본 포스팅은 파이토치로 배우는 자연어 처리 (한빛미디어), 한국어 임베딩(에이콘), 머신러닝 교과서 with 파이썬, 사잇킷런, 텐서플로(길벗) 책 그리고 https://wikidocs.net/22886 참고하여 작성되었습니다.
이미지 자료https://github.com/gilbutITbook/080223/blob/master/ch16/
6.0 시퀀스 데이터
- 시퀀스
- 순서가 있는 항목의 모음(특정 순서를 가져, 상호독립적X)
-> 언어, 음성, 시계열처럼 데이터 항목이 앞뒤 항목에 의존하는 데이터: 순차데이터

- 사람의 언어에는 순서 정보가 포함
- 예) 음성: 음소의 연속
-> 결론적으로, 언어를 이해하려면, 시퀀스를 이해해야 함
- 순서가 있는 항목의 모음(특정 순서를 가져, 상호독립적X)
- 딥러닝에서의 시퀀스 모델링
- 상태정보(은닉상태)를 유지하는 것과 관련
- 시퀀스에 있는 각 항목을 만나면서 은닉 상태를 업데이트 함
- 시퀀스 모델링의 종류

- 다대일(many-to-one)
- 입력 데이터가 시퀀스, 출력은 고정 크기의 벡터
- 예) 감성분석: 텍스트(입력), 클래스 레이블(출력)
- 일대다(one-to-many)
- 입력데이터가 시퀀스가 아닌 일반적인 형태, 출력은 시퀀스
- 예) 이미지 캡셔닝: 이미지(입력), 영어 문장(출력)
- 다대다(many-to-many)
- 입력과 출력 배열이 모두 시퀀스
- 입력과 출력이 동기적인지 아닌지에 따라 더 분류 가능
- 동기적인 다대다 모델링의 예: 각 프레임이 레이블되어 있는 비디어 분류
- 동기적이지 않은 다대다 모델링의 예: 한 언어에서 다른 언어로 번역하는 작업(예를 들어 독일어로 번역 전에 전체 영어 문장을 읽어 처리)
- 다대일(many-to-one)
순환 신경망(Recurrent Neural Network, RNN)
- 정의
- 입력과 출력을 시퀀스 단위로 처리하는 시퀀스(Sequence) 모델
- 히든 노드가 방향을 가진 엣지로 연결돼 순환 구조를 이루는 인공신경망의 한 종류
- 음성, 문자 등 순차적으로 등장하는 데이터 처리에 적합한 모델
- RNN과 피드포워드 신경망 비교

- 기본 피드포워드: 정보가 입력에서 은닉층으로 흐른 후, 은닉층에서 출력층으로 전달
