가시다 님이 진행하시는 AWS EKS WorkShop Study - AEWS 3기에 합류하여 학습한 내용을 시리즈로 정리합니다.
해당 시리즈는 EKS 관련 주요 지식과, 실습에 대한 내용이 담겨있습니다.
EKS 아키텍처 - Docs
1. 컨트롤 플레인
- 분산 구성 요소
- 복원성
- 가동 시간(SLA)
- AWS Managed VPC: AWS 리전 내 AWS 가용 성 영역 3개에 걸쳐, 최소 2개의 API 서버 인스턴스와 3개의 etcd 인스턴스를 배치합니다.
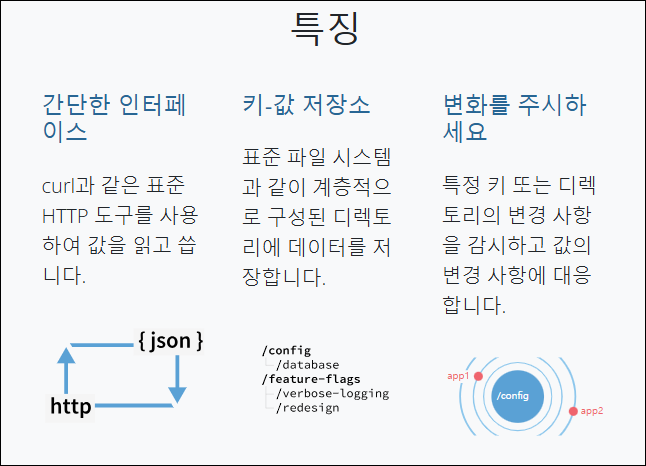
ETCD란?
- etcd는 분산 시스템이나 머신 클러스터에서 액세스해야 하는 데이터를 저장하는 안정적인 방법을 제공하는 강력하게 일관성 있는 분산 키-값 저장소
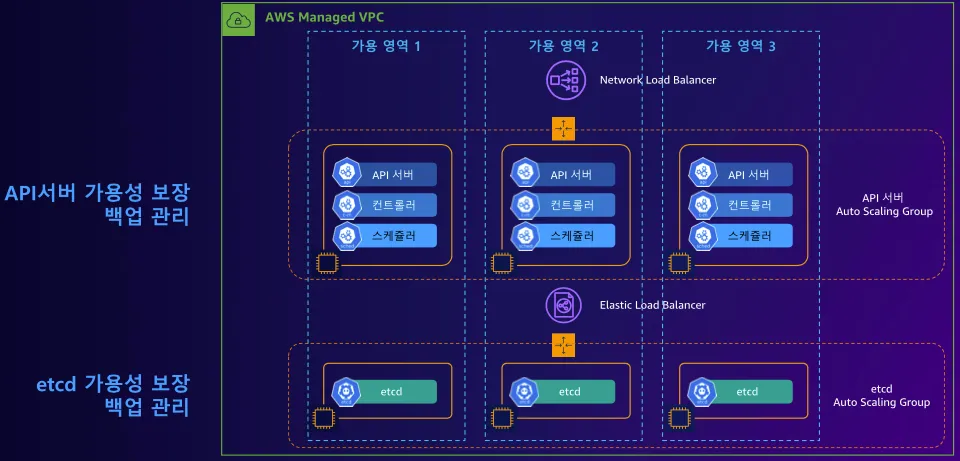 위 이미지처럼, 컨트롤 플레인을 고가용성으로 구성한 아키텍처처럼, AWS EKS에서는 컨트롤 플레인을 외부에 노출할 때, NLB를 사용하고 있습니다.
위 이미지처럼, 컨트롤 플레인을 고가용성으로 구성한 아키텍처처럼, AWS EKS에서는 컨트롤 플레인을 외부에 노출할 때, NLB를 사용하고 있습니다.
- 그럼 API 부하 분산을 ALB가 아닌 NLB로 사용하는 이유가 무엇일까요?
저의 추측은 아래와 같습니다.- 프로토콜 호환성 지연 측면
-> Kube-apiserver는 통신 시 HTTP(S)뿐 아니라 WebSocket이나 기타 프로토콜 업그레이드를 사용할 수 있습니다. 그렇기에, L4 Layer인 NLB는 Packet 레벨에서 빠르게 연결을 전달할 수 있기에 - 고성능
-> NLB는 초당 수백만 개 이상의 요청 처리가 저지연으로 가능합니다. k8s API Server는 다수의 클라이언트(kubelet, kubectl, 컨트롤러 등)과 지속적으로 통신해야하기에 높은 처리량 및 저지연이 중요합니다. - Kubernetes 1.31: SPDY에서 WebSockets로의 스트리밍 전환(?)
-> SPDY -> WebSocket과 같은 업그레이드 시, 복잡한 L7 처리에 로드벨런서가 건드리지 않도록 하여, 안정적으로 서비스 제공이 가능하도록 한 것이 아닐까?
또한, NLB는 단순히 TCP/UDP 계층에서 트래픽을 중계하므로, 장기간 유지되는 WebSocket 연결에 유리하다고 추측했습니다.
- 프로토콜 호환성 지연 측면
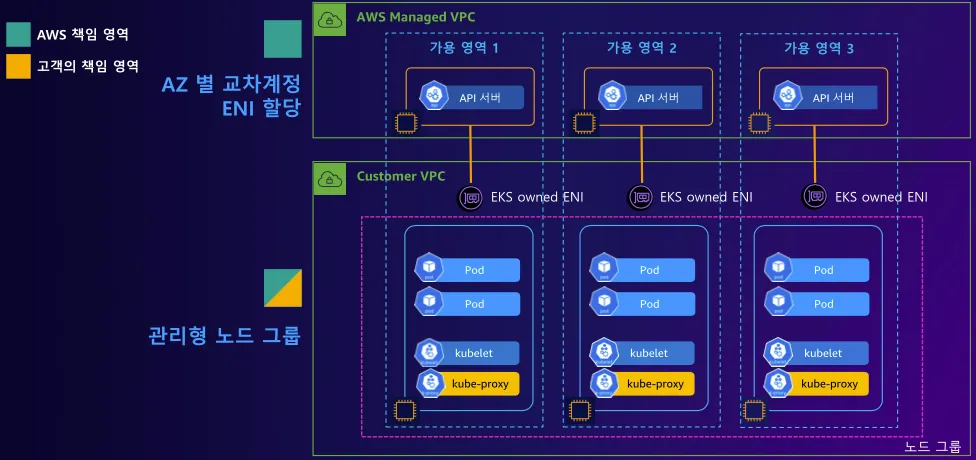
2. 데이터 플레인 - Docs
데이터 플레인에는 여러 노드 유형이 존재하며, 비교적 최근에 추가된 AWS Auto Mode등이 있습니다.
