[Review] Storytelling from an Image Stream Using Scene Graphs (AAAI, 2020)
0. Summary
- Task: Visual Storytelling
- Image Sequence를 Encoding할 때 Graph 활용 (Graph Scene)
- Graph를 바탕으로 이미지 내(within image), 이미지 간(cross-image) 관계를 모델링 (GCN, TCN)
- Attention을 활용한 Hierarchical Story Decoder를 통해 각 이미지에 대한 Story 생성
[keyword] Graph Scene, GCN, TCN!
1. Introduction
Visual Storytelling
- Visual Storytelling은 sequence of images를 이해하고, coherent story를 생성해야 한다는 점에서 어려움.
Previous Works
- Visual Storytelling을 다루는 기존의 연구들은 encoder-decoder structure를 사용함.
- 이러한 구조에서 CNN 기반의 모델은 visual feature를 추출하며, RNN 기반의 모델은 text를 생성함.
저자들은 이렇게 CNN 모델에서 추출되는 feature를 high-level feature라고 말함.
- 이미지의 모든 정보를 이렇게 high-level feature로 표현하는 것은 직관적이지 않으며, 모델의 interpretability와 reasoning 능력을 떨어트림.**
Human Process
- 그렇다면 실제 사람이 스토리를 생성하는 과정을 생각해봅시다!


- 먼저, 우리는 각각의 이미지 내에 있는 Object를 인식할거고 (아이와 문과 열쇠구멍이 있네!)
- 그것들의 Relationship을 추론할거고 (아이가 열쇠구멍을 보고 있어! / 아이가 문을 등지고 서 있어!)
- 그리고 이를 토대로 각각의 장면에 대한 내용을 추론할 것. (아하 아이는 방 안을 훔쳐보다가, 자리에서 떠나고 있구나~)
SGVST (Scene Graph Visual Story Telling)
- 이러한 휴먼의 프로세스에 motivation을 얻어, SGVST 모델 구축했음!
- 모델은 다음 프로세스와 같이 동작함. (like human process)
1. 각각의 이미지를 Scene Graph로 변환. (object, relation)
2. 그래프를 통해 이미지 내(object)와 이미지 간의 관계를 모델링.
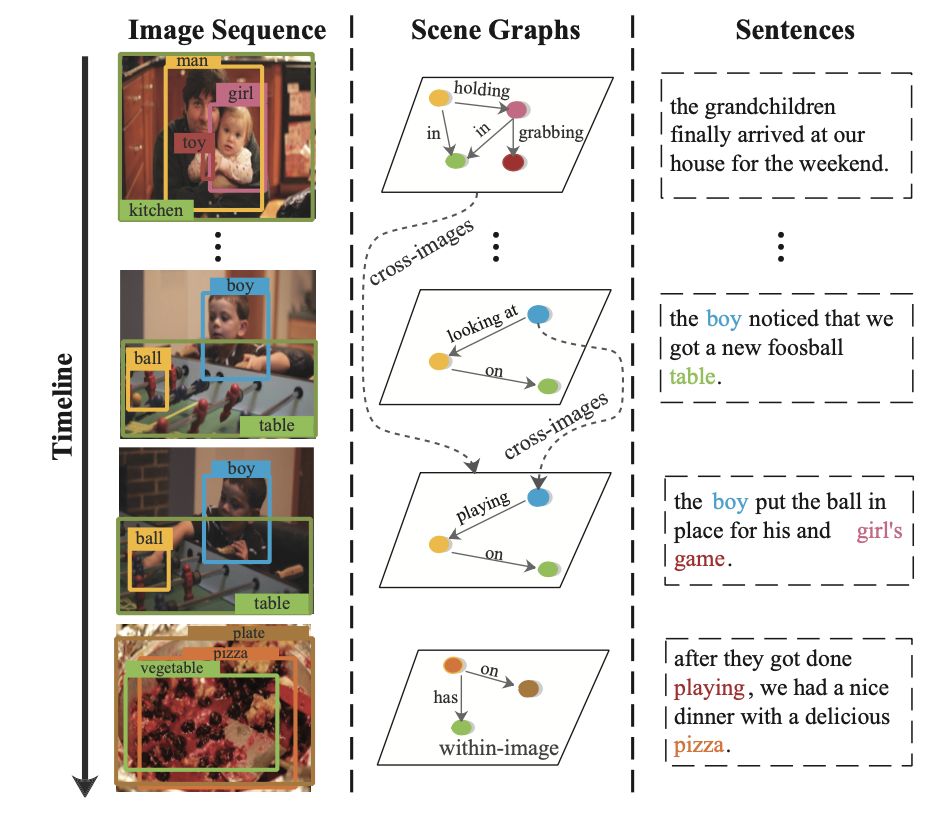
- 저자들은 이렇게 이미지 내, 이미지 간의 관계를 모델링하여 image를 represent하는 것이 visual storytelling에 도움을 줄 것이라고 주장함.
