[Review] Improving Language Understanding by Generative Pre-Training (GPT-1)
DSAIL 2022-Summer
Story Generation Study (Week1)

0. Presentation
- 발표 예상 시간 : 15분 내외
- 지식 전달 목표
- Model Architecture : 모델이 어떻게 동작하는지?
- Background of NLP : 왜 이런 방식을 사용하는 모델이 등장하게 되었는지?
1. Summary
1-1. Labeled Corpus와 Unlabeled Corpus
- NLP task의 종류는 Document Classification, Question Answering, Machine Translation, Natural Language Inference 등 매우 다양하며, 이러한 task를 학습하기 위해선 해당 task에 맞는 라벨링된 데이터(Labeled corpus)가 필요함.
- 하지만 이러한 라벨링된 데이터는 손으로 직접(manually) 만들어야 하는 경우가 대부분이기 때문에, 특정 테스크를 위한 라벨이 달려있으면서(labeled) & 학습하기에 충분한 양이 있는 (large) 경우는 별로 없음!
- 내 테스크에 맞는 labeled data는 잘 없지만.. unlabeled corpus는 널려 있다!
- 그렇다면, 이렇게 많은 데이터를 그냥 허비하는 건 아까워! 이를 잘 활용할 수 있는 방법은 없을까?
1-2. In this Paper
- 그래서, 이 논문에서는 Pre-training of a language model on a diverse corpus of unlabled text를 바탕으로, Fine-tuning on each specific task를 하는 것을 시도함!
- 또한 다양한 Natural language understanding을 필요로하는 벤치마크 Task들을 통해 이 논문에서 제안하는 접근법이 얼마나 효과적인지 검증하고자 함.
- 모델은 총 네 가지 NLP Task에 대해 실험되었으며, 대부분의 경우에서 이 논문의 접근법이 다른 모델보다 뛰어났다는 것이 실험 결과를 통해 증명됨.
2. Pre-Knowledge
2-1. Word Embedding
- 단어를 어떻게 컴퓨터가 이해할 수 있는 숫자로 표현하느냐, 이 표현법에 따라 성능은 엄청나게 좌지우지 된다!
- 내가 가지고 있는 데이터로만 word embedding을 구성하는 것 보다는, unlabeled data를 이용해 전반적인 단어의 임베딩을 먼저 갖추는 것이 좋다는 다양한 실험이 있었음.
(예를 들어 우울, 눈물이라는 단어를 맨 처음부터 새롭게 알려주는 것보다, 사전에 다양한 텍스트를 통해 우울과 눈물이 대략 비슷하게 같이 등장한다는 것을 알려준 상태로 학습하는 게 더 유리함!) - 단어 수준 임베딩 : 비슷한 단어는 자주 같이 등장하지 않을까? (이 단어가 어떤 단어와 같이 쓰였는지에 따라 단어 임베딩) ex) Word2Vec, FastText, GloVE...
- 문장 수준 임베딩 : 이 단어 다음에 무슨 단어가 등장하는지 보자! 단어 뿐만 아니라, 보다 문장 안에서 이 단어의 위치, 맥락 등을 같이 고려한 임베딩! (Language Model: ELMo, GPT, BERT...)
(참조: https://m.blog.naver.com/horajjan/221662891600)
2-2. Transformer
- 일반적인 RNN 계열의 모델은 다음과 같은 두 문제가 고질병
- Long-term dependency 문제
- Sequential 하게 데이터를 처리하기 때문에 느림.
- 이와 같은 두 가지 문제를 해결하고자 나온 것이 Transforemr!