아래 아키텍처에서 주목해야할 점은 "EKS owned ENI" 입니다.
EKS owned ENI는 사용자의 VPC에 존재하며, AWS Managed VPC의 API 서버와 통신하는 구조입니다.
EKS 관리형 노드 그룹 사용 시, Spot 인스턴스를 사용하고 계신가요? 비용 절감 결과나 주의사항이 있나요?
- Spot 인스턴스 사용 시, 온디멘드 대비 70% 이상의 비용 절감 효과를 누릴 수 있는 경우도 존재하는 것처럼, 굉장한 제안이 될 수 있습니다.
하지만, 저렴한 이유가 있는데, Spot 타입은 AWS에서 남는 수량을 잠깐 대여해주는 것으로, 타 사용자가 해당 수량을 온디맨드 타입 등으로 대여시, 불시에 사용중인 노드가 중단될 가능성이 존재합니다.- 참고로 Spot by NetApp라는 서비스에선, 위와 같은 단점을 잘 보완하여 spot 타입을 사용하더라도 좋은 퍼포먼스를 보여줄 수 있도록 설계된 서비스가 있으니 참고해보시기 바랍니다.
EKS Cluster Endpoint
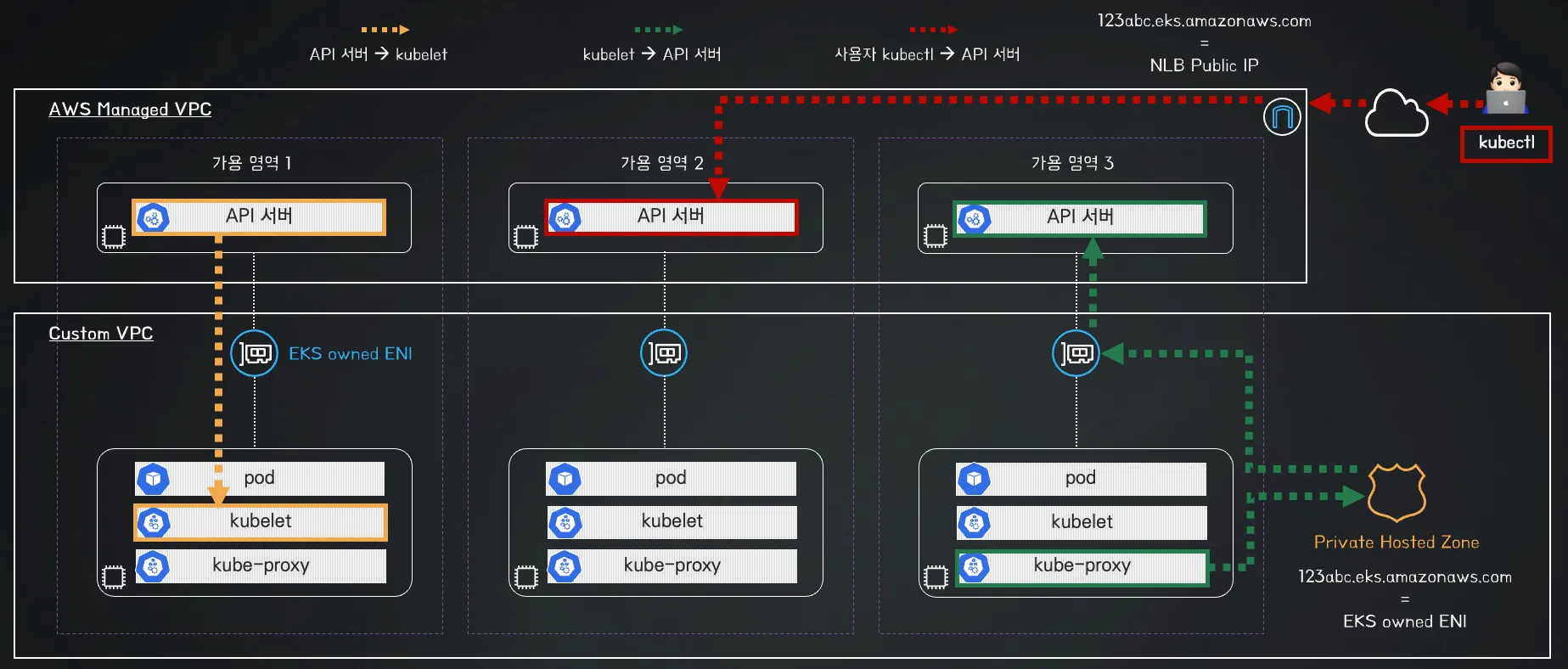
AWS EKS에는 Cluster Endpoint를 어떤 방식으로 노출할지 선택하는 옵션이 크게 세 가지 있습니다.
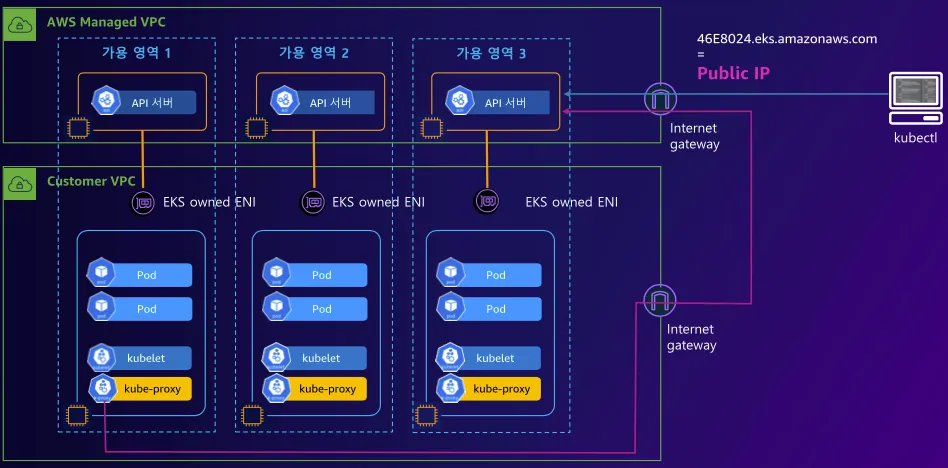
- Public
: 제어부 → (EKS owned ENI) 워커노드 kubelet, 워커노드 → (퍼블릭 도메인) 제어부, 사용자 kubectl → (퍼블릭 도메인) 제어부
<시나리오>
1. 제어부(컨트롤 플레인) 주소가 공인 도메인(예: xxxxx.eks.amazonaws.com) 으로 노출됨
2. 사용자의 kubectl 은 인터넷을 통해 이 공인 도메인으로 직접 접속
3. 워커 노드(EC2나 Fargate)는 내부적으로 EKS가 관리하는 ENI(EKS owned ENI) 를 통해 제어부와 통신
4. 즉, 워커 노드는 사설망(VPC) 안에 있지만, 제어부 주소는 공인이라서 외부에서 접근 가능 (SG/네트워크 정책에 따라 제한 가능)
장점: 설정 간단, 어디서나 인터넷 연결만 있으면 접근 가능
주의: 공인 도메인으로 노출되므로, 보안상 IP 제한·Security Group·인증/인가 설정이 중요
- Public, Private
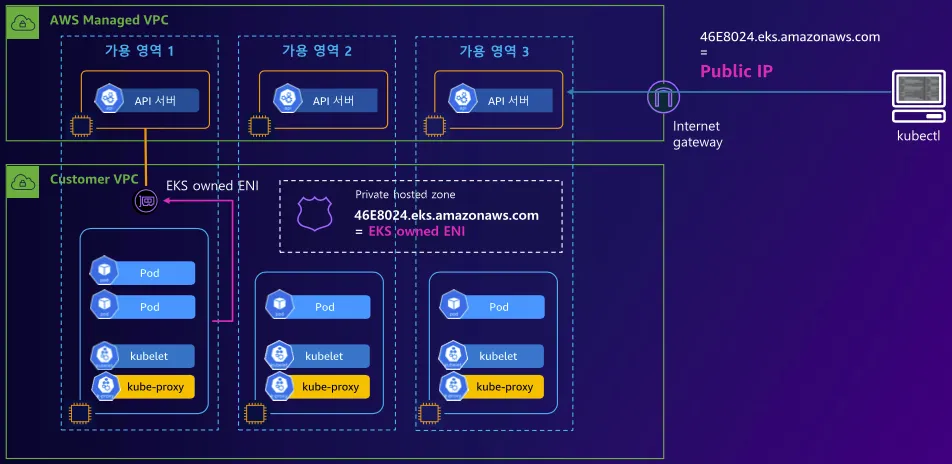
: 제어부 → (EKS owned ENI) 워커노드 kubelet, 워커노드 → (프라이빗 도메인, EKS owned ENI) 제어부, 사용자 kubectl → (퍼블릭 도메인) 제어부
<시나리오>
1. 제어부는 공인 도메인과 사설 도메인(프라이빗 IP/도메인) 둘 다를 가진다
