Kafka + S3 Sink Connector (AWS)
AWS에 EC2를 만든 다음 Kafka Cluster를 만든 후, S3에 파일을 업로드하는 S3 Sink Connector를 연동해보려고 합니다.
Producer에서는 Json을 직렬화아여 Broker로 보내면 Sink connector cosume한 후, 역직렬화하여 Json형태로 S3에 저장하는 파이프라인을 만들겠습니다.

인프라는 AWS EC2 세대를 사용하여 구성하겠습니다. S3에 데이터를 put할 수 있는 IAM계정의 access & secret key가 필요합니다.
Kafka Broker Cluster 생성
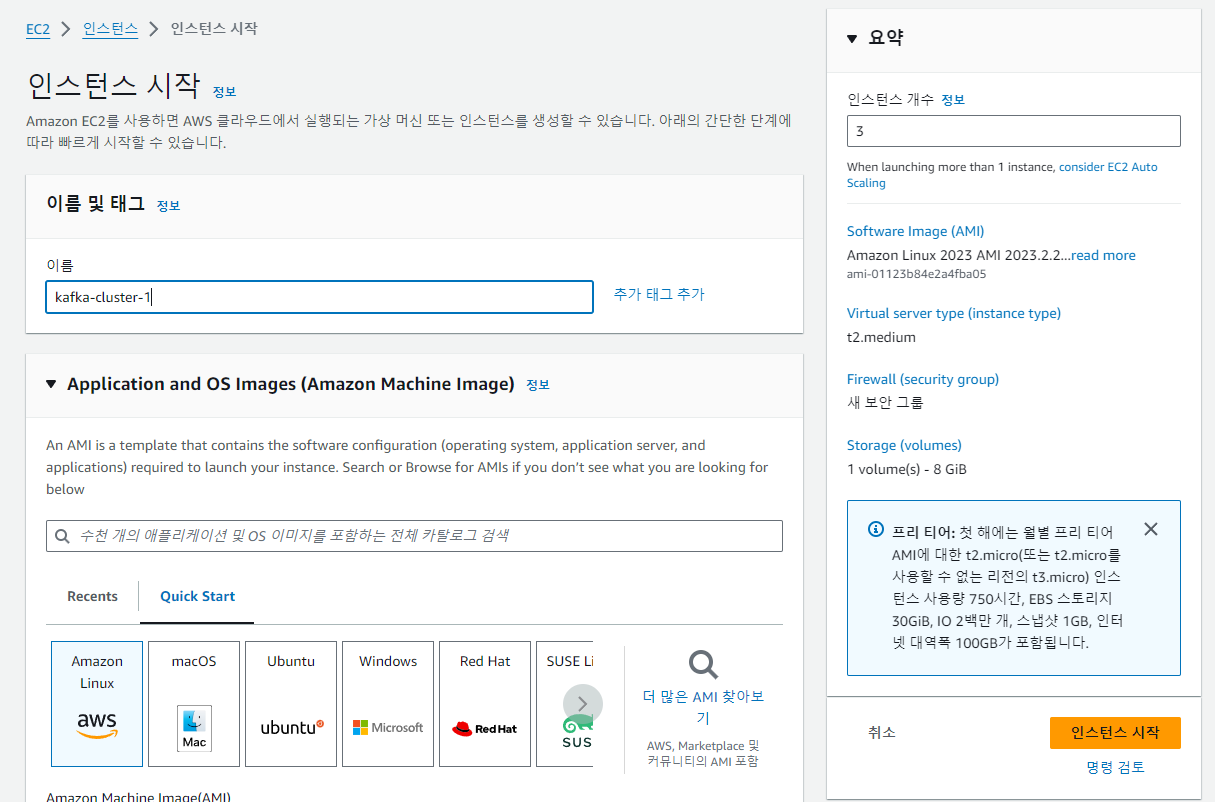
EC2 생성
우선 AWS에서 Kafka Cluster를 만들기 위해 3개의 인스턴스를 생성합니다. cluster를 생성하기 위해서는 최소 3개의 노드가 필요합니다.
t2.medium으로 동일한 성능의 인스턴스를 만들었습니다. (t2.small로 시도했으나, 메모리 부족으로 인스턴스를 업그레이드 했습니다.)
