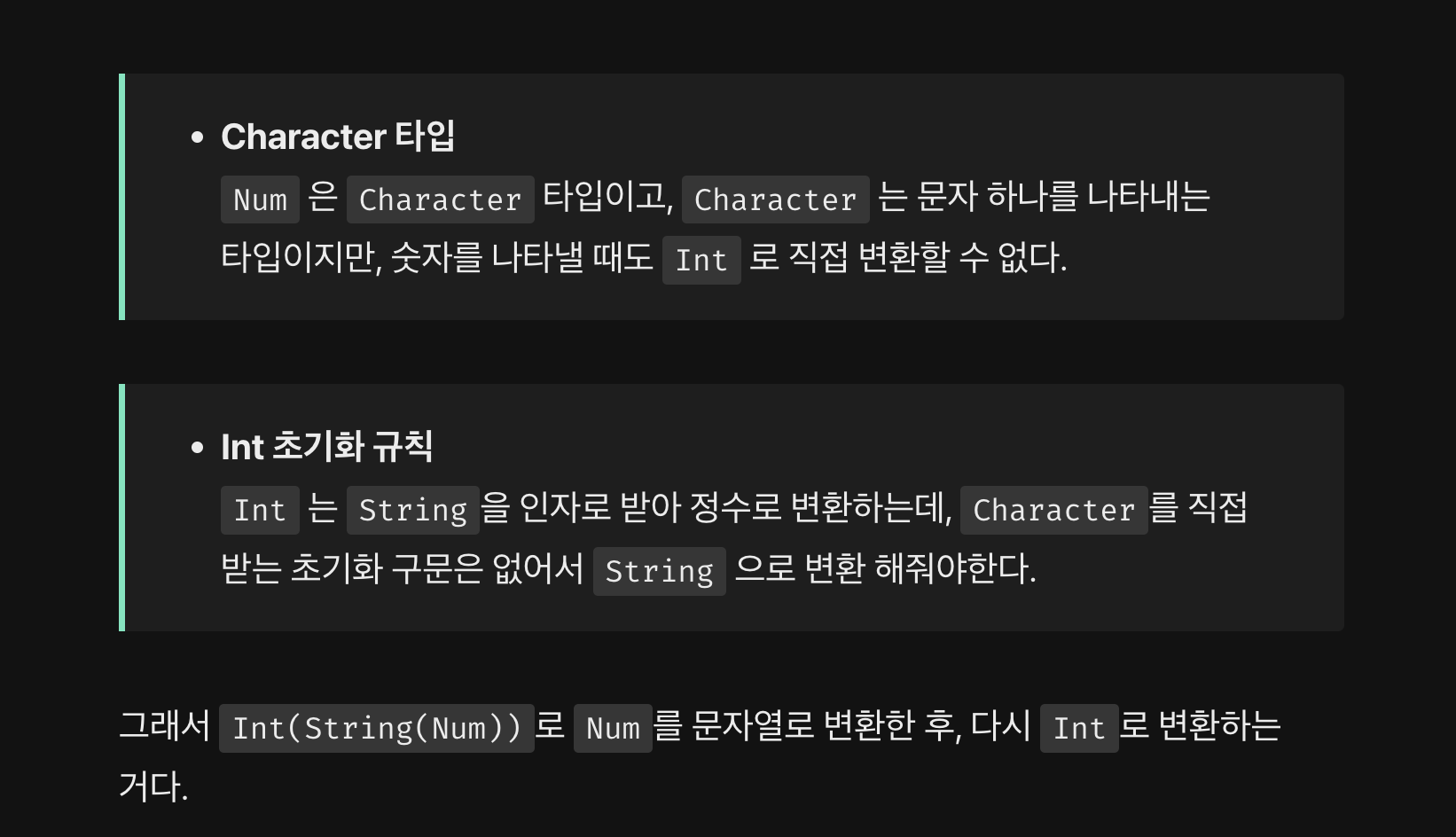
어제 블로그 작성한 부분 중에 내가 Character 타입에 대해 이해하지 못해,
튜터님을 찾아갔었다는 내용이 있다.