- RNN: 은닉층이 입력층과 이전 타임 스텝의 은닉층에서 정보 받음
(인접한 타임 스텝의 정보가 은닉층에 흘러, 네트워크가 이전 이벤트 기억 가능 -> 루프, 순환 에지)- 은닉층의 노드에서 활성화 함수를 통해 나온 결과값을 출력층 방향으로도 보내면서, 다시 은닉층 노드의 다음 계산의 입력으로 보냄
- 단일층과 다층 RNN
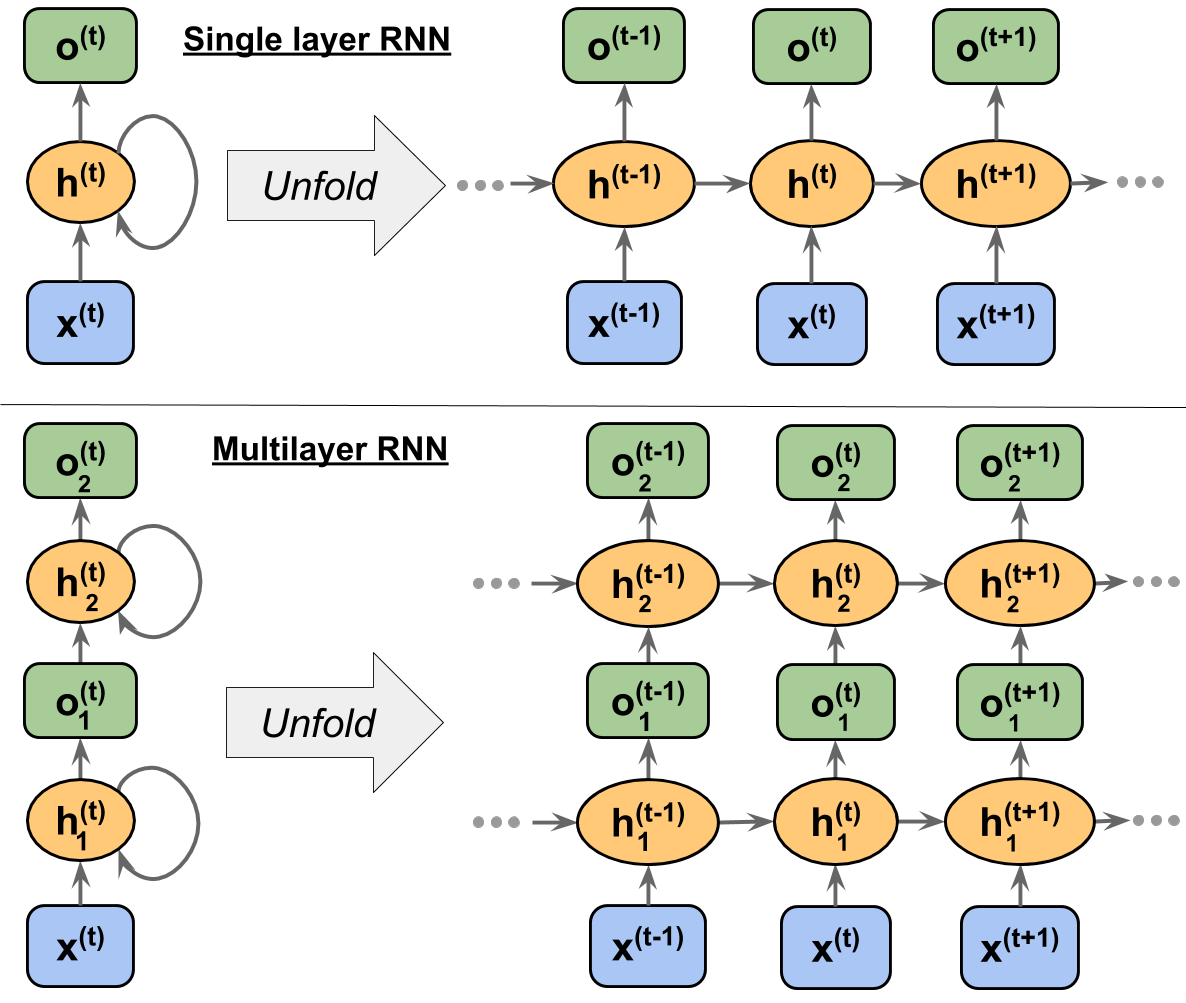
- RNN의 은닉 유닛은 표준 신경망의 은닉 유닛과 달리, 두 개의 다른 입력을 받음
(* 수식 정의 참고) - x: 입력층의 입력 벡터, o: 출력층의 출력 벡터
- 메모리 셀(RNN 셀): 각각의 시점(time step)에서 바로 이전 시점에서의 은닉층의 메모리 셀에서 나온 값을 자신의 입력으로 사용하는 재귀적 활동을 수행
(이전의 값을 기억하려고 하는 일종의 메모리 역할을 수행) - 은닉 상태(hidden state): 메모리 셀이 출력층 방향 또는 다음 시점인 t+1의 자신에게 보내는 값
- RNN의 은닉 유닛은 표준 신경망의 은닉 유닛과 달리, 두 개의 다른 입력을 받음
- 수식 정의

- ht: 현재 시점 t에서의 은닉 상태값
-> 이를 계산하고자 두 개의 가중치를 가짐- 입력층을 위한 가중치 Wx
- 이전 시점 t-1의 은닉 상태값인 ht-1을 위한 가중치 Wh
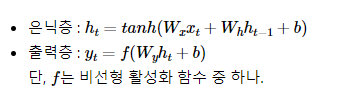
- ht: 현재 시점 t에서의 은닉 상태값
RNN에서 활성화함수로 tanh를 쓰는 이유 참고1 참고2
- 활성화 함수: 신경망 구조에서 입력값에 대해서 가중치를 곱한 후 적용하는 비선형 함수
- 사용 이유: 신경망 구조에서 비선형성을 추가해서 XOR 같은 비선형 문제를 해결하기 위해서(대다수의 문제가 비선형이어서 선형 함수로 해결할 수 없는 경우가 많다)
- 왜 tanh함수를 쓰는가? | “sigmoid에 비해 tanh 는 기울기가 0에서 1 사이이므로 Gradient Vanishing problem에 더 강하기 때문”
- sigmoid의 한계와 tanh의 등장