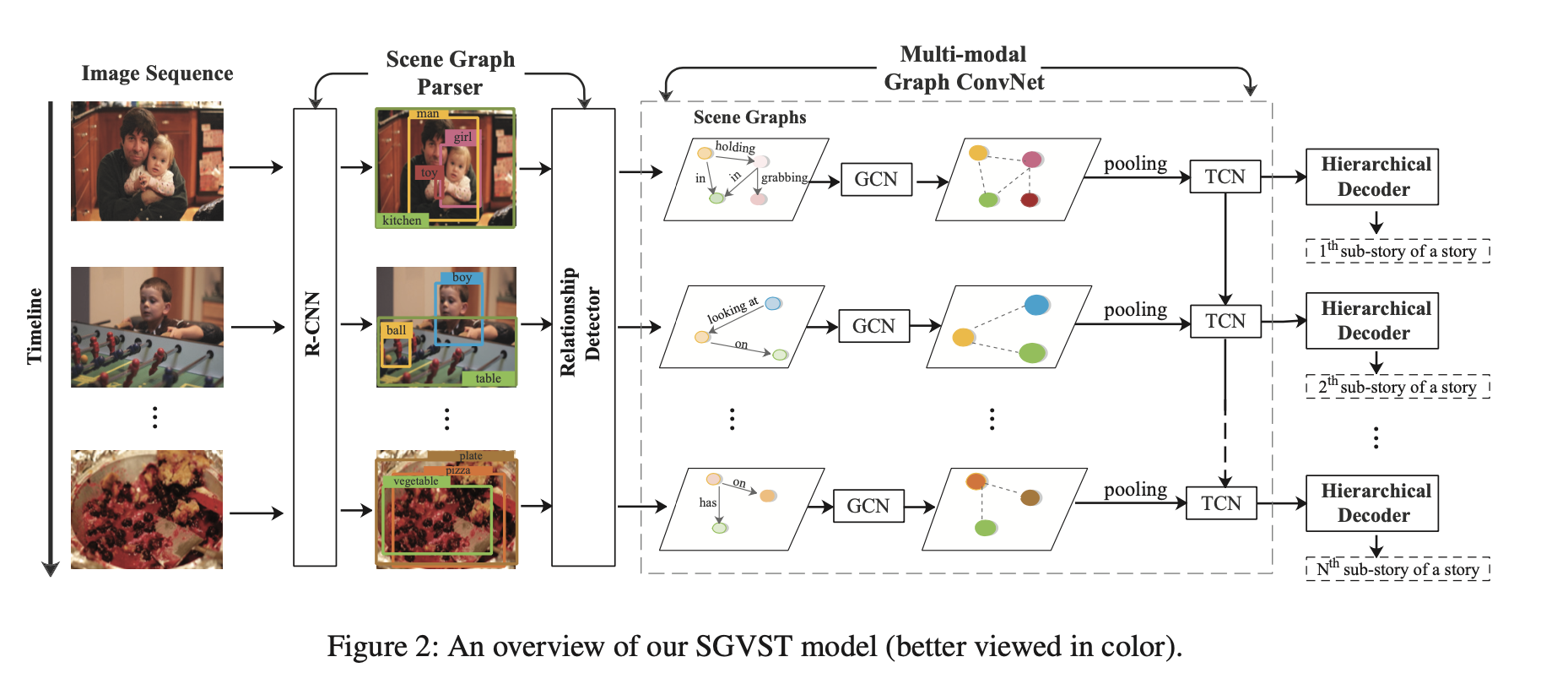
2. Method: SGVST
Model Architecture
Notation
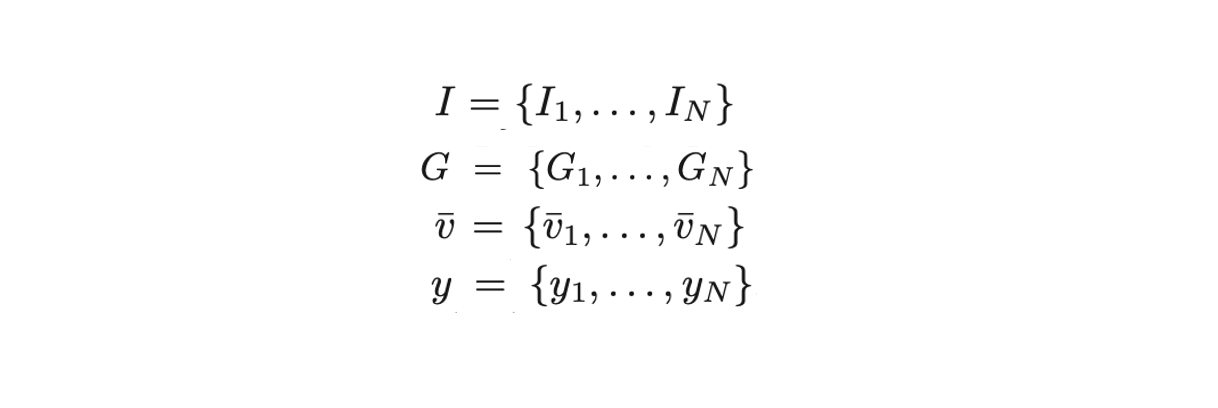
- : image stream
- : scene graphs
- : relation-aware representations
- : output a story
2-1. Scene Graph Parser
- Scene graph aprser은 Image를 scene graph로 파싱해줌.
- Visual Relationship Detection 연구에서 이거 많이 사용함.
- Graph 구성
1. Node : Object- Node Feature : Object의 Region Reprentation
- Edge : 두 Object 간의 Relation (방향 그래프)
- Edge Feature : Relation Label의 Representation
Object Detector
- Faste-RCNN 사용해서 각 이미지로부터 object를 인식, 이에 대한 set of region representation 반환.
Relationship Detector
- 두 Object들이 어떤 관계를 가지고 있는지 예측.
