GPT-1(Improving languague understanding by Generative Pre-Training)란?+벡터 흐름 하나하나 자세하게 설명
NLP
목차
- 간단 요약
- 논문 분석
1. 간단 요약

최근 2020년에 발표된 GPT-3가 뛰어난 성능을 보여주고 있다.
다음과 같이 어떠한 질문을 하든지 척척 답해내는 것을 볼 수 있다.
문장 내에 탄소의 원자수를 원하는지, 아니면 단순히 원자 수를 원하는지를 모델이 구분하여 그에 따른 정답을 내놓는다.
이러한 모델의 기초는 이번에 소개하고자 하는 GPT로 부터 시작했다.
바로, 라벨링되지 않은 방대한 데이터를 사용하려는 시도를 한 것이다.
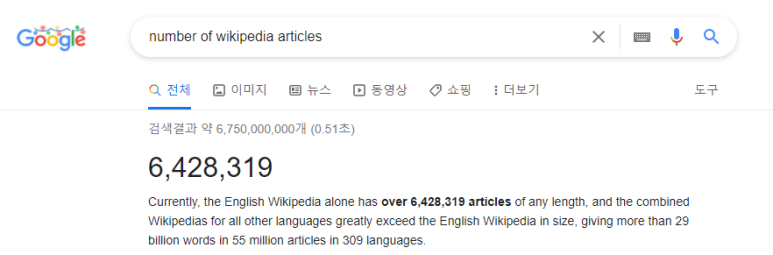
글을 쓰는 시점, 영어위키피디아에 올라와 있는 글 개수는 650만개 정도가 되고 , 사용된 단어는 40억개에 달한다.
하지만 우리가 supervised learning을 하기 위해서는 '문제-정답 쌍' 데이터가 필요하다.
y=f(x)의 f를 구하기 위해서는 x뿐만이 아니라 y도 필요하기 때문이다.
GPT가 출시할 당시 사용 가능한 쌍 데이터들은
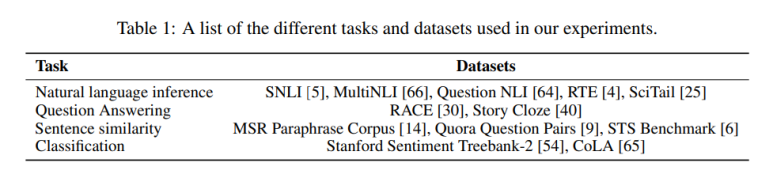
다음과 같은 조합들이 있지만, 사람이 만든 것이기에 각각 몇천에서 몇십만개정도 밖에 되지 않았다.
우리가 사용하려는, wikipedia에 적힌 데이터들은 사람들이 일일히 라벨링한 라벨링된 데이터셋(labeled dataset)이 아니므로, 그로인해 우리는 저 데이터를 버려야 하는가?
저 미지의 데이터를 참조하여 사용한다면 어떨까?
저 Wikipedia에 올라와 있는 글은 우리가 읽을 수 있는 글로 이루어져 있으므로, 각각의 문서에 등장하는 단어 등장 순서 정보는 분명히 의미있는 정보일 것이다.
마치 ELMo처럼 말이다. (ELmo에서는 문장 내 단어의 순서 sequence 정보를 따로 만들어 단어 임베딩에 추가함으로써 문장 정보를 단어 하나하나에 담을 수 있었다.)
+ElMo란?
물론 GPT와 ELMo는 pre-trained language representation(사전학습된 언어 표현정보, 이번 경우 단어들의 나열 순서 정보를 담은 함축벡터를 말한다)을 down-stream task(이 정보를 첨가하여 진행 할 후속 작업)에 적용하는 방법은 다르다.
다음 포스트에서 소개할 BERT 논문의 Introduction에서는 다음과 같이 설명한다.
크게 두가지의 방법이 있다.
- Feature-based
- Fine-tuning
이다.
1. Feature-based
"The feature-based approach, such as ELMo (Peters et al., 2018a), uses task-specific architectures that include the pre-trained representations as additional features. "
: ELMo처럼, task-specific(작업(Classification,Entailment,Similarity,Multiple choice 등)에 따라 성능 향상을 위해 차별화된) 모델 구조를 사용하는데 여기에 pre-trained language representation(사전학습된 언어 표현정보)를 '추가적인 특징' 형식으로 집어넣는 것이다.
2. Fine-tuning
"The fine-tuning approach, such as the Generative Pre-trained Transformer (OpenAI GPT) (Radford et al., 2018), introduces minimal task-specific parameters, and is trained on the downstream tasks by simply fine-tuning all pretrained parameters."
"Apart from output layers, the same architectures are used in both pre-training and fine-tuning. The same pre-trained model parameters are used to initialize models for different down-stream tasks. During fine-tuning, all parameters are fine-tuned."
: GPT처럼, 최소의 task-specific(작업 차별화된) parameters(=linear output layer parameters)를 도입하고, 이 parameters는 downstream tasks(후속 작업)을 통해 모든 사전학습된 parameter들이 미세조정(fine-tuning)됨으로 인해 학습된다.
output layer를 제외하고, 같은 구조가 pre-training과 fine-tuning에 사용되고, 같은 사전학습된 모델의 가중치가 각각의 다른 down-stream tasks(하류 작업)의 모델을 초기화(initialize : 초기 가중치 설정)하기 위해 사용된다. fine-tuning 동안 모든 parameters(가중치들)이 미세 조정 된다.
글로는 정확히 의미 전달이 되지 않을 수 있으므로 시각화 해보면,


