11. CPU 스케줄링
11-1. CPU 스케줄링 개요
모든 프로세스는 CPU를 필요로 하고 모든 프로세스는 먼저 CPU를 사용하고 싶음
운영체제가 프로세스들에게 공정하고 합리적으로 CPU 자원을 배분하는 것
프로세스 우선순위
프로세스 종류마다 입출력장치를 이용하는 시간과 CPU를 이용하는 시간의 양에는 차이가 있음
- 입출력 집중 프로세스(I/O bound process) : 비디오 재생이나 디스크 백업 작업을 담당하는 프로세스와 같이 입출력 작업이 많은 프로세스
- CPU 집중 프로세스(CPU bound process) : 복잡한 수학 연산, 컴파일, 그래픽 처리 작업을 담당하는 프로세스
유닉스, 리눅스, macOS 등의 유닉스 체계 운영체제에서는 ps -el 명령을 통해 확인이 가능 -> nice 명령을 통해 일부 프로세스의 우선순위를 변경 가능
윈도우에서는 Process Explorer라는 소프트웨어를 통해 우선순위 확인과 변경이 가능
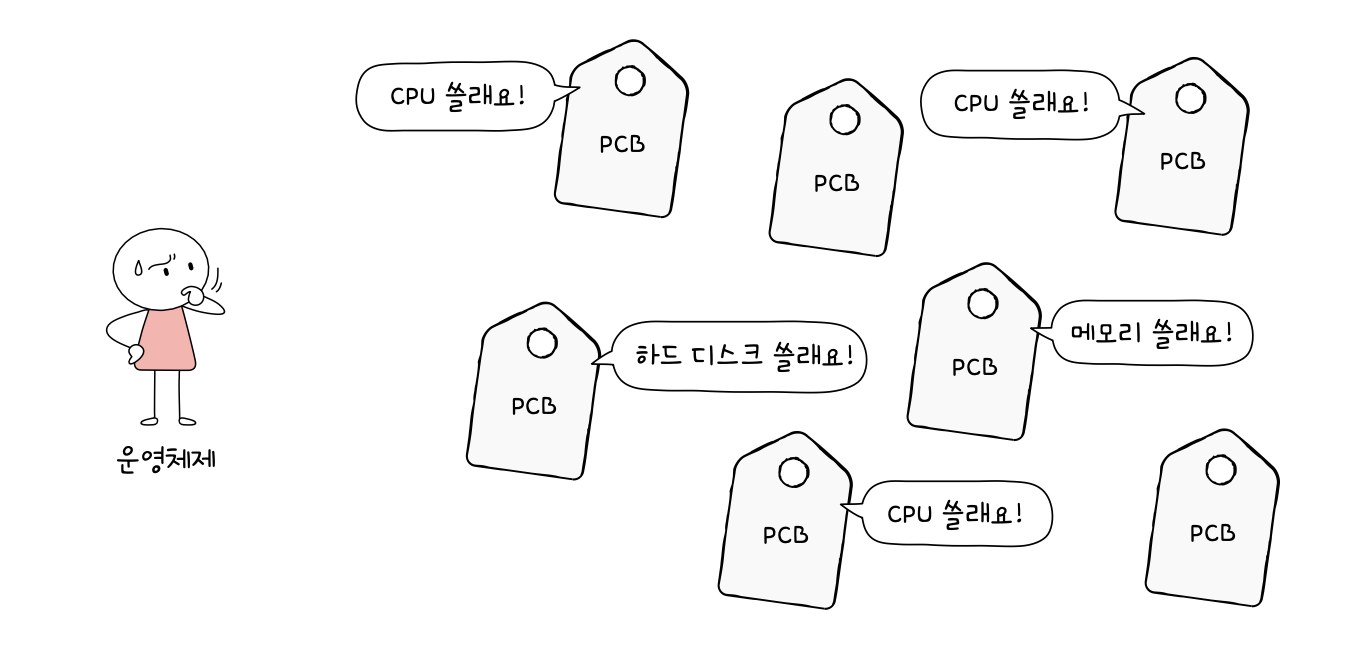
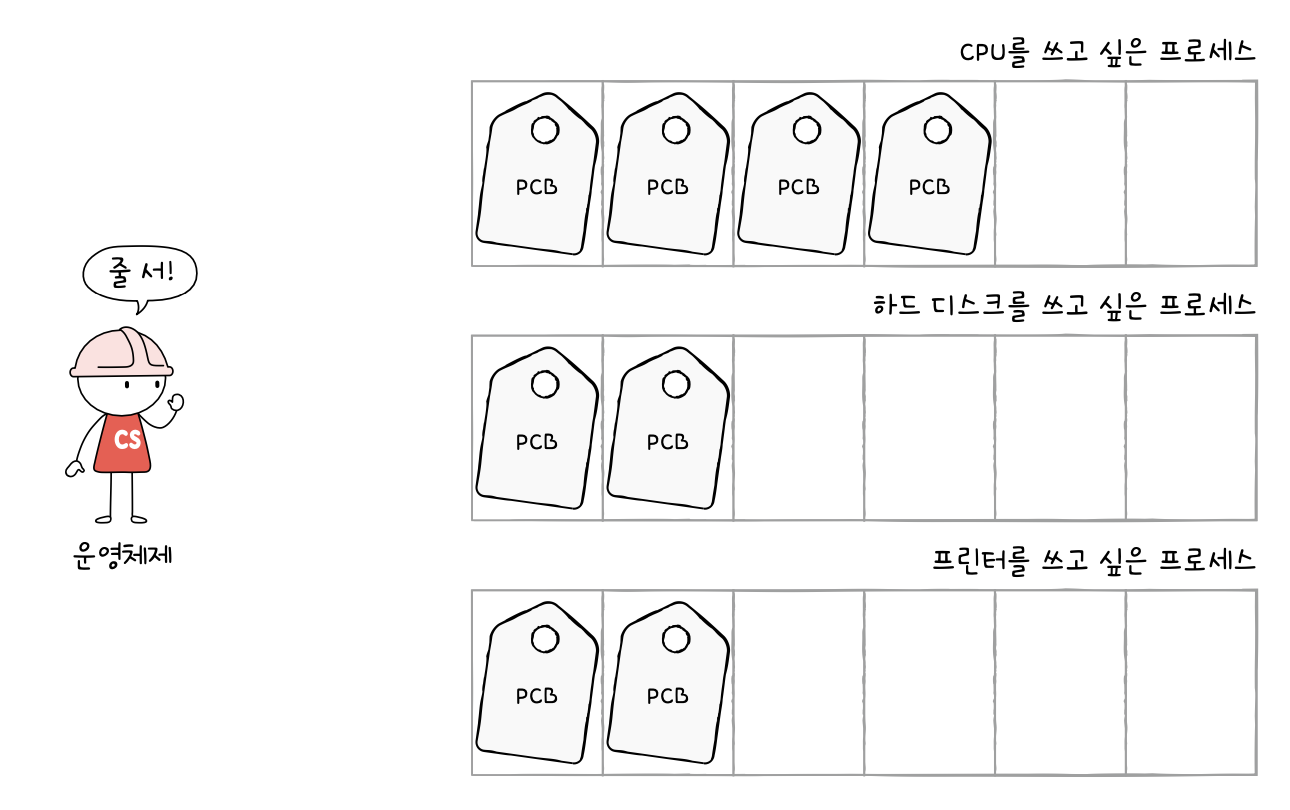
스케줄링 큐(scheduling queue)
 |  |
|---|---|
| 스케줄링 큐 전 | 스케줄링 큐 후 |
- 준비 큐(ready queue) : CPU를 이용하고 싶은 프로세스들이 서는 줄
- 대기 큐(waiting queue) : 입출력장치를 이용하기 위해 대기 상태에 접어든 프로세스들이 서는 줄
선점형과 비선점형 스케줄링
