[Review] Unlimiformer: Long-Range Transformers with Unlimited Length Input (NeurIPS, 2023)
Abstract
- Transformer는 모든 토큰에 대해 Self-attention을 수행 > input length의 길이에 제한을 받아왔음.
- 이를 해결하기 위해 이 논문은 Unlimiformer를 제안함.
- 기존의 Pre-trained Encoder-decoder Transformer를 Wrap
- Cross-attention 계산을 단일 k-nearest-neighbor (KNN) Index로 대체
(이때 k-NN distances로 attention dot-product scores 사용)
- 이 k-NN index는 GPU나 CPU의 메모리에 저장될 수 있을뿐만 아니라, Sub-linear time에 query될 수 있음
- 제안하는 접근법의 장점
- 이런 방식은 거의 제한없이 Input sequence를 인덱싱할 수 있게 함.
- 또한 각각의 Decoder layer는 모든 Key에 Attention하는 대신 Top-k keys을 골라 사용할 수 있게 됨.
- 몇 가지 Long-document그리고 Book-summarization benchmark에 대해 실험, 500k개의 긴 토큰을 입력으로 받은 경우에도 Test time에서 어떤 Input의 Truncation없이 Test time에서 이것이 잘 동작한다는 것을 발견했음.
- 추가적인 학습 가중치나 코드 수정 없이 BART나 Longformer와 같은 사전 훈련 모델을 unlimited input으로 확장시킬 수 있음.
1. Introduction
Limited input length of Transformer
- Transformer는 일반적으로 512 (BERT, T5) 또는 1024 (BART)의 Context Window를 보유
- 이것을 확장시키기 위한 Long-context 모델들에 대한 연구가 진행되었음.
- 이들은 Sparsify or Approxmiate attention을 사용하여 Computational Cost는 유지하면서 토큰을 4배 늘렸음.
ex) Longformer (2020), Performers (2020) - 이러한 모델의 실험은 대부분 Long-document summarization, Question-answering dataset에 대해 수행됨.
- 이들은 Sparsify or Approxmiate attention을 사용하여 Computational Cost는 유지하면서 토큰을 4배 늘렸음.
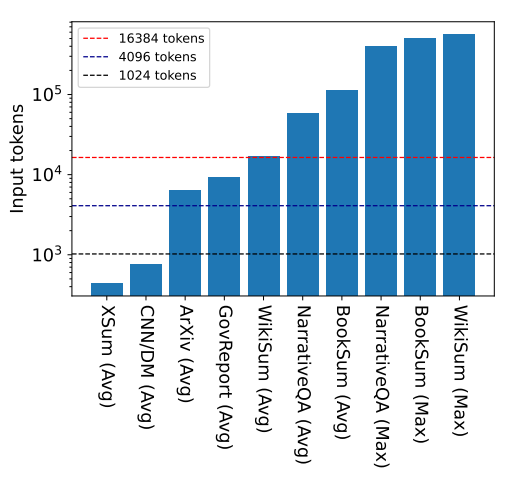
- 여러 벤치마크 데이터셋의 평균 또는 최대 Input length, 기존의 Long-context를 갖는 모델들로 충분하지 않은 경우가 많음.
- 그러나, 아직 500k 이상의 토큰을 갖는 Long narratives (e.g., Book summarization) 테스크에 대한 실험은 진행되지 않았음.
- Figure 1은 몇 가지 유명한 Summarization, Question-answering 데이터에 대한 input lengths들을 나타냄.
Limitations of previous works
- 이러한 Extremely-long-input 케이스를 다루기 위해 Long-input transformer는 주로 Base Architecture를 수정함.
- 그러나 이는 모델을 처음부터 Re-pre-training하는 과정을 필요로 함 (Computationally costly)
- Longformer-Encoder-Decoder (LED, 2020)과 같은 다른 모델들은 Pre-trained models를 활용하기도 하지만, 여전히 새로운 Positional Embedding또는 Global Attnetion Weight의 학습을 요구함. (Computationally costly)
Unlimiformer - Unbounded Input length!
- 우리는 Test time에서 Unbounded length를 입력으로 받을 수 있도록 Pre-trained Language model을 증강한 Retrieval-based approach인 Unlimiformer를 제안함.
- Long input sequence가 주어졌을 때, Unlimiformer는 k-nearest-neighbor (kNN) 인덱스를 모든 input tokens들의 hidden states에 대해 구성함.
- 그 다음, 모든 decoder layer 내의 standard cross-attention head는 k-NN 인덱스를 query함.