2. 워커 노드 → 제어부 통신: 사설망(VPC) 내부 IP를 통해 프라이빗하게 접근 (Private Endpoint)
3. 사용자(kubectl) → 제어부: 기본은 여전히 공인 도메인으로 접근 가능
4. 필요 시, Public Endpoint에 “특정 IP만 허용” 같은 퍼블릭 액세스 제한도 가능
VPC 안에서 Private DNS를 통해 사설 엔드포인트로 접근 가능(옵션)
장점: 워커 노드는 사설 경로로 제어부와 통신 (인터넷을 거치지 않음), 운영자(kubectl)는 내부망 또는 외부망 어느 쪽에서도 필요 시 접근 가능
주의: 공인 도메인이 살아 있기 때문에, 엄격히 내부 전용으로 잠그지는 못함 (단, 퍼블릭 액세스 제한 설정은 가능)
동일한 API (도메인) 주소에 대해서 VPC 내부와 외부(인터넷)에서 각기 다른 IP 정보를 응답을 가능한 기술 방법은?
- Split-horizon DNS 혹은 이중 DNS 기법이라 함
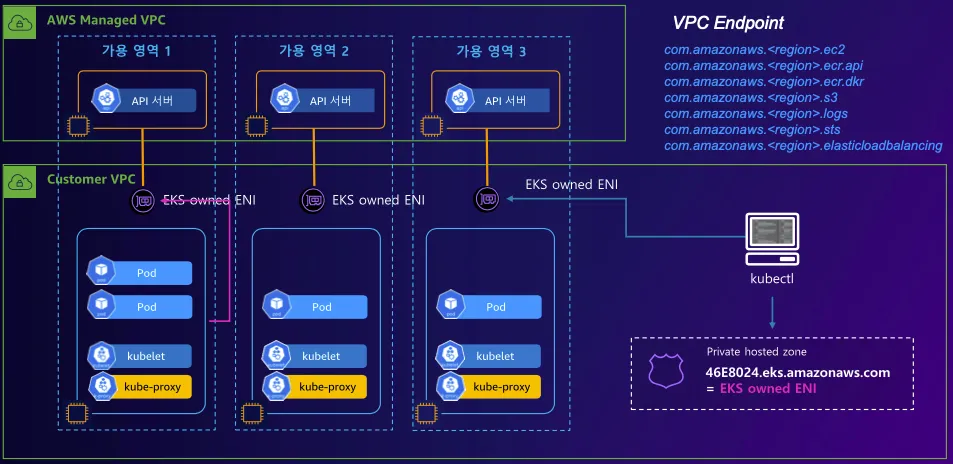
- Private(Fully-Private)
: 제어부 → (EKS owned ENI) 워커노드 kubelet, 워커노드,사용자 kubectl → (프라이빗 도메인, EKS owned ENI) 제어부
<시나리오>
1. 제어부가 사설 도메인으로만 노출됨 → 공인 도메인 없음
2. 사용자(kubectl) 은 VPC 내 혹은 VPN/Direct Connect 등을 통해서만 제어부에 연결
3. 퍼블릭 인터넷에서는 도메인 자체가 라우팅되지 않음
4. 워커 노드는 마찬가지로 EKS owned ENI를 통해 사설 경로로 제어부와 통신
장점: 외부(인터넷)에서 전혀 접근할 수 없어 보안 수준이 가장 높음
주의: kubectl 등 관리자가 클러스터에 접속하려면 반드시 사설망(VPC 내부)이거나, 온프레미스→VPC VPN/전용선이 필요. CI/CD나 외부 툴에서 접근할 때도 프라이빗 연결이 필수이므로 네트워크 구성이 상대적으로 복잡해질 수 있음
kubectl exec 나 logs 명령 실행 시 요청과 실행 과정의 flow는 어떻게 될까요? - Link
1. kubectl을 통해 사용자가 명령을 요청하여, kube-apiserver로 전송
2. kube-apiserver는 명령의 대상이 될 노드/파드 컨테이너를 식별
3. 대상 노드의 kubelet에게 스트리밍 세션을 오픈 지시
4. 노드 kubelet은 파드 컨테이너 런타임에게 요청하여 명령을 수행
5. 해당 명령 스트림에 대한 내용이 kubelet -> kube-apiserver -> kubectl 방향으로 전달되어 출력참고할 점?