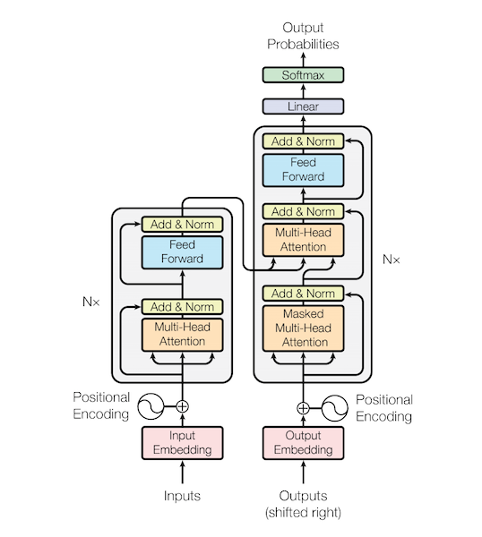
- "Attention is All you need"라는 논문의 제목 답게, Attention Mechanism만을 사용하여 모델이 전개됨.
1. 세 가지 Attention 기법을 활용하여, Long Term Dependency 문제 최소화- 순차X, 한 번에 다 때려박은 다음, Position 정보를 추가해주기 위해 Positional Encoding 적용 이로 인해 병렬 계산이 가능하여 빠.
- Encoder와 Decoder로 이루어진 구조인데, 가장 큰 차이점은 Encoder에서는 Attention 적용 시 모든 시퀀스를 참조할 수 있지만, Decoder는 Masked Self-Attention을 사용하기 때문에, 내 현재 시퀀스 다음 것은 참조하지 못함. (오늘 소개할 GPT-1은 Decoder 부분을 따온 것임!)
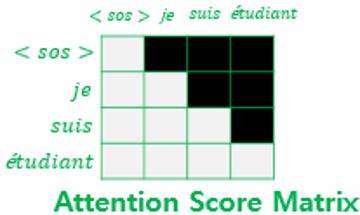
(출처 : https://wikidocs.net/31379)
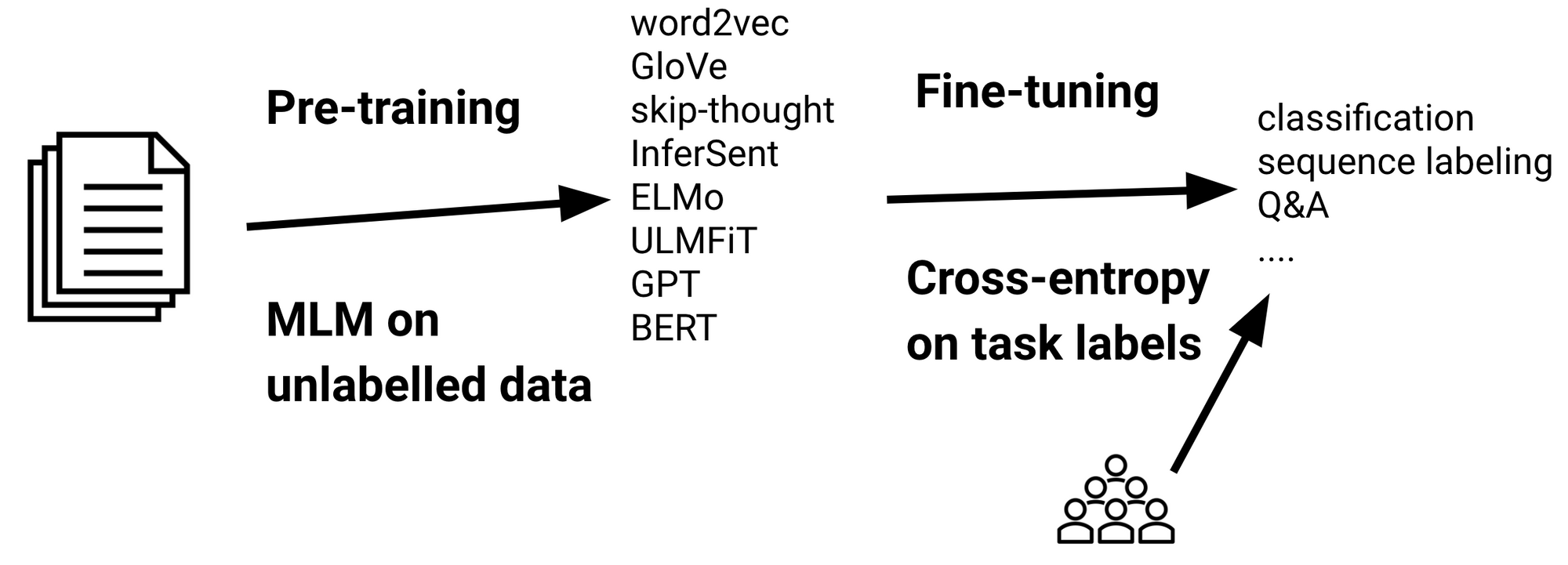
2-3. Pre-training & Fine-tuning
3. Introduction
3-1. Unlabeled Data의 활용의 이점
- Supervised Learning을 위해 Unlabeled Data로부터 언어적인 정보(linguistic information)를 활용하는 것은 추가적인 labeled data를 수집하는 것보다도 효율적일 수 있음. (manually labeling -> expensive, time-consuming)
- Supervised Leearning을 위한 충분한 데이터가 있는 경우에도, Unlabeled Data를 활용하면 그 성능을 Boosting시킬 수 있으며, Model Generalization에 효과도 있음.
