개요
프로젝트를 진행하면서 Auto Increment를 PK로 사용할 때 발생할 수 있는 문제점을 알게 되었다.
Auto Increment는 1234와 같이 사람이 알기 쉬운 데이터이다. 따라서 유저가 API 요청을 보낼 때 게시물과 같은 데이터의 ID를 임의로 지정해 요청한다면, 예외처리가 되어있지 않은 경우 전혀 다른 데이터에 영향을 줄 수 있다.
이를 방지하기 위해 사용자가 파악하기 어려운 랜덤값을 가지는 UUID를 pk로 사용하는 것을 고려해보았다.
UUID를 PK로 사용하기
UUID
UUID(Universally Unique Identifier)는 RFC 4122 표준에 정의된 128비트 값을 나타낸다.
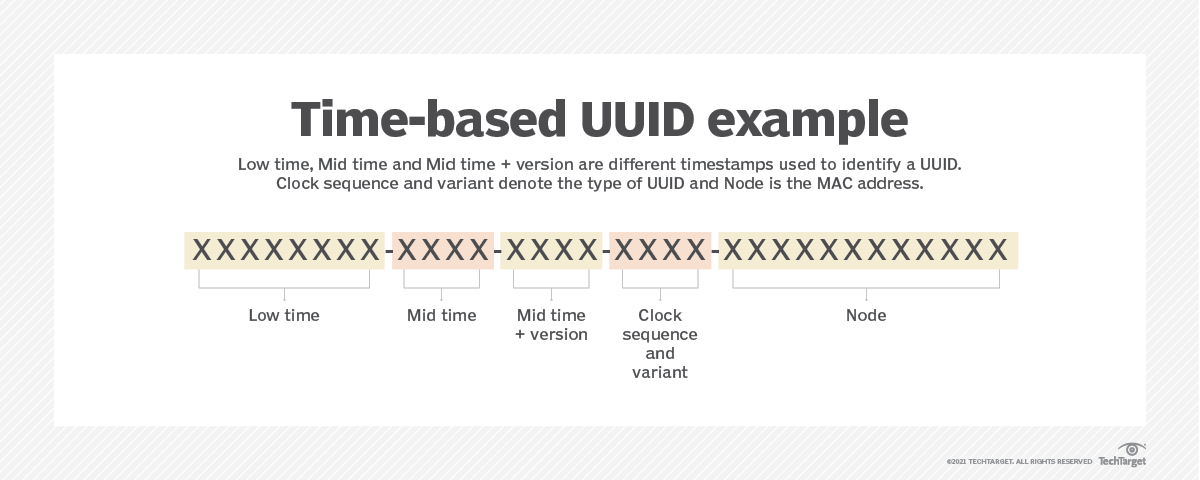
UUID는 32개의 문자와 4개의 하이픈으로 구성된 문자열로 8-4-4-4-12 형태로 이루어져 있다.
UUID의 총 생성 가능 갯수는 340,282,366,920,938,463,463,374,607,431,768,211,456개로 중복값이 생길 가능성은 희박하다.
UUID를 PK로 사용한다면?
장점
유저가 데이터베이스의 PK를 파악해 위와 같은 API의 취약점을 회피할 수 있다는 장점이 있다. 또한 서로 키값의 중복이나 충돌없이 데이터를 병합할 수 있다는 장점이 있다.
단점
UUID는 32자리 문자열로 이루어져있기 때문에 BIGINT PK에 비해 더 많은 디스크를 차지하게 된다. 인덱스는 PK의 크기를 기준으로 만들어지므로 인덱스의 용량도 증가해 메모리를 많이 차지한다.
UUID는 랜덤한 값이므로 데이터를 정렬하기가 어렵다. 시간 별로 데이터를 정렬하는 방법을 따로 구현해야 한다.
해결방법
프로그램 설계에 있어 가장 좋은 방법은 어떠한 방식을 사용하든 PK는 외부에 노출되지 않는 것이라고 한다.
따라서 PK와 UUID를 모두 사용해 정수형 Increment를 PK로 데이터를 관리하고 외부에 노출시키는 ID는 UUID를 사용한다.
UUID를 URL에 사용하기
UUID를 URL에 그대로 사용한다면 eunyeop.com/76800dcd-6a00-4a9c-bae4-096d95ed7082 같은 형태이므로 가독성이 매우 떨어진다. 이때 Slug를 만든다면 좀 더 가독성이 높은 형태로 사용할 수 있다.
이를 위한 대안으로 유투브에서 사용하는 Base64uid가 있다.
https://github.com/gpslab/base64uid
이 라이브러리는 64개의 문자를 사용해 길이 10개로 구성된 고유 식별자를 생성한다. 길이는 변경 가능하며 UUID보다 훨씬 짧은 길이의 랜덤 식별자를 생성할 수 있다.
PostgreSQL에서 UUID 사용하기
PostgreSQL은 자체적으로 UUID 데이터 타입을 제공한다. 또한 UUID를 생성하는 함수 get_random_uuid()를 제공한다.
이 함수는 version 4 UUID를 생성해 반환한다. 다른 버전의 UUID를 사용하고 싶다면 uuid-ossp 모듈을 사용하면 된다.
데이터를 삽입할 때마다 UUID가 생성되도록 하려면 해당 컬럼의 DEFAULT를 get_random_uuid()로 설정하면 된다.
References
https://www.postgresql.org/docs/current/functions-uuid.html
https://www.baeldung.com/uuid-vs-sequential-id-as-primary-key
https://tomharrisonjr.com/uuid-or-guid-as-primary-keys-be-careful-7b2aa3dcb439