튜터님을 찾아가고 나서 문제는 해결 했지만, 짚고 가야할 부분과
더 고민해볼 포인트, 그리고 그 고민을 해결할 수 있는 필요배경지식에 대해 공부해보라며 친절히 알려주셨다.
오늘은 과제도 제출했으니 마음 편히 공부해보련다.
1. 문법적으로 짚고 가야 할 포인트
String을 매개변수로 하는 Int의 생성자를 보가 되면init?(String)의 꼴을 가진다.
init과init?의 차이를 알고있는지 스스로 확인 후 피드백 해보자.
Int 타입의 init?(String) 생성자는 failable initializer (실패 가능 생성자)다.
문자열을 Int로 변환할 수 있는 경우에는 Int 인스턴스를 생성하지만,
변환할 수 없는 경우에는 nil을 반환한다.
예를 들어 "123" 과 같은 문자열은 숫자로 변환이 가능하기 때문에
Int("123") 은 유효한 Int 인스턴스를 생성한다.
하지만 "abc" 와 같은 문자열은 숫자로 변환할 수 없어 Int("abc") 는 nil을 반환한다.
정리하면 init?을 사용하는 이유는 ,
입력된 문자열이 숫자로 변환될 수 없는 경우에 대한 처리를 명확하게 하기 위함이다.
이렇게 하면 호출하는 쪽에서도 실패 가능성을 고려해서 옵셔널 처리를 할 수 있다.
Init은 기본 생성자, 인스턴스를 항상 성공적으로 생성, 실패할 가능성이 없어서 반환타입 없음init?은 실패 가능 생성자, 초기화 중에 특정 조건에 따라 생성 실패할 수 있음, 반환 타입이 옵셔널이고 실패하면nil을 반환, 입력값이 유효하지 않은 경우도nil을 반환
2. 고민 포인트
init?을 통해 실패할 수 있다면,Character또한init?(Character)로 구현하면 되는거 아닐까 ?
Apple은 왜 이렇게 생각해봄직한 것을 구현하지 않았을까 ?
.
.
.
3. 고민 해결을 위한 필요배경지식
[ 순서 ]
- Character 타입
- ASCII 코드
- 유니코드
- Scalar(스칼라) 단어 뜻
- UnicodeScalar 타입
< Character 타입 >
Character 타입은 문자 하나를 나타내는 데이터 타입이다.
Character는 하나의 문자로 할당되고,
"A"와 같은 길이가 1인 문자열을 Character로 변환하여 사용할 수 있다.
길이가 2 이상인 문자열을 Character로 변환하려고 하면 오류가 발생한다.
주요 특징
- 유니코드 지원 :
Character는 유니코드 기반이므로 전 세계 언어의 다양한 문자를 표현할 수 있다.- 문자열과의 관계 :
String타입은 여러Character의 집합이다. 문자열을 다루는 경우도Character배열로 작업할 수 있다.
