1-1. 데이터베이스 관리 - 물리적 데이터 구조 설계
물리적 저장장치에 논리적 개념의 데이터들을 저장하고 관리하는 과정
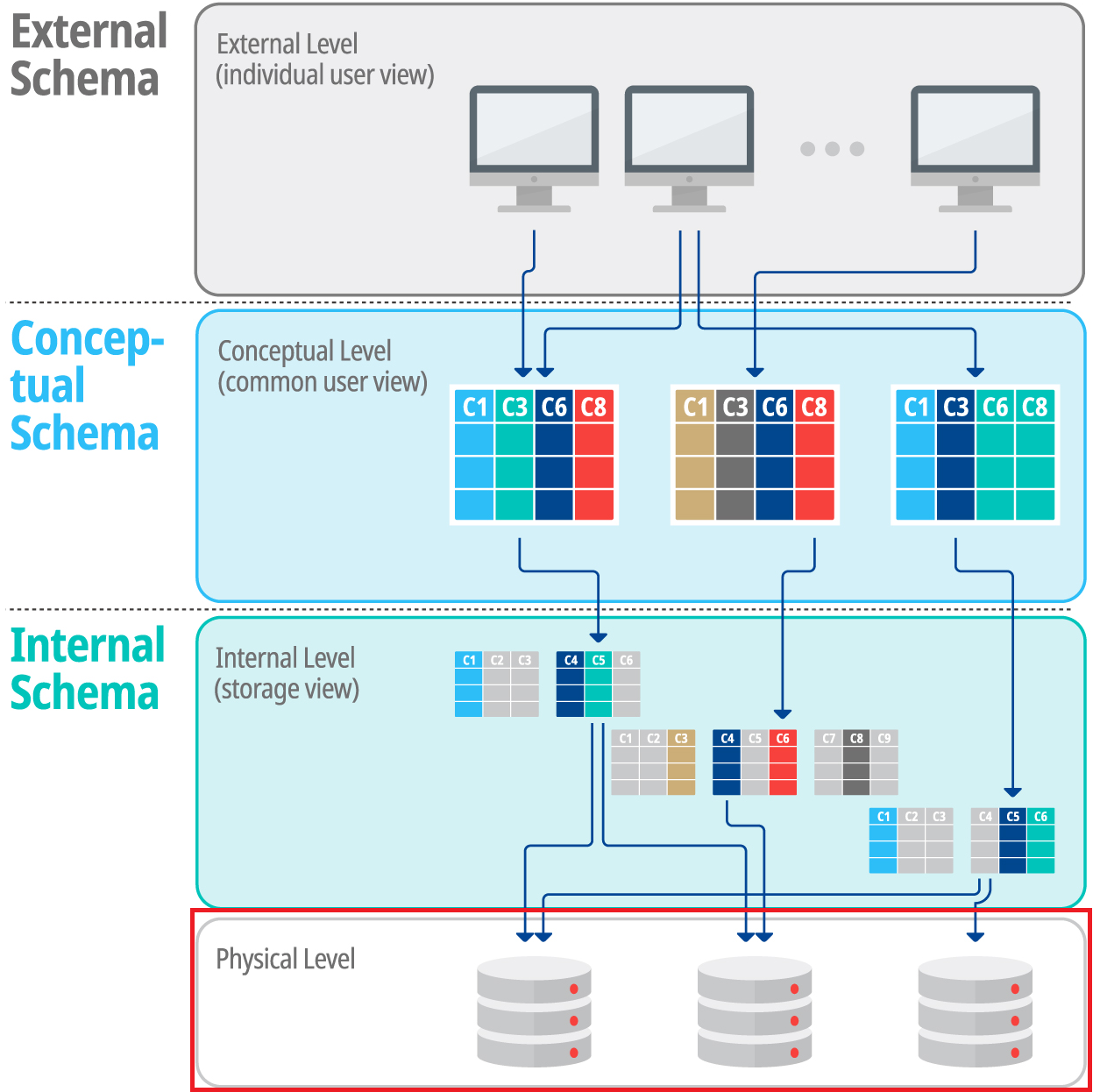
데이터베이스를 구축하는 과정에서 데이터를 물리적 저장장치에 저장하고, 논리적 구조에 매핑하는 작업을 진행하게 됩니다.