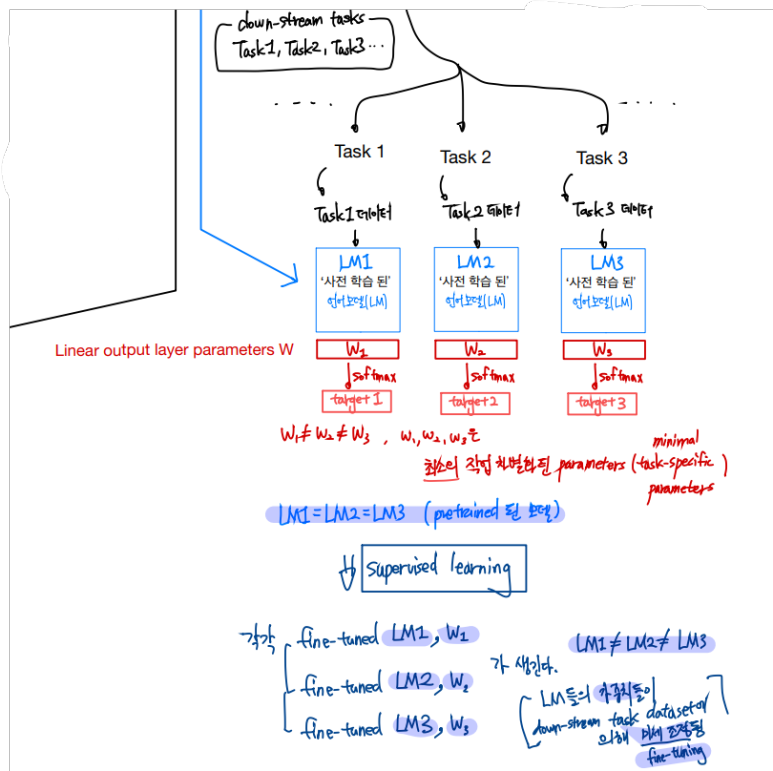
간단하게 비교하면,
Feature-based는 사전학습된 모델을 가지고 단어 나열 순서(단어 sequence) 정보를 하나의 특징벡터(feature)로 뽑아내 기본 input vector에 꼬리붙이기(concat)하는 것이고,
fine-tuning은 사전학습된 모델을 복사하여 각각의 하류 작업(down-stream tasks)에서 사용하며, 각각의 하류 작업에 해당하는 학습데이터(labeled dataset : 문제와 정답이 쌍으로 존재하는 학습 데이터)들을 집어넣어 학습하는 과정에서 이미 사전학습된 모델과, 출력 softmax 이전 부분에 사용되는 최소한의 가중치가 하류 작업에 맞게 미세하게 조정(fine-tuning)되는 것을 말한다.
GPT가 저 fine-tuning임을 인지하면서 GPT를 이해하보자.
현재 unlabeld된 데이터는 labeled된 데이터보다 방대함으로 이 unlabeled 된 데이터를 사용해보자는 것이 GPT의 주장이다.
흐름을 소개하면
-
Unlabeled Text Corpora(라벨링 되지 않은 문서 말뭉치)를 준비한다.
-
이 데이터셋을 이용해 'Generative pre-training'을 하여 모델 가중치들을 사전학습해놓는다.
-
Specific Task(튜닝하려는 작업)에 대한 Labeled Text Corpora(라벨링 된 문제-정답 쌍 문서 말뭉치)를 준비한다.
-
라벨링 된 작업 데이터들을 사전학습된 언어 모델에 집어넣어 fine-tuning(미세 조정)을 한다.
-
각 작업마다 따로 진행하여 Discirminative fine-tuning(작업 차별화 되는 fine-tuning)이 가능하다.
으로 설명할 수 있다.
근데 문제가 있다.
라벨링이 되지 않은 문서로 부터 단어 수준의 정보들을 사용하는것은 까다롭기 때문이다.
첫번째, 학습을 할 때 어떤 타입의 목적함수가 가장 효과적인지 알기가 힘들다.
두번째, 학습이 되더라도 이 정보를 target task(여러가지 taks들)에 transfer할 때, 각 task들에 가장 효과적인 방법이 무엇인지 모른다.
여기서 transfer란, transfer learning의 transfer이다.
transfer learning은 특정 task를 학습한 모델을 다른 task를 수행하는데 재 사용하는 학습법이다.
이때 먼저 학습하는 것을 pre-training이라 하는 것이다.
GPT는 목적함수로써, window(앞에 몇 단어까지 다룰 것인가)내 단어 등장 순서정보 로그확률 합을 이용하였고, target task에 transfer할 때는, 라벨링 된 데이터에 대한 supervised 학습에서 단어 등장 순서정보 로그 확률 합을 최대화 하는 동시에, 라벨링이 되지 않은 데이터에 대한 단어 등장 순서정보 로그 확률 합 또한 최대화 하도록 하였다.
- Unsupervised pre-training


