[Review] A Survey on In-context Learning (2022)
Abstract
- Large language models (LLMs)의 increasing capabilities와 함께 in-context learning (ICL)은 natural language processing의 새로운 패러다임으로 떠올랐음. 여기에서 LLM은 few examples로 augmented된 context에 기반해 예측을 수행함.
- LLM의 능력을 추론하고 평가하기 위해 ICL을 탐구하는 것을 중요한 트렌드가 되었음.
- 이 논문은 ICL의 challenges와 progress를 요약하고 조사하는 것을 목표로 함.
- 우리는 첫번째로 ICL의 formal definition을 소개하고, 관련 연구들 간의 상관관계를 명확히 하고자 함.
- 그 다음, 우리는 advanced techniques들을 구성하고 논의함. 여기에는 training strategy, prompt designing strategies, related analysis가 포함됨.
- 추가적으로, 우리는 다양한 ICL application 시나리오들을 탐구하며 (such as data engineering, knowledge updating)
- 마지막으로, 우리는 ICL의 challenges를 다루고, 향후 연구를 위한 potential direction를 제안함.
- 우리는 우리의 연구가 ICL이 어떻게 동작하는지에 대한 이해를 돕고, ICL를 향상시킬 수 있는 데 대한 더 많은 연구들을 촉진시킬 수 있을 것으로 기대함.
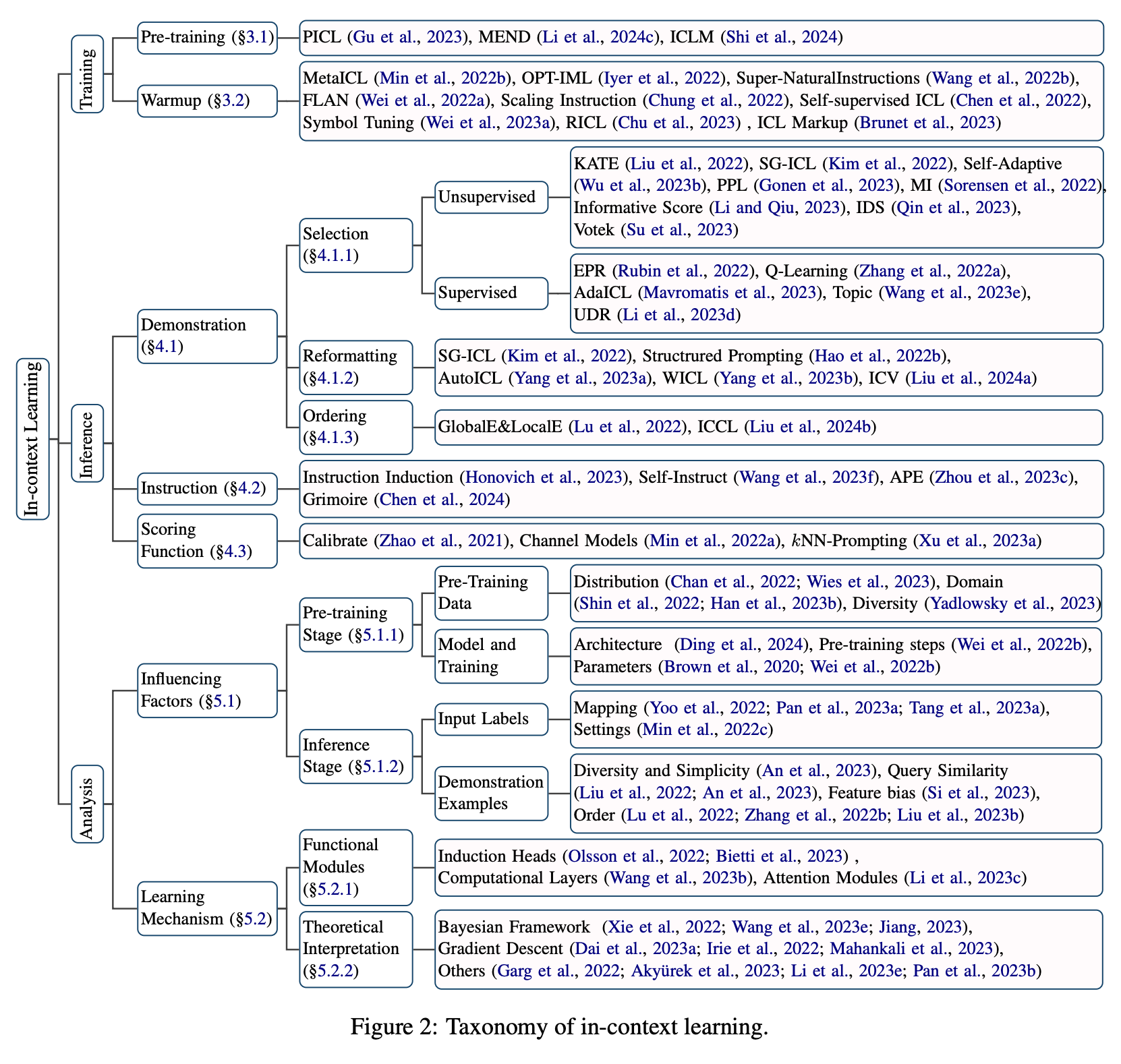
1. Introduction
In-Context Leanring
- Model size와 data size가 증가하면서, LLM은 in-context learning (ICL) 능력을 증명하였음.
With the scaling of model size and data size
- 이는 즉, context 내에 있는 몇 개의 예제로부터 학습하는 것을 의미함.
Learning from a few examples in the context
- 많은 연구들은 LLM이 complex tasks의 시리즈들을 ICL을 통해 수행할 수 있다는 것을 발견하였음. (e.g., solving mathematical reasoning problems)
- 이러한 강력한 능력은 large laguage model의 emerging abilities로서 여겨지고 있음.
ICL의 동작방식
- In-context learning의 key-idea는 analogy(비유/유추/유사)로부터 학습하는 것임. - 아래 Figure 1은 "how language models make decisions via ICL"에 대한 내용을 보여주고 있음.