hosts 파일 수정
같은 VPC내의 kafka cluster를 kafka-1, kafka-2, kafka-3으로 호스트이름을 짓고 호출하려고 합니다. 일단 호스트 이름을 아래와같이 변경한 후에 /etc/hosts에서 kafka-1,2,3을 등록합니다. hosts파일에 등록하는 ip는 퍼블릭 ip가 아닌 프라이빗 ip입니다. 3개의 인스턴스에서 모두 같은 방법으로 변경합니다. 이후의 모든 과정들도 3개의 인스턴스에서 동일하게 작업합니다.


Java 설치 여부 확인
자바가 설치되어 있지 않아 자바를 설치합니다.
sudo yum install -y java-11-amazon-corretto.x86_64
java -version
타임존 변경
s3에 파일을 저장할때 한국 시간을 기준으로 파티셔닝을 할 예정이기 때문에 타임존을 KST로 변경합니다. 해당 사항은 옵션입니다.
sudo timedatectl set-timezone Asia/SeoulKafka 바이너리 다운로드
현재시점을 기준으로 kafka 공식사이트에서 stable버젼이 3.6.0이라고 명시되어 있어, 해당 버젼의 바이너리파일을 다운로드 합니다.
압축을 해재하고 난 뒤, /opt/kafka 심볼릭 링크를 생성하고 이제 /opt/kafka에서 작업하겠습니다.
cd /home/ec2-user
wget https://downloads.apache.org/kafka/3.6.0/kafka_2.12-3.6.0.tgz
tar -xvf kafka_2.12-3.6.0.tgz
sudo ln -s /home/ec2-user/kafka_2.12-3.6.0 /opt/kafka
Properties 변경
kafka를 cluster로 실행하기 위해서는 몇 가지 properties를 수정하려고 합니다.
1) Zookeeper
/opt/kafka/config/zookeeper.properties는 아래와 같이 변경합니다. 저는 dataDir를 /data/zookeeper로 변경했습니다. 그리고 server.1~3은 위에서 설정한 hosts에 따라 각 인스턴스의 호스트네임을 입력해줍니다.
dataDir=/data/zookeeper
server.1=kafka-1:2888:3888
server.2=kafka-2:2888:3888
server.3=kafka-3:2888:38882) Kafka
/opt/kafka/config/server.properties는 아래와 같이 변경합니다.
broker.id는 카프카에서 고유한 id입니다. hosts파일에서 kafka-1,2,3순서를 매긴대로 broker.id도 그대도 번호를 매깁니다.
그리고 VPC외부에서 Kafka Broker를 Produce하고 Consume하기 위해서는 각 인스턴스의 Public DNS와 포트를 advertised.listeners에 넣어 주어야합니다. 그리고 앞에서 주키퍼를 3개를 사용하기 위해 설정했기 때문에 여기에서도 각 인스턴스의 2181 주키퍼포트를 입력합니다.
broker.id=1 # kafka-1,2,3에 맞춰 브로커의 아이디를 입력
advertised.listeners=PLAINTEXT://[Pulbic DNS]:9092
zookeeper.connect=kafka-1:2181,kafka-2:2181,kafka-3:2181Zookeeper 설정
zookeeper.properties에서 dataDir을 /data/zookeeper로 수정했고, 해당 폴더에 zookeeper id를 부여하는 파일을 만들어야 합니다. 디렉토리를 만들고 myid라는 파일안에 1~3의 아이디 값이 기록되도록 합니다. myid파일을 열어보면 1번 서버는 1이라는 숫자만 있고, 마찬가지로 3번 서버는 myid파일에 3의 숫자만 기록되도록 합니다.
sudo mkdir -p /data/zookeeper
echo 1 > sudo /data/zookeeper/myid
Zookeeper 실행
zookeeper실행을 위해 아래 명령어를 입력합니다. -daemon은 백그라운드에서 실행하기 위한 옵션입니다. 처음 실행해볼때는 -daemon을 빼고 실행해서 설정값이 잘 입력되어 에러가 나는지 확인해도 됩니다.
sudo /opt/kafka/bin/zookeeper-server-start.sh -daemon /opt/kafka/config/zookeeper.properties제대로 실행되었는지 확인하기 위해서는 /opt/kafka/log/에서 zookeeper.out파일을 확인합니다. 그리고 ps -ef | grep zoookeeper로 프로세스가 있는지 확인합니다.