라벨링 되지 않은 말뭉치의 토큰(단어라고 생각해도 된다.)들의 순서정보를 뽑아내기 위해
k개의 이전 단어들에 대해 그 다음 단어의 등장 가능성을 최대화 하였고, 이를 모든 n개의 단어에 대해 진행한다.
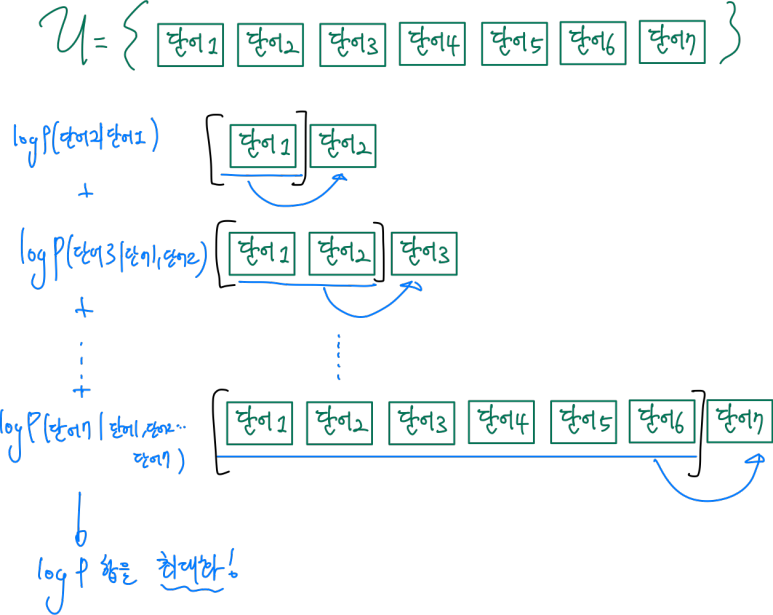
저 목적함수 L1(u)를 최대화 하도록 신경망을 생성하고, 이 Θ라는 parameters는 SGD를 통해 학습된다.(SGD:stochastic gradient decent)
그리고 이 확률 P 값은 multi-layer Transformer decoder를 통해 얻어진다.
이는 transformer의 decoder만을 쌓아서 만든다.
그림으로 보면
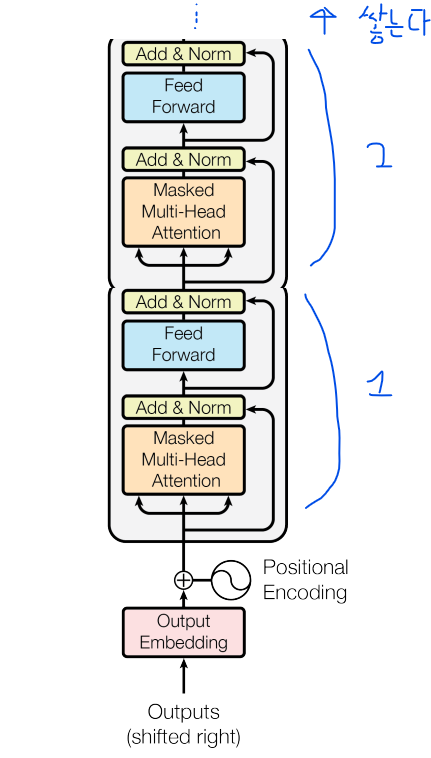
다음과 같고, 논문에서는 12개의 decoder block을 쌓았다.
이제 벡터 단위로 자세하게 이해해보면