3-2. Semi-Supervised Approach
- 이 논문의 목표는, Unlabeled Corpus를 활용한 Unsupervised Learning을 통해 생성된 Representation을 바탕으로, 더 효과적인 Supervised Leanring을 하고자 하는 것! (Semi-supervised approach)
- 사용하는 데이터
- Large corpus of unlabeled text
- Several datasets with manually annotated training examples for target task (=downstream task)
3-3. Unsupervised Learning
- Unsupervised Learning에서는 특정 테스크에 국한되지 않는, 여러 테스크에 general하게 사용할 수 있는 범용적인 텍스트 표현 벡터(universal representation)를 생성하는 것을 목표로 함.
- 이러한 모델을 위해, Transformer를 사용하였음 (그 중에서도 Decoder 부분) Transformer는 RNN 계열의 모델과 비교했을 때, 다양한 장점 중에서도 특히 Long term dependecnies를 해결하는 데 탁월하다는 것이 증명됨.
4. Framework
4-1. Two-Stage 접근방식
- 첫 번째 stage에서는 unlabeled large corpus를 바탕으로, high-capacity language model을 학습함.
- 두 번째 stage에서는 앞에서 만든 representation을 이용해, fine-tuning을 수행함. 내가 결과적으로 수행하고자 하는 Specific task (downstream task)를 위한 결과를 뽑아냄.
4-2. Unsepervised Pre-training
- unsupervised corpus of token이 주어졌을 때, standard language modeling objective를 사용함. 이는 다음과 같은 likelihood를 maximize하는 것임.
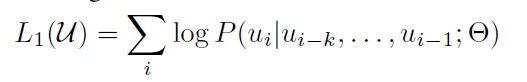
- K는 context window의 사이즈를 나타내며, P는 조건부 확률 (Conditional Propability)이고, Θ는 주어진 모델의 파라미터를 나타냄.
- 즉, 주어진 모델의 파라미터가 있을 때, 타겟으로 하는 word의 k만큼 전에 있는 단어들이 나왔을 때, 현재 이 i번째 단어가 나올 확률을 최대화 시키는 방향으로 학습하는 것임.
- 이러한 파라미터들은 Stochastic gradient descent로 학습되며, language model로는 multi-layer transformer decoder를 사용하였음.
