
안녕하세요, 이번 포스팅은 Spring Batch가 무엇인지 알아보고 기본 구조인 Job, Step, Spring Batch에 필요한 스키마와 그 구조에 대해 공부한 내용을 공유하겠습니다😆.
아래 순서로 포스팅됩니다. 참고해주세요!
- Spring Batch 아키텍처
- Job
- Step
- Spring Batch 스키마
Spring Batch 아키텍처
아래는 Spring Batch의 전반적인 구성입니다.
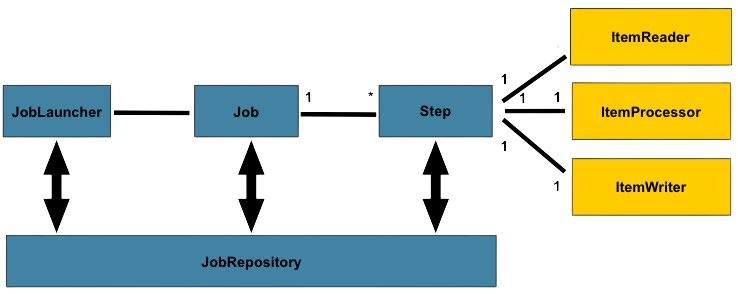
JobLauncher : Job을 실행시키는 컴포넌트.
Job : 배치 작업의 단위(Step과 1대다 관계).
JobRepository : Job 실행과 Job,Step을 저장.
Step : 배치 작업의 단계.
ItemReader, ItemProccessor, ItemWriter : 데이터를 읽고 처리하고 쓰는 구성.
Spring Batch의 세부 구조입니다.
아래 내용을 알고있어야하기 보다는 Application Layer에서 Core와 Infrastructure를 활용해 Application을 구현한다는 점만 인지하고 있으면 됩니다.
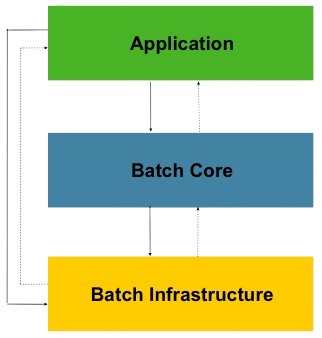
Application Layer
- 사용자 코드와 구성(작업을 작성)
- 비즈니스, 서비스 로직
- Core, Infrastructure를 이용해 배치의 기능을 만든다.
Core Layer
- 배치 작업을 시작하고 제어하는데 필수적인 클래스
- Job, Step, JobLauncher
Infrastructure
- 외부와 상호작용
- ItemReader,ItemWriter,RetryTemplate
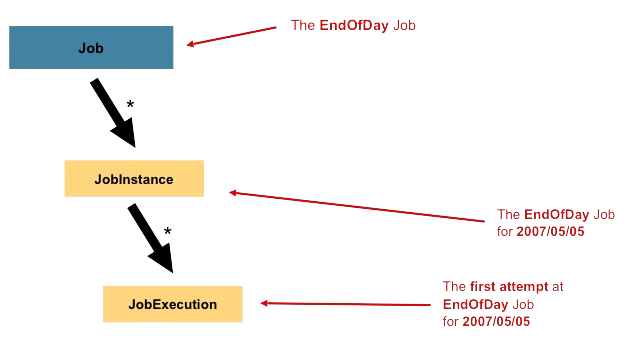
Job
Job은 아래 그림처럼 전체 배치 프로세스를 캡슐화하는 엔터티입니다. Job 엔티티 정의를 통해 JobInstance를 실행하고 Instance가 Excution을 실행하는 구조로 이뤄져있습니다.
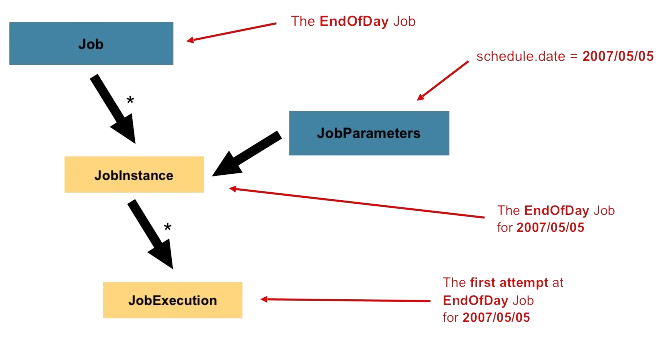
이 과정에서 JobParameters를 받아서 조건에 맞는 경우에만 실행이 되도록 할 수 있습니다.
💡 예시코드
// Spring Batch v5
@Bean //Bean으로 등록
public Job footballJob(JobRepository jobRepository) {
return new JobBuilder("footballJob", jobRepository)
.start(playerLoad()) //playerLoad는 스탭
.next(gameLoad()) //gameLoad 스탭
.next(playerSummarization()) //playerSummarization 스탭
.build(); // playerLoad ➡ gameLoad ➡ playerSummarization 슨서로 Step을 실행하고 Job 빌드
}Step
작업 처리의 단위를 의미합니다. 크게 Tasklet 방식과 Chunk 방식이 있습니다.
