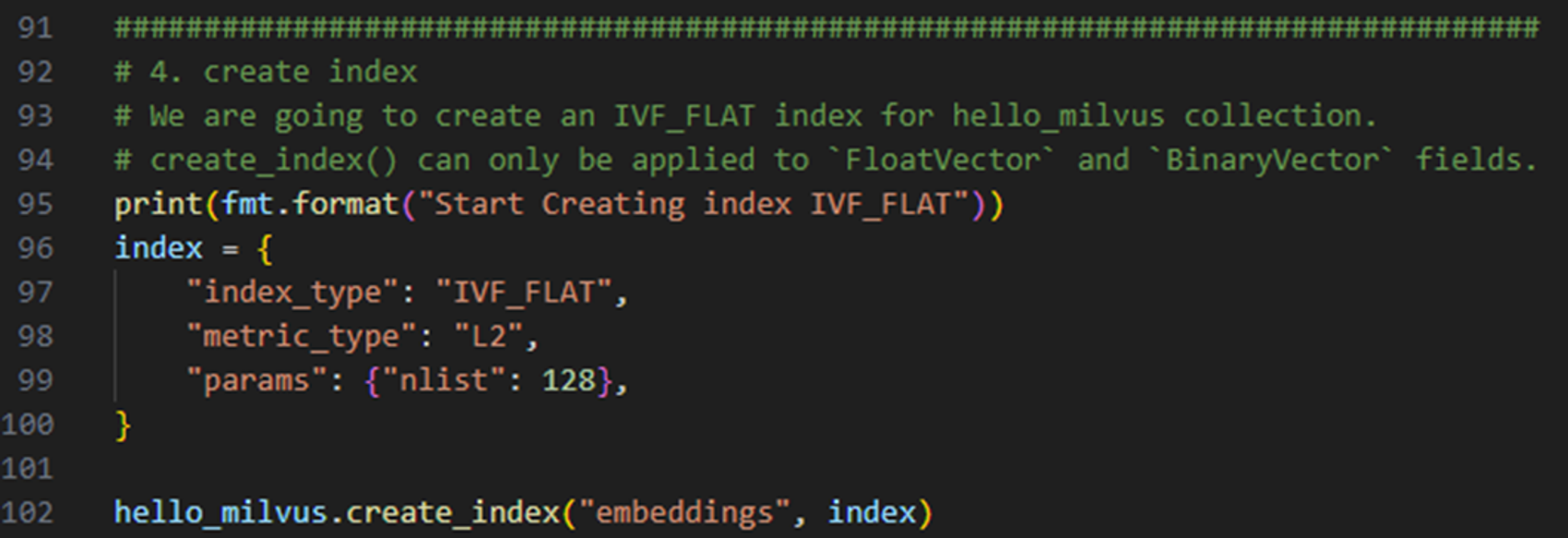
- 벡터 DB에서는 쿼리 성능을 향상 시키기 위해 필드마다 인덱싱 기준을 할당하고 인덱스를 설정할 수 있었다.
- 그리고 인덱스 설정을 할당/해제해보며 알게된것은 milvus에서는 사용자가 메모리에 적제된 컬렉션을 할당 해제 해야한다는 것이었다.
- RDBMS의 대표적인 mysql의 경우, DBMS에서 알아서 메모리를 관리해주지만,
- Milvus에서 쿼리를 수행하기 위해서는 load()를 통해 메모리에 쿼리를 위한 정보를 할당하고, release()를 통해 해제해주어야한다.
- 인덱스를 해제하기 위해서는 메모리에서 컬렉션이 해제된 상태여야된다.