- 통신 프로토콜
kube-apiserver <> kubelet 간에는 SPDY or WEBSocket/HTTP2와 같이 스트리밍이 가능한 프로토콜이 사용되어 exec 같은 양방향 인터렉션을 지원이 되는 것- 보안/권한
API server는 RBAC 등을 통해, kubectl exec/logs 명령을 호출하는 사용자가 적절한 권한이 있는지 파악
kubelet도 요청을 받을 때, 자체적으로 해당 요청이 API server로부터 온 것인지 확인
EKS 배포 실습
AEWS 스터디에서 제공된 CloudFormation을 통해 손쉽게 EKS 환경에 필요한 인프라 리소스를 구축할 수 있었으며, 구성된 리소스는 아래와 같습니다.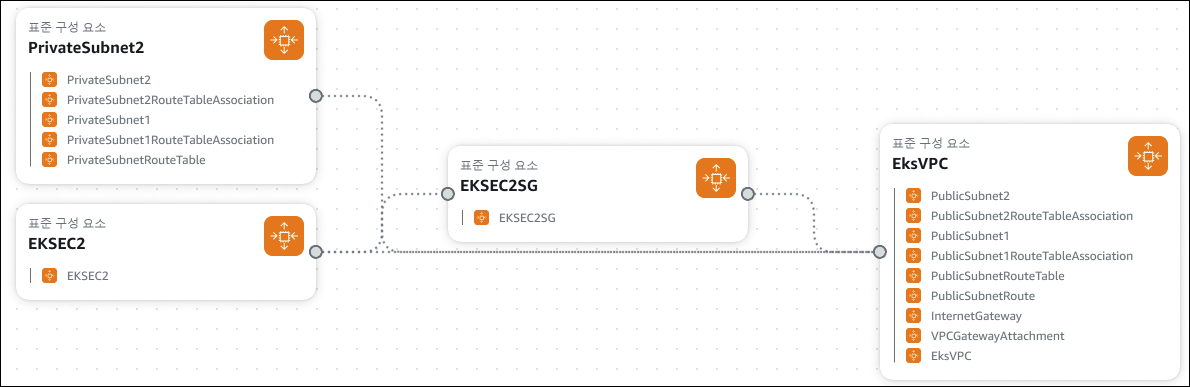
- EC2에 SSH로 접근한 후, eksctl 도구로 EKS 배포
- aws configure 같은 세부 설정은 설명은 생략합니다.
eksctl create cluster --name $CLUSTER_NAME --region=$AWS_DEFAULT_REGION --nodegroup-name=$CLUSTER_NAME-nodegroup --node-type=t3.medium \
--node-volume-size=30 --vpc-public-subnets "$PubSubnet1,$PubSubnet2" --version 1.31 --ssh-access --external-dns-access --verbose 4- EKS 정보 확인
## dig 조회 : 해당 IP 소유 리소스는 어떤것일까요? : 자신의 PC에서도 해당 도메인 질의 조회 해보자
APIDNS=$(aws eks describe-cluster --name $CLUSTER_NAME | jq -r .cluster.endpoint | cut -d '/' -f 3)
dig +short $APIDNSdig 조회 시, IP가 두 개 조회되는데, 이는 EKS 클러스터 엔드포인트인 API Server에 대한 Public IP주소입니다.

데이터 플레인 노드 정보 상세 확인 실습
- 노드 SSH 접속
# 노드 IP 확인 및 PrivateIP 변수 지정
aws ec2 describe-instances --query "Reservations[*].Instances[*].{PublicIPAdd:PublicIpAddress,PrivateIPAdd:PrivateIpAddress,InstanceName:Tags[?Key=='Name']|[0].Value,Status:State.Name}" --filters Name=instance-state-name,Values=running --output table
kubectl get node --label-columns=topology.kubernetes.io/zone
kubectl get node --label-columns=topology.kubernetes.io/zone --selector=topology.kubernetes.io/zone=ap-northeast-2a
kubectl get node --label-columns=topology.kubernetes.io/zone --selector=topology.kubernetes.io/zone=ap-northeast-2c
N1=$(kubectl get node --label-columns=topology.kubernetes.io/zone --selector=topology.kubernetes.io/zone=ap-northeast-2a -o jsonpath={.items[0].status.addresses[0].address})
N2=$(kubectl get node --label-columns=topology.kubernetes.io/zone --selector=topology.kubernetes.io/zone=ap-northeast-2c -o jsonpath={.items[0].status.addresses[0].address})
echo $N1, $N2
echo "export N1=$N1" >> /etc/profile
echo "export N2=$N2" >> /etc/profile- eksctl-host 에서 노드의IP나 coredns 파드IP로 ping 테스트
ping 테스트 시, 응답이 없다. 이유는? SSH 접속중인 EC2의 ip가 노드 보안 그룹에 없기 때문입니다.
ping <IP>
ping -c 1 $N1
ping -c 1 $N2- EC2 ip를 노드 보안 그룹에 추가
아래 명령을 보면 알겠지만, 인프라를 배포했던 cloudformation에 EC2 IP는 "192.168.1.100/32"로 고정되어 있습니다.
# 노드 보안그룹 ID 확인
aws ec2 describe-security-groups --filters Name=group-name,Values=*nodegroup* --query "SecurityGroups[*].[GroupId]" --output text
NGSGID=$(aws ec2 describe-security-groups --filters Name=group-name,Values=*nodegroup* --query "SecurityGroups[*].[GroupId]" --output text)
echo $NGSGID
echo "export NGSGID=$NGSGID" >> /etc/profile
# 노드 보안그룹에 eksctl-host 에서 노드(파드)에 접속 가능하게 룰(Rule) 추가 설정
aws ec2 authorize-security-group-ingress --group-id $NGSGID --protocol '-1' --cidr 192.168.1.100/32
다시 ping 테스트 시, 정상 응답 확인이 됩니다.
- 노드 SSH 접속
ssh -i ~/.ssh/id_rsa -o StrictHostKeyChecking=no ec2-user@$N1 hostname
ssh -i ~/.ssh/id_rsa -o StrictHostKeyChecking=no ec2-user@$N2 hostname
ssh ec2-user@$N1
ssh ec2-user@$N2파드 정보 확인 시, 온프레미스 쿠버네티스의 파드 배치와 EKS가 다른점은?
- EKS owned ENI 확인

kubelet, kube-proxy 통신 Peer Address는 어디인가요?