non-preemptive (비선점형) : Process가 자원을 반납하기 전까지 다른 프로세스가 자원을 사용할 수 없음. 수행시간이 긴 프로세스가 자원을 점유하게 되면 이후 실행되어야 하는 프로세스들이 자원을 할당받지 못하는 기아 현상이 발생.
preemptive (선점형) : Process가 한번 실행될 때 제한된 시간만을 할당해서 사용. 프로세스의 우선순위에 따라 스케쥴링을 하게 되므로 우선순위가 낮은 프로세스는 기아 상태에 빠짐.
| 비선점형 (non-preemptive) | 선점형 (preemptive) |
|---|---|
| 정해진 시간 없이 process 종료 전까지 점유 | 일정 시간을 process에 할당해 해당 시간만 자원을 사용하고 반납 |
| 중간에 interrupt가 일어나지 않음 | interrupt를 통해 실행 중인 process를 교체 |
| 종료 후 context switch 외에 추가적인 오버헤드 없음 | context switch 가 일정 시간마다 일어나기 때문에 오버헤드 있음 |
| 프로세스 우선순위 고려 없음 | 프로세스에 대한 우선순위를 고려 |
| FCFS, SJF, Priority Scheduling | Round-Robin, Multilevel Queue Scheduling |
[⭐혼공단 미션 인증!⭐]
준비 큐에 A,B,C,D 순으로 삽입되었다고 가정했을 때, 선입 선처리 스케줄링 알고리즘을 적용하면 어떤 프로세스 순서대로 CPU를 할당받는지 풀어보기
- 선입 선처리는 들어오는 순서대로 처리하는 방법이므로 들어온 순서 A→B→C→D 그대로 CPU를 할당 받는다.