- 기존 연구의 모델 사용 (LSTM-based model).
- 두 Object 넣으면, 가장 높은 확률을 가지는 Relation Label 예측.
Representation (Node, Edge)
- 각각의 Object 노드와 Edge는 Embedding Layer를 거쳐, D차원의 Dense Vector로 임베딩됨. (노드, 엣지 둘 다 동일한 D차원)
2-2. Multi-modal Graph ConvNet
Graph Convolution Network
- 이미지 내 관계 모델링: 이미지 내 object간의 관계가 잘 학습되도록 Object Node Embedding 업데이트!
- 만약 (, , ), (, , ) 이러한 오브젝트가 이미지에 포함되어 있다고 가정.
- 세 가지 타입의 연산을 통해 object embedding과 edge embedding 업데이트 됨.
> function
, , ) 벡터를 concatenate한 후, MLP Layer에 넣어, Output Vector 출력 (, , 에 대해 세 개 나옴)
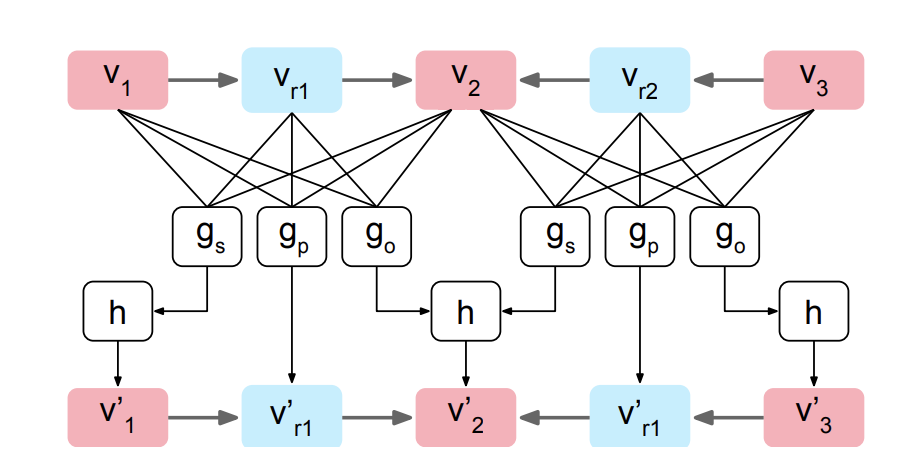
[reference] "Image generation from scene graphs." Proceedings of the IEEE conference on computer vision and pattern recognition. (2018)
-
Relation Vector 의 경우, 연산을 통해 바로 업데이트.
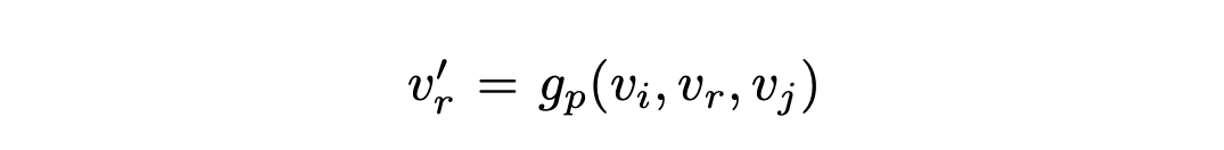
-
를 업데이트 하기 위해서는, 가 출발노드인 관점에서의 이웃노드들과, 가 도착노드인 관점에서의 이웃노드 모두를 고려하여야 함.
-
V는 각 상황에서의 Candidate Vector의 집합을 나타냄.
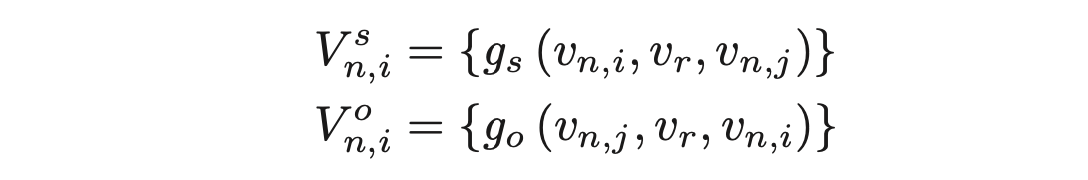
-
의 경우 와 의 결과를 합한 후, average pooling (h) 을 적용함으로써 new object vector 생성.
이러한 연산을 모두 지난 후에, object node는 이미지 내의 잠재된 visual information을 모두 통합된 상태가 됨!
Temporal Convolution Network
- 이제 이미지 간 (cross-image) temporal relationship 정보를 통합할 차례~!
- 먼저, 이미지의 대표 representation을 만들어주기 위해, 앞서 구한 object node들을 각 image 별로 pooling해줌.
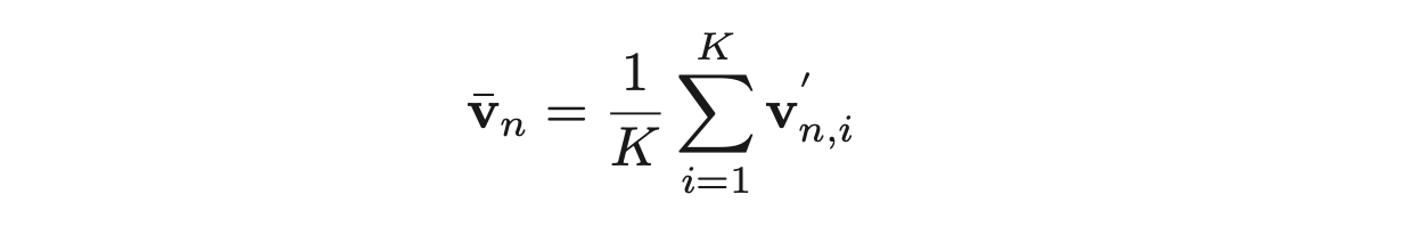
- TCN 사용, 얘는 시간 순서에 따라 변하는 region representation을 처리하기 위한 모델임.