이 과정을 물리적 데이터 구조 설계 작업이라 하며, 데이터베이스 관리를 원활하게 하기 위해 테이블 스페이스와 인덱스 스페이스 개념을 인지해야 합니다.
테이블 스페이스란, 하나 혹은 여러 개의 파일로 구성된 데이터 저장구조를 말합니다. 데이터는 테이블 스페이스에 저장 후, 물리적인 HDD와 매핑됩니다.
인덱스 스페이스란, 말 그대로 인덱스를 저장하는 저장공간을 말하며 이 역시 물리적인 HDD 저장장치와 매핑됩니다.
이러한 데이터 구조를 저장하는 공간은 DB관리자가 관리하며, 이를 위한 계획을 수립한 후 구성해야 합니다. Row(Record), Column 등의 size를 확인하여 해당 공간의 볼륨(Volume)을 설정해야 하고, 향후 공간확장(Extent, 엔티티의 변화성)까지 고려해야 합니다.
또한 데이터베이스 성능을 고려하여 주기적으로 재편성 계획을 수립해야 합니다.
1-2. 데이터베이스 관리 - 인덱스, 해싱
데이터베이스 성능 향상을 위한 기법으로 인덱스와 해싱이 있습니다.
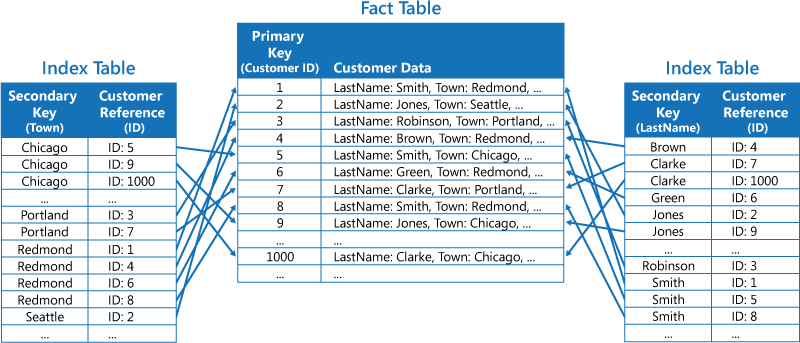
인덱스란, DB Table 내 data에 접근하기 위한 시작점을 말합니다.
인덱스를 참조용으로 구성한 테이블과, 데이터베이스를 구성하는 데이터와 함께 구성한 테이블이 있습니다. 인덱스를 구성하는 요소로 인덱스 키 및 포인터가 존재합니다.
인덱스 기법은 데이터 행에 접근하는데 참조할 수 있는 중요 요소로, 좀 더 빠른 데이터 조회가 가능하도록 해줄 수 있습니다.
해싱 기법은 데이터가 빠르게 접근할 수 있도록 key 값을 사용하는 개념입니다.
인덱스와 다른 개념은 아니지만, 인덱스를 구성할 때 해싱기법을 이용하므로 다소 상이한 부분이 있습니다.
key 값을 행의 물리적 위치로 가르키는 포인터로 변환하여 사용하는 랜더마이징 알고리즘을 사용하는 기법이기도 합니다.
우리가 흔히 사용하는 dictionary가 hashing 기법을 이용한 대표적인 자료구조이고, 인덱스와 마찬가지로 데이터를 빠른 시간에 조회할 수 있도록 해줄 수 있는 기법입니다.
인덱스
-
성능 이점
행에 대한 직접 접근점을 제공합니다.