Query
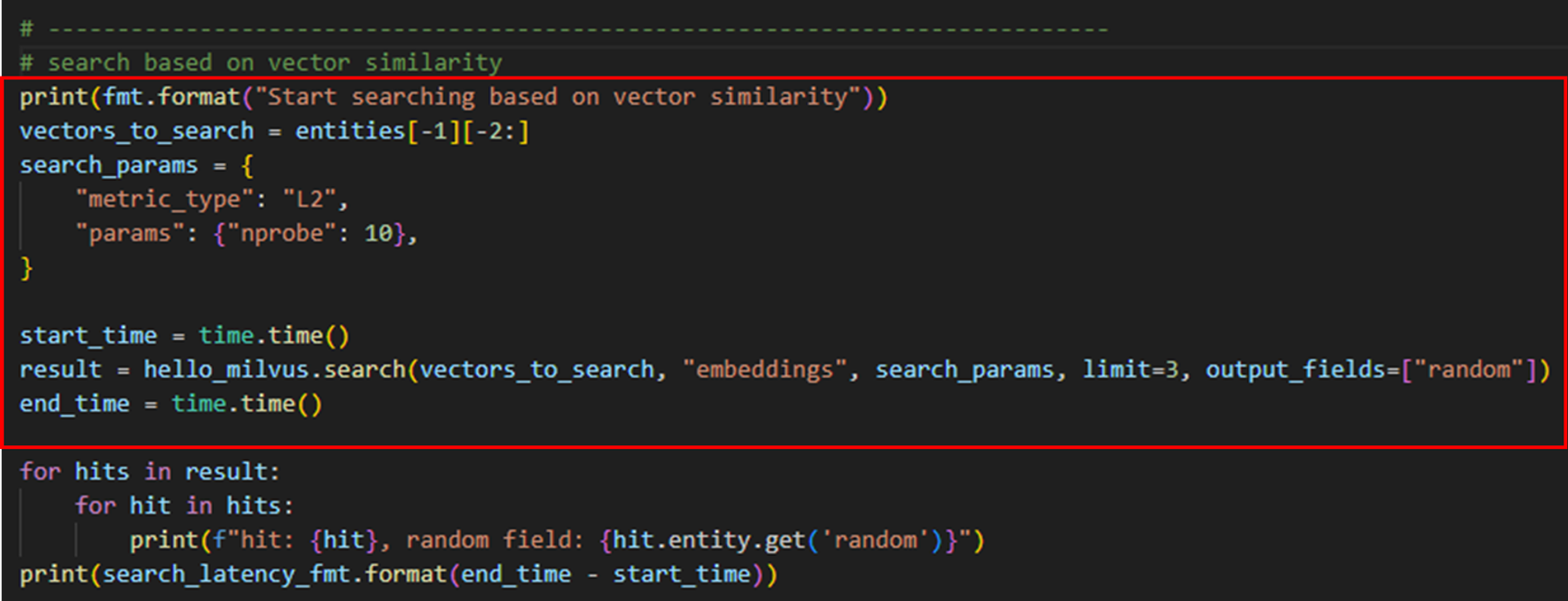
- 정의한 엔티티에서 벡터의 마지막 2개의 요소와 근접한 요소를 검색하는예제이다
search_paramsmetric_type:L2norm을 기준으로 검색params: {nprobe: 10} : 10개의 클러스터를 탐색하겠다는 의미
search- 첫번째 인자: 검색을 수행할 기준(검색 타겟)
- 두번째 인자: 검색의 대상이 되는 필드명
- 세번째 인자: 검색 옵션