< ASCII 코드 >
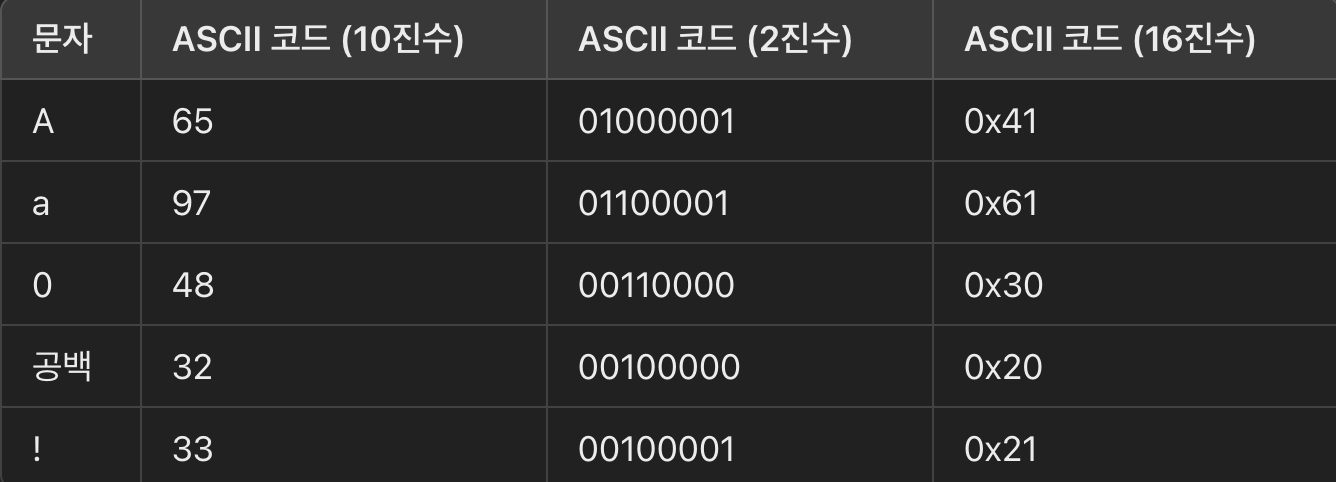
ASCII (아스키, American Standard Code for Information Interchange) 코드는
컴퓨터와 전자 통신 장비에서 텍스트를 표현하기 위해 사용하는 문자 인코딩 표준인데,
1960년대에 만들어져 현재까지 널리 사용되고 있다.
영어 알파벳, 숫자, 특수 문자, 그리고 제어 문자들까지 포함하고 있다고 한다.
2진수로 나누는 것도 신기한데 그걸 아스키 코드 16진수로 표현하는게 인상적이다.
아스키는 7비트로 구성되어 있어서 최대 128개 문자만 표현할 수 있다.
여기에는 영어나 숫자, 몇가지 특수문자와 줄바꿈이나 탭 같은 제어문자도 포함된다.
그리고 영어 기반의 문자만 표현할 수 있다보니 다른 언어는 포함하지 않는다.
이런 한계를 극복하기 위해 등장한 것이 유니코드(Unicode)로,
전 세계 언어의 모든 문자를 포함하며 확장 가능하다.
그렇다면 이어서 유니코드를 알아보자.
< 유니코드 (Unicode) >
유니코드 는 전 세계 모든 문자를 컴퓨터에서 표현하고 사용할 수 있게 만든 문자 인코딩 표준 이다.
문자 인코딩 표준이란,
컴퓨터가 텍스트를 숫자로 변환해서 저장하거나 전송할 수 있게 만들어주는 규칙이라고 생각하면 된다.
컴퓨터는 문자 자체를 이해하지 못하고 숫자만 처리할 수 있기에,
각 문자를 특정한 숫자에 대응시키는 규칙이 필요한 것인데 그것이 바로 문자 인코딩 표준 이라고 한다.
자, 다시 돌아가서 유니코드가 왜 필요한지 알아야한다.
초기에는 위에서 봤던 아스키처럼 영어와 기본적인 특수문자만 지원하는 표준만 있었다.
하지만 다른 나라 언어를 컴퓨터에서 다루기 위해서는 더 많은 문자 공간이 필요하게 되었는데,
유니코드는 모든 언어와 다양한 기호들을 하나의 체계로 통합하려고 만들어진 것이라 보면 된다.
유니코드의 장점
유니코드 덕분에 한 프로그램이나 문서에서 다양한 언어를 동시에 쓸 수 있고,
이모지나 특수기호도 쉽게 다룰 수 있게 되었다.
하나의 통일된 표준으로 다양한 문자를 표현할 수 있게 해준것이 유니코드의 큰 장점이다.
< Scalar (스칼라) 단어의 뜻 >
스칼라의 대해 알아보다가 한 단어임에도 불구하고 어느 상황에서인지에 따라 뜻이 바뀌어서 당황했다.