- TCN에서는 dilated casual convolutions 연산 적용. 이는 large receptive field를 갖는 데 유리하며, 미래의 정보가 과거에 영향을 주지 않음. (Casual)
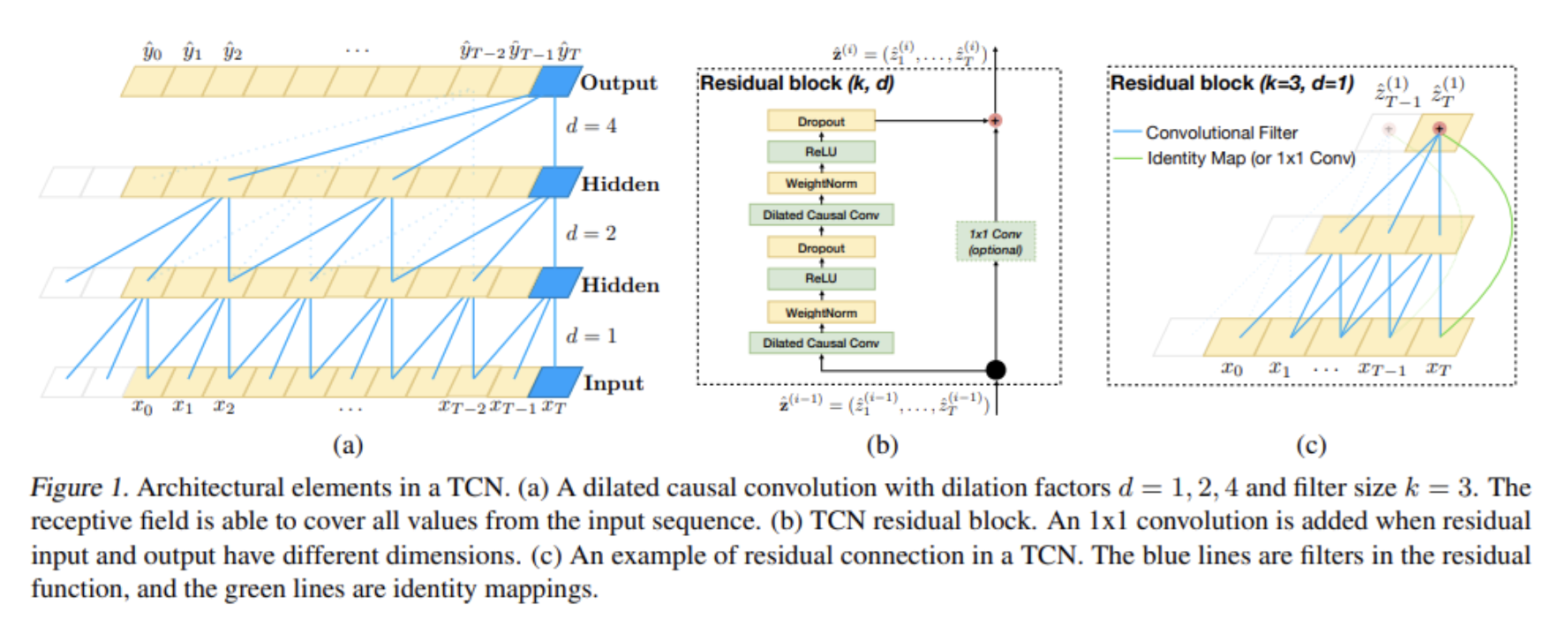
- 맨 왼쪽 그림을 수식으로 나타내면 다음과 같음. (여기서의 sequence는 story image sequence임.)