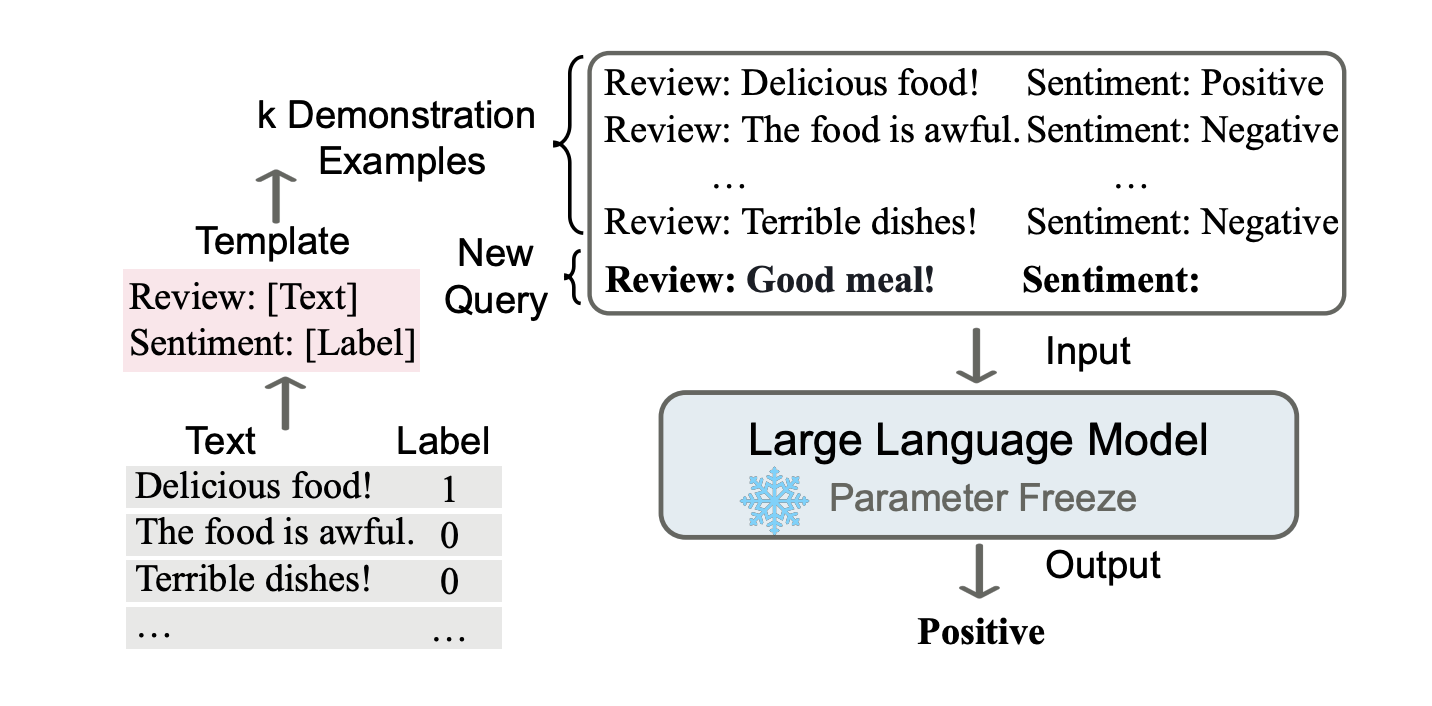
ICL requires a pormpt context containing a few examples written in natural language templates. Taking this prompt and a query as the input, large language models are responsible for making prediction.
- 첫 번째로, ICL은 prompt context를 형성하기 위해 a few demonstration examples를 요구함. 그리고 이러한 예제들은 주로 natrual language templtes로 작성됨.
- 그 다음, ICL은 query question과 the piece of prompt context를 함께 concatenate하여 input을 만듦. 이는 language model의 입력으로 들어가 prediction하는 데 활용됨.
- backward gradients를 model parameters를 업데이트 하는 데 활용하는 supervised learning과는 다르게, ICL은 parameter updates를 수행하지 않음.
- 모델은 demonstration안의 숨겨진 pattern들을 학습하며, 이에 따라 right prediction을 생성함.
Advantages & Unexpected Areas
-
새로운 패러다임으로써, ICL은 다수의 attractive advantages를 가지고 있음.
-
첫 번째, demonstration을 natural language로 작성할 수 있음.
- 이것은 LLM과 상호작용할 때 해석가능한 인터페이스를 제공함.
- 또한 human knowledge를 LLM에 통합시키는 것을 더 쉽게 만들며, 이는 demonstration과 templates를 단순히 수정함으로써 가능함.
-
두 번째, in-context learning은 analogy로부터 학습을 수행하는 인간의 의사결정 과정과 유사함.
-
세 번째 supervised learning과 다르게, ICL은 training-free learning framework를 가짐.
-이것은 computational costs (for adapting the model to new task)를 상당히 줄일 뿐만 아니라
- langauge-model-as-a-service를 만드는 것을 가능하게 함. (이는 곧 large-scale real-world tasks에 쉽게 적용될 수 있음)
-
이러한 유망함에도 불구하고 여기에는 ICL에 대한 더 많은 investigation을 요구하는 interesting question과 intriguing properties들이 남아있음.
- vanilla GPT models이 ICL의 우수한 capability를 보여주고 있음에도 불구하고 몇 개의 연구들은 이러한 capability가 adaptation (during pretraininig)을 통해 크게 향상될 수 있음을 보여주었음.
- 게다가 ICL의 능력은 specific settings (including prompt template, the selection and order of demonstration examples, and other factors)에 의해 민감함.
- 추가적으로, conciseness of demonstration examples (예제들의 간결함)을 최적화하고 ICL의 computational efficiency를 향상시키는 것이 지속적인 연구의 중요한 부분임 (critical areas of ongoing research)
- 게다가, preliminary explanations에도 불구하고 ICL의 underlying working mechanism은 불명확하며, 더 많은 조사를 요구함.
Goal of this paper
- ICL에 대한 빠른 연구와 함게, 우리의 조사는 현재 동향에 대해 커뮤니티가 민감하게 반응할 수 있도록 하는 것을 목표로 함.
- 다음 섹션부터, 우리는 in-depth discussion of related studies에 대해 탐구하며, Appendix A에 key findings들을 정리할거임. (왜 Appendix에 해주시지??)
- 우리는 challenges와 Potential direction을 강조하며, 우리의 연구가 이 분야에 관심이 있는 beginners에게 유용한 roadmap이 되고 future research를 명백히하는 데 도움을 주길 바람.