Kafka 실행
zookeeper가 제대로 실행된 것을 확인하면, Kafka를 실행합니다. 마찬자기로 -daemon은 백그라운드 실행이고 log도 동일한 위치에서 확인할 수 있습니다.
sudo /opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties
Topic 생성
kafka도 잘 실행이 되었다면, topic을 생성합니다. 토픽의 이름은 test-topic으로 했고, 레플리카와 파티션을 3개로 설정했습니다.
/opt/kafka/bin/kafka-topics.sh --bootstrap-server kafka-1:9092,kafka-2:9092,kafka-3:9092 --create --topic test-topic --replication-factor 3 --partitions 3
생성이 완료되었다는 메시지가 뜨면, 토픽의 리스트를 조회해 잘 생성되었는지 한번 더 확인해봅니다.

kafka cluster를 모드를 ec2에 간단하게 생성했습니다. 이제 s3 sink connector를 연동하기 위한 작업을 시작합니다. kafka connector는 각 kafaka 인스턴스에 distributed mode로 실행합니다.
standalone모드는 하나의 노드에서 worker를 생성하지만, distributed 방법을 사용한다면, 같은 group.id를 가진 노드(인스턴스)에서 worker를 생성하여 분산할 수 있습니다. Kafka와 마찬가지로 이렇게 되면 하나의 노드가 장애로 죽게되어도 다른 노드에서 동일한 일을 처리할 수 있으니 고가용성(HA)을 보장할 수 있습니다.
S3 Sink Connector 연동
AWS 접속 정보 등록
S3 sink connector가 S3에 파일을 업로드하기 위해서는 접근 권한이 있어야 함으로 S3에 접근이 가능한 access/secret key를 등록합니다. sudo로 실행하면 /root/.aws/credential에 정보가 기록됩니다.
sudo aws configureS3 Bucket 생성
S3 Sink connector가 데이터를 저장할 버킷을 생성합니다. 저는 테스트용이기 때문에 이름이 겹치지 않은 버킷으로 test-bucket-2334로 만들었습니다. 테스트 후 바로 삭제할 예정이기 때문에 겹치지 않는 이름으로만 생성하면 됩니다.

S3 sink connector plugin 다운로드
s3 sink 커넥터를 사용하기 위해서는 플러그인을 다운 받아야합니다. confluent에 제공하는 플러그인을 다운로드합니다.
압축을 해제하고 /opt/kafka/plugins/kafka-connect-s3 디렉토리를 만들고 파일을 복사합니다.
cd /home/ec2-user
wget https://api.hub.confluent.io/api/plugins/confluentinc/kafka-connect-s3/versions/4.1.1/archive
unzip archive
mkdir -p /opt/kafka/plugins/kafka-connect-s3
cp confluentinc-kafka-connect-s3-4.1.1/lib/* /opt/kafka/plugins/kafka-connect-s3/
Properties 수정
S3에 저장되는 형식은 상황에 따라 다르나, 여기서는 Json파일형태로 저장하려고 합니다. publish할 때 json 데이터를 string으로 직렬화하여 kafka broker에 보내고, sink connector는 string -> json으로 역직렬화를 합니다.
bootstrap.servers : kafka broker 서버 3대를 등록해줍니다.
group.id : 분산모드 실행시 같은 그룹 아이디를 가지고 있어야합니다.
key.converter.schemas.enable : 레지스티를 사용하지 않기 때문에 반드시 false로 설정합니다.
rest.advertised.host.name, rest.advertised.port: 다른 노드에 worker를 실행시키기 위해 각 노드의 public DNS와 포트 번호를 입력합니다. 이 설정을 하지 않으면, worker들이 다른 노드에 생성되지 않습니다.
plugin.path: 다운로드한 plugin의 경로
/opt/kafka/config/s3-sink-connecter-distributed.properties
bootstrap.servers=kafka-1:9092,kafka-2:9092,kafka-3:9092
group.id=s3-sink-connect-cluster
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=false
value.converter.schemas.enable=false
rest.advertised.host.name=[Public DNS]
rest.advertised.port=8083
plugin.path=/opt/kafka/pluginsdistribute 모든 offset등을 카프카에 topic형태로 관리하게 됩니다. 이와 관련된 설정에서 레플리카와 파티션의 개수를 원하는데로 조정 할 수 있습니다.
