이터러블
이터러블
이터레이션 프로토콜 또한 ES6에서 도입되었다.
순회 가능한 자료구조를 만들기 위한 규칙인데, 핵심은 두 가지다.
이터러블 프로토콜 : Symbol.iterator를 프로퍼티 키로 사용한 메서드를 직접 구현하거나 Symbol.iterator 메서드를 상속받아 호출하면 이터레이터 프로토콜을 준수한 이터레이터를 반환한다. 이 규약을 이터러블 프로토콜이라고 하며 이것을 준수한 객체는 이터러블이다. for ... of 문으로 순회할 수 있다는 특징이 있으며 스프레드 문법과 배열 디스트럭처링 할당이 가능하다.
이터레이터 프로토콜 : 이터러블의 Symbol.iterator 메서드를 호출하면 이터레이터 프로토콜을 준수한 이터레이터를 반환한다. next 메서드를 소유하며 이것을 호출하면 순회하며 value와 done 프로퍼티를 갖는 이터레이터 리절트 객체를 반환하다. 이 규약을 이터레이터 프로토콜이라고 하며, 이것을 준수한 객체는 이터레이터이다. 이터러블의 요소를 탐색하기 위한 포인터 역할을 한다.
처음 이해하기에 조금 난해하다. 이터러블 객체에서 이터레이터 객체를 호출하면 이터레이터 객체에서 이터레이터 리절트 객체를 반환해주는데, 그것이 이터러블 객체의 요소를 순회하게 해주는 것이다. 아래의 사진을 보면 이해가 조금 쉬워질 것이다.
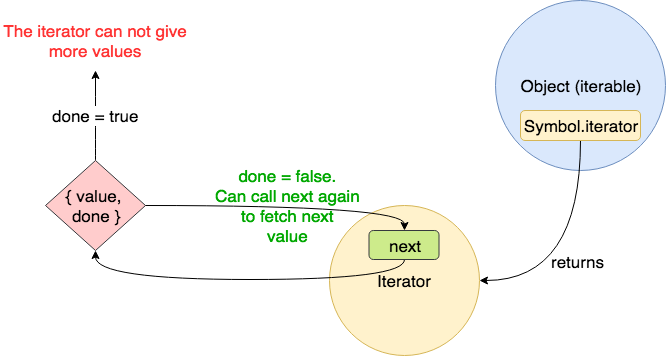
빌트인 이터러블에는 Array, String, Map, Set, TypedArray, arguments, DOM 컬렉션이 있다. 이것들은 기본적으로 이터레이션 프로토콜을 준수하고 있으므로 이터러블이다. 그렇지만 이것들을 제외하더라도 관계를 만들어서 직접 이터러블을 구현할 수 있다. 대표적으로 피보나치 수열 예제를 보자.
const fibo = {
[Symbol.iterator](){ // 이 메서드를 직접 구현하여 프로토콜을 준수하도록 한다.
let [pre, cur] = [0,1];
const max = 10;
return {
// Symbol.iterator 메서드는 next 메서드를 소유한 이터레이터를 반환해야 한다.
// next 메서드는 value, done을 소유한 이터레이터 리절트 객체를 반환해야 한다.
next() {
[pre, cur] = [cur, pre + cur];
return {value:cur,done:cur>=max};
}
};
}
};
for (const num of fibo){
// 이 상황에서, fibo 객체를 순회 할 때 마다 next 메서드가 호출된다.
// 호출 때마다 value가 들어가며 done 프로퍼티가 true가 되면 반복이 멈춘다.
console.log(num); // 1 2 3 5 8
}이 예제는 이터러블을 구현한 것이다. 대략적인 흐름을 눈으로 보고 이해했다면 조금 발전시켜보자.
// 이터러블이면서 이터레이터인 객체를 생성하는 예제
const fibo = function (max) {
let [pre, cur] = [0,1];
// Symbol.iterator 메서드와 next 메서드를 같이 반환한다.
// 그렇다면 두 가지 모두의 역할을 할 수 있다.
// 아래에선 메서드 내에서 this를 반환했기 때문에 this는 두 가지를 소유한 객체다.
return {
[Symbol.iterator](){ return this; },
next() {
[pre, cur] = [cur, pre + cur];
return {value:cur,done:cur>=max};
}
};
};
let iter = fibo(10);
for (const num of iter) {
console.log(num); // 1 2 3 5 8
}
iter = fibo(10); // 초기화 하지 않으면 값이 누적된다.
console.log(iter.next()); // {value: 1, done: false}
console.log(iter.next()); // {value: 2, done: false}
console.log(iter.next()); // {value: 3, done: false}
console.log(iter.next()); // {value: 5, done: false}
console.log(iter.next()); // {value: 8, done: false}
console.log(iter.next()); // {value: 13, done: true}스프레드 문법과 디스트럭처링 할당
위에서 언급한 스프레드 문법과 배열 디스트럭처링 할당에 대해서 잠깐 짚고 넘어가자.
이것들은 모두 이터러블에서 사용할 수 있는 문법이다. 유사 배열 객체와 다름을 알아두자.
먼저 스프레드 문법은 이전에 살펴본 Rest 파라미터와 비슷하게 생겼지만 반대의 역할을 한다.
Rest 파라미터는 함수에서 인수들의 목록을 배열로 전달받기 위한 것이었지만 스프레드 문법은 값이 모여있는 이터러블을 펼쳐서 개별적인 값의 목록으로 만들어 주는 것이다.
디스트럭처링 할당은 이터러블을 디스트럭처링하여 1개 이상의 변수에 개별적으로 할당하는 것을 말한다.
두 가지 다 예시로 간단하게 알아보자.
function sum(){
return [...arguments].reduce((pre,cur) => pre + cur, 0);
}
console.log(sum(1,2,3)); // 6
function parseURL(url = ''){
const parsedURL = url.match(/^(\w+):\/\/([^/]+)\/(.*)$/);
// 정규표현식 내에서 괄호를 사용하면 그 부분을 별도로 대응하며 그것을 기억한다.
// 이 경우, 원본 URL이 패턴과 일치하기 때문에 그것이 [0], :// 이전의 문자열이 [1] 이런 식으로 들어간다.
console.log(parsedURL);
if (!parsedURL) return {};
const [,protocol,host,path] = parsedURL; // 이처럼 띄엄띄엄 할당도 가능하다.
return {protocol,host,path};
}
const parsedURL = parseURL('https://developer.mozilla.org/ko/docs/Web/javaScript');
console.log(parsedURL);
/*
{protocol:'https',
host:'developer.mozilla.org',
path:'ko/docs/Web/javaScript'
}
*/