- 아래 명령 수행 시, 이전에 확인한 API Server의 IP와 동일한 것을 알 수 있다.
for i in $N1 $N2; do echo ">> node $i <<"; ssh ec2-user@$i sudo ss -tnp; echo; done
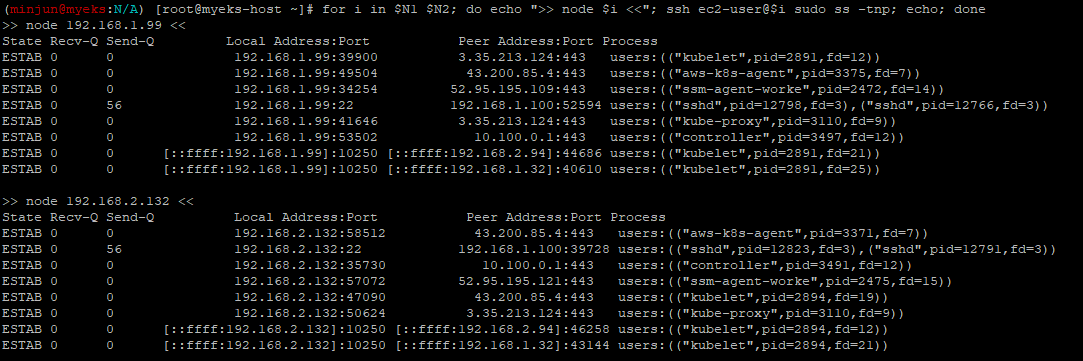
❗또한, 위에서 확인할 수 있는 주요 연결은 아래와 같습니다.
-
kubelet → EKS Control Plane
192.168.1.99:39900 -> 3.35.213.124:443
노드에서 동작하는 kubelet이 컨트롤 플레인(API Server)에 주기적으로 상태 보고를 하거나, Pod 생성/삭제 등의 명령을 받기 위해 연결합니다. -
kube-proxy → EKS Control Plane
192.168.1.99:41646 -> 3.35.213.124:443
서비스(ClusterIP 등) 관련 정보를 받아 iptables/ipvs 등을 업데이트하기 위해 kube-proxy도 API Server와 통신합니다. -
10.100.0.1:443 (Service IP)
로그에 보이는 Local Address:Port -> 10.100.0.1:443 형태는,
보통 Kubernetes라는 이름을 가진 기본 Service(클러스터 IP가 10.100.0.1)로 등록된 API Server에 접근하는 트래픽입니다.
클러스터 내부에서 kubernetes.default.svc 주소로 API Server에 접근할 때 이 IP가 사용됩니다.
- [터미널] 파드 1곳에 shell 실행해두기
kubectl 명령으로 특정 파드에 접근 (경로) : 작업PC -> API Server -> kubelet -> pod
kubectl run -it --rm netdebug --image=nicolaka/netshoot --restart=Never -- zsh
$ ip -c a
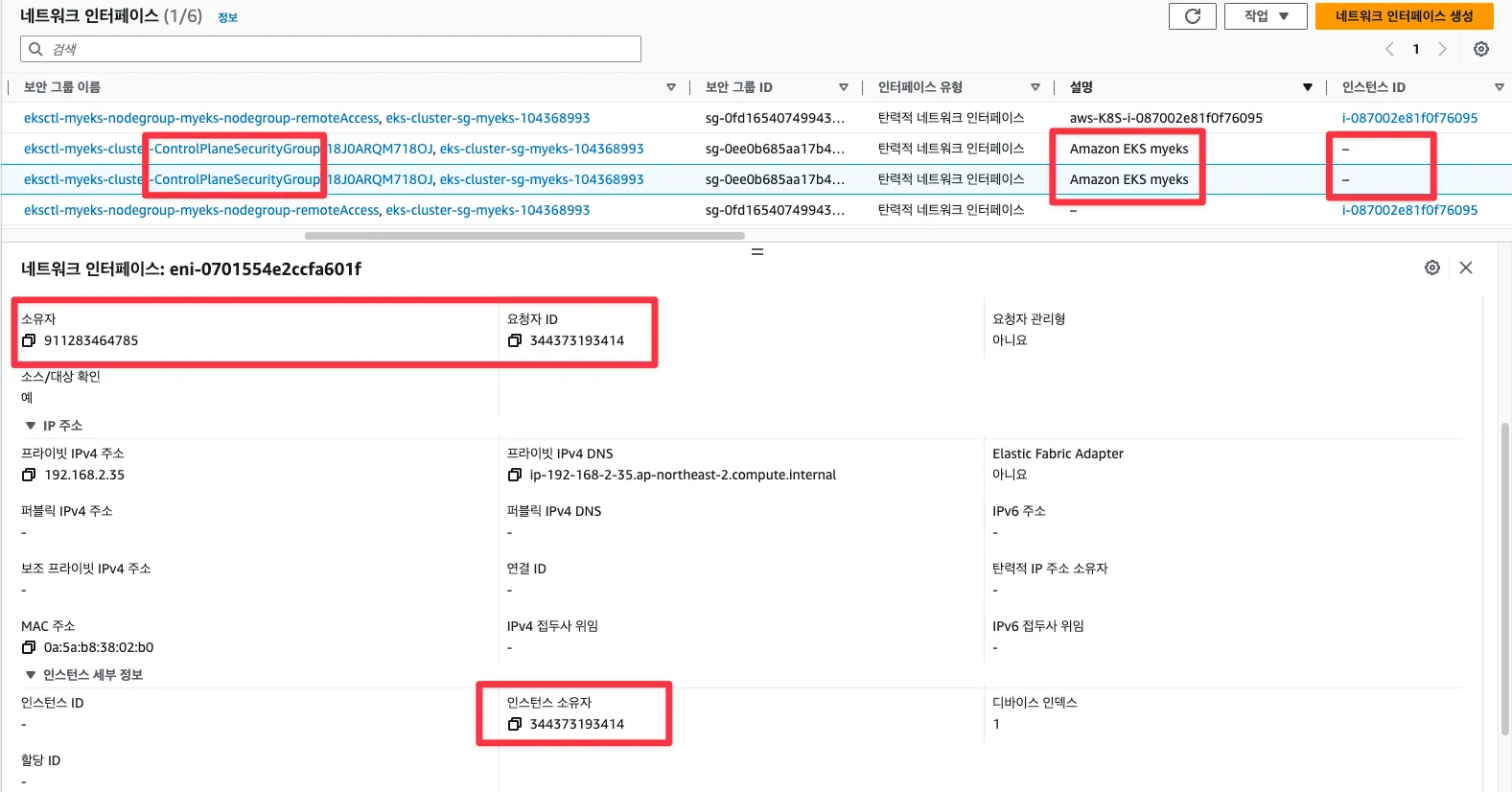
$ watch uptime- exec 실행으로 추가된 연결 정보의 Peer Address는 어딘인가요? + AWS 네트워크 인터페이스 ENI에서 해당 IP 정보 확인
for i in $N1 $N2; do echo ">> node $i <<"; ssh ec2-user@$i sudo ss -tnp; echo; done
ESTAB 0 0 [::ffff:192.168.2.132]:10250 [::ffff:192.168.2.113]:44986 users:(("kubelet",pid=2894,fd=22))
⁉️Network Interface 중, EKS Owned ENI를 살펴보면, 소유자는 저의 계정이며, 요청자는 AWS로 각각 다릅니다.