Kafka connector 실행
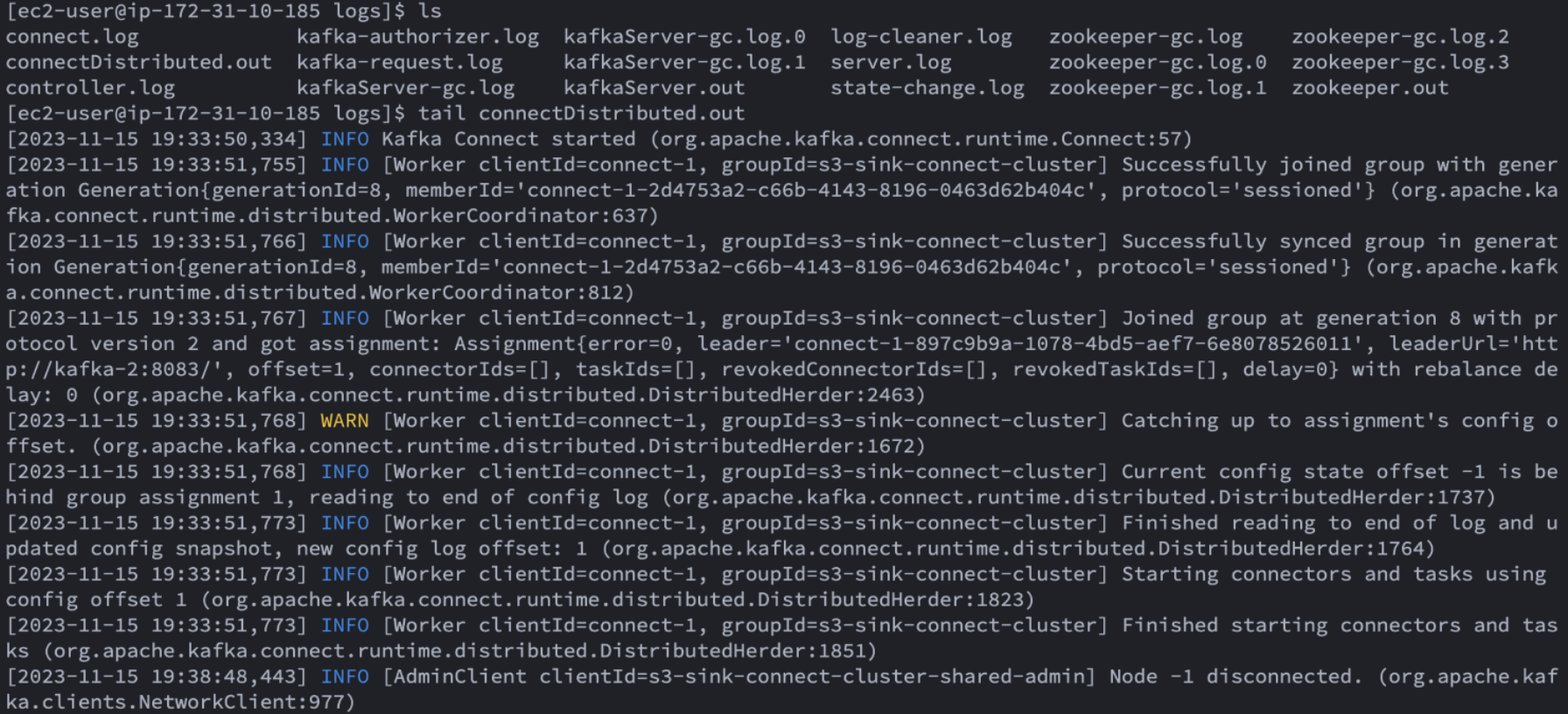
각 노드에서 sink connector를 실행합니다.