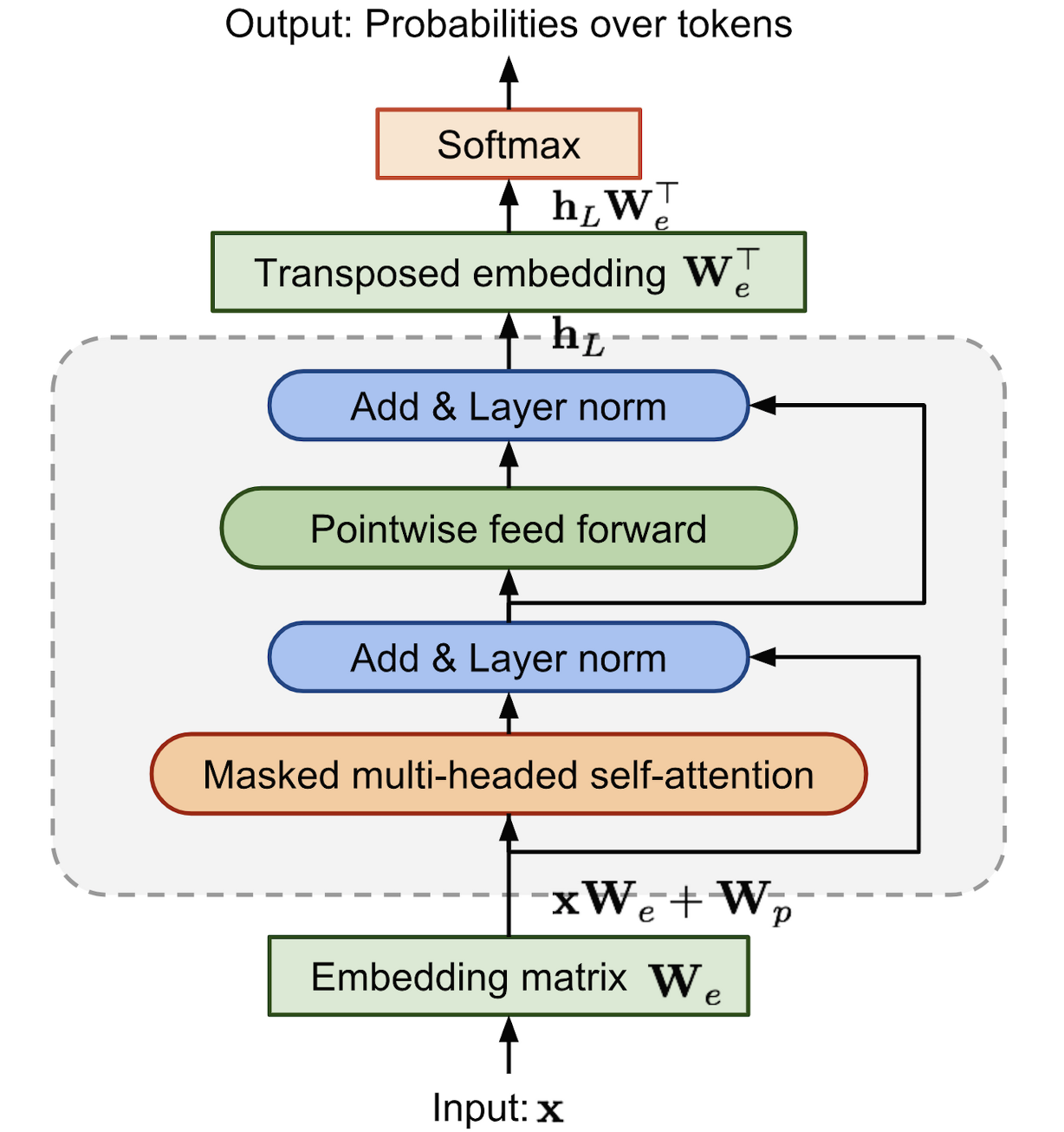
(출처: https://supkoon.tistory.com/25)
- input context tokens에 대해 multi-headed self-attention operation이 적용되며, position-wise feedforward layers가 output distribution을 생산하기 위해 이어짐.
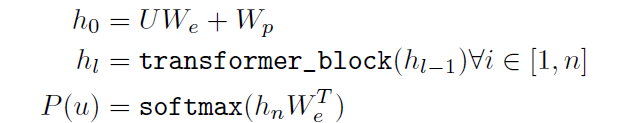
- U는 context vector of tokens를, We는 token embedding matrix를, Wp는 position embedding matrix를 나타냄. transformer_block의 n은 레이어 개수를 의미함.
4-3. Supervised fine-tuning
- language model을 학습한 후에는, supervised target task를 적용함.
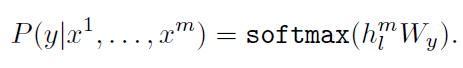
- labeled dataset C가 있다고 가정할 때, 이에 대한 각각의 instance는 input tokens의 sequence로 이루어져 있음. (x1, x2, ..., xm) 그리고 이에 대응되는 (각각의 instance에 대응되는) label y가 존재함.