이유가 뭘까요? EKS는 사용자 계정 내에서 동작하지만, EKS 매니지드 서비스인 컨트롤 플레인에 필요한 ENI, SG등의 리소스가 필요하게 됩니다.
그렇기에, 해당 리소스들이 실제 소유자는 사용자이지만, 생성 요청은 AWS이기에 이렇게 표시되는 것입니다.
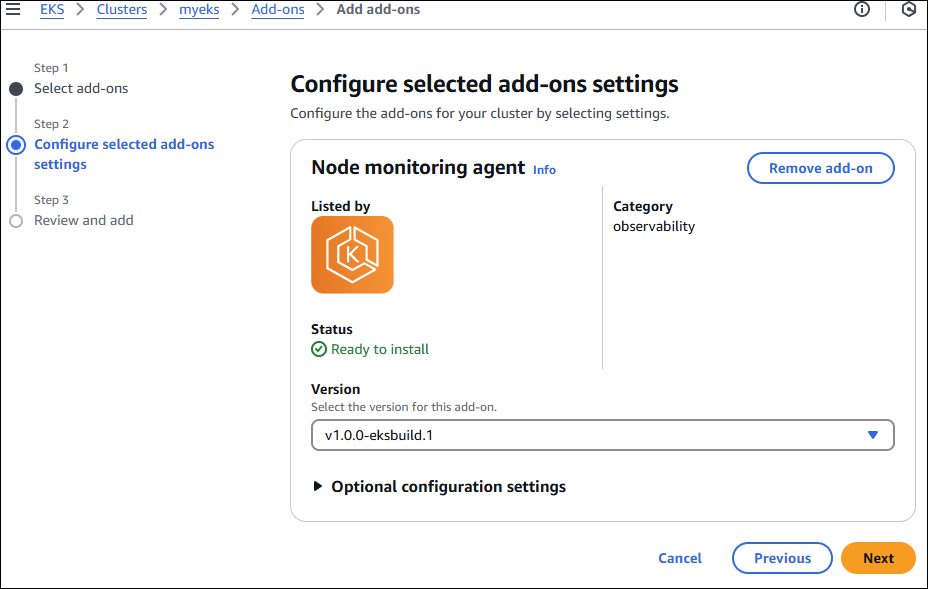
[Add-on] eks-node-monitoring-agent - Link
EKS Cluster Add-on으로 eks-node-monitoring-agent를 구성합니다.
해당 에드온은 EKS Node의 상태를 확인 가능합니다.
- 해당 명령으로 설치를 확인합니다.
watch -d kubectl get pod -n kube-system에드온 설치 후, 노드를 확인 시, 기존의 정보보다 다양한 사항을 확인 가능합니다.
kubectl get nodes -o 'custom-columns=NAME:.metadata.name,CONDITIONS:.status.conditions[*].type,STATUS:.status.conditions[*].status'
NAME CONDITIONS STATUS
ip-192-168-1-99.ap-northeast-2.compute.internal MemoryPressure,DiskPressure,PIDPressure,Ready,KernelReady,ContainerRuntimeReady,StorageReady,NetworkingReady False,False,False,True,True,True,True,True
ip-192-168-2-132.ap-northeast-2.compute.internal MemoryPressure,DiskPressure,PIDPressure,Ready,KernelReady,ContainerRuntimeReady,StorageReady,NetworkingReady False,False,False,True,True,True,True,True쿠버네티스 노드 헬스체크 원리(lease API)
헬스체크 방식에는 크게 두 가지 방법이 있습니다.
-
Node 상태(.status) 업데이트
노드가 자신에게 어떤 변화가 있을 때(예: CPU나 메모리가 많이 변동됨)나 5분 정도 지나면,
쿠버네티스 API 서버에 “나 상태 좋아요!”라고 상태를 저장해둡니다.
그런데 5분은 좀 길 수도 있어서, 노드가 갑자기 꺼졌을 때 빠르게 알아차리기 어렵다는 단점이 있습니다. -
Lease(리스) 객체 활용
“리스(Lease)”를 간단히 말하면, “책을 빌리고 일정 시간마다 연장하는 것”과 비슷합니다.
노드는 10초마다 “내가 아직 살아 있어요”라며 쿠버네티스 API 서버에 리스 시간을 갱신하게 됩니다.
만약 이 갱신이 40초(기본값) 넘게 없으면, “어? 노드가 다운된 것 같네?” 하고 API 서버는 판단하게 됩니다.
이렇게 10초마다 짧게 짧게 “정상” 신호를 보내니, 노드 이상을 더 빠르게 감지할 수 있게 됩니다.
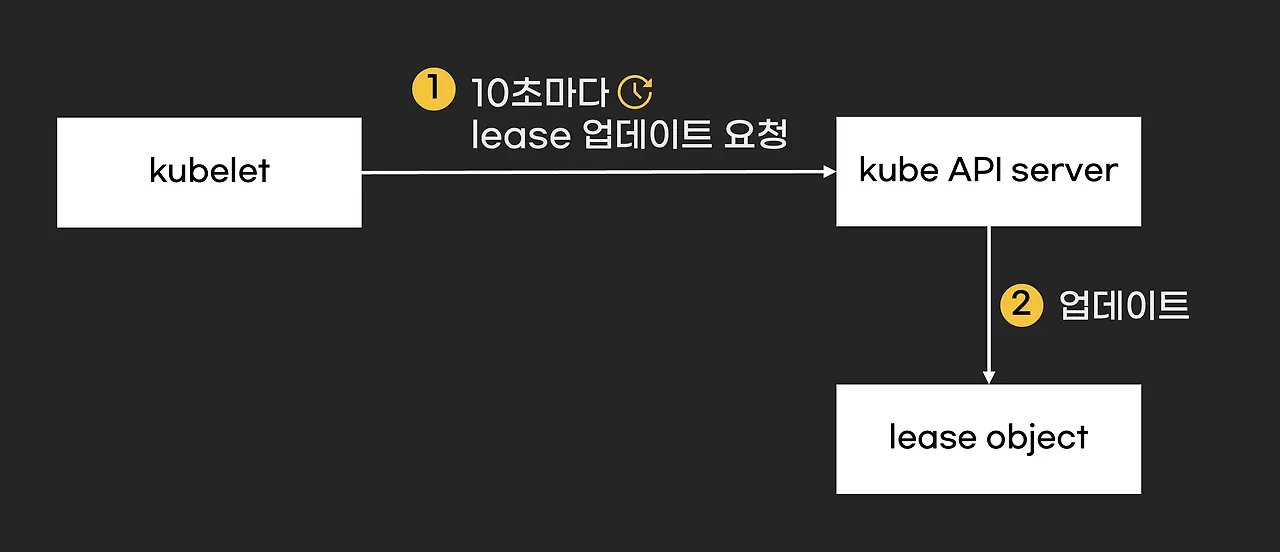
- lease 자원을 확인해봅시다.
lease 객체는 kube-node-lease 네임스페이스에 각 노드마다 저장됩니다.
get leases -n kube-node-lease
- 상세 정보 확인
기본적으로 40초의 간격으로 상태체크를 수행하도록 구성되어 있음
kubecolor describe leases -n kube-node-lease
❓그렇다면, 위의 두 방식으로 노드 상태체크에 실패했을 경우는 어떻게 될까요?
pod-eviction-timeout: 노드가 NotReady 상태일 때, Pod를 강제 퇴출(evict)하는 시간 - EKS 기본값 5분(300초)
이때, AWS EKS의 경우 eviction에 대한 값은 5분으로 고정!