- 이때, kNN distance가 attention dot-product scores로 사용되며, top-k input tokens에 대해서만 attention함.
- 사전 실험에서, 우리는 top-k attention keys가 전체 attention의 99% 이상의 역할을 할 수 있다는 것을 보았으며, 때문에 오직 top-k keys에만 attention하는 것이 approximation of the full, exact함.
- Unlimiformer는 어떤 encoder-decoder model에도 적용될 수 있으며, index 정보는 GPU나 CPU에 저장될 수 있고, 이때 하나의 인풋 토큰에 대한 single vector만 저장하면 됨.
https://kongsberg.tistory.com/47
Unlimiformer as generic approach
- 이것은 학습된 모델에 적용될 수 있고, 기존의 checkpoint를 추가적인 weight나 training 없이도 향상시킬 수 있음.
(그리고 물론 Unlimiformer를 fine-tuning할 때에, 성능은 더 향상될 수 있음.) - Unlimiformer는 다양한 long-context 데이터세트에서 기존의 모델인 LED(2020), PRIMERA(2022), SLED(2022), Memorizing Transformer(2022)와 같은 강력한 long-range-transformer보다 높은 성능을 보이며, 이러한 모델에 Unlimiformer를 적용하여 성능을 개선할 수 있는 모습을 보여줌.
Point !!!
1. Transformer의 input token의 범위를 unbound로 확장한 모델인 Unlimiformer 제안
2. 이 모델은 Encoder-Decoder 간의 Cross Attention 상황에서 Input token의 Hidden State를 저장해두었다가, 이들간의 kNN distance를 구해 Top-k token에만 attention할 수 있도록 함.