2. Definition and Formulation
-
이전 연구에 따라, 우리는 formal definition of in-context learning을 제시함.
In-context learning is a paradigm that allows language models to learn tasks given only a few examples in the form of demonstration.
-
공식적으로, query input text 와 a set of candidate answers 이 주어졌을 때, pre-trained language models 은 maximum score를 가진 candidate answer를 prediction으로 결정함. (conditioned a demonstration set )
-
는 optional task instruction 와 demonstration examples를 포함함.
-
여기서 은 task에 따라 자연어로 작성된 example들임.
-
Candidate answer 의 likelihood는 socring function 로부터 계산됨. (whole input sequence에 대해)
- final predicted label 는 highest probability를 갖는 candidate answer가 됨.
- 이 정의에 따르면 우리는 ICL이 다음과 같이 관련된 개념과 다르다는 것을 알 수 있음.
Prompt Learning
-
prompts가 templetes들로 discrete될 수 있거나 soft parameters가 model이 desired output을 예측하는 것을 도울 수 있음.
-
ICL은 prompt tuning의 subclass 정도로 분류될 수 있으며, 여기에서 demonstration examples는 prompt 중 하나의 파트임.
-
사전 연구에서 prompt learning에 대한 서베이를 진행했지만 이 연구에 ICL은 포함되지 않았음.
Prompt learning
Pre-trained Language Model을 특정 Task에 맞게 최적화 하기 위해 모델에 입력으로 주어지는 Prompt를 조작하여 원하는 출력을 유도하는 방식을 연구하는 분야로, 크게 다음과 같은 두 가지 방식을 활용
a) Discrete templates: 명시적인 텍스트 형태의 프롬프트를 최적화
b) Soft parameters: 학습 가능한 연속적인 벡터 형태의 프롬프트를 최적화 -
이와 달리 ICL은 자연어로 작성된 demonstration (with task instruction, few examples)를 통해 task를 최적화하는 방식으로, few-shot / zero-shot 환경에서 어떻게 더 잘 프롬프트를 구성할 수 있을까에 초점을 맞춤.
-
이는 descrete의 templates의 한 일종으로 볼 수 있으므로, 논문에서는 subclass에 포함될 수 있다고 표현하였음. 어쨌든 결과적으로는 prompt learning(혹은 tuning)이 더 큰 개념으로 사용됨.
Few-shot Learning
- few-shot learning은 제한된 수의 supervised examples를 통해 model parameters를 최적화하는 과정을 포함하는 general machine learning approach임. 반면에, ICL은 parameter updates를 필요로 하지 않으며, pre-trained LLMs를 바탕으로 직접적으로 수행함.
3. Model Training
- LLM이 ICL의 capability의 유망함을 보여주어오고 있지만, 많은 연구들은 이러한 ICL의 capabilities들이 더 나아가 specifalized training (before training)을 통해 향상될 수 있다고 보았음.
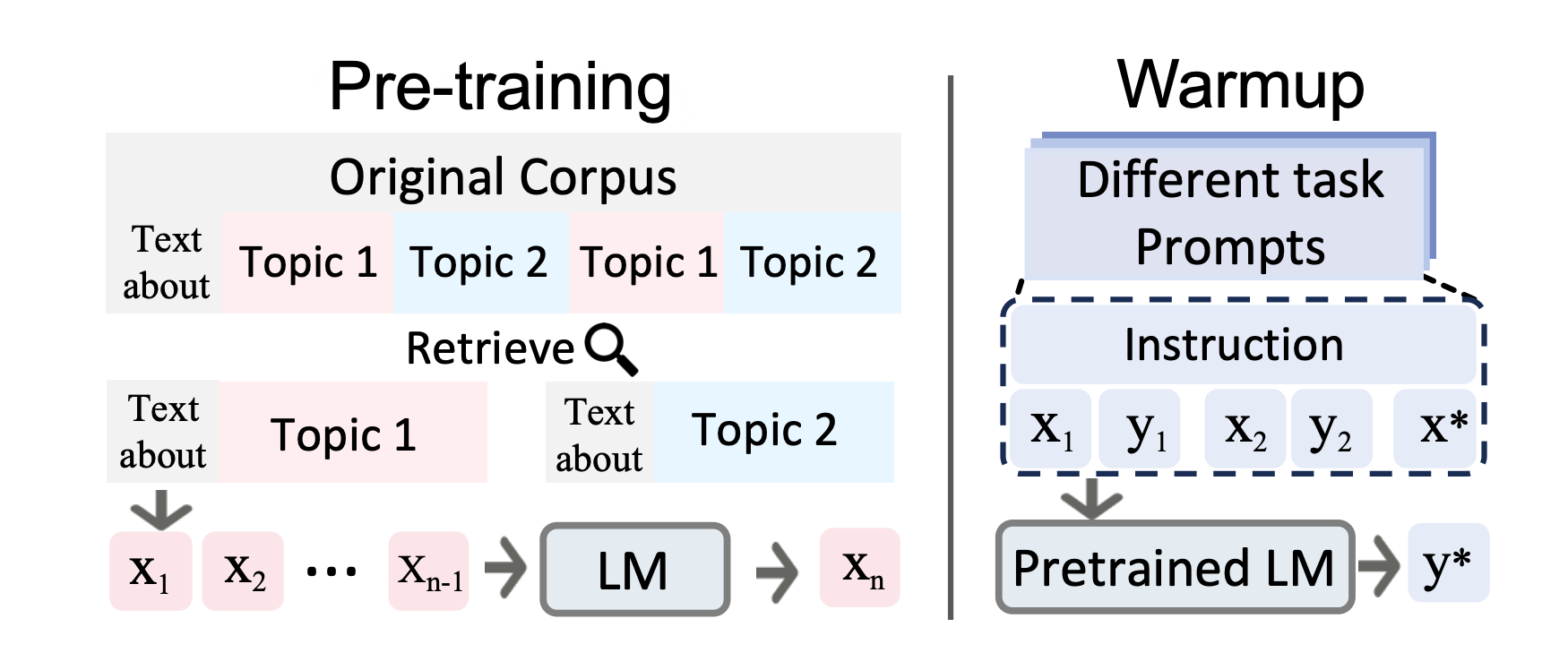
3.1 Pretraininig
- ICL의 성능을 향상시키기 위해 활용할 수 있는 가장 직관적인 방법은 pretraininig 또는 continual pretraininig을 수행하는 것임.