- The
pod-eviction-timeoutparameter inside the Kubernetes Controller Manager is set by default at 5 minutes and could be updated through the Kubernetes control plane. - Link
참고 - How Does Alibaba Ensure the Performance of System Components in a 10,000-node Kubernetes Cluster? - Link
- 효율적인 노드 하트비트
- 쿠버네티스 클러스터의 확장성은 노드 하트비트의 효과적인 처리에 달려 있습니다. 일반적인 프로덕션 환경에서 kubelet은 10초마다 하트비트를 보고합니다. 각 하트비트 요청과 연결된 콘텐츠는 노드의 수십 개의 이미지와 일정량의 볼륨 정보를 포함하여 15KB에 이릅니다. 그러나 이 모든 것에는 두 가지 문제가 있습니다.
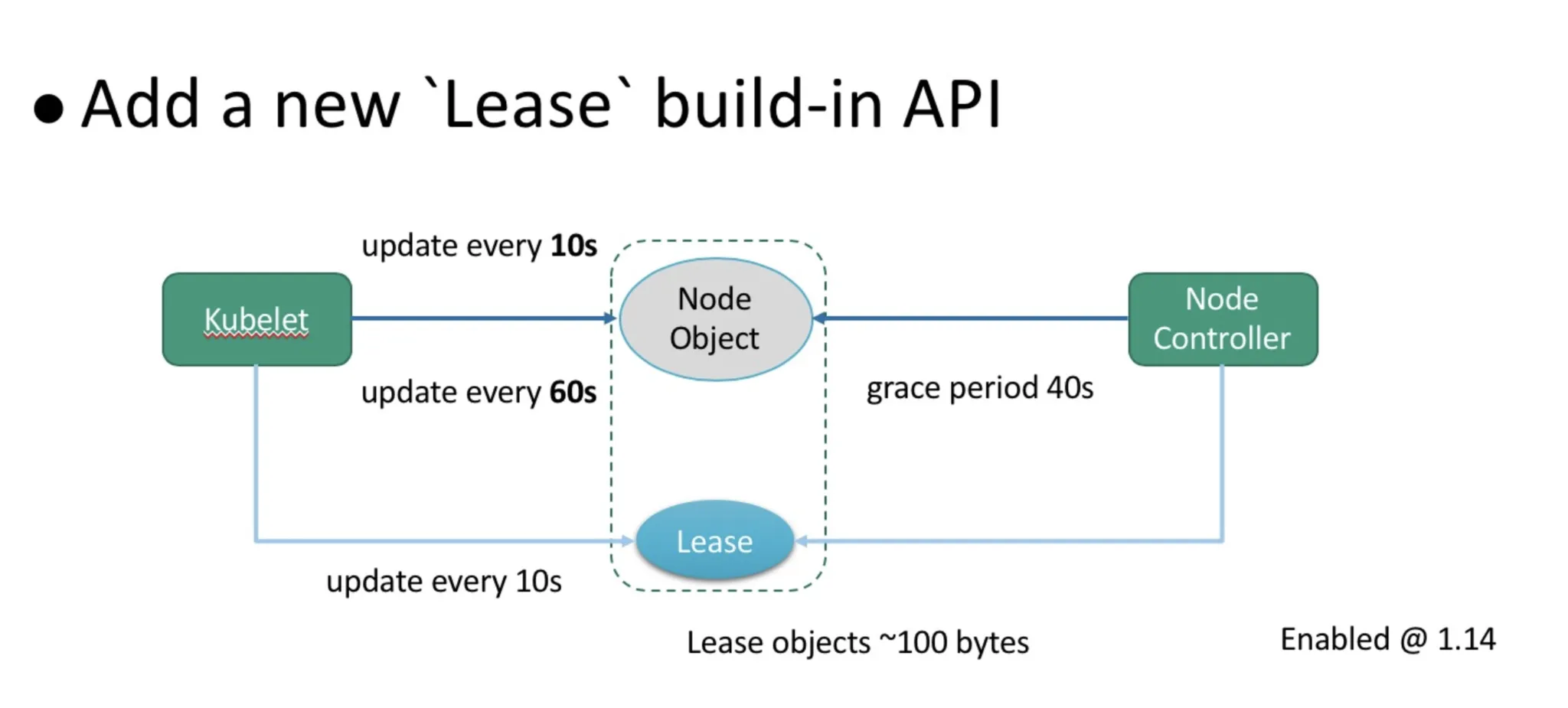
<문제점>
- 하트비트 요청은 etcd에서 노드 객체의 업데이트를 트리거하는데, 이는 10,000개의 노드가 있는 쿠버네티스 클러스터에서 분당 약 1GB의 트랜잭션 로그를 생성할 수 있습니다. 변경 내역은 etcd에 기록됩니다.
- API 서버의 CPU 사용량이 높고 직렬화 및 역직렬화의 오버헤드가 큰 노드로 구성된 Kubernetes 클러스터에서 하트비트 요청을 처리하는 CPU 오버헤드는 API 서버의 CPU 시간 사용량의 80%를 초과합니다.
❗위의 두 문제점에 대한 대표적인 해법이 지금것 설명했던 lease의 활용처입니다.
<개선 방식>
- 노드의 주요 상태(.status)는 변화가 있을 때에만 업데이트(디폴트 5분 주기 또는 상태 변경 시).
- 대신 노드 “생존 여부”는 별도의 Lease(리스) 객체를 통해 10초 단위로 빠르게 업데이트.
- Lease 객체는 매우 작은 크기로, etcd가 기록해야 할 데이터량이 크게 줄어듦.
- “NodeLeaseController”가 이 작업을 관리해 API 서버와 etcd에 대한 오버헤드를 완화.