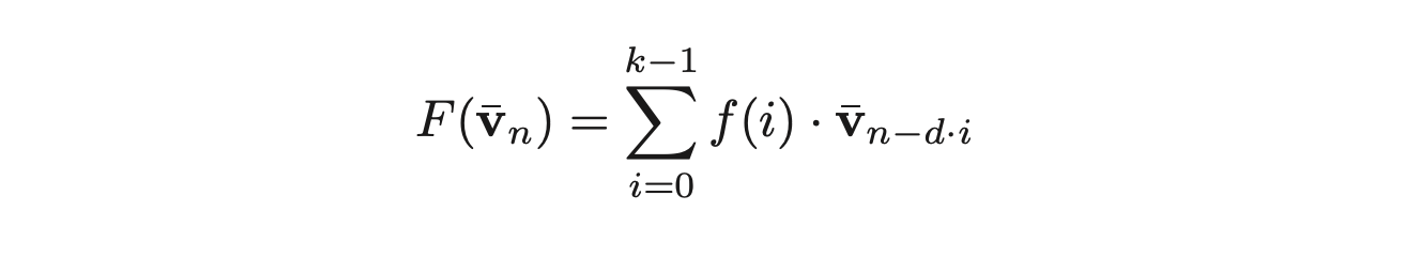
- 는 fully-convolutional network (FCN)를 의미, 는 filter size를 의미. 는 dilation factor를 의미. (몇 개 건너 볼건지)
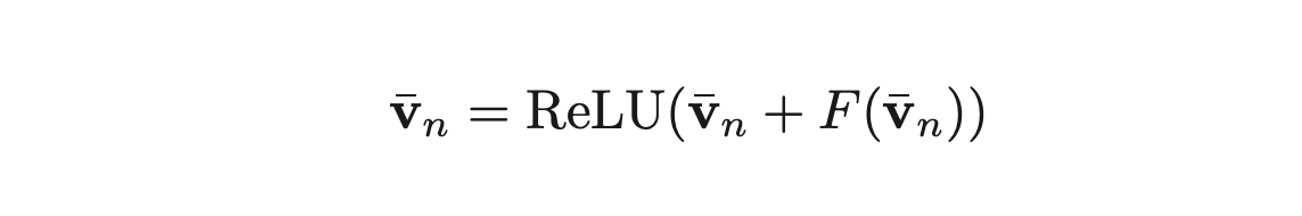
- 두 번째 그림처럼 마지막에 Skip Connection도 해주고, RELU 씌워주면, 이미지 간 relation 정보까지 결합된 Image representation 완성!
High-level Encoder
- 앞의 과정을 통해 relation-ware 정보를 잘 뽑아냈지만, 이 과정에서 image inforamtion이 소실될 수 있음. 그래서 high-level feature도 같이 넣어주려고 함.
- Faster R-CNN에서 뽑은 region representation을 BI-GRU에 넣어서 잘 만든 후에, 이를 relation-aware와 세 단계에 걸쳐 결합함으로써, 최종적인 new relation-aware image representation 완성.
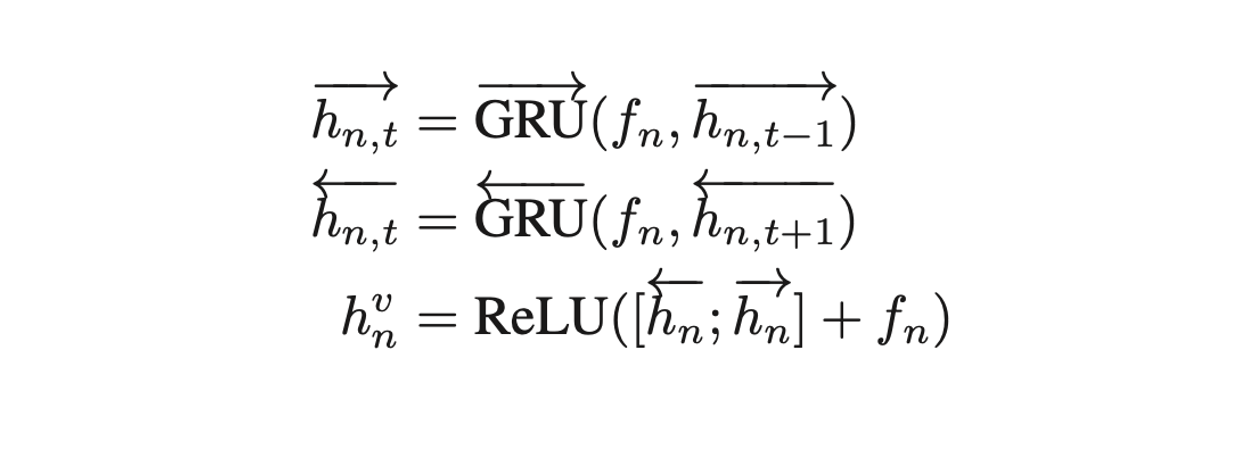
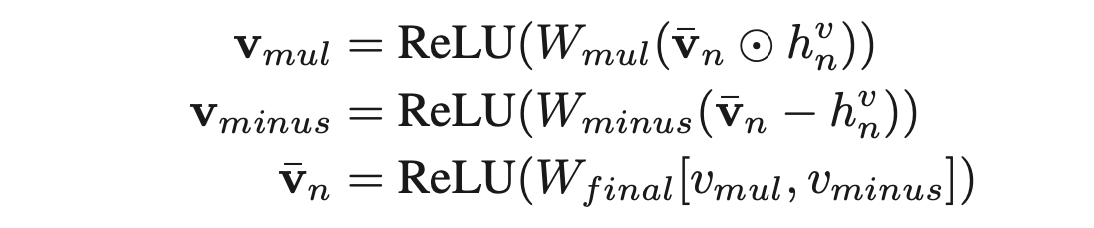
2-3. Hierarchical Story Decoder
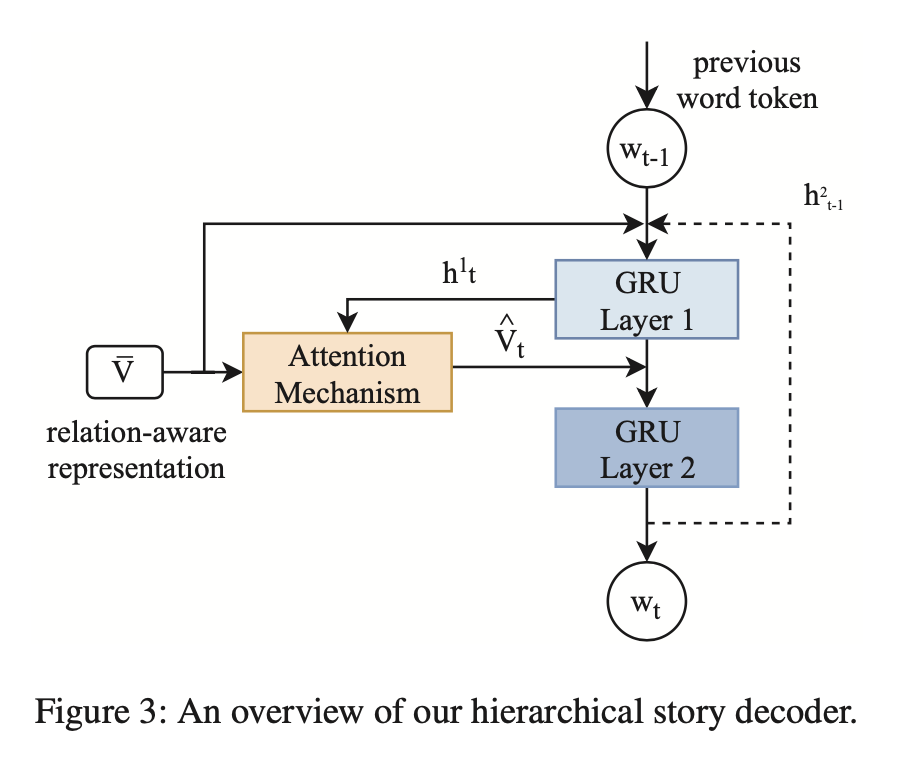
- 완성된 sequence 내 각 image의 realtion-aware representation을 가지고 story를 생성할 차례!