- 예를 들어, 이전연구에서는 pretraininig copora를 related contexts를 aggregating함으로써 인식하고, 모델이 prior demonstration을 통해 reason하는 법을 학습할 수 있도록 함.
In-context pretraining: Language modeling beyond document boundaries. In The Twelfth International Conference on Learning Representations (2024)
- 또 다른 연구에서는 meta-distillation pretraining process를 도입하였으며, 여기에서 LLM은 distilled demonstration vectors를 통해 추론할 수 있도록 하는 방법을 통해 ICL efficiecy를 향상시켰음.
3.2 Warmup
-
ICL ability를 향상시킬 수 있는 또 다른 방법은 continual training stage를 pretraining과 inference사이에 추가하는 것임. (그리고 우리는 이걸 model warmup for short라고 부름)
-
Warmup은 optional procedure for ICL임. 그리고 이건 LLM inference전에 adding parameters들을 수정함으로써 LLM을 조정함.
-
대부분의 pretraining data가 ICL에 맞게 구성되지 않기 때문에, 연구자들은 various warmup strategies를 도입했음. 이 pretraining과 ICL inference간의 격차를 극복하기 위해.
-
이전 연구에서는 연속적으로 LLMs을 broad range of tasks들에 대한 multiple demonstration examples들로 대해 finetune하는 방법을 제안하였으며, 이는 ICL abilities를 boost시켰음.
-
또 다른 연구에서는 모델이 context의 input-label을 mappings하는 능력을 향상시키기 위해 symbol tuning 기법을 제안하였음. 그리고 이것은 자연어 기호(positive/negative sentiment)를 임의의 심볼(too/bar)로 대체하는 방법을 제안하였음.
Symbol tuning improves in-context learning in language models. (EMNLP, 2023)
-
또 다른 연구는 downstream task의 raw text를 ICL 포맷으로 일치시키기 위한 self-supervised method를 제안하였음.
Improving in-context few-shot
learning via self-supervised training. (ACL, 2022) -
이하 부분 약간 생략
Prompt Designing
- 이 섹션에서 우리는 inference동안의 ICL의 principles에 초점을 맞춤. 여기에는 demonstration organization, instruction formatting이 포함됨.
4.1 Demonstration Organization
- 많은 연구들이 ICL의 성능이 demonstration surface에 강하게 의존한다는 사실을 밝혀옴. (such as selection, formatting, ordering of demonstration examples)
- 이 서브섹션에서 우리는 demonstration organization streategies들을 소개함. 그리고 그것들을 다음과 같이 세 가지 카테고리로 나누어서 분류함.
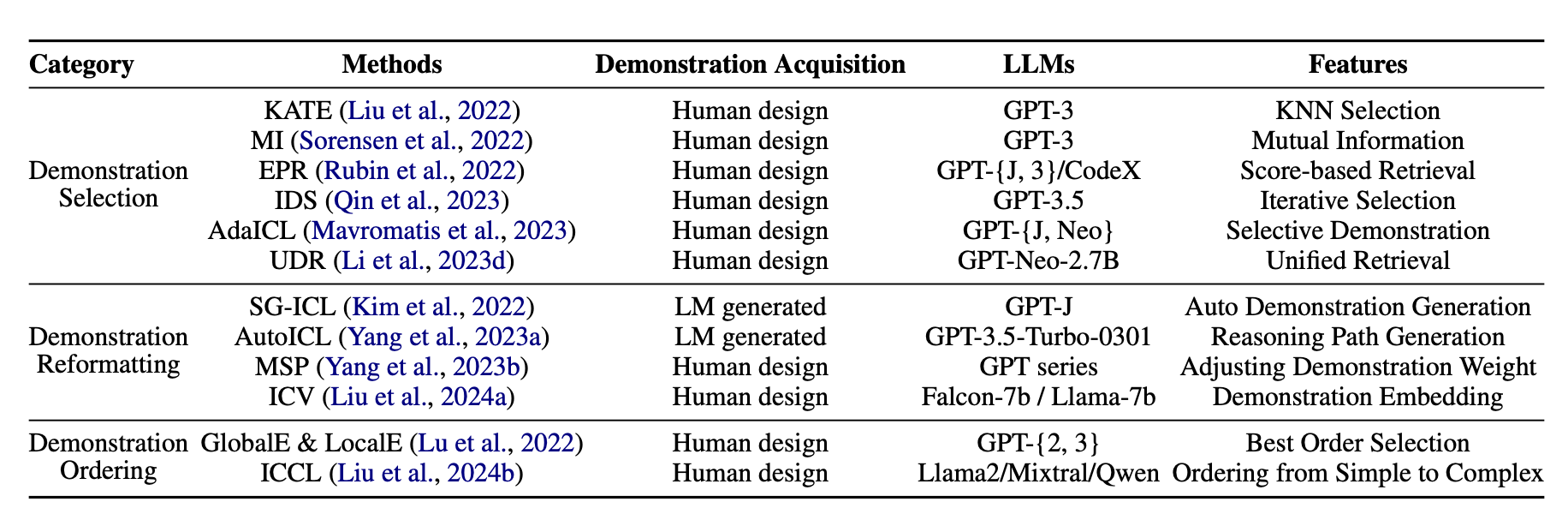
4.1.1 Demonstration Selection
-
demonstration selection은 다음과 같은 근본적인 질문을 해결하는 것을 목표로 함.
What samples are good examples for ICL
-
우리는 관련 연구들을 두 가지 접근법으로 나누어서 설명하고자 함.
- Unsupervised methods based on predefined metrics
- Supervised methods
Unsupervised Method
- ICL examples을 선택하는 것에 대한 직관적인 접근법은 input instances와 가장 가까이 있는 neighbors를 선택하는 것임 (based on their similarities) - 많은 연구들에서 이 방법을 채택하고 있음.
- Distance metrics (such as L2 distance or cosine similarity based on sentence embeddings)이 흔하게 사용됨.
- 예를 들어, 한 연구에서는 KATE를 제안했는데, 얘는 kNN기반의 unsupervised retriever임. in-context examples를 선택하기 위한.