수학에서 Scalar
- 벡터가 방향과 크기를 모두 가진 값이라면 스칼라는 방향 없이 크기만 가진 단순한 숫자이다.
- 예로 들자면 온도나 무게 같은 값은 방향과 관계 없이 크기만을 나타내므로 스칼라 라고 할 수 있다.
컴퓨터 과학에서 Scalar
- 하나의 값을 나타나는 자료형. 예로 들자면
Int,Float,Bool같은 기본 데이터 타입은 모두 스칼라 타입으로 간주된다. 문자열이나배열같은 복합 자료형은 여러 값을 담고 있으므로 일반적으로 스칼라라고 하지 않는다.
유니코드에서 Scalar
- 각 문자를 고유하게 나타내는 코드 포인트 (숫자) 를 의미한다.
- 유니코드 스칼라 값은 보통
U+0000에서U+D7FF또는U+E000에서U+10FFFF까지의 범위 안에 있다.
.
.
.
.
아..... 마지막 유니코드에서 스칼라 부분을 적으면서 너무 어려웠지만...!
예시를 몇 가지 보니까 저 외계어가 다 이런 값이겠구나 하고 알고만 있으면 될 것 같다.
U+0041: 유니코드에서 "A" 문자의 스칼라 값.U+AC00: 한글 "가"의 스칼라 값.U+1F600: 😀 이모지의 스칼라 값.
요약하자면 스칼라란!
scalar는 단순히 크기나 값을 가지는 단일한 숫자나 값을 뜻하는 용어로, 복잡하지 않은 하나의 단위 값이라고 생각하면 된다.
< UnicodeScalar 타입 >
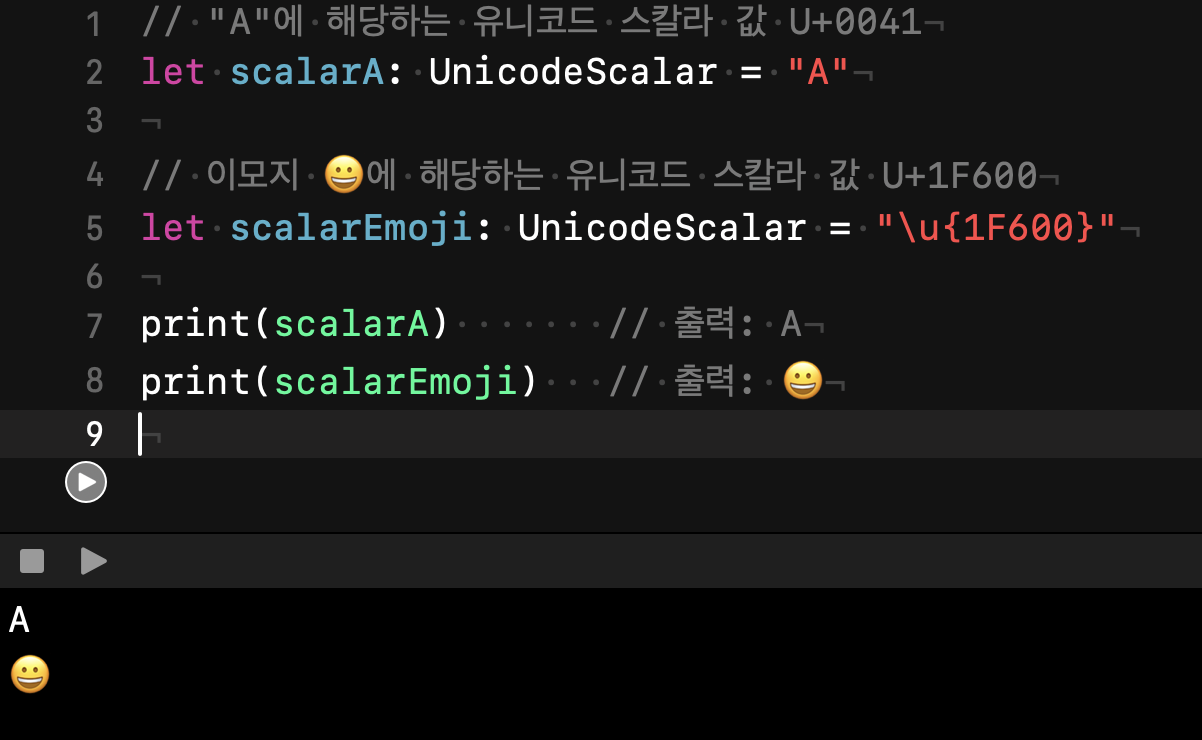
UnicodeScalar 타입은 swift에서 제공하는 데이터타입으로 단일 유니코드 스칼라 값을 나타내기 위해 사용된다.
