
*해당 내용은 edX 및 Linux Foundation에서 제공하는 강의 LinuxFoundationX LFS158x - Introduction to Kubernetes의 내용을 해석 및 요약한 것입니다.
** 본문 내 모든 이미지의 출처는 해당 강의 내 자료 입니다.
이전글 : https://velog.io/@gwangjogong/Kubernetes-Architecture-1
TL;DR
- Control plane components들 중 Controller Managers 와 Key-value Data Store(etcd)를 다룬다.
- Controller Managers는 현재 state와 desired state를 지속적으로 비교하며, 두 state가 다를 경우, desired state와 동일해지도록 controller/operator 작업을 실행한다.
- Key-value data storage (etcd)는 Raft Consensus Algorithm 기반의 분산된 data store로, 클러스터내 state 및 config data를 일관적으로 유지하는데 활용된다.
Controller Managers
controller managers는 k8s 클러스터의 state를 조정하기 위해, controllers 또는 operator process를 실행한다.
Operator?
Operator는 사용자가 직접 정의하고 구현하는 controller
controllers는 watch-loop process로, 클러스터의 현재 state와 desired state를 비교한다. 두 state가 다를 경우, desired state와 동일해 질때까지 수정작업을 진행한다.
kube-controller-manager
kube-controller-manager는 노드가 unavailable해질 때 대응하는 controller 또는 operator를 실행하며, 컨테이너 pod 개수가 예상대로(as expected) 유지되도록 하고, 엔드포인트, 서비스 계정 및 API 액세스 토큰을 생성하는 역할을 담당한다.
cloud-controller-manager
cloud-controller-manager는 kube-controller-manager와 마찬가지로, 노드가 unavailable해질 때 대응하는 controller 또는 operator를 실행한다. 다만, cloud 라는 단어가 다르듯, AWS 등 cloud provider를 통해 storage volumne을 관리하거나 로드밸런싱, 라우팅등을 관리한다.
Key-Value Data Store (etcd)
etcd는 CNCF에서 운영되는 오픈 소스 프로젝트며, 굉장히 일관적(consistent)이고 분산된 key-value data store다. K8s 클러스터의 state를 지속하는데 사용된다.
etcd는 Go로 작성되었으며, 클러스터 state 뿐만 아니라 subnets, ConfigMaps, Secret 등 configuration detail 등을 저장하는 데에도 사용된다.
etcd에서 새로운 데이터는 오로지 추가(append)되는 방식으로만 저장된다. 저장된 데이터는 절대로 교체되지 않는다. 다만, 오래된 데이터(obsolete data)는 주기적으로 압축되어, data store의 용량을 최소화한다.
이전 API Server 섹션에서도 말했다싶이, etcd data store과 통신(communicate) 할 수 있는 component는 오직 API Server 뿐이다.
etcdctl & etcd topology
ectd의 CLI형 관리도구 etcdctl은 snapshot 저장 및 복원 등 single etcd 클러스터에 유용한 기능을 제공한다. (보통 개발 또는 학습 환경이 이런 구조를 가진다)
하지만 배포 환경(staging/production)에서는 data store를 HA mode 내에 복사해두는 것이 매우 중요하다. (클러스터 구성 데이터 복원력 - cluster configuration data resiliency)
kubeadm 등 일부 k8s 클러스터 부트스트래핑 도구는 기본적으로 stacked etcd control plane nodes(하단 이미지 참고)를 제공한다. 이 경우 data store가 control plane node 상의 다른 component 들과 자원을 공유하며 작동한다.
