
웹 크롤링(Web Scraping)
- 컴퓨터 소프트웨어 기술로 웹 사이트들에서 원하는 정보를 추출하는 것
- 웹은 기본적으로 HTML형태(어떤 정형화된 형태)로 되어 있다.
- HTML을 분석해서 우리가 원하는 정보들만 뽑아오는 것
- 외국에선 'Web Crawling'보다는 'Web Scraping'이라는 용어를 더 자주 사용함
- Python으로 크롤링 하는 소스들이 가장 흔하다
시도해보기
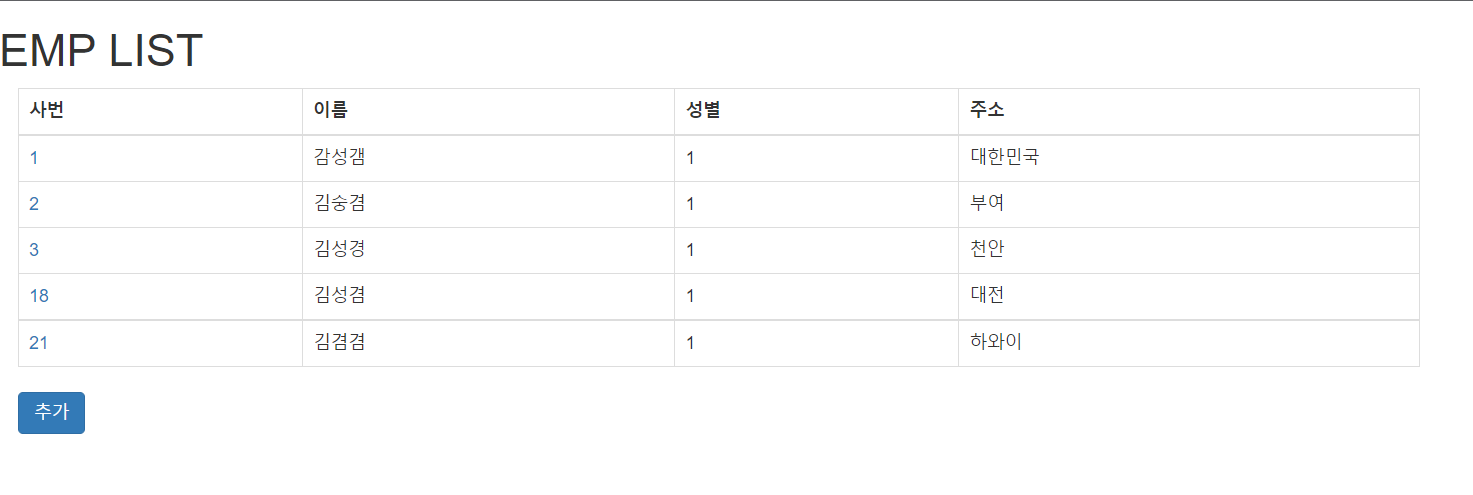
직접만든 EMPLIST사이트를 crawling 해보자
- 설치하는방법
- 코드
import requests
URL = "http://127.0.0.1:5000/"
resp = requests.get(URL)
print(resp.status_code)
print(resp.text)- 결과
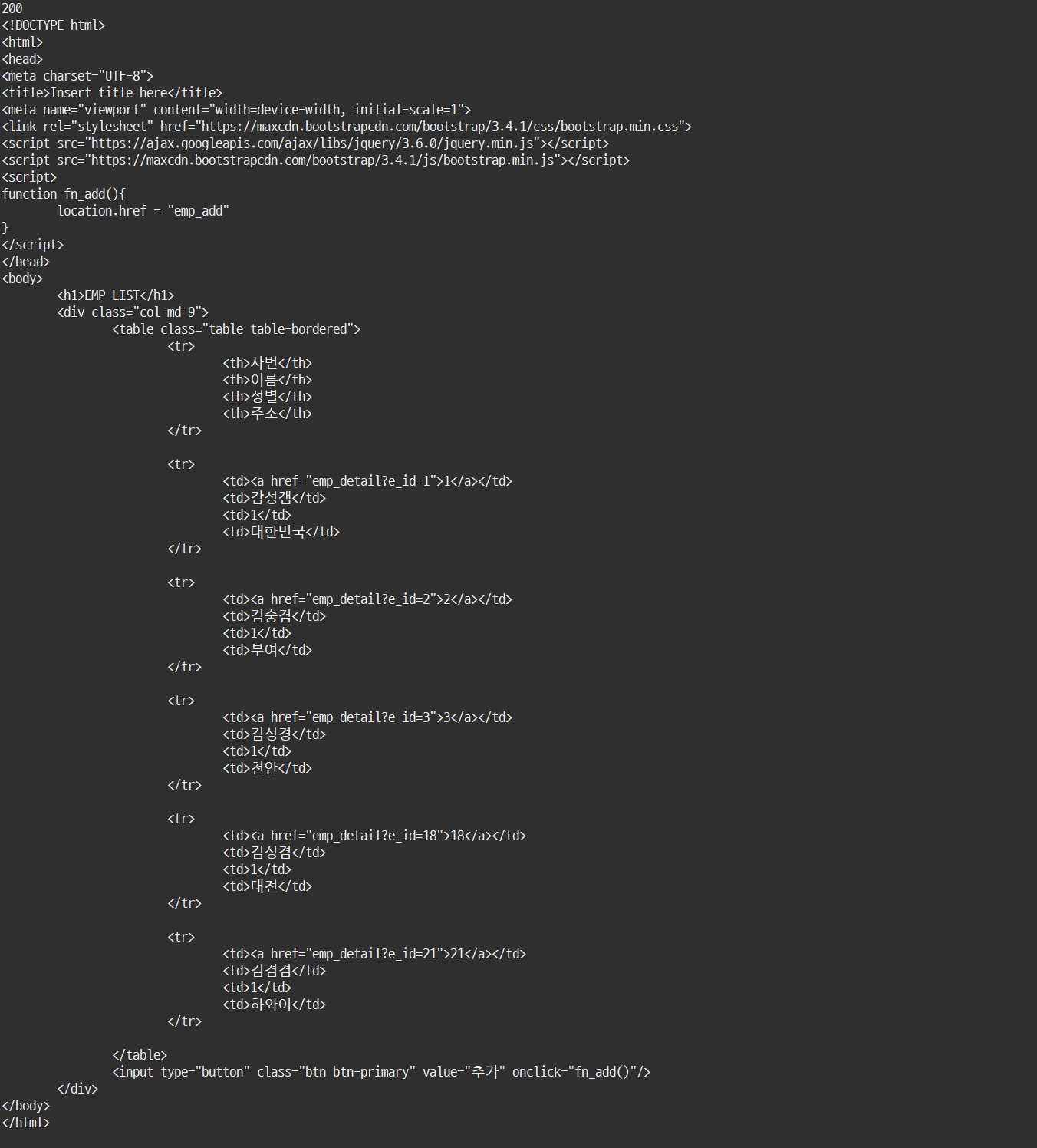
- 페이지 소스보기를 통해서 나오는 html코드가 출력된다.
테이블 데이터에서 필요한 것만 가져오기
- 코드
import requests
from bs4 import BeautifulSoup
url = "http://127.0.0.1:5000/"
response = requests.get(url)
if response.status_code == 200:
html = response.text
soup = BeautifulSoup(html, 'html.parser')
trArr = soup.select('tr') # tr태그 데이터를 배열형태로 가져온다.
for idx, tr in enumerate(trArr):
if(idx > 0):
tdArr = tr.select('td') #tr안에 있는 td데이터를 배열형태로 가져온다
print(idx, tdArr[1].text, tdArr[3].text) # td배열에서 이름과 주소에 해당하는 데이터를 가져온다.
else :
print(response.status_code)- 결과

- 원래 사이트에 있던 테이블에서 이름과 주소만 긁어왔다.

김성겸