- 두 개의 GRU Layer와 Attention 메커니즘 사용.
- GRU Layer 1 : 입력으로 이전 단계의 word token과 target image representation, 이전 단계의 두 번째 GRU Layer의 hidden state를 받아, 생성
- Attention Layer : 를 Query, 를 Key와 Value로 Attention 적용. 이로써 현재 출력을 할 때, image representation에 어디에 attention 해야할 지 알 수 있음.
- GRU Layer 2 : 와 , 을 바탕으로, hidden state 생성
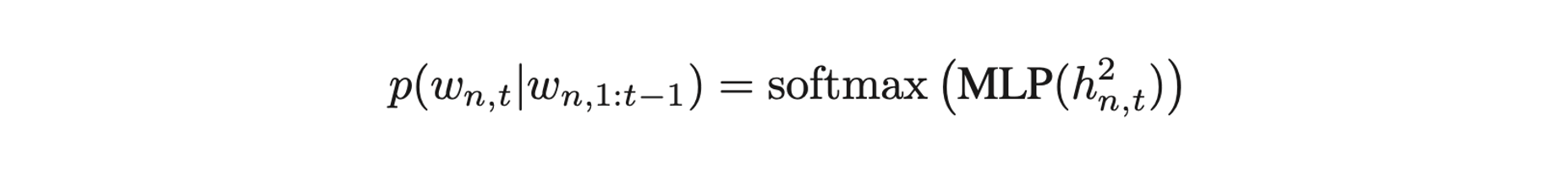
- MLP, softmax를 지나 다음 word 출력! (이후 반복 ,, 또 반복,, 모든 워드와,, 이미지에 대해..)
3. Experiment
Dataset
- VIST : Flicker albums 기반. 각각의 샘플(album)은 다섯 개의 이미지와 다섯 개의 스토리 문장으로 구성됨.
Baseline
- HPSR : encoder, decoder, reconstructor
- AREL : CNN-RNN architecture & reinforcement learning
- HSRL : hierarchically structured reinforcement learning
- SGVST variants : 각 파츠들 중요성 검증 위해, 몇 개 부품 뺀 버젼