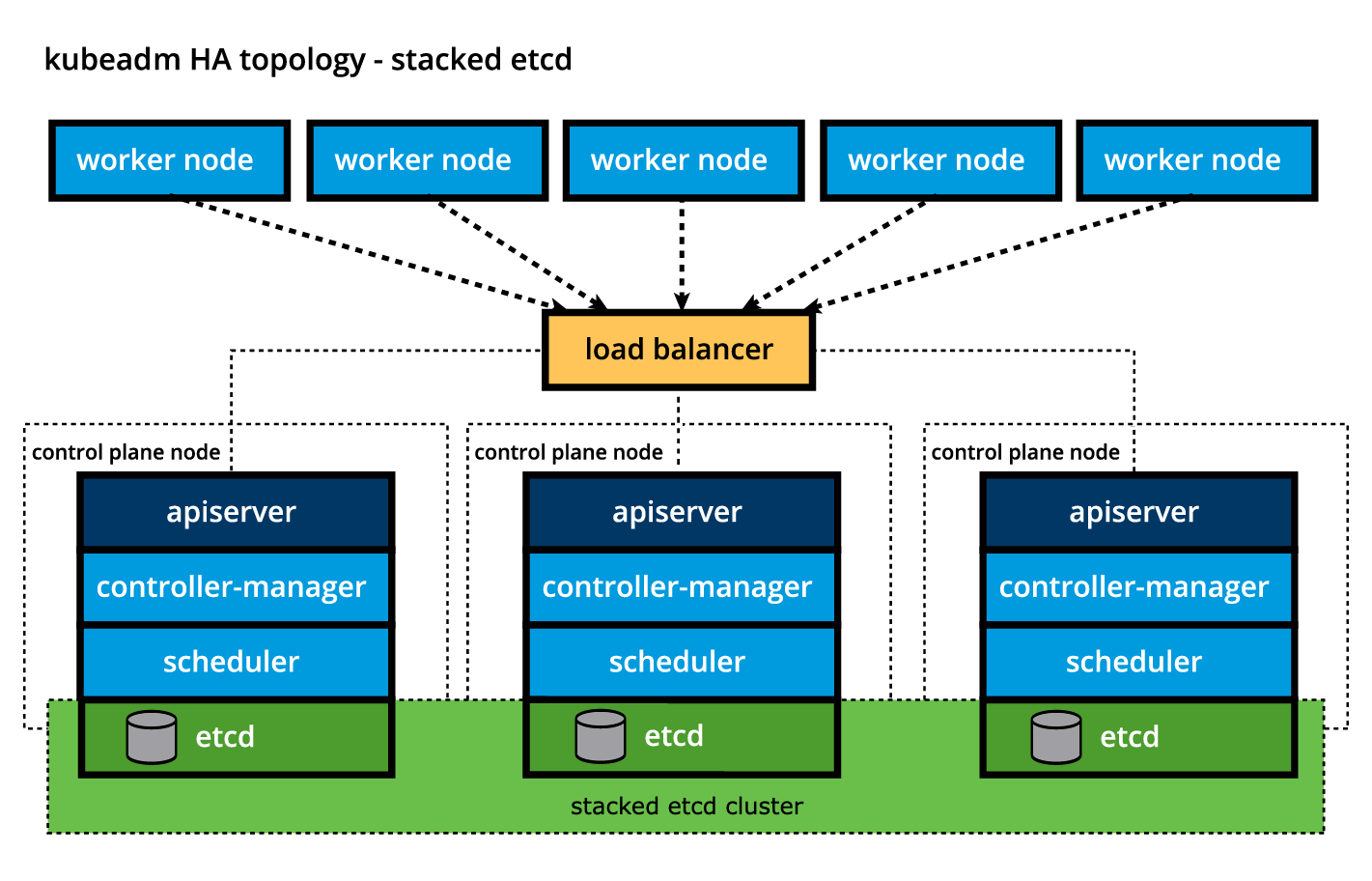
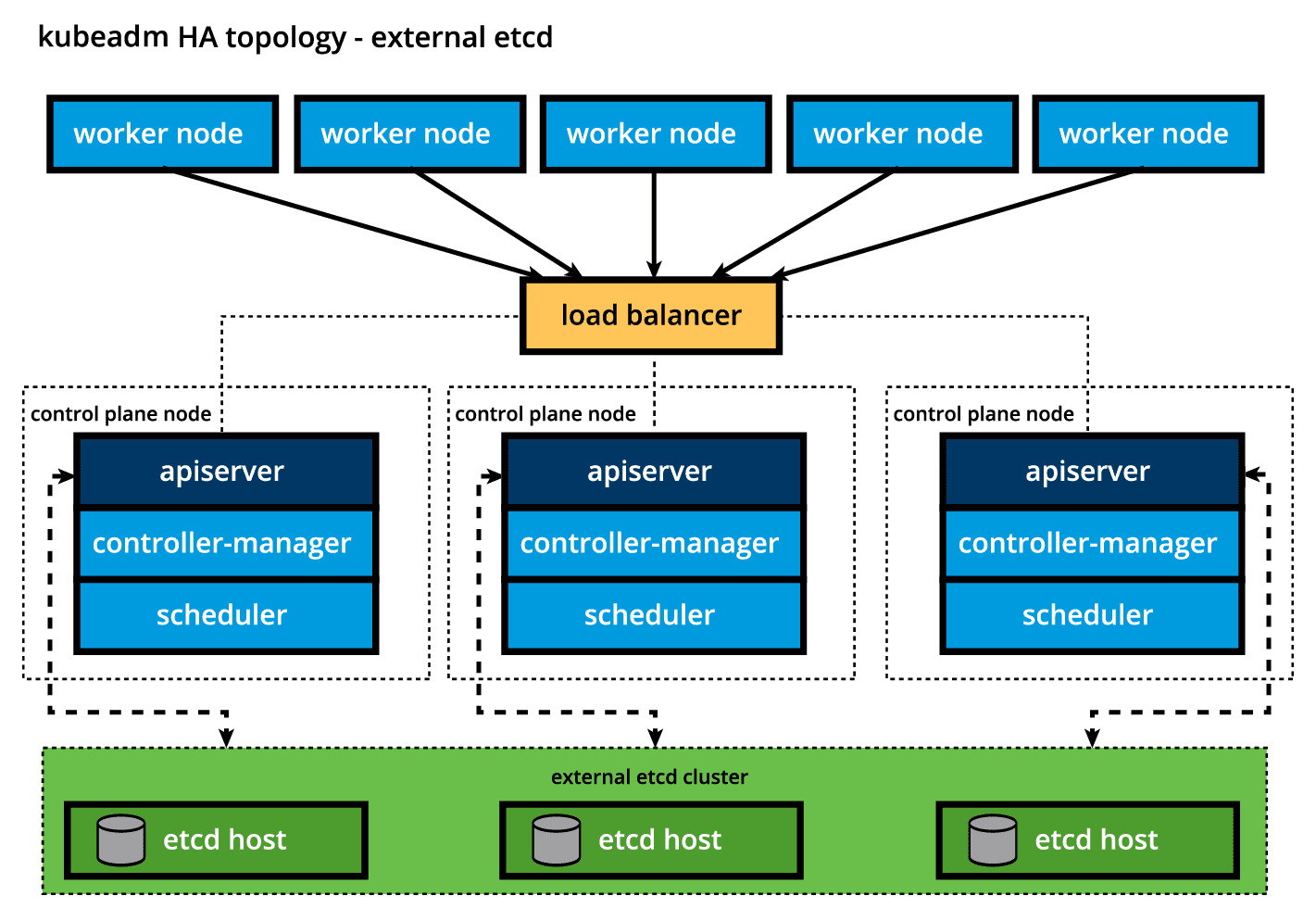
만일 data store의 격리가 필요하다면, 부트스트랩 과정을 external etcd topology(하단 사진 참고)에 맞게 구성할수 있다. 말그대로, data store를 다른 호스트에서 제공하여, etcd failure가 발생할 확률을 줄일 수 있다.