- sigmoid는 미분의 최대값은 0.25이기 때문에 깊어질 수록 vanishing 문제가 발생한다. 이를 해결하고자 Tanh를 만들었다. 이는 [-1,1]의 범위의 출력, 평균은 0으로 편향 이동 문제나 zig zag 현상을 해결하는데 쓰이는 방법이다. 더 나아가, 미분의 최대값이 1로 vanishing 문제를 해결한다.
- 그렇다면 Relu를 왜 안쓰는가?
- RNN은 이전 단계의 값을 가져와서 사용하므로, Relu를 쓰면 이전 값이 커짐에 따라 전체적인 출력이 발산할 수 있다. 따라서 RNN에서는 이를 normalizing하는 과정이 필요하며, sigmoid 보다 기울기의 역전파가 더 잘되는 tanh함수를 활성화 함수로 사용한다.
-
예시: 번역기
-> 입력: 번역하고자 하는 단어의 시퀀스인 문장
-> 출력: 해당되는 번역된 문장 또한 단어의 시퀀스 -
장점
- 입력, 출력 길이를 다르게 설계 가능
- 시퀀스 길이에 관계없이 인풋과 아웃풋을 받아들일 수 있는 네트워크 구조
-> 필요에 따라 다양하고 유연하게 구조를 만들 수 있음

-> 입력, 출력의 길이에 따라 달라지는 RNN의 형태
-
단점
- 그래디언트 배니싱, 그래디언트 익스플로딩 문제
: 역전파 시 그래디언트가 너무 작아지거나, 반대로 너무 커져서 학습이 제대로 이루어지지 않는 경우가 많음
-> 해결책: 중요한 정보를 기억하거나 불필요한 정보를 잊는 기능을 강화한 LSTM, GRU 등의 셀
- 그래디언트 배니싱, 그래디언트 익스플로딩 문제
RNN의 그래디언트 배니싱 문제 참고
- RNN은 학습할 때, 가중치 매개변수의 기울기를 효율적으로 계산할 수 있는 오차 역전파법(Backpropagation)을 사용
- 역전파: 인공신경망을 학습하기 위한 알고리즘으로, 역방향으로 해당 함수의 국소적 미분을 곱해 나가는 방법(출력하고자 하는 값과 실제 모델이 계산한 값이 얼마나 차이가 나는지 계산한 후, 그 오차 값을 다시 전달하고, 각 노드가 가진 값을 업데이트 하기 위한 알고리즘)
- RNN의 경우 시간 방향으로 펼친 신경망의 역전파를 수행 => BPTT(BackPropagation Through Time)
- 문제점: 데이터의 시간 크기가 커지는 것에 비례하여 BPTT가 소비하는 컴퓨팅 자원이 증가해, 역전파 시의 기울기가 불안정해짐.