- 이러한 input들은 pre-trained model를 통과하며, 이로부터 transformer block의 마지막 레이어의 값(hidden state)를 얻음.
- 그리고 이건 fine-tuning을 위해 task에 맞게 추가된 linear output layer의 입력으로 추가 parameter Wy와 함께 들어감.
- softmax 함수를 통해 y를 예측함.
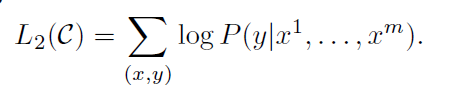
- 이를 위한 목적 함수 (objective function)는 다음과 같이 표현됨.(주어진 x에 대해 y가 출력될 확률을 최대화)
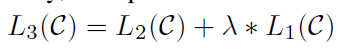
- 앞서 설명한 두 Objective Function을 합치면, 최종 모델의 Objective Function이 완성됨.
- 특이하게, 여기서는 language modeling에 auxiliary objective를 추가하였음. 이는 부가적인 파라미터로 Fine-tuning을 돕기 위함임.
- 기존 연구들에서 이것을 추가하는 게 supervised model의 generalization과 convergence를 가속화(accelerating)한다는 것이 입증되었으므로 추가하는 것은 합당.
- 결과적으로 추가된 extra parameters는 오직 fine-tuning때 사용하는 Wy와 delimeter tokens를 위한 embeddings임. 기존의 방식들과는 달리, pre-training 이후, fine-tuning 단계에서 복잡한 절차 없이, 적은 파라미터만 가지고도 이렇게 downstream task를 수행할 수 있도록 구성한 것!
4-4. Task-specific input transformations
- 어떤 NLP Task를 목표로 하느냐에 따라 input형태는 제각기임.
- Text Clssification 같은 경우는, 위에서 말한 구조대로 수행하면 됨.
- 그런데, Question Answeirng 같은 테스크를 위해서는, structured inputs을 만들어야 함. (질문, 답변, 뽑아낼 document 등)
- 이렇게 제각기 다른 Task의 input들을 큰 수정없이 처리할 수 있게 하기 위해, task-specific input adaptation을 사용했음.
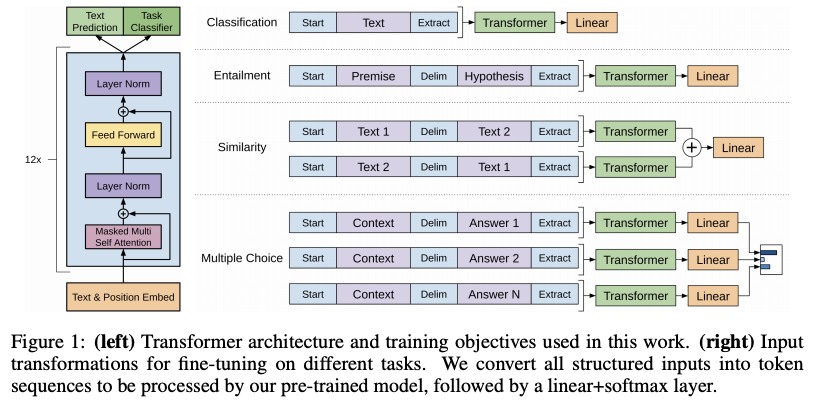
- 이 방식은 Structured text input을 Single contigous sequence of token으로 받는 방식임.
- 문장의 시작과 끝은 < s >, < e > 로 분리하며, 여러 개의 sentence가 입력으로 들어오는 경우에는 Delimiter를 넣어주어, 문장이 서로 다르다는 것을 명시해줌.
5. Experiments
5-1. Setup
Unsupervised pre-training
- 우리는 BooksCorpus dataset을 language model 훈련할 때 사용함. 이것은 7000개의 유니크한 unpublished books으로 이루어져 있으며, 어드벤처, 판타지, 로맨스 등의 다양한 장르를 포함함.