첫번째 층의 입력은 context vector U에 token embedding matrix We를 곱하고 거기에 순서정보를 담기 위해 position embedding matrix Wp를 더해준다.
하지만 이런 설명만으로는 U와 We를 곱한다는 것이 정확이 어떤 의미를 담고 있는지 알 수 없으므로 세부적인 흐름까지 이해해보자. (이 부분이 며칠을 Googling해도 나오지 않아 많은 고민을 했다.)
일단 We와 Wp의 형태를 이해해보자.
그러기 위해 알아야 할 기본 개념인 Byte Pair Encoding을 알아야 한다.
간단히 말하자면, 자주 붙어서 등장하는 쌍 알파벳들을 묶은 다음, 그 묶여진 쌍(Pair) 알파벳(알파벳은 1 byte)을 어휘집합에 더함으로써 어휘집합의 양을 증가시키고, 학습되지 않은 단어에 대해도 유의미한 단어분류를 할 수 있도록 한 것이다.
세부적으로는 다음 링크에서 이해 할 수 있고,
Byte-Pair Encoding
GPT에서 사용한 방식은 다음 논문의 방식이다.
(기본 말뭉치로도 말뭉치에 없는 단어들을 subword 로 표현 가능하다. => 학습하지 않은 단어에 대해도 대응력이 향상된다.)
1. We
그렇다면, We는 말뭉치에서 BPE를 거치고 다음과 같이 생성이 된다.
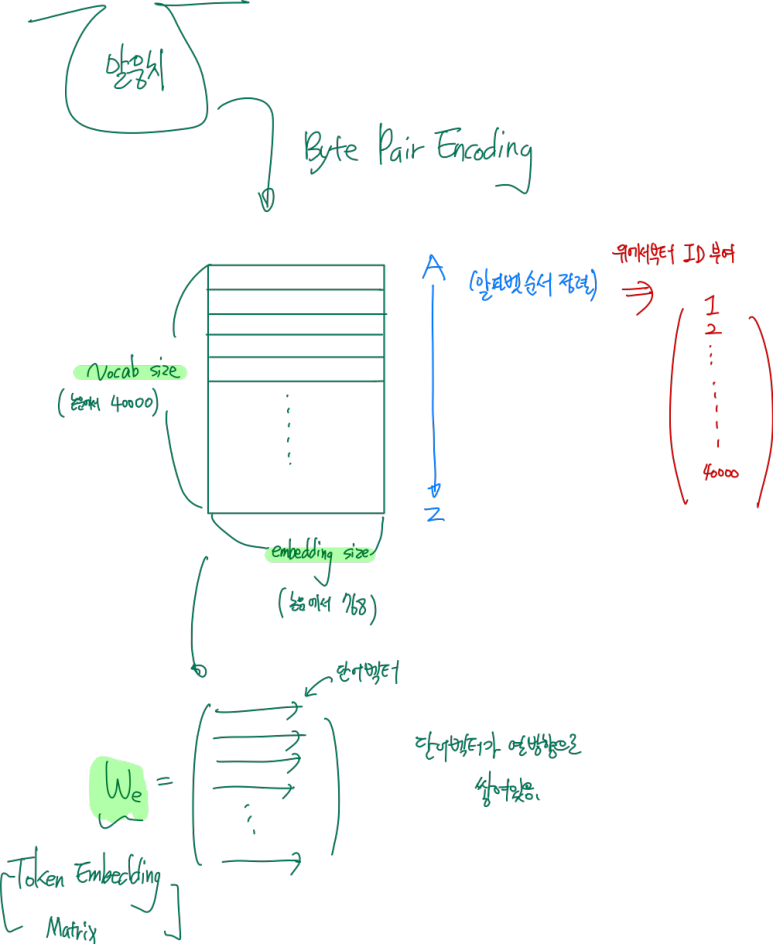
각 단어벡터 마다 하나하나씩 ID가 붙게 되고 우리는 unlabeled data의 단어들의 등장 순서에 따라 저기서 하나하나씩 뽑아서 학습을 하기 위한 We를 만들어 주면 된다.
이때, 단어를 뽑는 작업에서 저 ID를 사용하는 것이다.
- 자세히
저 40000개의 vocab은 subword(기본 단어들로 만든 부수 단어)이고 기본 단어는 478개이다. => 총 40478개의 vocab이 준비된다.
2. Wp
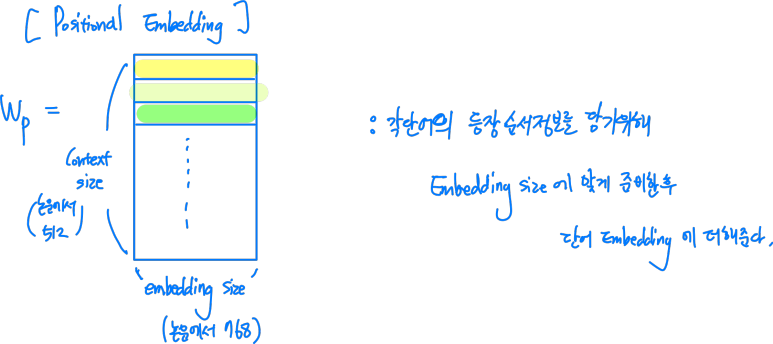
각 단어의 등장 순서정보를 담기 위한 positional embedding 벡터들이 열방향으로 쌓인 행렬이다.
이는 transformer에서 본 적이 있을 것이다.
차이점이라면, 기존 sinusoidal(사인파 모양의) version 이 아니라 학습된 Positiona Embedding이라는 점이다.
자세히 구분하면
Positional Encoding과 Positional Embedding로 나뉘고
-
Encoding의 경우 학습되는 Parameter가 아니고 확정적으로 주어지는 정보이며,
-
Embedding의 경우 Random initialize 후 학습을 통해 Position 정보를 Parameter로서 가진다는 점이다.
이제 U라는 context vector of tokens를 처리할 시간이다.