sudo ./bin/connect-distributed.sh -daemon ./config/s3-sink-connector-distributed.propertieslog 디렉토리에서 connect.out의 로그파일을 확인하여 정상적으로 동작하는지 확인합니다.
connector 등록
커넥터 실행 후, s3 sink connector를 등록합니다. properties파일이나 API로 등록할 수 있습니다. 저는 API로 connector를 등록하겠습니다. connector 생성을 위해 아래와 같은 컨피그를 설정합니다. 저는 python을 사용했습니다.
name : 커넥터 이름
task.max : worker의 개수, 분산 모드를 확인하기 위해 3개 이상으로 실행
topics : kafka broker에서 받은 topic의 이름
s3.compression.type : json파일을 gz으로 압축
format.class : S3에 저장할 데이터 타입입니다
partitioner.class : TimeBasedPartitioner을 사용하면 날짜(또는 시간)별로 디렉토리가 생겨 파티션형태로 데이터를 저장 가능
partition.duration.ms : 파티션을 단위를 설정합니다. 저는 24시간으로 설정했습니다.
flush.size : 토픽에서 데이터를 받아 sink하기 위한 개수(즉각적인 결과를 확인하기 위해 1로 설정)
아래 스크립트를 실행하면 connector 등록이 가능
import requests as req
import json
s3_sink_connector = {"name": "test-s3-sink",
"config": {"connector.class": "io.confluent.connect.s3.S3SinkConnector",
"tasks.max": 3,
"topics": "test-topic",
"s3.region": "ap-northeast-2",
"s3.bucket.name": "test-bucket-2334",
"s3.compression.type": "gzip",
"s3.part.size": 5242880,
"flush.size": 1,
"storage.class": "io.confluent.connect.s3.storage.S3Storage",
"format.class": "io.confluent.connect.s3.format.json.JsonFormat",
"schema.generator.class": "io.confluent.connect.storage.hive.schema.DefaultSchemaGenerator",
"partitioner.class": "io.confluent.connect.storage.partitioner.TimeBasedPartitioner",
"partition.duration.ms": 3600000,
"path.format": "YYYY-MM-dd",