- 유사하게 k-NN cross lingual demonstrations는 multi-lingual ICL을 위해 사용되어 source-target language alignment를 강화함.
- 다른 연구에서는 graphs와 confidence scores를 결합하여 다양하고 대표적인 예제들을 고르도록 했음.
- 게다가 distance metrics로 mutual information이나 perplexity를 사용하는 연구들은 이것들이 prompt selection에 유효하다는 것을 보여줌. (labeled examples or specific LLMs 없이도)
- 게다가, output scores of LLMs를 unsupervised metrics로 이용하는 연구들도 있었으며 이것이 demonstration selection의 effectiveness를 향상시킬수 있다는 것을 보여주었음.
- 특히, 한 연구는 best subset permutation of kNN examples를 와 가 주어진 상황에서 라벨 를 compress하기 위해 데이터를 전송하기 위한 code length를 고려해 선택하는 방법을 제안함 (???)
- 마지막 연구 하나 생략
Supervised Method
-
off-the-shelf retrievers가 extensive NLP 테스크를 위한 편리한 서비스를 제공하고 있음에도 불구하고, 이것들은 휴리스틱하고 sub-optimal함. 왜? 이것들이 task-specific supervision이 부족하기 때문에.
-
이를 해결하기 위해, 많은 supervised method들이 개발되어 왔음.
-
EPR (2022)는 demonstrate selection을 위해 dense retriever를 훈련하기 위한 two-stage method를 제안함.
- Specific input을 위해 이것은 unsupervised methods (e.g., BM25)를 활용하여 similar examples를 cindidates들로 불러옴
- 이후 이 데이터들은 supervised dense retriever를 구성하는 데 사용함. (그럼 룰베이스로 데이터셋 만들어서 학습시킨다는 것?)
-
EPR에 따라, 다른 연구는 통합된 demonstration retriever를 채택하였음. 이는 different tasks들에 따른 demosntrations을 선택하는 역할을 함.
-
이전 연구와 다르게, (individual demonstrations을 반환했던) 또 다른 연구는 전체 demonstratios set을 반환하는 방법을 선택함. 이러한 방식은 모델이 example간 inter-relationships을 고려할 수 있게 함.
-
추가적으로, 다른 연구는 AdaICL을 제안하였으며, 이는 model-adaptive method로, 여기에서 LLM은 unlabeled data set을 예측함으로써 uncertainty score for each instance를 생성하도록 함.
맨 마지막 uncertainty score 관련 논문
Which examples to annotate for in-context learning? towards effective and efficient selection (CoRR, 2023)
- Prompt tuning을 기반으로, 다른 연구는 LLMs를 topic model로 보았으며,, 이를 통해 concept 를 몇 개의 demonstration으로부터 추론하고, 이 컨셉들을 바탕으로 token을 생성하도록 했음.
- 오 뒤에 이거에 대한 설명이랑 강화학습 이야기나오는데 일단 당장은 필요 없을 것 같아서 패스~
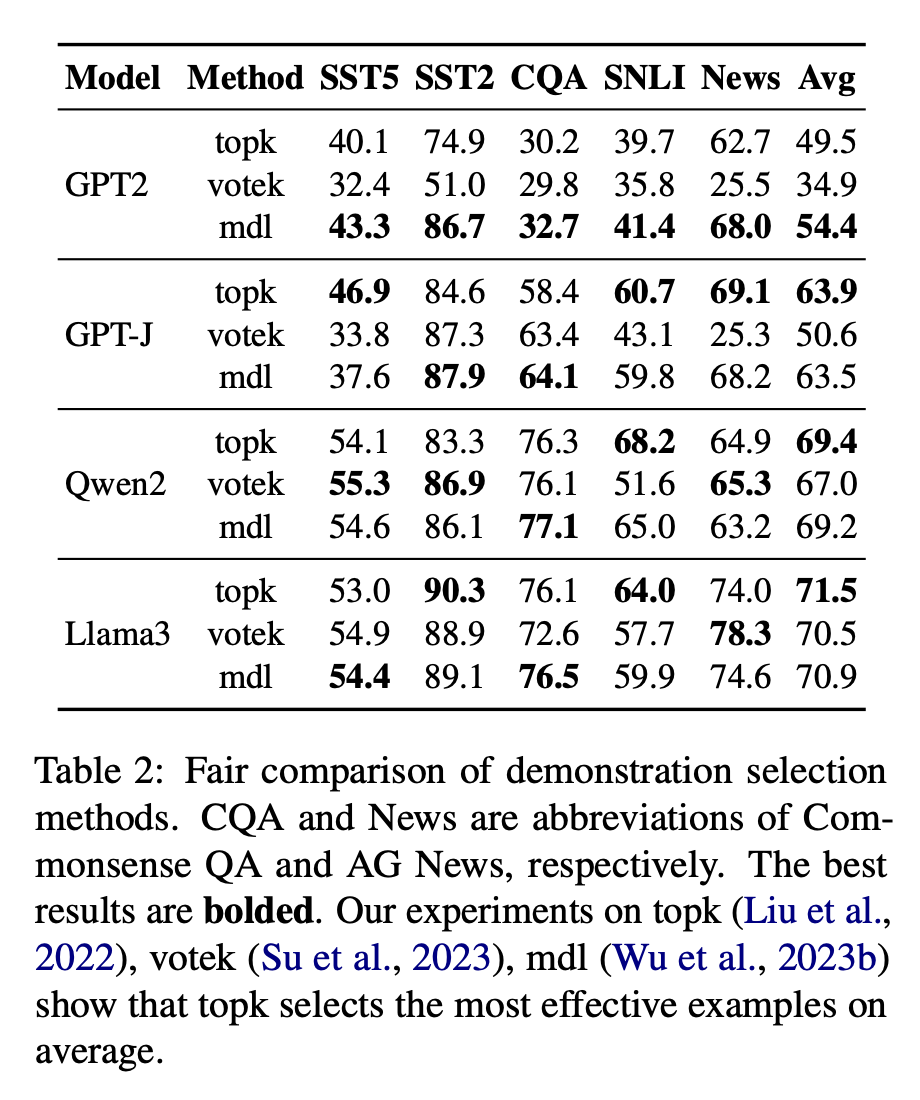
- 보다 직관적인 성능 비교를 위해 (unsupervised methdos에 대한) 우리는 topk, votek, mdl을 기반으로 실험을 수행했음. 실험 결과는 아래와 같으며, 더 많은 정보는 Appendix B에 있음.