3. 이러한 방식은 하나의 토큰에 대한 single vector만 메모리에 저장하면 되어 기존 모델보보다 엄청난 양의 메모리 절약이 가능함.
4. 또한 모델의 구조를 변경해야 하므로, 재학습이 필요했던 기존 연구와는 달리 Unlimiformer는 사전 학습된 모델을 사용하여 추가적인 학습이나 파라미터 없이도 모델을 개선하는 General한 방식임.
2. Unlimiformer
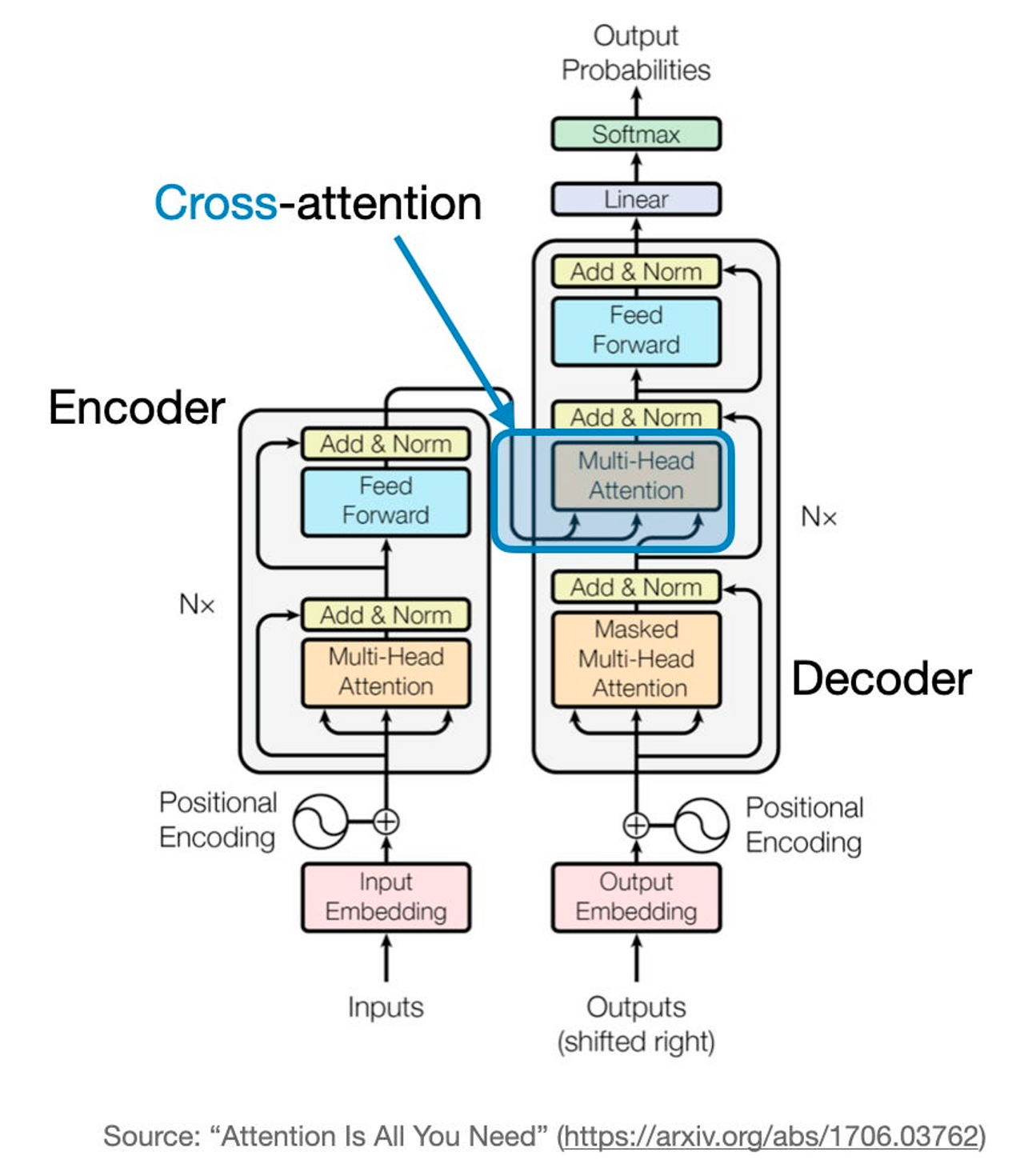
- Pre-trained Encoder-decoder transformer가 주어졌을 때, Unlimiformer는 Decoding step에서 각각의 Cross-attention head가 full-length-input으로부터 attend할 keys들을 선택할 수 있게 함.
- 우리는 kNN을 각각의 Decoder layer에 투입시켜, Cross-attention 진행 전에 모델은 kNN 인덱스에서 nearest-neighbor를 검색함. (per-decoder-layer, per-attention-head-tokens)
2.1 Encoding
- 모델의 Context window보다 긴 길이의 input sequence를 인코딩하기 위해, 우리는 주어진 모델의 encoder를 input의 overlapping chunks를 인코딩하는데 사용함.
Maor Ivgi, Uri Shaham, and Jonathan Berant. 2022. Efficient long-text understanding with short-text models.
- 긴 시퀀스를 처리하기 위한 접근방식 sled 제안. 인풋 토큰을 overlapping chunk로 분할하고, 각각을 인코딩한 다음, 디코더를 통해 chunk간 정보를 융합하는 방식
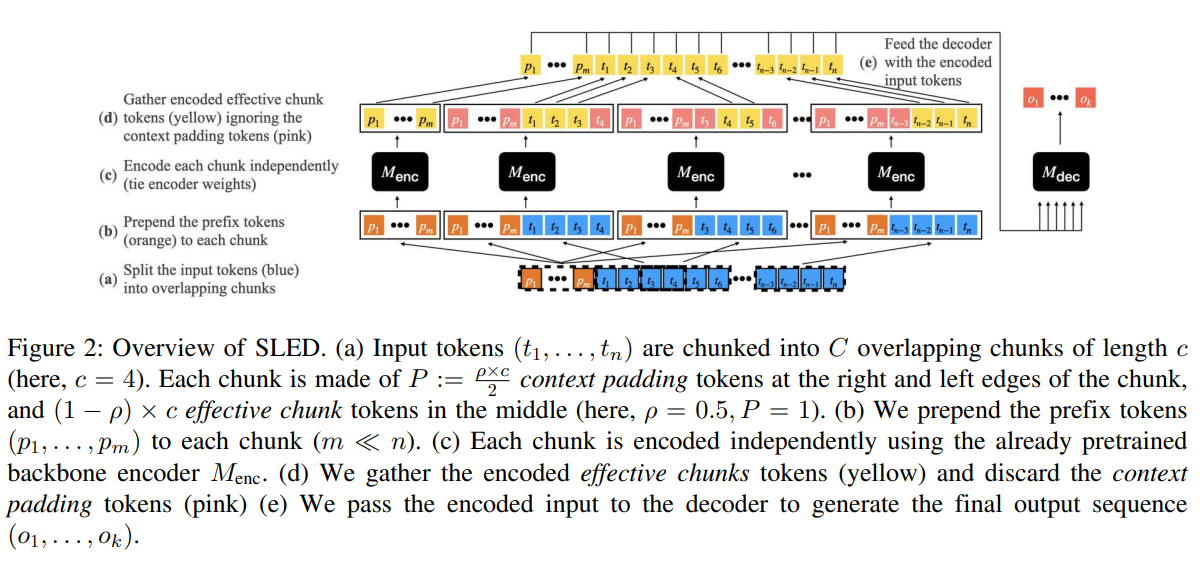
- 우리는 encoded inputs을 k-NN 인덱스로 만듦.