Metric
- BLUE
- ROUGE-L
- METEOR
- CIDEr-D
(BLUE, ROUGE, METEOR : 예측한 응답과 실제 정답(ground-truth)을 구성하는 단어들의 word-overlap 정도)
3-1. Quantitative Results
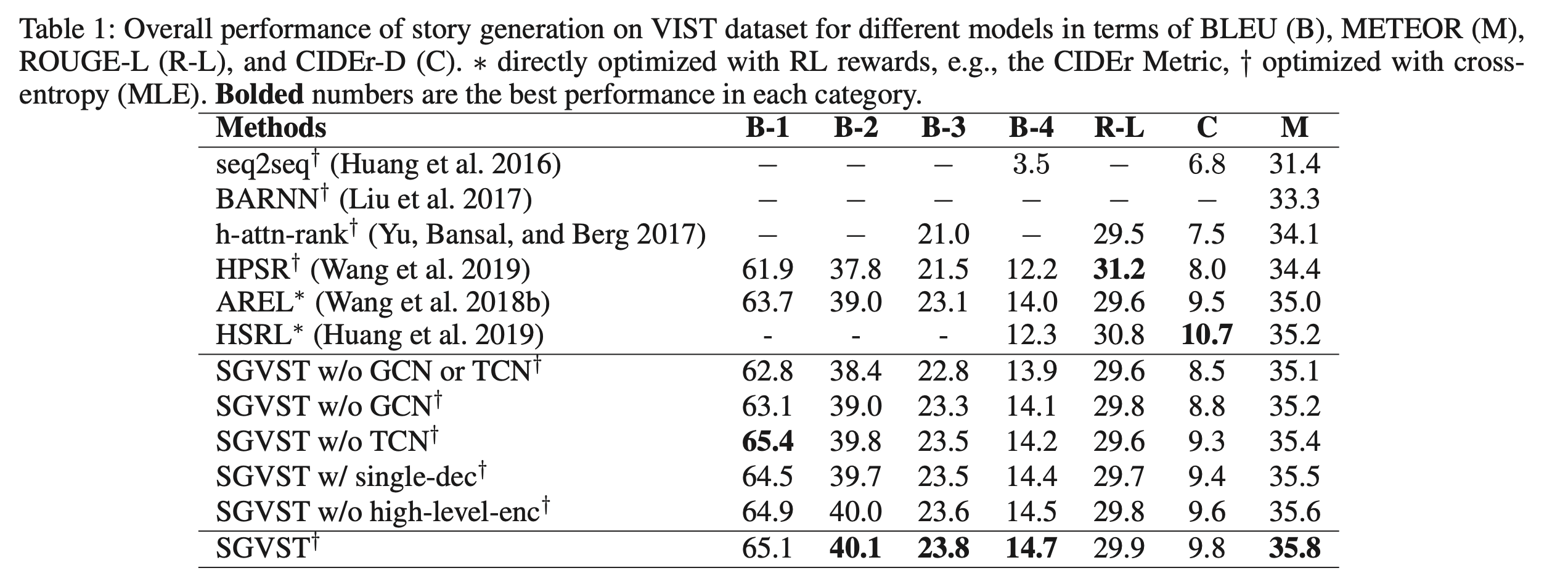
- SGVST 모델이 MLE 및 RL로 최적화된 다른 sota 모델보다 우수함.
- 이는 그래프 기반 모델이 스토리 생성에 도움이 될 수 있음을 증명!
- 다양한 SGVST variants들을 통해 각 파츠가 도움이 된다는 것을 알 수 있음.
- 이때, high-level enc를 without한 경우는 최종 형태의 SGVST와 거의 유사한 성능을 보이는데 이는 그래프 기반의 representation이 high-level feature를 학습할 수 있는 능력을 가지고 있음을 보여줌.
성능 디펜스
- CIDEr-D : 인간 평가와 상관성이 떨어진다는 연구 결과 있음. 근데 우리 일단 넣었음. 라고 말함.
- ROUGE-L : 우리 모델 점수가 다 거의 같음. 이는 ROUGE가 이 task를 평가하는 데 적합하지 않음을 시사함.
- B-1 : 언급 없음.
3-2. Qualitative Results
Qualitative Examples
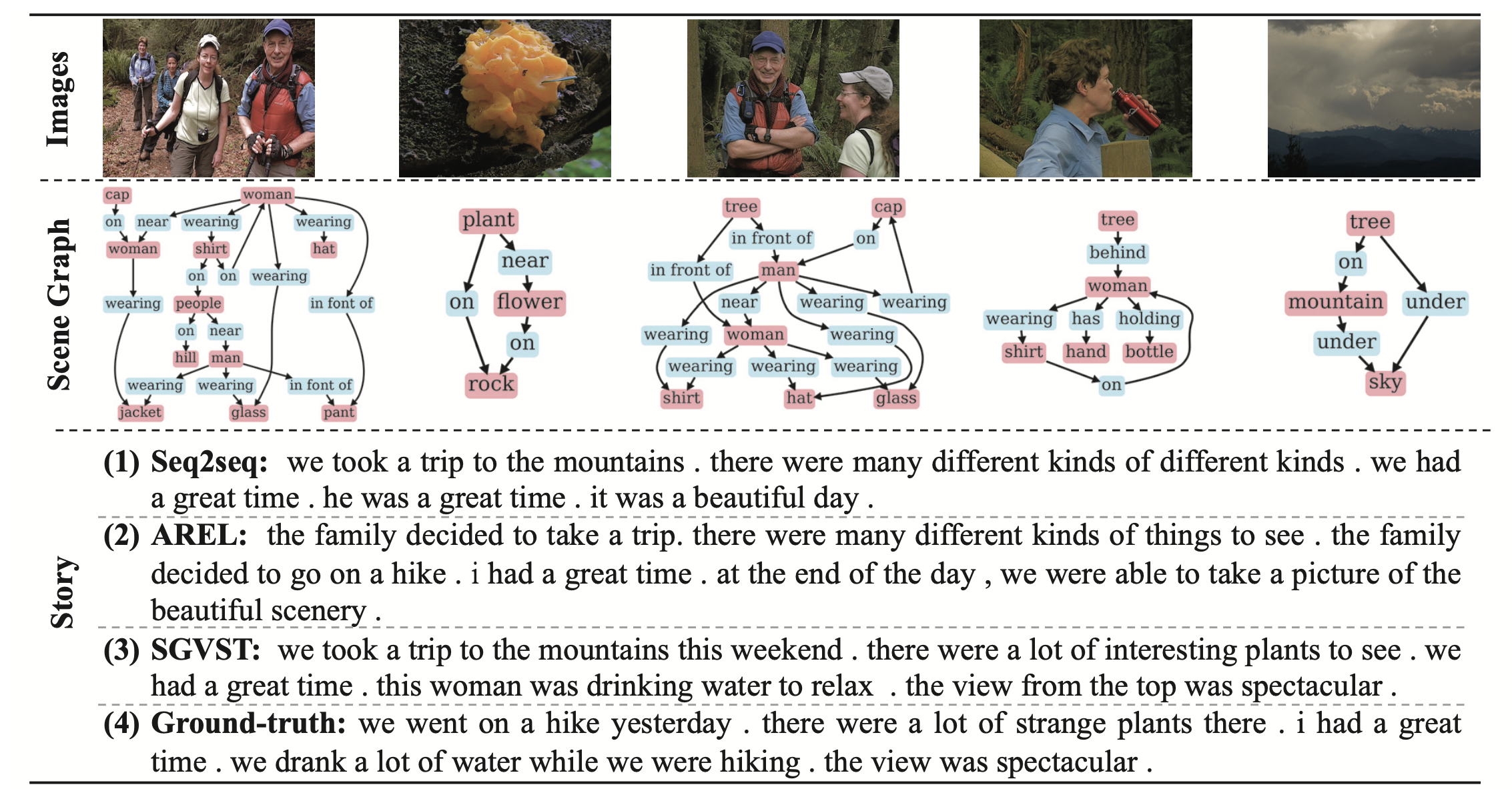
- seq2seq: different kinds of different kinds... 말을 절음.