11-2. CPU 스케줄링 알고리즘
[참고]
- FCFS(First Come, First Served) Scheduling (non-preemptive)
- 가장 간단하고 직관적인 스케쥴링 알고리즘으로 그 구조가 Queue와 비슷하다.
- 먼저 도착한 프로세스를 먼저 실행하고, 프로세스가 도착한 순서대로 CPU를 할당한다.
- 보편적으로 프로세스들의 평균 대기 시간이 길어진다는 문제가 있다.
- SJF(Shortest Job First) Scheduling (non-preemptive) ← ready queue에서만 보면 non임
- 다음에 실행할 프로세스를 선택할 때 실행 시간이 가장 짧을 것으로 예상되는 프로세스를 선택하는 방식
- ready queue에 프로세스를 새로 삽입할 때 CPU burst time이 가장 짧은 것을 다음 프로세스로 지정할 수 있도록 제일 앞에 삽입한다. → priority queue (minheap으로 구현)
(우선예약가능 → ready queue 앞에 세워주는 거지, 뚫고 먼저 들어가지는 않는다.) - 이 경우 FCFS보다 평균 대기 시간이 줄어들지만 CPU burst time이 긴 프로세스의 경우 오히려 대기시간이 증가하고 심할 경우 starvation 상태가 되는 문제점이 있다.
- 비선점형 방식뿐만 아니라 선점형 방식으로 이용되기도 한다.
- RR(Round-Robin) Scheduling (preemptive)
- 각 프로세스에 차례로 일정한 시간 할당량(time quantum) 동안 CPU 자원을 차지할 수 있도록 함
- time quantum 시간이 길다면 FCFS와 같은 형태로 작동하므로 RR 스케줄링을 사용하는 의미가 줄어들고, 시간이 너무 짧다면 너무 많은 Overhead가 생기기 때문에 좋지 않다.
- 따라서 적절한 time quantum 길이를 찾는 것이 중요함.
example.
- P1 : 4, P2 : 2, P3 : 3 (resource) ( 예 )P1이 끝나는데 4 time이 필요하다)
- time quantum = 2 (RR)
- ready queue : [P3, P1, P2] (FCFS, RR에 한해서, SJF는 위에 프로세싱 자료보고 고름)**
execution 순서
1) FCFS : [P3, P1, P2] → 돌아가는 과정 : P3,P3,P3,P1,P1,P1,P1,P2,P2 → 끝나는 순서 : P3, P1, P2
2) SJF : [P2, P3, P1] → 돌아가는 과정 : P2,P2,P3,P3,P3,P1,P1,P1,P1 → 끝나는 순서 P3, P1, P2
3) RR : [P3, P1, P2] → 돌아가는 과정 : P3,P3,P1,P1,P2,P2,P3,P1,P1 → 끝나는 순서 P2, P3, P1
(average) waiting time (context-switching에 의한 overhead는 계산하지 않음)
(→ 평균은 프로세스 개수로 나누기)
1) FCFS : P3(0) + P1(3) + P2(3+4) = 10, (10/3)
2) SJF : P2(0) + P3(2) + P1(2+3) = 7, (7/3)
3) RR : P3(0) + P1(2) + P2(2+2) + P3(2+2) + P1(2+1) = 13, (13/3)
P3(0) + P1(2) + P2(2+2) + P3(2+2+2) + P1(2+2+2+1) = 19 * 기다린 기준으로 생각한다!!
3-1) IF TIME-QUANTUM = 3, WAITING TIME = ?
RR : [P3, P1, P2] → 돌아가는 과정 : P3,P3,P3,P1,P1,P1,P2,P2,P1
→ WAITING TIME = P3(0) + P1(3) + P2(3+3) + P1(2) = 11
→ 타임퀀텀 사이즈에 따라 대기시간이 달라지는데 조절 잘 해야 한다. 컨텍스트 스위치가 많이 일어나면 대기시간이 길어질 수 있지만, 대기시간이 달라질 수 있어서 스위치가 많이 일어난다고 해서 비례적으로 대기시간이 길어지지는 않는다.