- 이때 index's nearest-neighbor similarity metrics으로 dot-product를 사용
2.2 Retrieval-augmented Cross-Attention
- Standard corss-attention 안에서, transformer decoder는 encoder의 Top-layer hidden states에 attention함.
- 그리고 이때, encoder는 보통 input sequence의 k first tokens만을 인코딩함 (truncation)
- 우리는 이 top의 k-token에만 어텐션 하는것이 아닌 top-k hidden states을 kNN으로부터 각각의 cross-attention head에 대해 반환하고, 이것 (only to these top-k)에 attention을 적용하고자 함.
- 이러한 방식은 truncating하는 것 대신 전체 input sequence로부터 retrieval하는 것을 가능하게 함.
- 우리의 방식은 GPU가 모든 입력 토큰에 attention을 수행하는 것보다 훨씬 cheaper함. 그리고 Softmax는 보통 가장 큰 값에 의해 영향을 많이 받기 때문에 Top-k를 참조하면 전체를 보는 것만큼의 효과를 낼 수 있음.
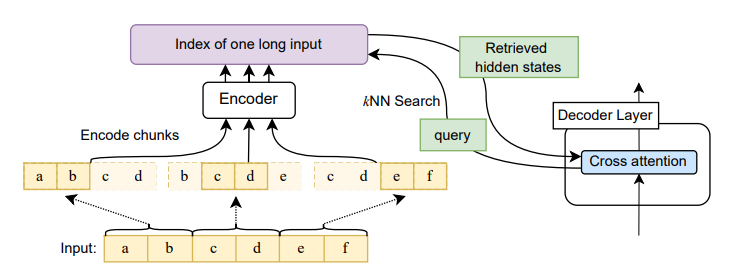
- 위의 아키텍처 그림은 Sequence-to-sequence transformer의 구조에서 변형한 우리의 접근방식을 나타냄.
- Full input이 encoding되고 k-NN 인덱스화됨. 그 다음 인코딩된 hidden state의 index는 각각의 decoding step에서 query됨.
- kNN search step은 non-parametric하며 어떤 pre-trained seq2seq transformer에도 적용될 수 있음.
2.3 Attentiion Reformulation
Standard cross-attention computation for a single head in transformer
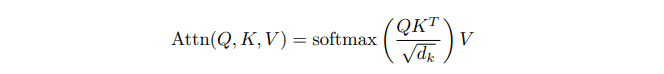
- : decoder hidden state
- : encoder's last layer hidden state
- : Dot-product of the decoder states and Query weight matrix
- : Dot-product of the last hidden states with the Key wieght matrix
- : Dot-product of the last hidden states with the Value weight matrix
- 우리의 목표는 를 최대화할 수 있는 set of keys인 를 반환하는 것임.
- 이때 는 model's context window 사이즈로 고정, 반환받은 최적의 조합을 통해 standard attention 진행하는 것.
- , , 는 layer-specific, head-specific하기 때문에 , 이 과정은 각 레이어와 각 헤드에 따라 다 다른 값을 반환하게 됨.
총 개의 인덱스
(L은 디코더 레이어 개수, H는 어텐션 헤드 개수) - 사실, 이러한 접근법은 Memorizing Transformer에서 소개된 적 있음 (k-NN index를 encoded inputs전에 사용하는 방식)
- 그런데 이제 모든 decoder layer와 모든 attention head에 대해 이 방법을 수행하는 게 time-intensive하기 때문에 이 선행 연구에서는 single decoder layer에만 그들의 memory layer를 적용했음.
그러니까 접근법은 똑같은데 상세사항은 다르다고 주장하는 것.
-
아래는 표준의 트랜스포머 어텐션 공식을 다른 순서로 계산하는 것을 나타냄. 우리는 이것을 통해 어떠한 수학적인 정의의 변경 없이도 모둔 attention heads와 모든 decoder layers의 single index를 저장할 수 있었음.