"locale": "KR",
"timezone": "Asia/Seoul",
"schema.compatibility": "NONE"
}
}
result = req.post(url="http://[1,2,3번 중 하나의 Pulbic DNS]:8083/connectors",
headers={"Content-Type": "application/json"}, data=json.dumps(s3_sink_connector))
print(result.json())아래 API로 등록 여부 및 상태 확인
# 커넥터 목록 조회
http://[1,2,3번 중 하나의 Pulbic DNS]:8083/connectors/
# 커넥터의 상태 조회
http://[1,2,3번 중 하나의 Pulbic DNS]:8083/connectors/test-s3-sink/status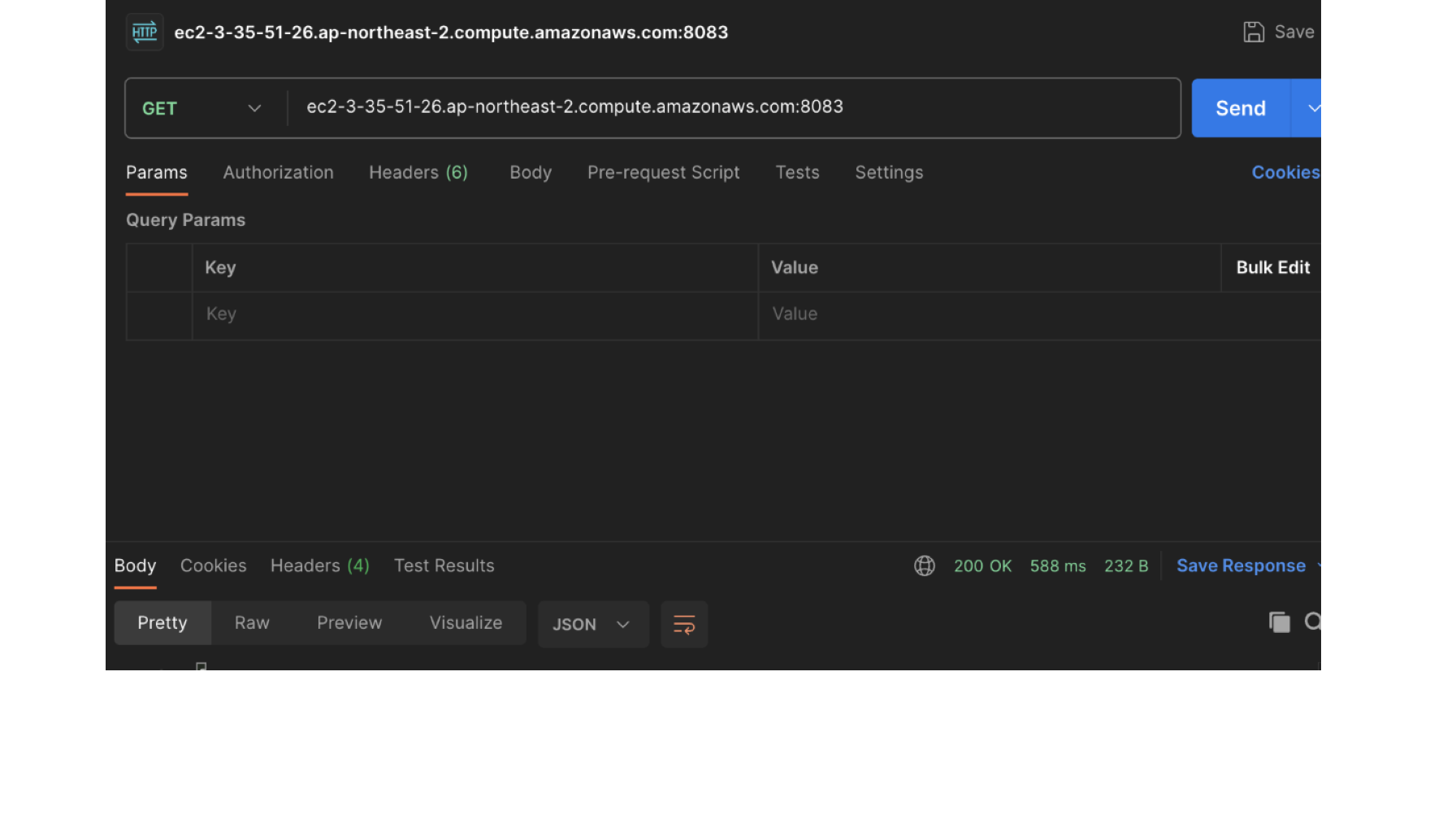
Python Kafka Producer로 kafka broker에 데이터 전송
python을 사용해서 간단하게 Producing해보려고 합니다. KafkaProducer에서 broker들의 Pulblic DNS를 리스트로 입력한뒤, string형태로 직렬화하여 보내겠습니다.
from kafka import KafkaProducer
import json
import random
producer = KafkaProducer(
bootstrap_servers=['ec2-***-***-***-190.ap-northeast-2.compute.amazonaws.com:9092',
'ec2-***-***-***-159.ap-northeast-2.compute.amazonaws.com:9092',
'ec2-***-***-***-25.ap-northeast-2.compute.amazonaws.com:9092'],
client_id='python_test_producer',
key_serializer=None,
value_serializer=lambda v: json.dumps(v).encode('utf-8'))
data = [{'number': random.randint(0, 1000)} for i in range(10)]
response = producer.send(topic='test-topic', value=data).get()
print(response) kafka broker에 데이터를 전송하면 되면, 즉시 s3 sink connector 로그에는 S3에 데이터가 커밋되었다는 로그가 나옵니다.

S3로 이동하여 데이터를 확인해보면, topic이름으로 디렉토리가 생성되고, 오늘 날짜로 디렉토리가 또 생기고 그 안에 데이터들이 저장되어 있습니다. s3 sink connector에서 flush.size 옵션을 1로 설정했기 때문에, kafka에 데이터를 전송한 수만큼 json파일의 수가 저장되어 있는 것을 볼 수 있습니다.