Demonstration Reformatting
-
직접적으로 training data로부터 examples를 선택하기 위한 또 다른 연구 트렌드는, LLMs을 이미 존재하는 demonstrations들의 representation을 reformat하는 데 활용하는 것임.
-
예를 들어, Kim et al., 2022) 연구는 LLM으로부터 demonstrations을 직접적으로 generation하는 방식을 선택함으로써 external demonstration data에 대한 의존성을 줄였음.
Self-generated in-context learning: Leveraging autoregressive language models as a demonstration generator. ArXiv preprint, abs/2206.08082 (2022) - 서울대학교 논문 (한 번 읽어보면 좋을 듯)
-
또 다른 연구는 Structured Prompting을 제안하였음. 이는 demonstration examples들을 개별적으로 인코딩함. (with special positional embeddings) 그리고, rescaled attention mechanism을 사용해 test example에 이것들을 제공함.
-
이러한 방법론들로부터 벗어나(diverging from these methods) 다른 접근방법은 latent representation of demonstrations을 수정하는 것에 초점을 맞춤. 구체적으로, 한 연구는 In-Context Vectors (ICVs)를 LLM내의 demonstration examples의 잠재적 임베딩들로부터 만들고, 이 ICV들을 inference동안 latent states of the LLM을 조정하는 데 사용함.
-
이를 통해 model의 demonstrations을 follow하는 능력들을 보다 효과적으로 강화할 수 있었음.
In-context vectors: Making in context learning more effective and controllable through latent space steering. (2024)
Demonstration Ordering
- 선택되는 demonstation examples의 순서를 정하는 것은 또한 demonstration organization의 중요한 파트임.
- 한 연구에서는 order sensitivity가 common prlbem이고, 항상 various models에 존재하는 것이라고 밝혔음.
- 이 문제를 다루기 위해 이전 연구들은 several traninig-free methods를 제안하였음. demonstration examples들을 sorting하기 위한.
- 특히, 한 연구는 global / local entropy metrics를 도입하여 these metrics과 ICL performance간의 양의 상관관계를 밝혀내었으며, 결과적으로 그들은 이 entropy metrics를 optimal demonstration ordering을 결정하는 데 활용하였음.
- 추가적으로, ICCL 은 ranking demonstations 으로 단순한 것에서 복잡한 것으로 (simple to compelx)하는 방법을 제안했음. 그리고 이를 통해 점진적으로 complexity of demonstration를 (inference process동안) 증가시켰음.
4.2 Instruction Formatting
-
demonstration을 format하기 위한 흔한 방법은 concatenating examples임 (with a template 에 직접)
-
그러나, complex reasoning을 필요로 하는 몇몇 테스크에서는 (e.g., math word problems, and commonsense reasoning) 오직 demonstration만으로는 에서 를 매핑하는 함수를 학습시키기 어려움. (어~~ 나도 그래~~!)
-
template engineering이 prompting안에서 연구되고 있는 가운데, 몇몇의 연구자들은 instuction 와 함께 task를 describing함으로써 ICL을 위한 demonstations의 포맷을 더 잘 디자인하는 방법에 초점을 맞춰왔음.
-
한 연구는 몇개의 demonstration examples가 주어졌을 때, LLM이 task instruction을 그들 스스로 생성할 수 있다고 보았음.
Instruction induction: From few
examples to natural language task descriptions. (ACL 2023) -
LLMs의 generation abilities들을 고려하면서, 다른 연구는 Automatic Prompt Engineer를 개발하였음. 이는 automatic instruction generation and selection을 함.
Large language models are human-level
prompt engineers (ICLR 2023) -
더 나아가 자동으로 생성되는 instruction의 퀄리티를 향상시키기 위해 몇개의 전략은 LLM을 그것의 own generation을 boostrap off하는 데 사용하였음.
Self-instruct: Aligning language models with self-generated instructions. (ACL 2023)
Grimoire is all you need for enhancing large language models (CoRR, 2024) -
추가적으로, Chain-of-thought (CoT)는 intermediate input과 output간의 reasoning steps를 도입하여 problem-solving 및 comprehension을 강화하였음.
-
이외의 최근의 많은 연구들은 LLM의 step-by-step reasoning의 강화를 강조하고 있음.
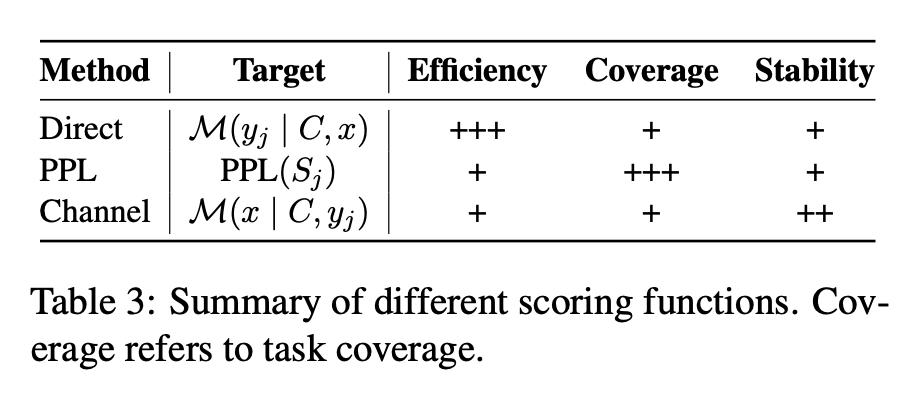
4.3 Scoring Function
- scoring function은 다음과 같이 정의됨.
How to transform the predictions of a language model into an estimation of the likelihood of a specific answer
- Direct method는 conditional probability of candidate answers (represented by tokens in the models' vocab)를 사용하는 것임
- 이때, 가장 높은 probability를 갖는 answer는 final answer로 선택됨. 그러나, 이 방식은 input sequences의 끝에 answer 토큰이 추가되어야 하기 때문에 template design에서의 제한이 있음.