- 해결책: 큰 데이터를 다룰 때는 신경망 연결을 적당한 길이로 자름: 잘라낸 신경망에서 역전파를 수행하는 과정- Truncated-BPTT

참고하면 좋을 자료: https://blog.floydhub.com/a-beginners-guide-on-recurrent-neural-networks-with-pytorch/
6.1 순환신경망
- RNN의 목적
- 시퀀스 텐서를 모델링하는 것(시퀀스 텐서의 학습)
- 가장 기본적인 형태 -> 엘만 RNN
- 엘만 RNN
- 시퀀스의 현재 상태를 감지하는 은닉 상태 벡터를 관리
- 현재 입력 벡터와 이전 은닉 상태 벡터로 은닉 상태 벡터를 계산
- 은닉 벡터가 예측 대상
- 같은 파라미터를 사용해 타임스텝마다 출력을 계산
(은닉상태 벡터에 의존해서 시퀀스의 상태 감지) - RNN의 목적: 주어진 은닉 상태 벡터와 입력 벡터에 대한 출력을 계산해 -> 시퀀스 불변성을 학습하자!
-> RNN은 시간을 따라서 파라미터 공유
-> CNN은 공간을 따라서 파라미터 공유
- 가변 길이 시퀀스
- 왜? 단어와 문장 길이가 다양해서
- 해결책: 시퀀스 길이를 동일하게 맞추자!
- 마스킹: 시퀀스 길이 정보를 이용해 가변 길이 시퀀스를 다루는 방법
(어떤 입력이 그레이디언트나 최종 출력에 포함되어서는 안 될 때 신호를 보낼 수 있음)
- 마스킹: 시퀀스 길이 정보를 이용해 가변 길이 시퀀스를 다루는 방법
6.1.1 엘만 RNN 구현하기
class ElmanRNN(nn.Module):
""" RNNCell을 사용하여 만든 엘만 RNN """
def __init__(self, input_size, hidden_size, batch_first=False):
"""
매개변수:
input_size (int): 입력 벡터 크기
hidden_size (int): 은닉 상태 벡터 크기
batch_first (bool): 0번째 차원이 배치인지 여부(True로 설정시, 입력 텐서의 0번쨰와 1번째 차원을 바꿈)
"""
super(ElmanRNN, self).__init__()
self.rnn_cell = nn.RNNCell(input_size, hidden_size)
self.batch_first = batch_first
self.hidden_size = hidden_size
def _initial_hidden(self, batch_size):
return torch.zeros((batch_size, self.hidden_size))
def forward(self, x_in, initial_hidden=None):
""" ElmanRNN의 정방향 계산
매개변수:
x_in (torch.Tensor): 입력 데이터 텐서
If self.batch_first: x_in.shape = (batch_size, seq_size, feat_size)
Else: x_in.shape = (seq_size, batch_size, feat_size)
initial_hidden (torch.Tensor): RNN의 초기 은닉 상태
반환값:
hiddens (torch.Tensor): 각 타임 스텝에서 RNN 출력
If self.batch_first:
hiddens.shape = (batch_size, seq_size, hidden_size)
Else: hiddens.shape = (seq_size, batch_size, hidden_size)
"""
if self.batch_first:
batch_size, seq_size, feat_size = x_in.size()
x_in = x_in.permute(1, 0, 2)
else:
seq_size, batch_size, feat_size = x_in.size()
hiddens = []
if initial_hidden is None:
initial_hidden = self._initial_hidden(batch_size)
initial_hidden = initial_hidden.to(x_in.device)
hidden_t = initial_hidden
for t in range(seq_size):
hidden_t = self.rnn_cell(x_in[t], hidden_t)
hiddens.append(hidden_t)
hiddens = torch.stack(hiddens)
if self.batch_first:
hiddens = hiddens.permute(1, 0, 2)
return hiddens- forward() 메서드
- 입력 텐서를 순회하면서 타임 스텝마다 은닉 상태 벡터를 계산
6.2 예제: 문자 RNN으로 성씨 국적 분류하기
6.2.1 SurnameDataset 클래스
- 데이터셋 클래스 만들기
-> 벡터로 변환된 성씨와 국적을 나타내는 정수 반환 + 시퀀스의 길이 반환(시퀀스에 있는 최종 벡터의 위치 파악에 사용)
class SurnameDataset(Dataset):
@classmethod
def load_dataset_and_make_vectorizer(cls, surname_csv):