- AREL : family라고 이야기하다가 갑자기 I로 바뀜. (이미지 간 결합도 떨어짐)
- SGVST : 근데 얘도 갑자기 we..하다가 this woman하는데.. (그래도 물 마신다는 표현이 좀 더 정확하긴하다)
Human Evaluation
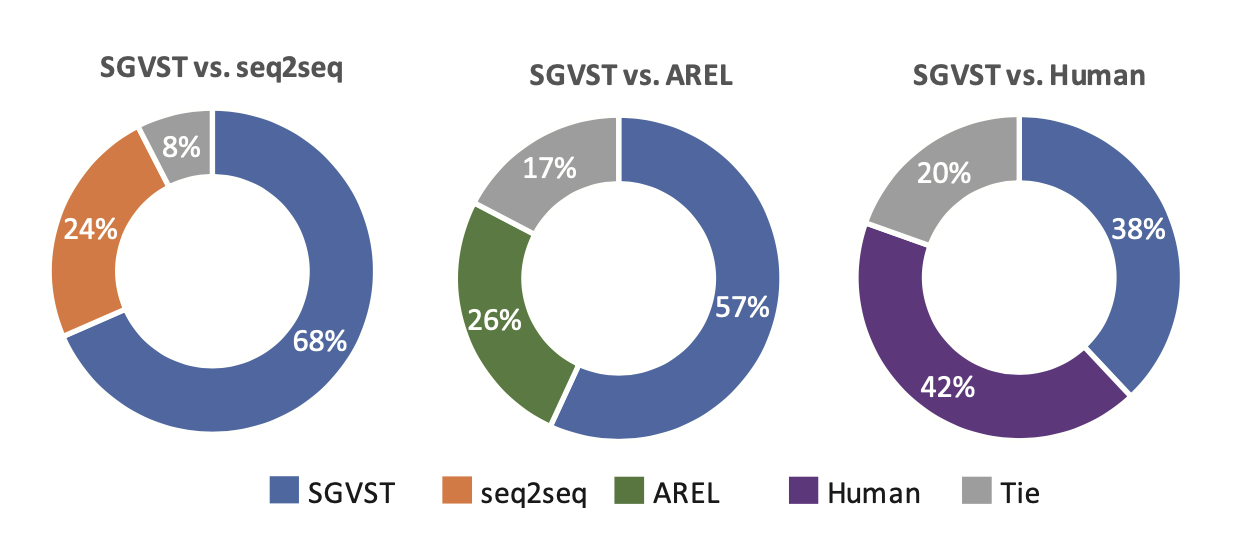
- 두 결과 중 괜찮은거 양자택일 하세요!
- 두 모델보다 월등히 높은 평가, 인간의 스토리 (Ground Truth)에 필적하는 평가

- 세부 항목에 대한 Rating에서도 매우 좋은 평가를 받음!
4. Take-home Message
- 이 논문에서는 보다 발전된 Visual Storytelling 테스크를 수행하고자 함.
- 그 중에서도, image를 represent하는 방식에 개선점을 둠.
- 기존 CNN 모델을 통해 High-level feature를 뽑았던 이전 연구들과는 달리, 이 논문에서는 실제 인간이 스토리를 인지하는 프로세스를 기반으로, 이미지를 Graph Scene으로 표현.
- 실험 결과, Graph를 기반으로 한 인코딩 방식이 Visual Story 생성에 효과적이라는 것을 알 수 있었다!
5. 개인적인 평가
- 사실 모델의 각 파츠들은 다 이미 있던 것에서 가져온 것들임. 근데 이미 있는 것들이더라도, 해당 Task를 수행하기 위해 설득력 있게 조합한 것이 의미있는 듯! Graph Scene, GCN, TCN 조합으로 representation 만든건 상당히 좋은 아이디어인 듯.
- 분량이 부족했는지 실험 결과에 대한 해석이 부족한 부분이 상당히 아쉬움. 자기네 잘 나온 부분만 강조하고, 그 외에 결과에 대한 타당한 해석은 단 하나도 없음. 분량도 적음.
- 분량 조절의 실패가 보이고.. 급하게 쓴 티가 가끔 남..

SKKU DSAIL 석박통합과정 n학기 / 정신건강과 인공지능의 융합을 연구합니다.