- PPL은 흔하게 사용되는 다른 메트릭임. 이건 entire input sequence에 대한 sentence perplexity를 계산함. 이 entire input sequence는 demonstration examples 로부터, input query 그리고 candidate label 에 대한 tokens들을 포함함.
- PPL은 sentence의 probability를 평가함. 이 방법은 위에서 말했던 answer token의 위치를 제한할 필요는 없지만 계산을 위해 추가적인 computation time을 요구함.
- 다른 연구에서는 Channel이라는 것을 conditional probability를 역으로 계산하는 데 활용함. 이 방식은 주어진 label에 대한 input query의 likelihood를 추정함.
- 이 방식은 language model이 input 안에 있는 모든 토큰들을 generate하는 것을 요구하지만, 잠재적으로 imbalanced traininig data의 선응을 올릴 수 있는 능력이 있음.
- 우리는 이러한 scoring function에 대해서 Table 3에 요악함.
5. Analysios
-
ICL을 이해하기 위해, 최근의 연구들은 무엇이 ICL 퍼포먼스에 영향을 주는지, 그리고 왜 ICL이 동작하는지에 대한 연구를 수행하기 시작했음.
What influence ICL performance / Why ICL works
-
이 섹션에서 influencing factors, learning mechanisms of ICL에 대한 상세한 설명을 제공하고자 함.
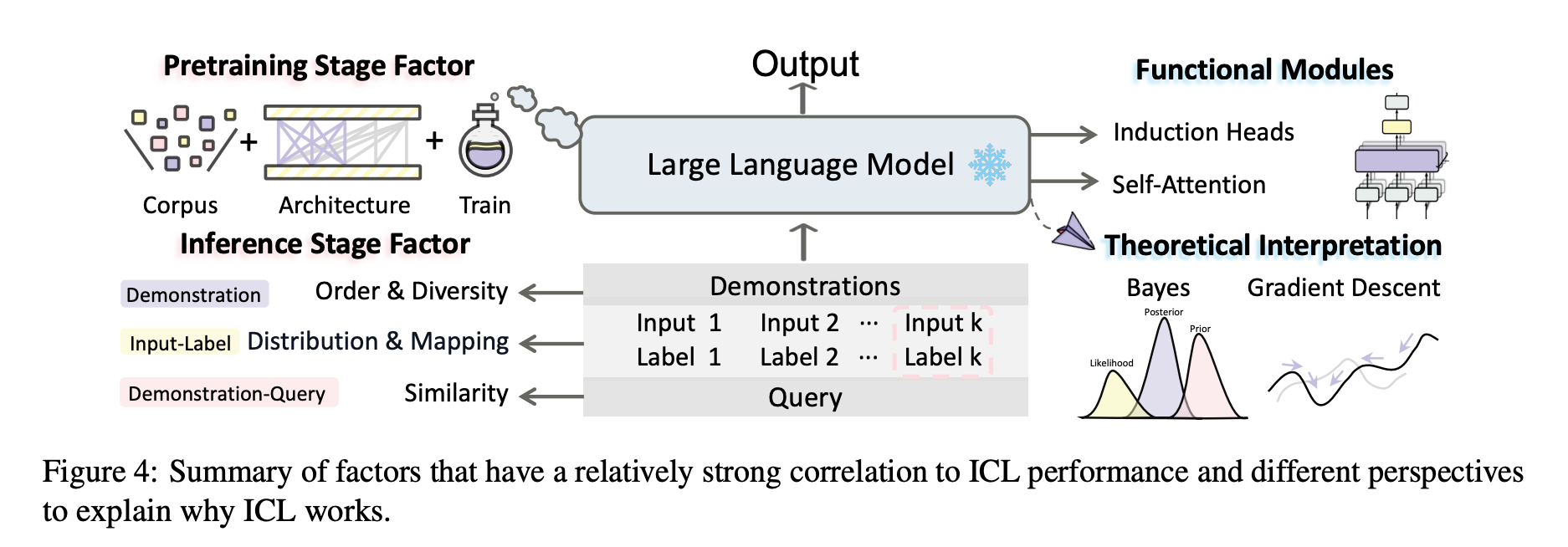
5.1 Influencing Factors
- 우리는 What influences ICL Performance에 대한 질문을 해결하기 위한 연구들을 소개함. (including factors both in the pretraining stage and in the inference stage)
5.1.1 Pretraining Stage
- 우리는 pretraining stage에서 영향을 줄 수 있는 factor들을 첫번째로 소개하고자 함.
- pretraining copora의 다양성은 상당히 ICL의 성능에 영향을 준다는 연구결과드이 많았음.
- 특히, 한 연구는 source d omain이 corpus size보다 중요하다는 것을 강조했으며, multiple copora를 결합하는 것이 ICL ability의 emergence를 이끌어내는 것을 시사하였음.
- 유사하게, 다른 연구에서는 경험적으로 LLMs이 stong ICL capabilities를 unseen task에서 나타내는지를 위한 task diversity threshold를 식별하였음.
- 또 다른 연구에서는 data distribution의 영향을 조사하였음. 예를 들어, 한 연구는 ICL capability가 specific distributional properties를 보이는 데이터로 학습했을 때 발생한다고 보았음. (이하생략)
- 이러한 연구를 넘어, ㅁ몇 개의 연구들은 model architecture와 traininig process이 ICL의 성능에 영향을 미친다고 보았음. 한 연구는 multiple task에 대한 다양한 큰 규모의 언어모델의 emergent abilities를 조사하였음. 그들은 pretrained model이 some emergenct ICL abilities들을 보유할 수 있게 된다고 언제? 그것들이 large scale of pretraining steps or model parameters에 도달했을 때 / 밝혔음.
- 다른 연구는 in-context samples이 서로 반드시 inference동안 attend되어야 함을 지적하였음. 현재의 causal LLM이 suboptimal ICL performance로 이어질 수 있음을 시사하면서.
5.1.2 Inference Stage
- inference 동안에, multiple properties of demonstration examples들이 존재함. (ICL에 영향을 줄 수 있는)
- 한 연구는 input-label settings (pairing format, the exposure of label space, input idstirbution)이 ICL의 성능에 상당한 영향을 미친다고 보았음.
- 그러나, 반대로 input-label mapping은 ICL에 크게 중요하지 않으며 accurate mapping이 ICL 성능에 큰 영향을 준다는 연구결과도 존재함.- 이와 관련된 연구 하나 나오는데 생략
- demonstration construction 관점에서 최근의 연구들은 diversity와 simplicity of demonstration에 초점을 맞추고 있음.