"""데이터셋을 로드하고 새로운 Vectorizer 객체를 만듭니다
매개변수:
surname_csv (str): 데이터셋의 위치
반환값:
SurnameDataset의 객체
"""
surname_df = pd.read_csv(surname_csv)
train_surname_df = surname_df[surname_df.split=='train']
return cls(surname_df, SurnameVectorizer.from_dataframe(train_surname_df))
def __getitem__(self, index):
"""파이토치 데이터셋의 주요 진입 메서드
매개변수:
index (int): 데이터 포인트 인덱스
반환값:
다음 값을 담고 있는 딕셔너리:
특성 (x_data)
레이블 (y_target)
특성 길이 (x_length)
"""
row = self._target_df.iloc[index]
surname_vector, vec_length = \
self._vectorizer.vectorize(row.surname, self._max_seq_length)
nationality_index = \
self._vectorizer.nationality_vocab.lookup_token(row.nationality)
return {'x_data': surname_vector,
'y_target': nationality_index,
'x_length': vec_length}6.2.2 데이터 구조
- 성씨에 있는 각 문자 토큰을 고유한 정수에 매핑하기
- 추가적으로, 토큰 활용 하기
- UNK 토큰(필수): 입력에 어휘 사전에 없는 토큰이 있을 때 사용
- MASK 토큰(필수): 가변 길이 입력 처리에 사용
- BEGINOF-SEQUENCE 토큰: 시퀀스 앞에 추가해, 모델이 문장 경계 인식하도록 함
- END-OF-SEQUENCE 토큰: 시퀀스 뒤에 추가해, 모델이 문장 경계 인식하도록 함
class SurnameVectorizer(object): # 전체적인 벡터 변환 과정 수행
""" 어휘 사전을 생성하고 관리합니다 """
def vectorize(self, surname, vector_length=-1):
"""
매개변수:
title (str): 문자열
vector_length (int): 인덱스 벡터의 길이를 맞추기 위한 매개변수
"""
indices = [self.char_vocab.begin_seq_index]
indices.extend(self.char_vocab.lookup_token(token)
for token in surname)
indices.append(self.char_vocab.end_seq_index)
if vector_length < 0:
vector_length = len(indices)
out_vector = np.zeros(vector_length, dtype=np.int64)
out_vector[:len(indices)] = indices
out_vector[len(indices):] = self.char_vocab.mask_index
return out_vector, len(indices)
@classmethod
def from_dataframe(cls, surname_df):
"""데이터셋 데이터프레임으로 SurnameVectorizer 객체를 초기화합니다.
매개변수:
surname_df (pandas.DataFrame): 성씨 데이터셋
반환값:
SurnameVectorizer 객체
"""
char_vocab = SequenceVocabulary()
nationality_vocab = Vocabulary()
for index, row in surname_df.iterrows():
for char in row.surname:
char_vocab.add_token(char)
nationality_vocab.add_token(row.nationality)
return cls(char_vocab, nationality_vocab)6.2.3 SurnameClassifier 모델
- 구성
- 임베딩 층, ElmanRNN 층, Linear 층
- 모델 입력: SequenceVocabulary에서 정수로 매핑한 토큰
- 과정
- 임베딩 층으로 정수 임베딩
- RNN으로 시퀀스의 벡터 표현 계산(벡터는 성씨에 있는 각 문자에 대한 은닉상태)
- 성씨 분류 작업이므로, 성씨의 마지막 문자에 해당하는 벡터 추출
-> 최종 벡터가 전체 시퀀스의 입력을 거쳐 전달된 결과물(성씨를 요약한 벡터) - 요약 벡터를 Linear 층으로 전달해 예측 벡터를 계산
- 예측 벡터로 훈련 손실 계산 or 소프트맥스 함수 적용 -> 성씨에 대한 확률분포 생성
- 모델의 매개변수
- 임베딩 크기, 임베딩 개수(어휘사전 크기), 클래스 개수, RNN 은닉 상태 크기
-> 임베딩 개수와 클래스 개수는 데이터가 결정
- 임베딩 크기, 임베딩 개수(어휘사전 크기), 클래스 개수, RNN 은닉 상태 크기