기존 transformer에서는 word embedding과 positional embedding만 더하면 되었다. 하지만 저 식에는 U라는 context vector of tokens라는 놈이 붙었다.
저 U가 바로 k라는 context window size만큼, 하나의 학습 sequence로 보기 위해
unlabeled dataset의 단어들의 등장 순서에 따라 We에 있는 단어 벡터를 하나하나씩 뽑아와 열방향으로 쌓기 위한 행렬이다.
U가 context vector라는 이름이 붙은 이유는 특정 단어를 예측하기 위해 필요한 이전 단어들의 sequence 정보가 context(문맥) 정보를 기 때문이라 예상된다.
이때 Id를 이용해 뽑는다. (k=3이라 가정 , 논문에서는 k=512 )
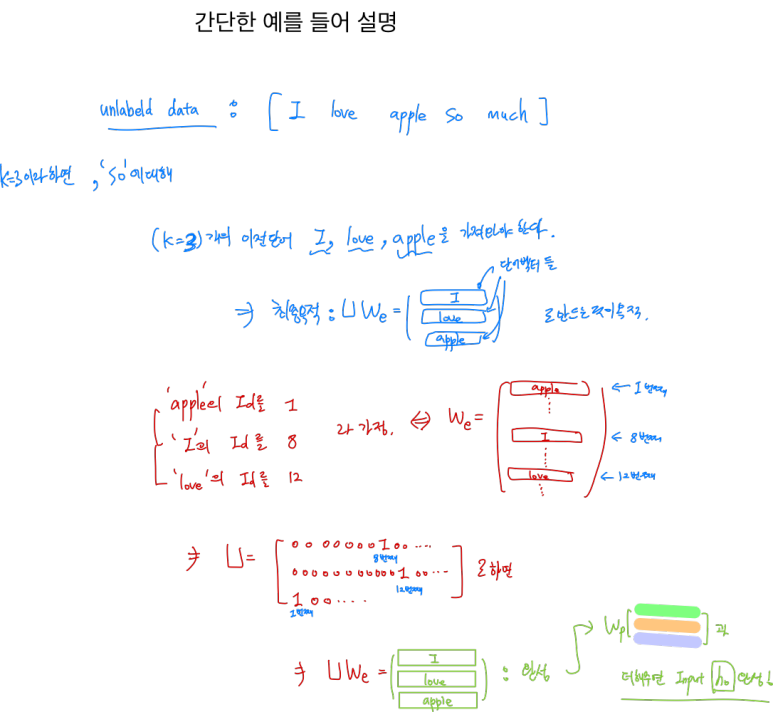
이렇게 h0가 준비가 되면, decoder block에서의 벡터 흐름을 따라가보자.

참조하려는 token 이후의 token은 mask를 덮어 attention을 진행하고,
이 masked self attention 된 정보가 그 위의 단계로 전달된다.

마지막으로 확률값을 얻어오기 위해 decoder 의 마지막 softmax 부분을 보자.
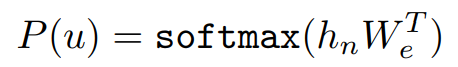
논문속 12개의 디코더를 쌓았으므로, n=12 가 될 것이고 마지막 디코더 박스의 h12 는 Token embedding의 전치와 곱함으로써, 1x40000 모양의 행렬이 되고 이를 softmax를 거쳐서 나온 한줄기의 벡터의 원소들의 값 중에서 input으로 들어온 값 다음에 등장할 단어의 Id에 해당하는 값이 최대가 되도록 학습한다.
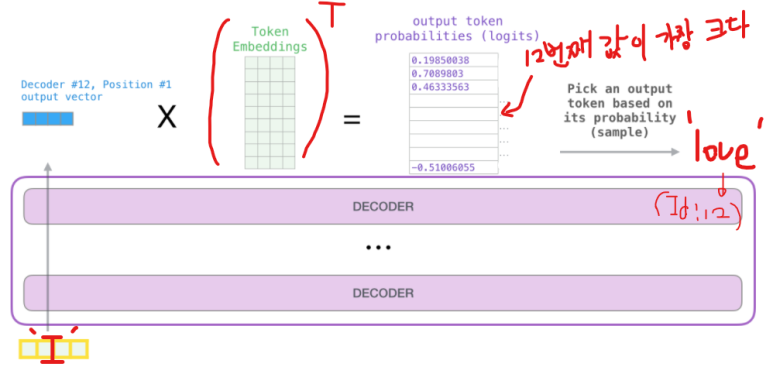
처음으로 들어온 값은 'I 이므로 그 다음에 올 단어는 'love' 이므로 마지막 softmax 이후 나온 벡터의 원소중에 12 번째(love의 id:12)값이 가장 크도록 학습하면 된다.
다른 love,apple 에 대해서도 똑같이 진행한다.
더 시각각화를 해보면 다음과 같다.
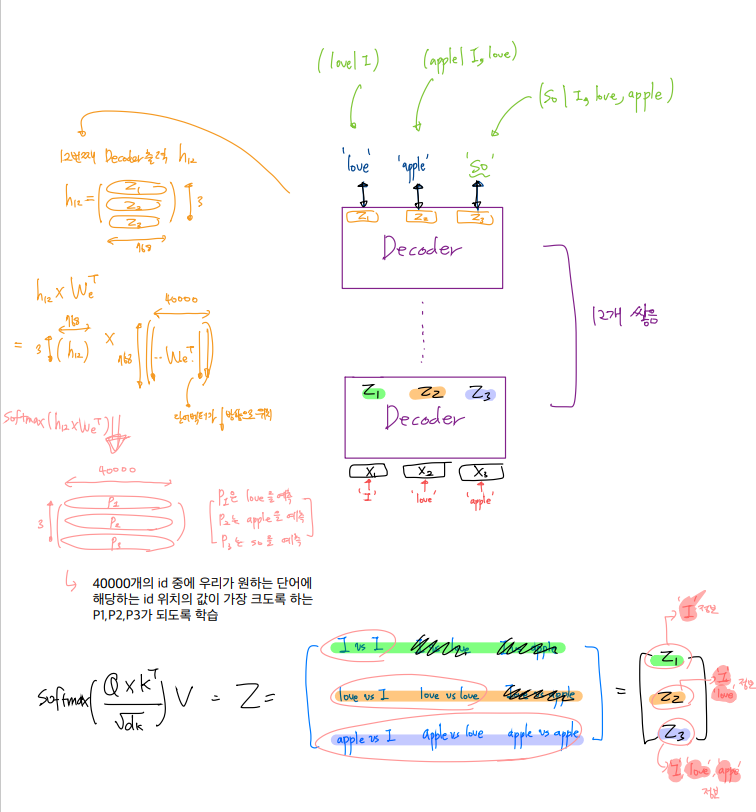
mask 때문에 우리가 의도했던, 이후 단어 정보를 참조하지 않고, 이전 단어 정보들만을 참조한다는 것을 이해할 수 있다. [ (love/I), (apple/I,love), (so/I,love,apple) ]
위와 같은 방법으로 라벨이 없는 방대한 dataset을 이용해 여러 단어들의 등장 순서 정보를 단어 모델에 pre-training 해 놓을 수 있다. 그리고 이 모델 속에 라벨링이 되어있는 dataset을 집어넣어 fine-tuning 한다.
2. Supervised fine-tuning
이제 labeled dataset C 로 Supervised fine-tuning을 해보자.
labeled dataset은 { token들의 sequence (x1 ,x2 ,x3 , ... , xn) , 그에 따른 라벨 y } 형태로, 쌍 데이터이다.
이제 이 dataset을 아까 얻은 pre-trained model에 집어넣고, 마지막 transformer block의 마지막 token에 대한 activation 인 hlm 를 선형 linear layer(가중치 Wy)에 집어넣고 그에 대한 softmax 값을 라벨 y를 예측하는 데 쓴다.
식으로 보면 다음과 같다.
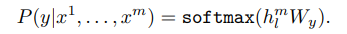
하지만, h가 이전과는 다르다. 위에 m이 붙었으므로, 마지막 토큰 xm의 output 만을 이용한다.
시각화를 해보자면,