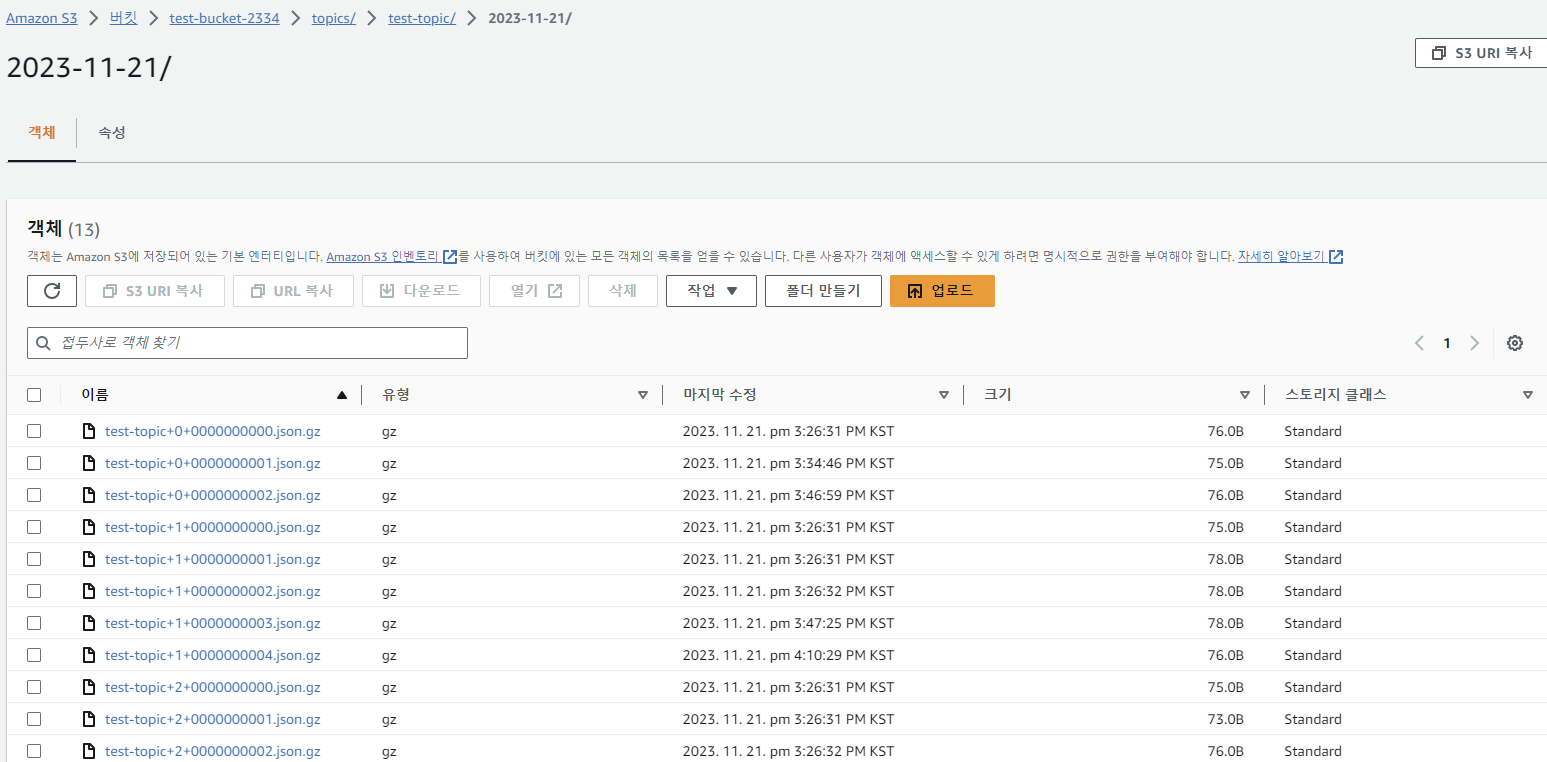
그리고 3개의 노드에서 분산되어 저장되었지 http://[Public DNS]:8083/connectors/test-s3-sink/status로 확인해 보면 worker_id가 3개의 노드로 되어 있습니다.

AWS에서 Kafka를 설치하고 S3와 Kafka S3 Sink Connector를 사용해서 연동해보았습니다.