유니코드에서 각 문자를 특정 숫자 값으로 표현하는데,
UnicodeScalar는 이 코드 포인트를 스위프트에서 다룰 수 있게 해주는 타입이라고 보면 된다.
예를 들자면 U+0041은 문자 A에 해당하는 유니코드 스칼라 값인데 이걸 스위프트에서 UnicodeScalar 타입으로 표현할 수 있다.
이렇게 특정 문자의 유니코드 값을 알고 있다면 UnicodeScalar 를 이용해 그 문자에 접근 할 수 있다.
문자열의 각 문자를 UnicodeScalar로 접근해서도 다룰 수 있고
UnicodeScalar는 Int값을 이용해 초기화 할 수도 있다.
UnicodeScalar(65) 는 "A"를 나타낸다.
UnicodeScalar와 다른 문자열 타입의 차이
Character: 단일 문자로 유니코드 스칼라 값 하나 이상으로 구성될 수 있음. 예를 들어, 이모지는 Character이지만 여러 유니코드 스칼라로 구성될 수도 있음.String.Element: Character 타입으로, 문자열의 각 개별 문자(문자열에서 하나씩 꺼낸 요소)를 나타냄.UnicodeScalar: 단일 유니코드 코드 포인트를 다룸.
쭉 알아봤으니 고민포인트를 해결해보자.
init?을 통해 실패할 수 있다면,Character또한init?(Character)로 구현하면 되는거 아닐까 ?
Apple은 왜 이렇게 생각해봄직한 것을 구현하지 않았을까 ?
고민 포인트의 대한 결론은,
Swift 는 가능한 실패하지 않는 초기화를 선호하는 경향이 있다고 한다.
Character의 초기화에서 명확하게 단일 문자를 얻을 수 있다면, init? 을 쓸 필요가 없을 것이다.
오히려 init? 을 사용하는 경우는 확실히 실패할 가능성이 있을 때만 쓰도록 되어 있다.
Character 초기화 과정에서 실패할 만한 명확한 경우가 거의 없기 때문에,
Apple은 Character를 굳이 init? 로 만들지 않은 것이라고 보면 될 것 같다.
음 ...
Character 타입은 기본 문자 단위를 표현하고 타입 간의 변환에서 최대한 실패 가능성을 줄여서
단순함과 일관성을 유지하는 부분을 알게 되었다.
애플이 왜 Character 타입을 init? 으로 구현하지 않았는지,
또 타입 변환에서 명확성을 유지하기 위해 설계된 이유를 그나마 이해할 수 있었다.
덕분에 애플이 일관성을 얼마나 중요하게 여기는지도 알게 되었고..!
변환에서 오류를 최소화하는 설계의 장점을 좀 알게 된 듯 하다.


Character의 초기화에서 명확하게 단일 문자를 얻을 수 있다면, init? 을 쓸 필요가 없을 것이다.
라는 부분에서 명확하게 단일문자를 얻을 수 있다는 게 어떤 뜻인 건가요?
그리고 고민포인트에 대한 결론에 유니코드와 관련된 내용은 적혀있지 않은데 어떤 연관이 있는 건가여?