그리고 그에 따른 확률을 높이는 목적함수를 최대화 한다. (아까와 똑같은 방법)

(C : labeled dataset)
연구자들은 성능 향상을 위해 보조 목적함수를 더하는 식으로 학습을 수행했다. (weight λ)
그리 했을 때 이득은 다음과 같다.
-
supervised model의 generalization(일반화)능력을 증가시킴 ( 모델을 변화에 강인하게)
-
수렴속도 향상
그래서 최종적으로 다음 목적함수를 optimize(최적화) 한다. (optimize란 최적의 값을 찾는 것)
<semi-supervised labeled + unlabeled>

하지만 주의해야 할 점이. L1(U) 가 아닌 L2(C) 라는 점이다.
이 말은, 사전학습된 모델에 C라는 unlabeled dataset의 문장 내 단어 등장 순서 정보 또한 추가적으로 학습한다는 말이다.
그러므로,
-
unsupervied pre-training 이후 모델이 준비되면,
-
labeled dataset C를 가지고
-
L2(C)를 최대화 하는 동시에
-
λ 만큼의 비율로 L1(C) 또한 최대화 하는 것이다.
( L2(C), L1(C) 둘 다 사전학습 된 모델에 fine-tuning 한다.)
마지막으로 성능향상을 위해 task마다 input의 형태를 변형시켜 넣어준다.
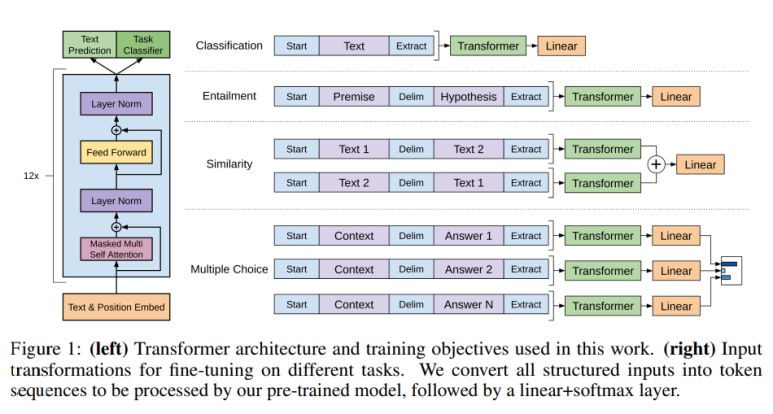
일단, 모든 input 형태에는 start <"s"> , end <"e"> 라는 랜덤 초기화(randomly initialized)된 token을 추가한다.
task마다 세부적으로 보면
- Classification (분류) : 그냥 Text 그대로 집어넣음
- Entailment (가정이 전제로 부터 나왔는가) : 전제 + delimiter(구획) + 가정 순으로 집어넣음
- Similarity (유사) : Text1,Text2의 유사도 판단을 할 때, 추가적으로 Text1,Text2의 순서를 바꿔서도 따로 transformer에 넣어준 다음 출력값을 더한 후 Linear layer에 넣음.
- Multiple Choice(다중 선택) : Context문장에 각각 delimiter + 정답 을 넣고 따로 transformer와 linear layer를 거치고 각 값들을 가지고 softmax 취해 여러개의 정답 중에 하나 선택.
2. 논문 분석
출처 입력


unlabeled data는 넘쳐나지만, labeled data는 부족 => trained model이 적절히 작동되기 힘듬
방대한 unlabeled data를 이용해 generative pre-training , 이후 task에 맞춰 discriminative fine-tuning
task마다 input transformation을 다르게 해 성능 향상. => 여러 task 성능향상을 보여줌.