두 방식의 가장 큰 차이는 작업을 처리하는 단계의 분리 입니다.
Tasklet 방식 의 경우 execute 메서드 하나만 포함하고 있으며, 이 메서드에서 모든 작업이 수행됩니다.
그렇기 때문에 구현이 간단하고 코드가 직관적이고 이해하기 쉽습니다.. 또 하나의 메서드를 처리하는데 독립적인 트랜잭션을 사용하기 떄문에 반드시 메서드의 결과가 순차적이여야 하는 상황에 적합합니다.
하지만 많은 데이터를 처리할 때는 chunk 방식에 비해 비효율적이며, Tasklet은 특정 작업을 수행하도록 설계되므로, 재사용성이 낮다는 단점이 있습니다.
Chunk 방식 의 경우 데이터를 chunkSize에 맞게 나누어 처리하는 방식입니다. 각 chunk는 ItemReader, ItemProcessor, ItemWriter 세 가지 주요 구성 요소를 통해 읽기, 처리, 쓰기 단계를 거칩니다.
장점으로는 메서드의 처리가 분리되어있어 재사용이 용이하고 확장성과 유지보수성이 높습니다. 그에 반해 설정과 구조가 Tasklet 방식에 비해 복잡하고, 각 단계의 구성 요소를 정의하고 조정해야 하기 때문에 단순한 작업에는 과도할 수 있습니다.
각 방식에 대한 성능적인 비교는 이후 포스팅에서 진행하고 간단하게 알아보겠습니다.
Chunk-oriented Processing
chunk 방식은 아래 그림처럼 Step의 실행부터 종료까지 하나의 트랜잭션 에서 실행합니다.
commitInterval만큼 데이터를 읽고 트랜잭션 경계 내에서 chunkSize 만큼 write합니다.
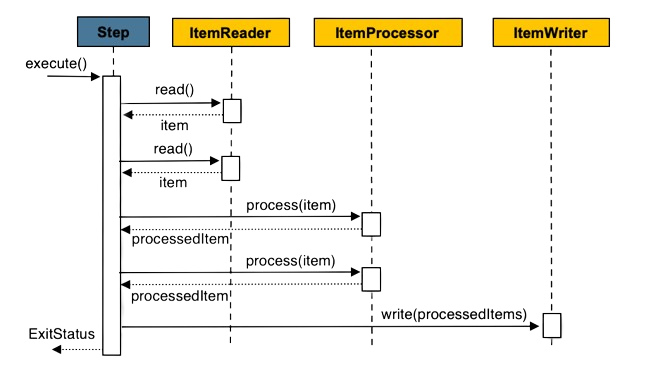
💡 예시코드
// Spring Batch v5
@Bean
public Job sampleJob(JobRepository jobRepository, Step sampleStep) {
return new JobBuilder("sampleJob", jobRepository)
.start(sampleStep)
.build();
}
@Bean
public Step sampleStep(JobRepository jobRepository,
PlatformTransactionManager transactionManager) {
return new StepBuilder("sampleStep", jobRepository)
.<String, String>chunk(10, transactionManager)
.reader(itemReader())
.writer(itemWriter())
.build();
}TaskletStep
앞의 chunk 방식의 과정을 하나의 메서드로 통합한 방식입니다.
RepeatStatus(반복상태)를 설정한다.RepeatStatus.FINISHED
💡 예시코드
@Bean
public Job taskletJob(JobRepository jobRepository, Step deleteFilesInDir) {
return new JobBuilder("taskletJob", jobRepository)
.start(deleteFilesInDir)
.build();
}
@Bean
public Step deleteFilesInDir(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("deleteFilesInDir", jobRepository)
.tasklet(fileDeletingTasklet(), transactionManager)
.build();
}
@Bean
public FileDeletingTasklet fileDeletingTasklet() {
FileDeletingTasklet tasklet = new FileDeletingTasklet();
tasklet.setDirectoryResource(new FileSystemResource("target/test-outputs/test-dir"));
return tasklet;
}public class FileDeletingTasklet implements Tasklet, InitializingBean {
private Resource directory;
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
File dir = directory.getFile();
Assert.state(dir.isDirectory(), "The resource must be a directory");
File[] files = dir.listFiles();
for (int i = 0; i < files.length; i++) {
boolean deleted = files[i].delete();
if (!deleted) {
throw new UnexpectedJobExecutionException("Could not delete file " +
files[i].getPath());
}
}
return RepeatStatus.FINISHED;
}
public void setDirectoryResource(Resource directory) {
this.directory = directory;
}
public void afterPropertiesSet() throws Exception {
Assert.state(directory != null, "Directory must be set");
}
}Spring Batch 스키마
Spring Batch를 사용하기 위해서는 반드시 Meta-Data Schema가 필요합니다. 이는 배치를 실행하고 관리하기 위한 용도이며, v4.xx 와 v5.xx의 스키마 구조가 달라 반드시 버전을 확인 하고 그에 맞는 스키마를 생성해줘야 합니다.