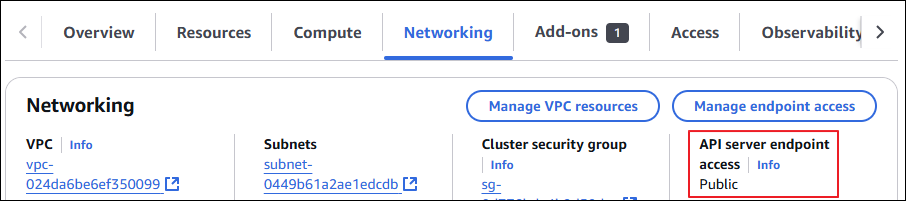
(심화) EKS Cluster Endpoint를 public + private으로 변경 - Link
먼저, EKS Cluster의 API server 엔드포인트의 액세스 지점을 확인하고, 이전에 API Server의 Public IP도 다시 한 번 체크합니다.
# [모니터링1] 설정 후 변경 확인 >> 추가로 자신의 집 PC에서도 아래 dig 조회 모니터링 걸어보자!
APIDNS=$(aws eks describe-cluster --name $CLUSTER_NAME | jq -r .cluster.endpoint | cut -d '/' -f 3)
dig +short $APIDNS
**while true; do dig +short $APIDNS ; echo "------------------------------" ; date; sleep 1; done**
# [모니터링2] 노드에서 ControlPlane과 통신 연결 확인 : IPv4 kube-proxy, kubelet 확인
N1=$(kubectl get node --label-columns=topology.kubernetes.io/zone --selector=topology.kubernetes.io/zone=ap-northeast-2a -o jsonpath={.items[0].status.addresses[0].address})
N2=$(kubectl get node --label-columns=topology.kubernetes.io/zone --selector=topology.kubernetes.io/zone=ap-northeast-2c -o jsonpath={.items[0].status.addresses[0].address})
**while true; do ssh ec2-user@$N1 sudo ss -tnp | egrep 'kubelet|kube-proxy' ; echo ; ssh ec2-user@$N2 sudo ss -tnp | egrep 'kubelet|kube-proxy' ; echo "------------------------------" ; date; sleep 1; done**
# Public(**IP제한**)+**Private** 로 변경 : 설정 후 6분 정도 후 반영 *~~>> curl 부분을 IP를 자신의 집 공인 IP를 직접 넣어보자!~~*
aws eks update-cluster-config --region $AWS_DEFAULT_REGION --name $CLUSTER_NAME --resources-vpc-config **endpointPublicAccess=true,publicAccessCidrs="$(curl -s ipinfo.io/ip)/32",endpointPrivateAccess=true**API server endpoint가 아래와 같이 변경된 것을 확인 가능

콘솔에서도 Public & Private으로 변경되어 있습니다.
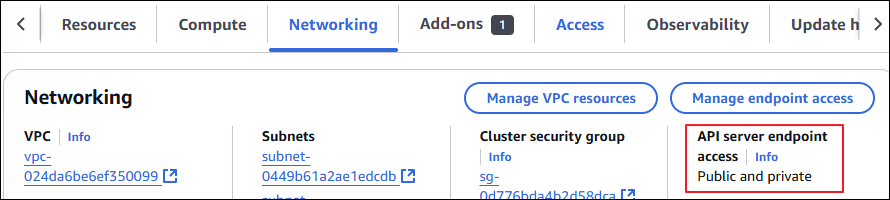
kubectl 확인
# kubectl 사용 확인
kubectl get node -v=6
kubectl cluster-info
ss -tnp | grep kubectl # 신규 터미널에서 확인 해보자 >> EKS 동작 VPC 내부에서는 Cluster Endpoint 도메인 질의 시 Private IP 정보를 리턴해준다
# EKS ControlPlane 보안그룹 ID 확인
aws ec2 describe-security-groups --filters Name=group-name,Values=*ControlPlaneSecurityGroup* --query "SecurityGroups[*].[GroupId]" --output text
CPSGID=$(aws ec2 describe-security-groups --filters Name=group-name,Values=*ControlPlaneSecurityGroup* --query "SecurityGroups[*].[GroupId]" --output text)
echo $CPSGID
# 노드 보안그룹에 eksctl-host 에서 노드(파드)에 접속 가능하게 룰(Rule) 추가 설정
aws ec2 authorize-security-group-ingress --group-id $CPSGID --protocol '-1' --cidr 192.168.1.100/32
# (최소 6분 이후 확인) 아래 dig 조회
dig +short $APIDNS
# kubectl 사용 확인
kubectl get node -v=6
kubectl cluster-info노드 확인
# 모니터링 : tcp peer 정보 변화 확인
while true; do ssh ec2-user@$N1 sudo ss -tnp | egrep 'kubelet|kube-proxy' ; echo ; ssh ec2-user@$N2 sudo ss -tnp | egrep 'kubelet|kube-proxy' ; echo "------------------------------" ; date; sleep 1; done
# kube-proxy rollout : ss에 kube-proxy peer IP 변경 확인
kubectl rollout restart ds/kube-proxy -n kube-system
# kubelet 은 노드에서 systemctl restart kubelet으로 적용해보자 : ss에 kubelet peer IP 변경 확인
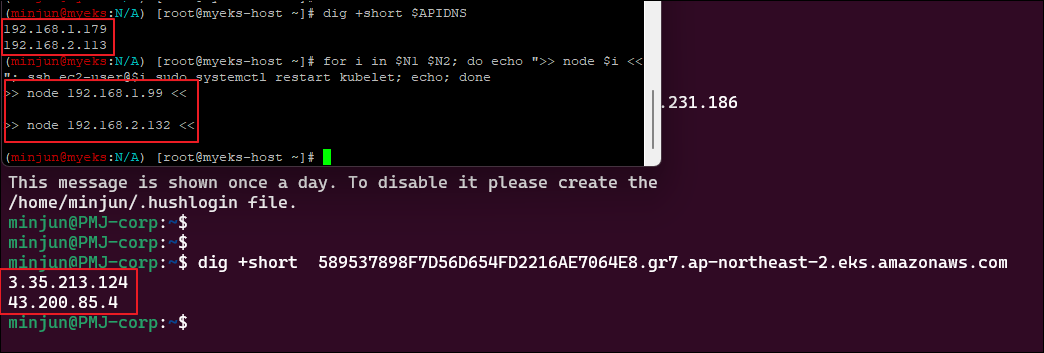
for i in $N1 $N2; do echo ">> node $i <<"; ssh ec2-user@$i sudo systemctl restart kubelet; echo; doneEC2가 아닌 개인 PC에서 확인
# 외부이기 때문에 Cluster Endpoint 도메인 질의 시 Public IP 정보를 리턴해준다
dig +short $APIDNS확인 결과
- kubectl 및 노드에서 엔드포인트 조회의 경우 192.168 과 같은 private 대역이 조회된다.
그러나, 개인 PC로 외부에서 Cluster 엔드포인트를 조회하는 경우 Public 대역이 조회된다.
즉, Public & Private 구조가 구현된 것이다.