.gif)
🎤 세팅
window.SpeechRecognition = window.SpeechRecognition || window.webkitSpeechRecognition;
const recognition = new SpeechRecognition();
recognition.interimResults = true;🎧 SpeechRecognition
Web Speech API로, 음성인식
SpeechRecognition.interimResults
interim results는 최종이 아닌 중간 결과를 말하는 것으로, boolean 값을 반환한다.
이 값을 설정해주어야 음성인식이 끝나지 않아도 말하는 도중에 계속해서 스크립트가 작성된다.
🎧 SpeechRecognition: result event
speech recognition service가 결과를 리턴했을 때 이벤트가 발생한다.
여기서 말하는 결과란, 단어나 구가 정상적으로 인식되어 앱으로 전달되는 것을 말한다.
recognition.addEventListener('result', e => {
console.log(e);
})
recognition.start(); console.log(e)의 출력문은 다음과 같다.
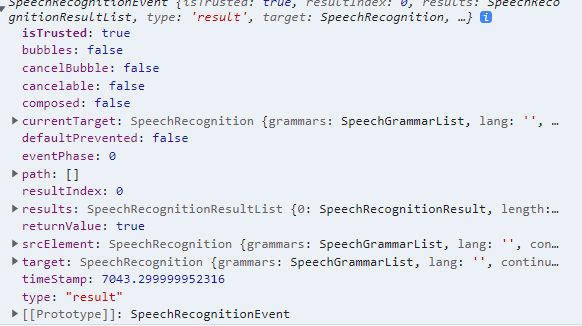
e.result를 보면
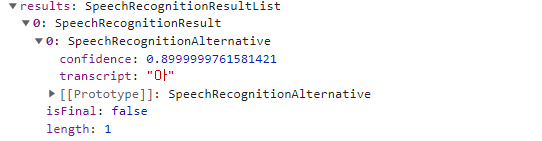
여기에 이렇게 transcript 란에 음성인식 결과가 들어있다.

🎤 화면에 출력하기
recognition.addEventListener('result', e => {
const transcript = Array.from(e.results)
.map(result => result[0])
.map(result => result.transcript)
.join('')
p.textContent = transcript;
})🎧 노드 추가하기
let p = document.createElement('p');
const words = document.querySelector('.words');
words.appendChild(p);🎧 음성인식된 문자를 조합해 문장으로 만들기
recognition.addEventListener('result', e => {
const transcript = Array.from(e.results)
.map(result => result[0])
.map(result => result.transcript)
.join('') e.results의 결과를 배열로 만든다.
results[0]이 SpeechRecognitionResult
results[0][0]이 SpeechRecognitionAlternative이다.
result.transcript에서 음성인식 된 내용을 가져와 병합한다.
병합한 내용은 p의 textContent로 할당해 화면에 표시되도록 한다.
여기까지 하면 음성인식은 한번만 진행되고 끝난다.
🎤 지속적으로 음성인식 하기
recognition.addEventListener('end', recognition.start);recognition이 끝날때마다 다시 시작시킨다.
음성인식은 한 번 말하고 나서는 종료되기 때문에 이렇게 해야 끊고 나서 다시 말해도 음성인식이 된다.
🎤 다시 말할 때 줄바꿈해 내용 적기
SpeechRecognitionResult.isFinal
음성인식이 끝났는지 여부를 불리언 값으로 반환한다.
var myIsFinal = speechRecognitionResultInstance.isFinal;
if(e.results[0].isFinal) {
p = document.createElement('p');
words.appendChild(p);
}한번 시작될 때 p태그를 새로 만든다음 노드에 추가해 인식 내용을 할당하기 때문에, 한번 끊고 말하면 다음 줄 새로운 텍스트 노드에 인식 내용이 표시된다.
🎤 음성인식
가장 흥미로웠던 부분이다. 주위에서 볼 수 있는 음성인식 기술을 구현해 볼 수 있다.
if(transcript.includes('get the weather')) {
console.log('geting the weather')
}transcript는 문자열 형태이니, 특정단어를 포함하는지 판별해 원하는 함수 혹은 API를 실행시킬 수 있다.
예를 들어, '날씨 알려줘'라는 단어를 들으면 날씨를 보여주는 기능을 구현해놓으면, 음성인식 기능이 구현되는 것이다.
Reference