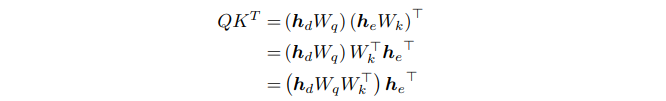
코드를 크게 바꾸지 않아도 된다는 점, 메모리에 미리 저장하는 것이 아닌 dot-product 계산을 그때마다 하면 된다는 점 강조하고 있음.
-
이러한 인덱스 (encoder의 마지막 hidden state of each token)들은 CPU 메모리에서 처리할 수 있으므로 사실상 우리 것 unlimited다! 라는 것
3. Training Unlimiformer
- Unlimiformer는 already trained-model의 test time에서 사용될 수 있음. (어떠한 추가 훈련 없이도)
- 아래 표는 BART (1024 context window)를 사용한 훈련 방식의 비교를 나타냄.
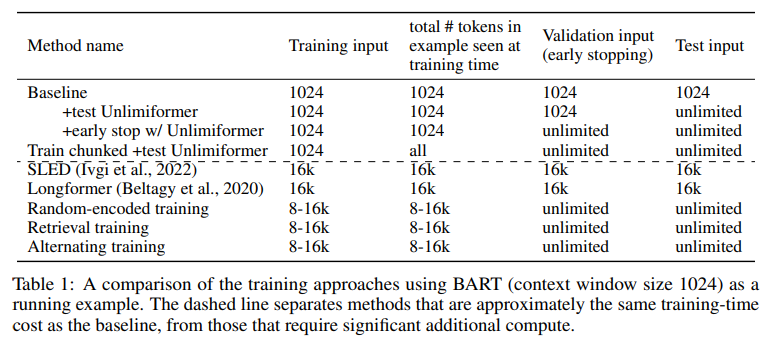
추가적인 훈련 없이 사용하는 기본 셋팅
- Test time에서 입력 시퀀스를 해당 모델이 받을 수 있는 context window로 자르고 처리한 뒤, k-NN index 적용한 decoder에서 아웃풋 생성
3.1 Low (additional-) Cost Training Methods: Applying Unlimiformer at validation or test-time only
- 우리는 첫번째로 다른 standard fine-tuning과 비교했을 때 적은 추가적인 계산을 요구하는 training approach를 고려해봄.
약간의 추가훈련 단계에서 사용하는 케이스들에 대해 소개하는 것.
+test Unlimiformer
- 가장 간단한 케이스로 standard fine-tuninig 방식을 사용 (input은 training 동안 truncated) 테스트 단계에서는 Unlimiformer 적용해서 full-length 처리
+early stop w/ Unlimiformer
- Unlimiformer 없이 훈련하는데 early stopping 적용할 적에 사용되는 validation set에 대해서 Unlimiformer 적용한 사례
Train chunked +test Unlimiformer
- Training example들을 non-overlapping chunks로 자른 후 각각의 chunk를 own training example로 다루어 진행 (data augmentation)
- 그 다음 모델을 normal하게 fine-tuning 진행, 훈련 샘플의 모든 부분을 훈련 중에 사용할 수 있다는 장점이 있음.
3.2 Long-range Training Methods: Applying Unlimiformer at training time
- 우리는 또한 Unlimiformer를 직접적으로 훈련하는 것도 고려함. + 추가적인 computational cost요구
Random-encoded training
- 각각의 training step에서 full training example을 chunk하여 인코딩(기존과 동일), 그 대신 디코더 레이어들이 keys를 선택할 때 encoded hidden states로부터 랜덤하게 선택해서 가져오는 방식 선택
Retrieval Training
- 각각의 훈련 단계에서 each decoder head와 layer를 위한 keys들은 kNN 서치를 통해 선택하고(기존과 동일), input이 16k보다 긴 경우에는 training time에서 inpupt을 16k tokens들로 truncated하는 방식 선택.
Alternating trainnig
- 우리는 Random-encoded traniing and Retrieval training를 번갈아가면서 사용
대체 왜 이런식으로 했는지..?
In this approach we alternate batches of Random-encoded training and Retrieval training. Retrieval training is identical to the test-time setting, while Randomencoded introduces regularization that makes the model attend to non-top-k keys as well.
4. Experimental Setting
4.1 Datsets

-
데이터 통계, 마지막 컬럼은 input example의 길이를 시각화한 것임.