- 네번째 인자: 몇 개의 결과를 반환할지
- 다섯번째 인자: 반환 데이터의 필드 이름 지정
RDBMS의 쿼리 기능도 지원
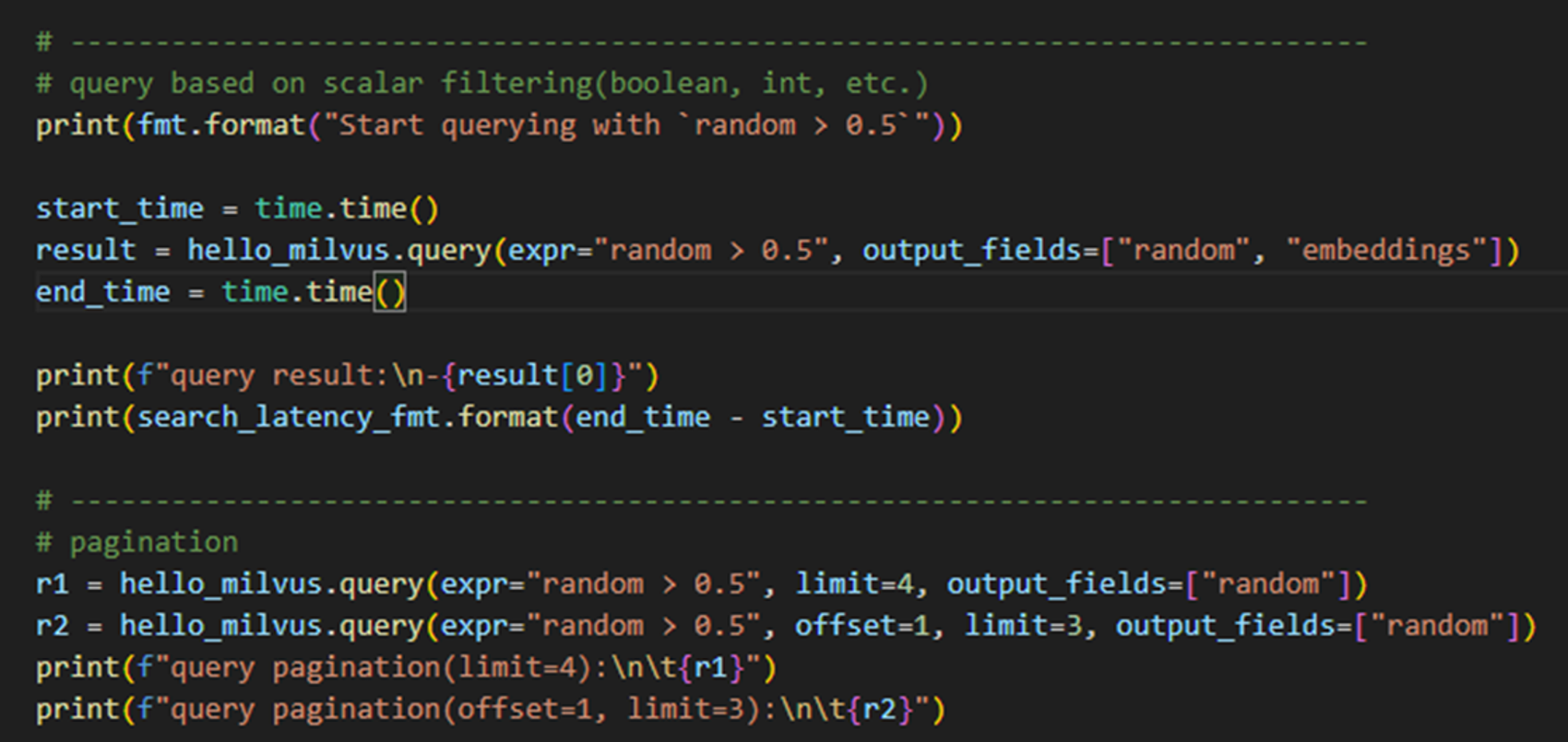
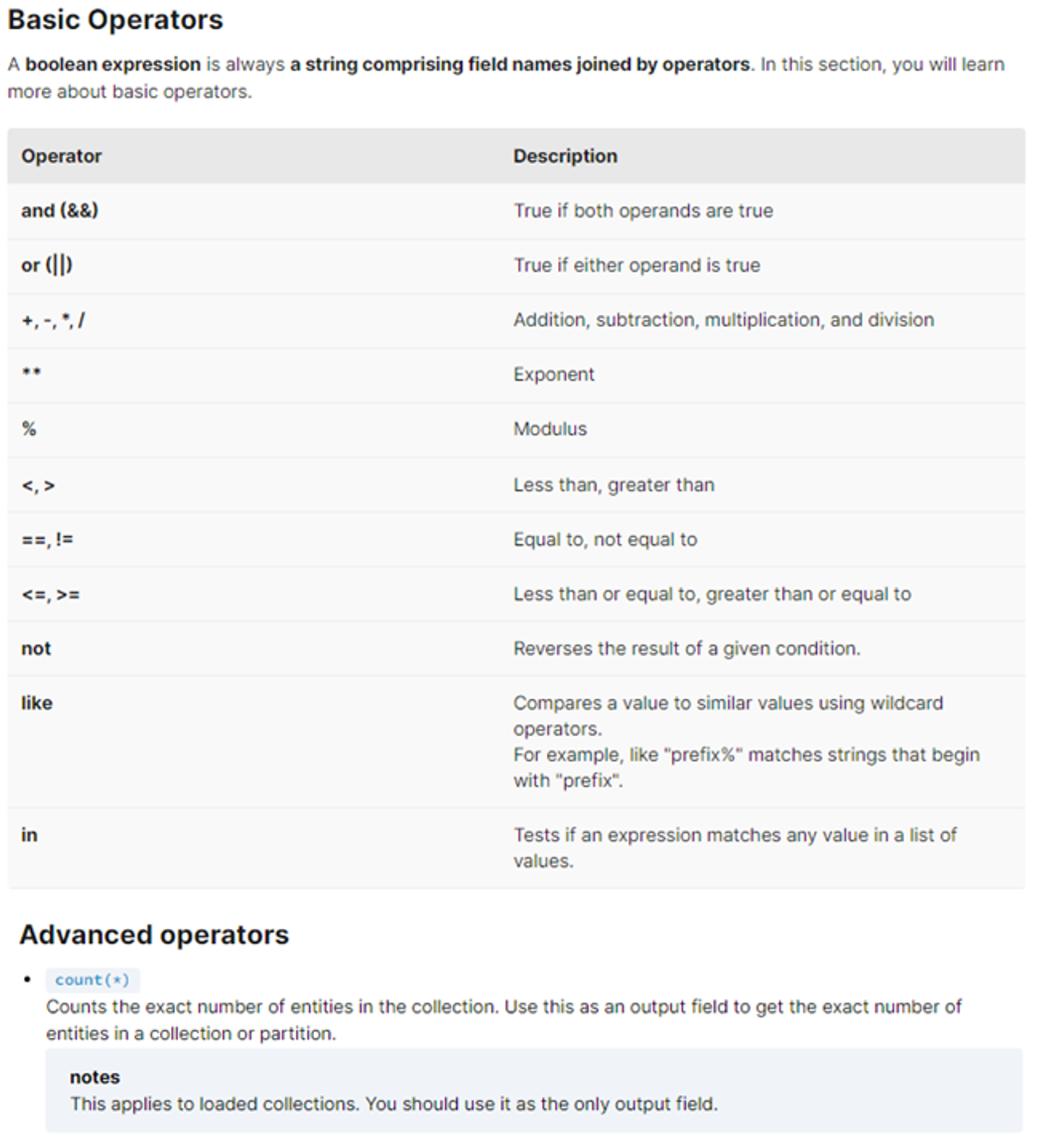
- Milvus에서는 RDBMS와 같은 스칼라값이 저장되어있는 필드들에 한해서 쿼리기능을 지원한다.
- 벡터 정보의 경우 RDBMS처럼 기존 쿼리 방식을 사용할 수 없지만, SCALAR 형식의 데이터의 경우에는 기존 쿼리와 비슷한 방법을 지원한다.
- 하지만, Milvus는 효율적인 검색과 데이터 저장을 목적으로 하기에 JOIN과 같은 복잡한 데이터 조작은 지원하지 않는다.
- 따라서 검색은 VectorDB로 수행하고, JOIN 과 같은 복잡한 데이터 조작은 어플리케이션 레벨에서 처리하거나 RDBMS와의 통합을 수행하여 처리해야 된다.
다음 블로그를 참고하였다

백엔드 주니어 개발자