- 이 데이터는 long stretches of contiguous text를 포함하기 때문에, generative model이 long ragne information의 조건을 학습할 수 있음.
Model Specifications
- 12-layer decoder-only transformer with masked self-attention head (768 dimensional states and 12 attention heads)
- position-wise feed-forward netwosk를 위해, 3072 dimensional inner states를 사용하였음.
- Optimizer : Adam
- Max learning rate : 2.5e-4
- Epoch은 100
- Batch Size : 64
- Tokenizing : BPE기반, 40000개의 단어로 구성.
- Activation function : Gaussian Error Linear Unit (GELU)
- Fine-tuning에서, 모델은 빠르게 수렴하며 3epoch이면 대부분의 케이스에서 충분했다고 함.
5-2. Supervised fine-tuning
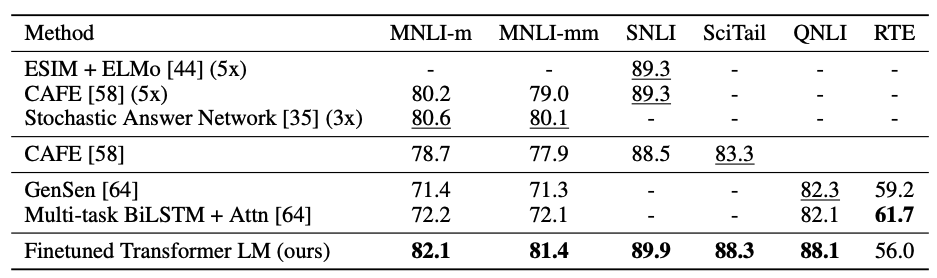
- 다양한 네 가지 supervised task에서 실험을 수행하였음.
- Natural language Inference
- Question Answering
- Semantic Similarity
- Text classification
Nautral Language Inference
- 한 pair의 문장을 읽고 수반, 모순 또는 중립 중 하나를 판단하는 테스크.
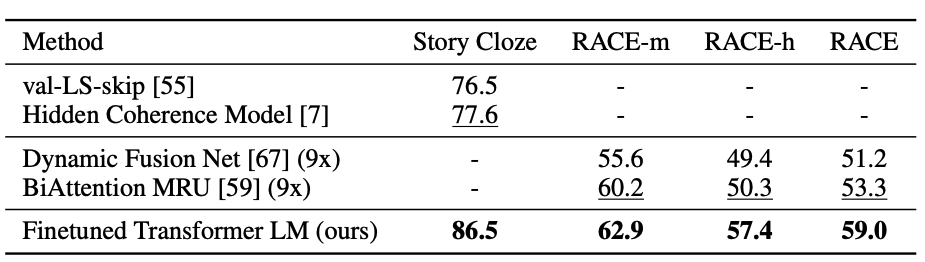
Question Answering and Commonsense reasoning
- 중, 고등학교 시험 질문과 영어 지문으로 구성.
Semantic Similarity
- 이는 두 문장이 의미적으로 동일한지 여부를 예측하는 것을 목표로 함.
- 개념의 재표현을 인식하고, 부정을 이해하고, 구문적 모호성을 처리하는 게 핵심.
Text Classification
- 우리가 아는 그것!
마무리!
6. Take-home Messages!
Key Points of GPT-1
- 다음 Two Stage로 이루어져 있는 Semi-supervised Approach 제안
- Pre-traied with large corpus of unlabeled text (unsupervised) - language modeling
- Fine-tuning for downstream task with (supervised)
- Pre-traning Unsupervised Learning의 경우 Trainsformer의 Decoder를 사용한 Language Model을 활용
- 해당 구조로, 다양한 NLP Task에 범용적으로 적용 가능한 Representation을 효율적으로 만들어 Fine-tuning할 수 있었음.
- Input Transformation 방식은 다양한 NLP Task의 입력을 받을 수 있도록 구성하여, 큰 수정없이도 적용 가능하다는 장점 있음.

SKKU DSAIL 석박통합과정 n학기 / 정신건강과 인공지능의 융합을 연구합니다.