-
2개의 long-document, 한 개의 book-summarization 데이터셋에 대해 진행하였음
GovReport (2021)
- long-document summarization dataset: 미국 정부 보고서의 요약본을 작성
Summscreen (2022)
- long-document summarization dataset: TV show episode의 recap을 작성하는 것
BookSum (2021)
- book-summarization dataset: BOOKSUM-Book setting 사용 - 전체 novel 입력받아서 요약본 작성
- 이를 위한 평가를 위해 Entity Mention Recall ("EntMent") 사용, 이것은 candidate summaries의 informativeness를 평가하는 지표
- candidate summary안에 언급된 gold entities들의 조각들을 평가함.
4.2 Baselines
- BART_base (2020) : pre-trained seq2seq 모델 (139M parameters) 흔히 요약에 많이 사용됨, max token length는 1024
- PRIMERA (2022): Longformer-Encoder-Decoder () 모델. 447M parameters, multi-domain summarization에 대해 사전훈련, maximum input length는 4096임
- SLED (2022) : encoder-decoder model for longer context. 이를 위해 fusion-in-decoder사용, long input은 chunk로 인코딩되고 decoder는 모든 input token에 대해 attention한다는 차이점
- Memorizing Transformer (2022): 가장 이 논문과 유사한 논문임
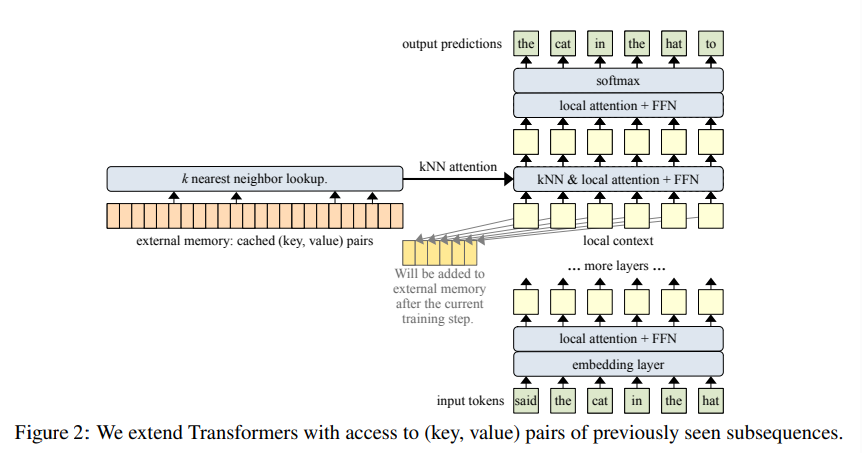
- transformer를 저장된 key값을 반환하고, 그것을 통해 standard cross attention하는 방식 사용
(본 논문과 거의 컨셉이 동일함) - public implementation이 없어서 완벽 제현은 안됐지만, 거의 유사하게 구현하여 활용했음.
- transformer를 저장된 key값을 반환하고, 그것을 통해 standard cross attention하는 방식 사용
✅ 해당 논문과의 주요 차이점
-
해당 논문은 이 방법을 사용하기 위해 additional learnable 파라미터 요구 ➡️ 이를 사용하기 위해 모델 학습이 필요, 하지만 우리 건 학습 파라미터 추가 아예 없는 generic approach
-
해당 논문은 Single decoder 레이어에 대해서만 key값 조회해서 사용함. ➡️ 그런데 우리는 모든 head, 모든 layer에 대해 적용하기 때문에 보다 다측면으로 인코더의 정보를 활용할 수 있음
5. Result
5.1 Long Document Summarization
Low-cost training
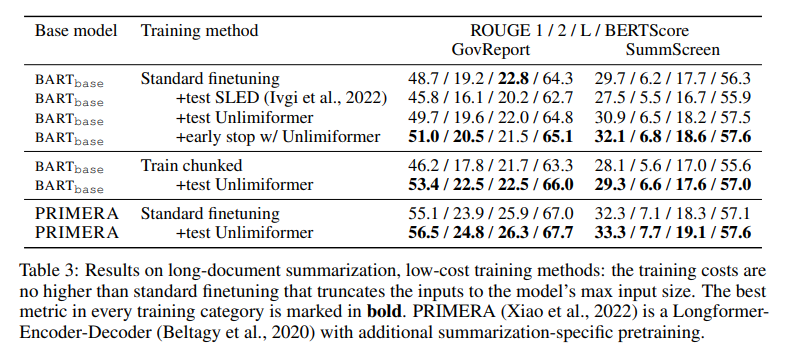
- 어떠한 훈련없이 exsiting checkpoint에 Unlimiformer를 적용한 가 BART를 향상시킴
- 반면에 additional trainig없이 SLED는 성능이 감소했음. 이는 Unlimiformer가 추가적인 훈련 없이도 효과적임을 보여줌.