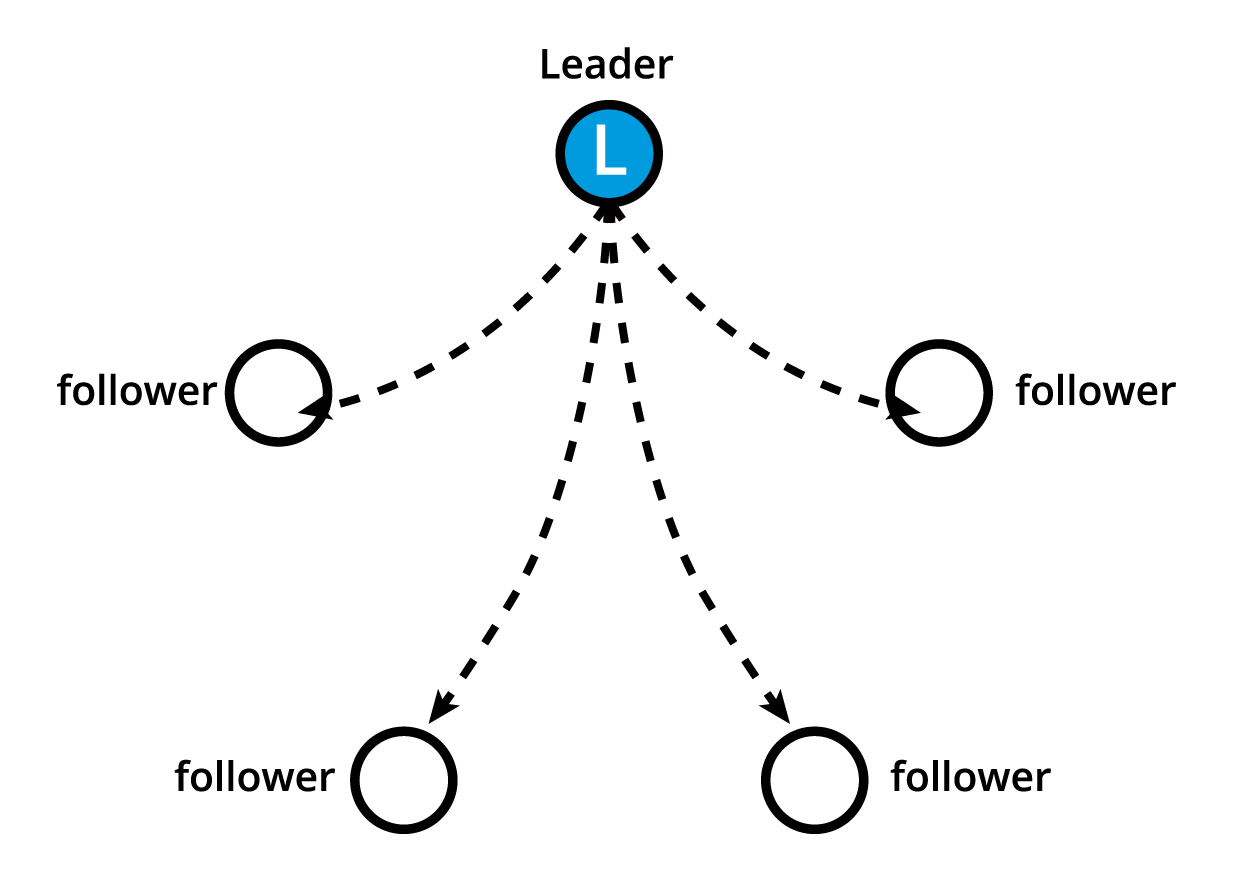
Raft Consensus Algorithm
etcd는 Raft Consensus Algorithm에 기반한다. 이 알고리즘은 여러대의 machine이 하나의 그룹과 같이 작동하도록 한다.(그룹 내 일부가 실패해도 작동이 가능하다)
강의 내 부가 설명
어느 시점에라도, 그룹 내 한개의 node가 leader 역할이며 나머지 node들은 follower 역할이다.(하단 사진 참고) etcd는 leader 선출을 원활하게(gracefully) 처리하며 leader node 포함한 node failure를 버틸 수 있다. 어떤 노드라도 leader로 선출 될 수 있다.
해당 강의에서 설명해주는 내용은 굉장히 abstract해서, Raft Consensus Algorithm이 어떻게 etcd의 강한 일관성이나 분산성을 유지시킬 수 있는지 이해하기는 어렵다. 구글에 검색하면 자세한 내용을 쉽게 찾아볼 수 있으니 궁금하다면 찾아보도록 하자.
다음글 : https://velog.io/@gwangjogong/Kubernetes-Architecture-3
