view
하나의 가상 테이블이라고 생각
작업을 하다보면 자주 조회하는 데이터들이 있다. 한 테이블에 데이터가 있으면 조회하기 편하겠지만 그렇지 않은 경우가 있다. 여러 테이블들을 조인해서 가져오고
쿼리가 복잡한 경우도 있다. 이러한 경우 쿼리로 뷰를 만들어 놓고 사용하면 편리하다.
-뷰는 보안에 유리하다.
테이블에 데이터를 노출시키고 싶지 않을 때 뷰를 사용하여 보여줄 데이터만 뷰로 제공할 수 있다.
- 뷰의 특징
원천 데이터가 변경되면 view데이터도 자동 변경-뷰의 검색은 자유로우나 삽입,수정,삭제는 제약이 있다.
뷰 생성 쿼리에 함수를 사용하면 반드시 알리아스 지정
뷰는 테이블과 유사하며 테이블처럼 사용한다.
테이블과는 달리 데이터를 저장하기 위한 물리적인 공간이 필요하지 않은 가상 테이블이다.
데이터를 물리적으로 갖지 않지만, 논리적인 집합을 갖는다.
테이블과 마찬가지로 select, insert,update,delete명령이 가능하다.
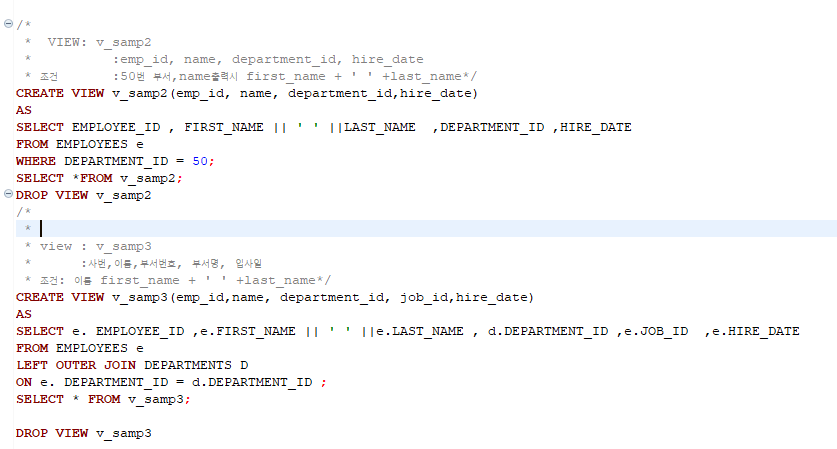
뷰 생성하는 방법
CREATE VIEW v_emp(emp_id, first_name, job_id,hiredate,dept_id)
AS
SELECT EMPLOYEE_ID , FIRST_NAME , JOB_ID , HIRE_DATE ,DEPARTMENT_ID
FROM EMPLOYEES e
WHERE JOB_ID = 'ST_CLECK'
;뷰 삭제하는 방법
DROP VIEW V_EMP;사용예제
sequence
- 시퀀스란
연속적으로 번호를 만들어 주는 기능
시퀀스란 자동으로 순차적으로 증가하는 순번을 반환하는 데이터베이스 객체이다. 보통 pk값에 중복값을 방지하기 위해 사용 - 시퀀스 생성
create sequence 시퀀스 이름
increament by n : 증가값을 설정, 2->2씩 증가
start with n :시작값
maxvalue n :최대값(nomaxvalue)
minvalue n : 최소값(nominvalue, cycle 옵션일 경우)
cycle : 시퀀스를 순 사용할지를 설정
cache n :시퀀스의 속도를 개선하기 위해 캐싱여부 지정
(nocache)
index
-
index란
- 조회속도를 향상시키기 위한 데이터베이스 검색 기술
- 색인이라는 뜻으로 해당 테이블의 조회 결과를 빠르게 하기 위해 사용
즉 인덱스가 필요한 이유는 인덱스를 생성해 줌으로써 조회 속도를 빠르게 할 수 있다.
-
인덱스의 내부 구조
index를 테이블의 특정 컬럼에 한개이상 주게되면 index table이 따로 만들어지고, 인덱스 컬럼의 로우값과 rowid값이 저장되면 row값은 정렬된 트리구조로 저장시켜
놓았다가 검색시 좀 더 빠르게 해당 데이터를 찾는데 도움을 준다.
(rowid는 테이블을 생성하고 컬럼을 만든 후 데이터를 삽입하면 하나의 row가 생성되며, 이는 절대적인 주소를 가지게 되는데 이를 오라클에서는 rowid라고 한다.)
DML명령을 상둉할 때는 원본 테이블은 물론 인덱스 테이블에도 데이터를 생신시켜 주어야 하기 때문에, UPDATE,INSERT,DELETE명령을 쓸 때 속도가 느려진다.
데이터가 많이 쌓일 것이라고 예상 되거나 많이 쌓여 있어서 현재 화면에서 조회속도가 너무 느릴때 인덱스 생성을 한다. -
반대로 인덱스 생성이 불필요한 경우
데이터가 적은 (수천건 미만)경우에는인덱스를 설정하지 않는게 오히려 성능이 좋다.
조회 보다 삽입, 수정, 삭제 처리가 많은 테이블 -
인덱스의 취약점
insert : index table에도 insert가 된다.
delete : index테이블에서 데이터를 지우지 않고 사용하지 않음으로 표시만 하게 된다.
update : 인덱스 테이블에서 delete를 한 후에 새로운 데이터를 insert작업을 함 -
index생성
unique 인덱스:인덱스를 사용한 컬럼의 중복값들을 포함하지 않고 사용할 수 있는 장점이 있다.
create unique index 인덱스명
on 테이블(컬럼);
non-unique인덱스 : 인덱스를 사용한 컬럼에 중복 데이터값을 가질 수 있다.
create index 인덱스명
on 테이블(컬럼);

감사합니다. 이런 정보를 나눠주셔서 좋아요.