- 또한 는 base model을 특별한 훈련 없이도 향상시켰음. Train chunked에서는 별 효과가 없었음.
(그래서 아예 보고하지 않았나 봄)
Long-range training
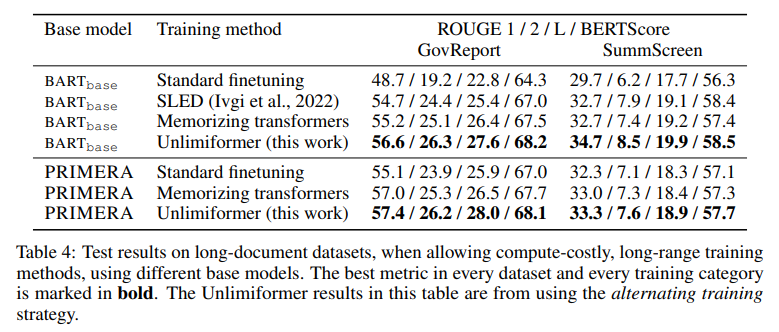
-
additional training cost를 포함시켰을 때의 결과를 보여줌. 거의 모든 데이터 및 메트릭에서 Unlimiformer가 동일한 훈련방식에서 베이스라인 능가하는 것을 보여줌
-
PRIMERA에 대해 진행한 실험은 다음과 같은 인사이트 제공
- PRIMERA의 모델 규모가 더 크고, 더 많은 학습 데이터로 사전훈련되었음에도 Unlimiformer+BART가 더 높은 성능을 보여줌
- Unlimiformer는 단순히 BART 등 standard 모델에 적용하는 것 뿐만 아니라 Long-context룰 위해 제안된 transformer에 적용되어 더욱 성능을 개선시킬 수 있음.
Book Summarization
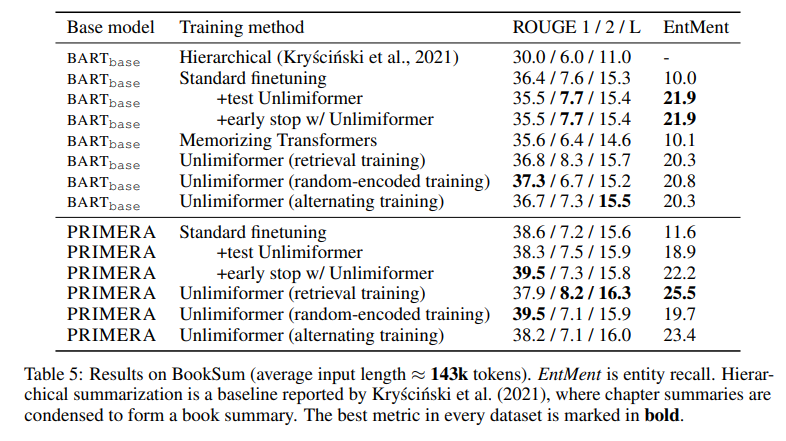
- Unlimiformer가 BART, PRIMERA를 능가하는 성능을 보이는 것 확인할 수 있음.
- 그런데 이 모델 BART 모델에서 성능차이가 크지 않게 나옴.
- 그러나 우리가 이 모델의 결과를 직접 확인해봤을 때, limited coherence와 high rate of hallucination을 발견할 수 있었음. 하지만 이건 n-gram 기반 메트릭에 반영되지 않으며, BERT-score또한 의미론적이긴 하나, 환각 현상 등을 제대로 반영하지 못함.
- 그럼에도 불구하고 test time에서 unlimited token을 참조할 수 있는 Unlimiformer는 훨씬 더 나은 Entity Mention Recall을 달성하는 모습을 보여줌. 즉, 테스트 단계에서의 추가만으로 기본 모델에 비해 이 성능이 두 배가 오르는 것을 보여줌.