labeled data만으로는 부족, 데이터가 충분하지 않고 다른 활용분야들에 대한 응용력을 학습 할 수 없다.
unlabeled data를 사용(leverage)하는 것이 중요. unlabeled data에서 좋은 표현들을 학습 할 수 있다면 이는 성능 부스트가 될수있다.
하지만 아까 글 처음에 설명한 문제점 2가지.
-
transfer(pre-training -> fine-tuning) 할 때 최적 목적함수가 무엇인지 확신할 수 없다.
-
pretrained 된 representation을 transfer할 때, 작업(task)의 종류에 따라 어떻게 다뤄야 하는지 모른다.
이런 문제점이 semi-supervised learning(준지도학습 : supervised learning에서 unlabeled dataset을 참조 학습)을 어렵게 한다.

전체적인 흐름은 일단, unsupervised pre-training과 supervised fine-tuning을 같이 하는 것을 사용함.
목표는 넓은 task들에 대해 적은 적응성을 같는것
=> 다양한 task들에도 효과적인 범용성있는 representation(형태)을 만들어 내는 것.
unlabeled data를 가지고 학습하는데 두 단계를 거침
-
unlabeled data를 가지고 , 그에 해당하는 목적함수를 최적화 시키는 신경망 모델을 미리 초기화한다.
-
이어서 이 학습된 신경망 모델의 parameter를 그대로 가져와 target task의 supervised 목적함수에 맞게 학습한다.
기본적으로 모델 구조로는 Transformer를 사용한다.
=> 다양한 task에 대해 성능이 잘 나온다. (긴 문장에도 강인)
transfer 도중에 task-specific한 input형태를 넣어주는데 이는 traversal-style approaches로 부터 비롯되었다고 한다.
traversal-style approaches를 찾아보면

구조화된 text input을 하나의 연속적인 token의 sequence처럼 넣는 것을 뜻한다.
시각화 하면

저기 참조된 [52]번 논문은 다음과 같고
T. Rocktäschel, E. Grefenstette, K. M. Hermann, T. Kocisk ˇ y, and P. Blunsom. Reasoning about entailment ` with neural attention. arXiv preprint arXiv:1509.06664, 2015.
https://arxiv.org/pdf/1509.06664.pdf
내용은 entailment task에서 두개의 text를 연속적으로 하나의 input으로 넣는 법이다.
논문 속 그림을 보자면,
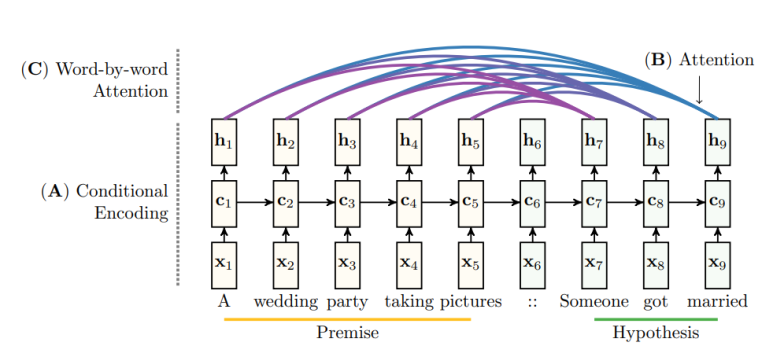
entailment 판단에서 Premise 뒤에 Hypothesis를 같이 넣어준다.
아무튼 이 기법을 잘 활용해 여러 Text를 task에 맞게 조금씩 다르게 집어넣어 성능을 높인다.
이후 Related Work로
-
Semi-supervised learning for NLP(supervised 와 unsupervised 둘다 사용)와
-
Unsupervised pre-training( unlabeled dataset에 대한 pre-training)
-
Auxiliary training objectives(보조 학습 목적합수: 메인 목적함수에 보조 목적함수도 최적화)가 나온다.

이후 위에서 설명했던, unsupervised pre-training과정과 이후 Supervised fine-tuning를 한다.
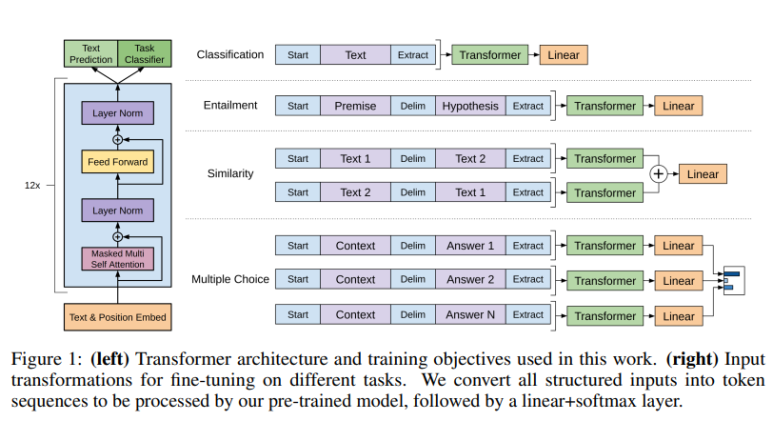
마지막으로 input 형태를 task에 맞게 변형시켜줌

input 변형에 대한 설명과 세부 구조.