class SurnameClassifier(nn.Module):
""" RNN으로 특성을 추출하고 MLP로 분류하는 분류 모델 """
def __init__(self, embedding_size, num_embeddings, num_classes,
rnn_hidden_size, batch_first=True, padding_idx=0):
"""
매개변수:
embedding_size (int): 문자 임베딩의 크기
num_embeddings (int): 임베딩할 문자 개수
num_classes (int): 예측 벡터의 크기
노트: 국적 개수
rnn_hidden_size (int): RNN의 은닉 상태 크기
batch_first (bool): 입력 텐서의 0번째 차원이 배치인지 시퀀스인지 나타내는 플래그
padding_idx (int): 텐서 패딩을 위한 인덱스;
torch.nn.Embedding을 참고하세요
"""
super(SurnameClassifier, self).__init__()
self.emb = nn.Embedding(num_embeddings=num_embeddings,
embedding_dim=embedding_size,
padding_idx=padding_idx)
self.rnn = ElmanRNN(input_size=embedding_size,
hidden_size=rnn_hidden_size,
batch_first=batch_first)
self.fc1 = nn.Linear(in_features=rnn_hidden_size,
out_features=rnn_hidden_size)
self.fc2 = nn.Linear(in_features=rnn_hidden_size,
out_features=num_classes)
def forward(self, x_in, x_lengths=None, apply_softmax=False):
""" 분류기의 정방향 계산
매개변수:
x_in (torch.Tensor): 입력 데이터 텐서
x_in.shape는 (batch, input_dim)입니다
x_lengths (torch.Tensor): 배치에 있는 각 시퀀스의 길이
시퀀스의 마지막 벡터를 찾는데 사용합니다
apply_softmax (bool): 소프트맥스 활성화 함수를 위한 플래그
크로스-엔트로피 손실을 사용하려면 False로 지정합니다
반환값:
결과 텐서. tensor.shape는 (batch, output_dim)입니다.
"""
x_embedded = self.emb(x_in)
y_out = self.rnn(x_embedded)
if x_lengths is not None:
y_out = column_gather(y_out, x_lengths)
else:
y_out = y_out[:, -1, :]
y_out = F.relu(self.fc1(F.dropout(y_out, 0.5)))
y_out = self.fc2(F.dropout(y_out, 0.5))
if apply_softmax:
y_out = F.softmax(y_out, dim=1)
return y_out- 이 때, forward를 시행하기 위해, 시퀀스 길이가 필요하다
-> column_gather()함수- 이 길이를 사용해 텐서에서 시퀀스마다 마지막 벡터를 추출하여 반환
- 배치의 행 인덱스를 순회하면서 시퀀스의 마지막 인덱스에 있는 벡터 추출
def column_gather(y_out, x_lengths):
''' y_out에 있는 각 데이터 포인트에서 마지막 벡터 추출합니다
조금 더 구체적으로 말하면 배치 행 인덱스를 순회하면서
x_lengths에 있는 값에 해당하는 인덱스 위치의 벡터를 반환합니다.
매개변수:
y_out (torch.FloatTensor, torch.cuda.FloatTensor)
shape: (batch, sequence, feature)
x_lengths (torch.LongTensor, torch.cuda.LongTensor)
shape: (batch,)
반환값:
y_out (torch.FloatTensor, torch.cuda.FloatTensor)
shape: (batch, feature)
'''
x_lengths = x_lengths.long().detach().cpu().numpy() - 1
out = []
for batch_index, column_index in enumerate(x_lengths):
out.append(y_out[batch_index, column_index])
return torch.stack(out)
6.2.4 모델 훈련과 결과
- 배치 데이터 하나에 모델 적용하고 예측 벡터 계산
- CrossEntropyLoss()함수와 정답으로 손실 계산
- 손실값과 옵티마이저로 그레이디언트 계산, 그레이디언트로 모델의 가중치 업데이트
-> 훈련 데이터에 있는 모든 배치에 반복(검증 데이터의 경우, 모델을 평가모드로 설정해 역전파를 끔, 편향되지 않은 모델의 성능을 얻는 목적으로만 사용)