아래는 v5.xx에 맞는 스키마 생성 쿼리입니다(링크).
CREATE SEQUENCE BATCH_STEP_EXECUTION_SEQ;
CREATE SEQUENCE BATCH_JOB_EXECUTION_SEQ;
CREATE SEQUENCE BATCH_JOB_SEQ;
CREATE TABLE BATCH_STEP_EXECUTION_SEQ (ID BIGINT NOT NULL) type=InnoDB;
INSERT INTO BATCH_STEP_EXECUTION_SEQ values(0);
CREATE TABLE BATCH_JOB_EXECUTION_SEQ (ID BIGINT NOT NULL) type=InnoDB;
INSERT INTO BATCH_JOB_EXECUTION_SEQ values(0);
CREATE TABLE BATCH_JOB_SEQ (ID BIGINT NOT NULL) type=InnoDB;
INSERT INTO BATCH_JOB_SEQ values(0);
# BATCH_JOB_INSTANCE
CREATE TABLE BATCH_JOB_INSTANCE (
JOB_INSTANCE_ID BIGINT PRIMARY KEY ,
VERSION BIGINT,
JOB_NAME VARCHAR(100) NOT NULL ,
JOB_KEY VARCHAR(32) NOT NULL
);
# BATCH_JOB_EXECUTION_PARAMS
CREATE TABLE BATCH_JOB_EXECUTION_PARAMS (
JOB_EXECUTION_ID BIGINT NOT NULL ,
PARAMETER_NAME VARCHAR(100) NOT NULL ,
PARAMETER_TYPE VARCHAR(100) NOT NULL ,
PARAMETER_VALUE VARCHAR(2500) ,
IDENTIFYING CHAR(1) NOT NULL ,
constraint JOB_EXEC_PARAMS_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
);
# BATCH_JOB_EXECUTION
CREATE TABLE BATCH_JOB_EXECUTION (
JOB_EXECUTION_ID BIGINT PRIMARY KEY ,
VERSION BIGINT,
JOB_INSTANCE_ID BIGINT NOT NULL,
CREATE_TIME TIMESTAMP NOT NULL,
START_TIME TIMESTAMP DEFAULT NULL,
END_TIME TIMESTAMP DEFAULT NULL,
STATUS VARCHAR(10),
EXIT_CODE VARCHAR(20),
EXIT_MESSAGE VARCHAR(2500),
LAST_UPDATED TIMESTAMP,
constraint JOB_INSTANCE_EXECUTION_FK foreign key (JOB_INSTANCE_ID)
references BATCH_JOB_INSTANCE(JOB_INSTANCE_ID)
) ;
# BATCH_STEP_EXECUTION
CREATE TABLE BATCH_STEP_EXECUTION (
STEP_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT NOT NULL,
STEP_NAME VARCHAR(100) NOT NULL,
JOB_EXECUTION_ID BIGINT NOT NULL,
CREATE_TIME TIMESTAMP NOT NULL,
START_TIME TIMESTAMP DEFAULT NULL ,
END_TIME TIMESTAMP DEFAULT NULL,
STATUS VARCHAR(10),
COMMIT_COUNT BIGINT ,
READ_COUNT BIGINT ,
FILTER_COUNT BIGINT ,
WRITE_COUNT BIGINT ,
READ_SKIP_COUNT BIGINT ,
WRITE_SKIP_COUNT BIGINT ,
PROCESS_SKIP_COUNT BIGINT ,
ROLLBACK_COUNT BIGINT ,
EXIT_CODE VARCHAR(20) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED TIMESTAMP,
constraint JOB_EXECUTION_STEP_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ;
# BATCH_JOB_EXECUTION_CONTEXT
CREATE TABLE BATCH_JOB_EXECUTION_CONTEXT (
JOB_EXECUTION_ID BIGINT PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT CLOB,
constraint JOB_EXEC_CTX_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ;
# BATCH_STEP_EXECUTION_CONTEXT
CREATE TABLE BATCH_STEP_EXECUTION_CONTEXT (
STEP_EXECUTION_ID BIGINT PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT CLOB,
constraint STEP_EXEC_CTX_FK foreign key (STEP_EXECUTION_ID)
references BATCH_STEP_EXECUTION(STEP_EXECUTION_ID)
) ;해당 테이블의 경우에는 배치의 로그를 기록하는 용도일 뿐이며 배치 서비스 구현에 필요하지는 않습니다.
(하지만 없으면 배치가 아예 실행안됨,,,,,,)
여기까지가 이번 Spring Batch의 기본적인 내용입니다. 위 내용을 가지고도 간단한 배치 프로세스는 구현이 가능합니다.
예를 들어 Tasklet 방식으로 Step을 구성하고 excute() 메서드에 원하는 기능만 추가하면 배치 설정에 맞게 실행되는 것을 쉽게 확인할 수 있습니다. 다음 포스팅은 Spring Batch의 기본 프로젝트를 세팅하고 간단하게 배치를 테스트해보도록 하겠습니다. 읽어주셔서 감사합니다~!

정리가 너무 잘 되어있어서 도움 많이 받아갑니다! :)