unsupervised pre-training에 사용한 dataset은 다음과 같고

labeled data에 대한 supervised learning은
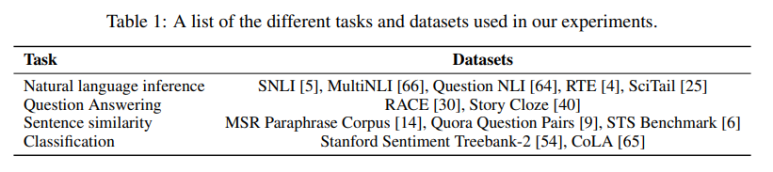
다음과 같다.

모델에 대한 구체적인 설명과, Fine-tuning에서의 hyperparameter 설명이다.
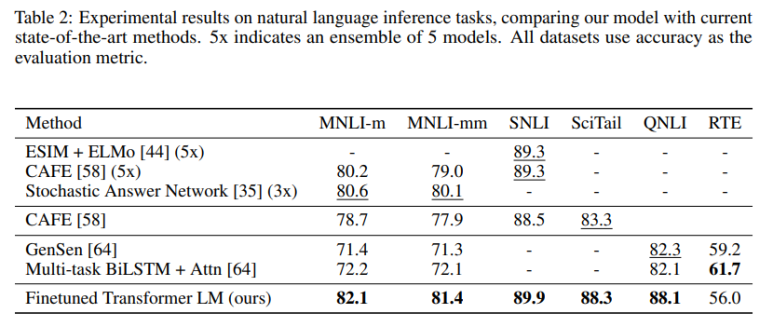
<Natural language inference 에 대한 성능 평가 (맨 마지막줄)>

Question and answering와 commonsense reasoning 성능 평가 (맨 마지막줄)

Semantic similarity와 classification
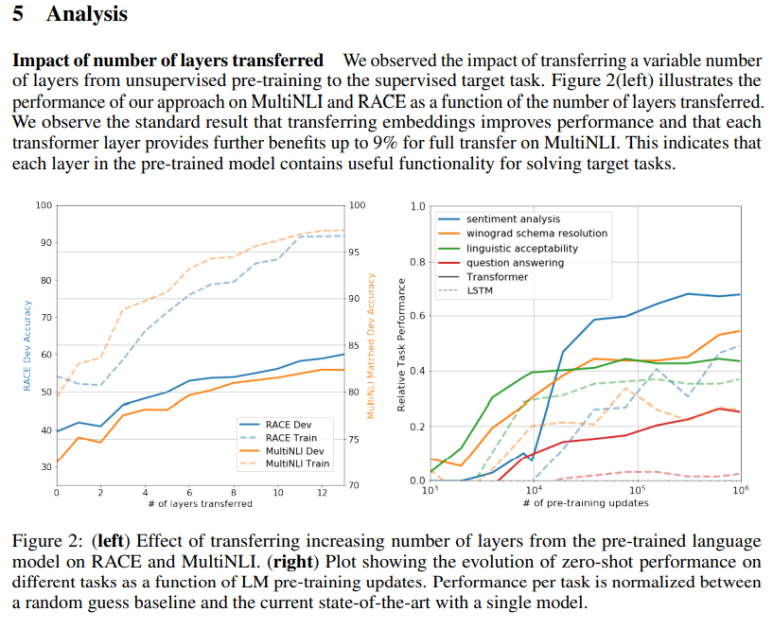
왼쪽 표는 Decoder 층의 개수에 따른 성능 증가 표이고 => 많아질수록 성능 증가
오른쪽 표는 Zero-shot(pre-training data를 0(zero)개 학습) performance이다. => pre-training 학습 데이터가 많아질수록 성능 증가. (점선은 transformer가 아닌 LSTM을 사용했을 때)
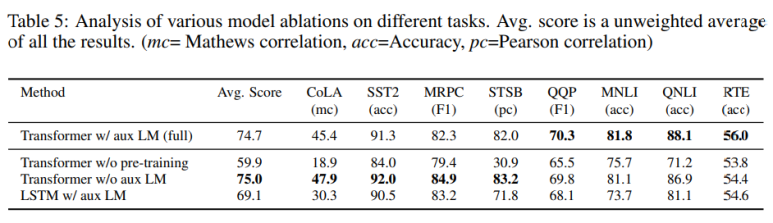
다양한 모델과 task 간 성능

ablation studies
ablation studies(추가 세부 연구)
-
보조 목적함수 없이 진행 => dataset이 크면 보조 목적함수가 있으면 좋지만 dataset이 작으면 없는것이 낫다.
-
Transformer과 LSTM 비교 => LSTM 사용하면 평균 5.6점 성능 낮아짐
-
pre-training없이 학습 => 14.8% 성능 감소

결론
unlabeled dataset에 녹아있는 보석같은 정보를 모델에 학습시킬 수 있는 pre-training을 사용하자.