- 예를 들어, 한 연구는 demonstration samples with embeddings closer to those of query samples이 전형적으로 better performance를 생산한다고 보았음 (than those with more distant embeddings)
- 주목할점은, demonstrations을 refine하는 노력에도 불구하고, 여전히 clear feature biases가 ICL inference동안 존재한다는 점임.
- strong prior biases를 극복하고 모델이 equal weights를 모든 contextual information에 부여하도록 하는 것은 매우 어려운 일임.
5.2 Learning Mechanism
- 학습 메커니즘의 관점에서, 우리는 Why ICL is effective라는 연구주제를 다룬 논문들을 조사하였음.
5.2.1 Functional Modules
- ICL capability는 Transformer 내의 있는 specific functional modules들과 긴밀한 연관이 있음.
- core components중 하나로, attention module을 우리 연구에서는 focal point로 다루겠음.
- 특히, 한 연구는 specific attention heads (reffered to as "induction heads"가 previous patterns들을 next-token prediction을 위해 모사할 수 있다고 말함.
- 추가적으로, 다른 연구는 Transformer의 information flow에 초점을 맞추었으며, ICL process 동안에 demonstration labggel words가 anchors의 역할을 하며서 key information들을 aggregate하고 final prediction을 위해 distribute한다고 말함.
랩세미나 논문 여기에 있다~ 여기 맥락에 있다~ 찾았다...
5.2.2 Theoretical Interpretation
- 이 subsection에서 우리는 theorectical interpretations of ICL을 different view에서 소개함.
Bayesian View
- ICL은 implicit Bayesian inference라고 볼 수 있음. 여기에서 모델은 ICL을 examples들 간의 shared latent concept들을 식별함으로써 수행함.
- 기타 자세한 내용 생략
Gradient Descent View
- 일단 생략
Other Views
- 일단 생략
6. Application
- user-friendly interface, lightweight prompting methods와 함께 ICL은 traditional NLP tasks에 broad 하게 적용되고 있음.
- 특히, demonstration을 사용함으로써 explicitly guide the reasoning process가 가능해졌고, 이를 통해 ICL은 complex reasoning과 compositional generalization을 요구하는 다양한 작업에 대해 remarkable effects를 보여줌.
- 우리는 몇 가지 emerging and prevalent application of ICL을 소개할거고 여기에는 data engineering, model augmentation, knowledge updating이 포함됨.
Data Engineering
- traditional methdos와 다르게 (human annotation, noisy automatic annotation) ICL은 상대적으로 높은 퀄리티의 데이터를 lower cost로 생성할 수 있음. -> 성능 향상에 기여
Model Augmentation
- context-flexible nature of ICL은 model augmentation에도 놀라운 성과를 보여주었음. 이것은 retrieval-augmented methodos를 향상시킴. 입력 앞에 grounding documents를 추가함으로써..(??) 게다가 ICL for retrieval은 모델이 더 안전한 답변을 도출할 수 있도록 함.
ICL의 맥락에서 이는 모델의 파라미터를 변경하지 않고 입력을 통해 모델의 성능을 향상시키는 것을 의미
Knowledge Updating
- LLM은 종종 outdated or incorrect knowledge를 포함하고 있음. ICL은 이러한 knoiwledge를 revising하는 것에 대한 효율성을 보여줌. (신중하게 구성된 demonstration을 통해) - higher success rates를 도출하면서. (gradient-based methdos와 비교했을 때)
- 위에서 언급했듯이 ICL은 상당한 이점을 볼 수 있음 traditional and emergent NLP application에.
- 이러한 NLP에서의 ICL의 큰 성공에 따라 다양한 모달리티로 확장되기 시작했음
7. Challenges and Future Directions
- 이 섹션에서 우리는 existing challenges 그리고 discuss future directions for ICL할 예정
Efficiency and Scalability
-
ICL안에서 demonstration의 사용은 두 가지 어려움(challenge)을 도입함.
- higher computational costs with an increasing number of demonstrations (efficiency)
- fewer learnable samples due to the maximum input length of LLMs (scalability)
-
이전 연구에서는 이 이슈들을 완화하고자 lengthy demonstration을 compact vector로 distil하려고 했으며 LLM의 inference time을 늘리고자 하였음.
-
그러나, 이러한 방법들은 종종 trade-off in performance를 야기하거나, 모델 파라밑 ㅓ에 대한 필수적인 접근을 요구함. 그리고 이것은 closed-source-model (like ChatGPT, Claude)에 대해 impractical함.
-
그러므로, ICL의 scalability and efficiency를 높이는 것 (with more demonstration) 남은 해결해야 할 도전과제들임.
Generalization
- ICL은 high quality demonstrations selected from annotated examples에 강하게 의존. 그리고 이는 종종 low-resource language and tasks에 scarce함.
- 이러한 scarcity는 generalization ability of ICL에 대한 challenge를 야기함.
- 이에 따라 연구들에서는 high-resource data를 이용해 low-resource task를 처리하는 데 사용하는 등의 연구를 진행하였음
Long-context ICL
- 최근의 context extended LLM내의 발전은 더 많은 demonstration examples를 사용했을 때의 ICL의 영향에 대한 연구로 이어졌음.
- 그러나, 연구자들은 increasing the number of demonstration이 필수적으로 성능을 향상시키는 것은 아니라는 것을 발견하였음. (혹은 심지어는 저해시킴)
- 이러한 성능저하는 further investigation의 필요성을 나타냄.
- 추가적으로, LongICLBench를 개발한 연구도 있었음. 이는 diverse extreme-label classification tasks를 포함하는데 이 연구는 확장된 demonstrations을 이해하는 것에 대한 LLM의 약점을 드러냄.
8. Conclusion
- 이 페이퍼에서 우리는 comprehensively review하였음 literature on ICL들을. advanced techniques, conducting analytical studies, discussing relevant application, and identifying critical challenges들을 수행하였음.
0 우리의 지식에 따라, 이것은 first comprehensive survey임 ICL에 대한. - 우리는 highlight the current state of research in ICL을 강조하고 insight to guide future work in this promising area를 제공하는 것을 목표로 함.