6. Analysis
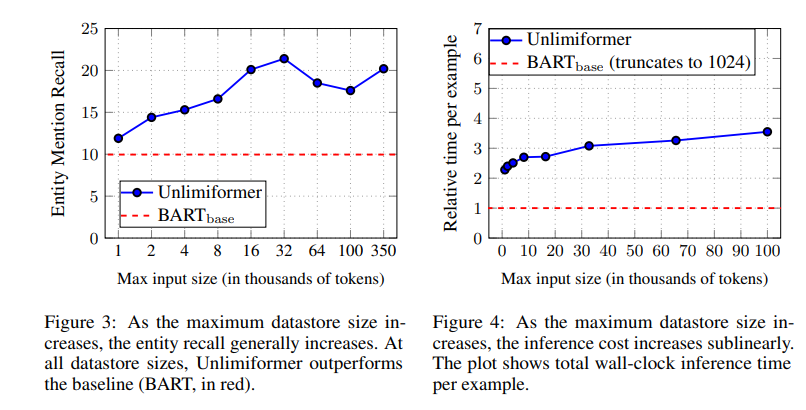
Is the long input really needed?
- 최근 여러 논문들은 많은 텍스트 생성데이터에서 필요한 정보의 대부분이 input의 시작 부분에 집중되어 있으며, long context modeling이 필요하지 않음을 보여줌.
- 이에 따라 Unlimiformer가 실제로 긴 입력을 활용하는지 평가하기 위해 BookSum의 입력길이를 제한하는 실험 진행
아니 근데 소설은 다르겠지 전체를 봐야하겠지 책이 앞부분에 줄거리를 써주겠냐고
- 결과는 EntMent에 대해서 입력 토큰의 길이가 커질수록 성능이 향상되는 모습을 보여주며, Unlimiformer가 더 longer input을 사용해 더 나은 결과를 생성한다는 것을 보여줌.
- 또한 일부 연구는 필요한 정보가 입력의 일부에 집중되어 있는 건 맞지만, 그것이 꼭 시작부분은 아니라는 연구도 있었음. (WkikSum 데이터셋에서 이러한 경향을 관찰했다고 함)
Computational cost
- Unlimiformer가 추가적인 훈련 파라미터를 필요로 하지 않음에도 불구하고 full input의 인코딩, index contruction, index search는 processing time을 훈련/추론 단계 모두에서 증가시킬 수 있음.
- 우리는 computational cost of inference를 input length 관점에서 시각화해봤음. (위의 그림에서 오른쪽)
- 결과적으로, 필요한 GPU-time이 sublinear하게 증가하는 것을 볼 수 있음 (일반적인 선형증가 보다 천천히 증가)
Performance on other tasks

- 다양한 다른 테스크에 대해서도 진행해본 결과를 공유함.
1. QASPER: question-answering dataset- Contract NLI: natural language inference dataset
- QMSum: query-based summarization dataset for metting trnascript
- NarrativeQA: reading comprehension dataset over narratives
- Unlimiformer imporoves over the base model.
What is attended to?
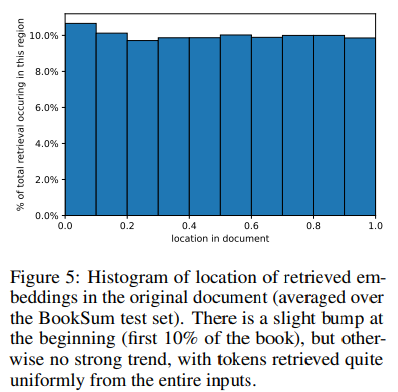
- BookSum 테스트 셋에 대한 전체 decoding process에서 key의 검색 빈도를 시각화함.
- 의미하는 바는 전체 문서에 고르게 걸쳐서 키가 검색된다는 뜻임. 즉, 문서의 시작 부분에만 중요한 정보가 있는게 아니고 고루 걸쳐 있다라는 것
- 결과적으로, Unlimiformer에서 제시한 입력토큰 처리방식과 long context modeling 연구의 필요성을 강조하는 대목.
7. Conclusion
- Pre-trained Encoder-Decoder 아키텍처의 Cross Attention 과정을 kNN으로 대체하여 더 효율적으로 긴 시퀀스에 대한 처리가 가능하도록 만들어진 Unlimiformer 소개
- 이 모델은 더 적은 메모리 사용량으로, 추가적인 훈련이나 학습 파라미터 없이도 test time에서의 적용 만으로 기존 standard fine-tuning의 성능을 능가하는것을 발견
메모리 사용량이라고 했지 연산량이라고는 안 했다
- 본 연구가 컴퓨팅 리소스가 부족한 practitioners와 researchers 에게 도움이 될 수 있길 바람~
- 코드에서 LLaMMa-2에 대해서 적용한 것도 있는 것도 있으므로 궁금하면 코드를 보세요!

저도 새로운 domain에 적용해보고싶네요~