테이블 행 유일성 및 무결성을 보장합니다. -
단점
검색의 효율성은 높지만 인덱스 설정 시 Column의 삽입/삭제/변경의 효율성은 저하되어, 인덱스 생성이 필요할 경우 모든 행에 대해 인덱스 공간을 마련해야 합니다.
또한 이로 인한 데이터 변경에 따른 추가적인 시간이 소요되며, 인덱싱이 다시 이루어질 경우 재편성이 요구됩니다. -
주의 사항
인스턴스가 적은 테이블은 인덱스 설정을 할 필요가 없으며, 데이터가 많을 때 효과가 있습니다.
데이터 값이 변경이 많을 경우, 인덱스 특성상 성능이 저하될 수 있습니다(인덱스와 별개로 Column 편성시 변동이 많은 데이터에 대한 Column을 맨 앞에 배치하는게 좋고, 변동성이 동일하다면 자주 접근하는 Column을 맨 앞에 배치하는게 좋습니다.)
중요한 조회일 경우 적종률이 전체의 20% 미만일 경우에 인덱스를 설정하는게 좋습니다. -
Primary key와 인덱스의 관계
Primary key 설정 후 해당 Record의 일부 Column만 참조한다면, Primary key가 선두 Column을 구성하는 경우에 인덱스를 사용하는게 좋습니다.
해싱

-
성능 이점
큰 자유공간으로 구성되어 효과적인 관리기능을 수행가능 합니다.
key를 사용하여 단 한번의 DB I/O 요구로 조회가능 합니다. -
단점
행이 하나이거나 적은 수인 테이블(look-up table)일 경우 접근이 원활하며, 행이 많거나 범위로 검색하는 경우 효과가 없습니다(Data 1개에 대해 접근하여 CRUD를 하는 경우에 효과적입니다). -
주의 사항
데이터 충돌을 최소화하기 위해 유일한 key값을 설정해야 합니다(key값의 유일성이 보장되어야 데이터 조회 및 CRUD가 원활히 진행됩니다).
소수의 Data에 대한 CRUD를 하는데 활용하므로, 변동이 많은 table에서 활용해야 효과가 높습니다.
2. 역정규화
엔티티(table) 및 속성(Column)을 추가하고 관리하는 과정을 통해
역으로 데이터 모델링을 수행하는 과정
정규화는 데이터 모델링 과정에서, 엔티티간 관계와 관계비율 등을 정의하여 DB구축을 위한 기본적인 정제과정을 의미합니다.
역정규화는 말 그대로 역으로 정규화하는 것, 구성한 엔티티(table) 및 속성(Column)을 추가 및 중복관리를 통해 데이터 모델링을 변경하거나 재편성하는 작업입니다.
따라서 역정규화를 위해선 table 및 Column을 변경해야 하므로, 이로 인한 신뢰성 저하 및 시스템 성능 변화 요소 등을 파악하는 것이 필요합니다.
MySQL에서 가장 대표적인 역정규화 쿼리문으로 join이 있으며, 이를 통해 알 수 있듯 여러 table의 관계를 재정립하고 변경하는 과정이 역정규화 과정입니다.
또한 관계된 테이블에 있는 외부 Column을 가져올 때 필요하며, 이 외 데이터가 복잡하여 쿼리문 작성이 불편하고 디스크 공간을 대용량으로 필요로 한 테이블이 있을 경우엔 역정규화가 필요한 대상으로 볼 수 있습니다.
선조인 테이블 기법
-
사용 시점
두개 이상 테이블이 어플리케이션에서 정기적으로 join될 경우, join 비용이 과다할 경우에 사용합니다. -
성능 이점
중복 Column은 포함이 안되고, 어플리케이션 수행시 절대적으로 필요한 Column으로만 구성됩니다.
정규화 테이블을 join하여 주기적으로 생성할 수 있습니다. -
단점
데이터 정확성 유지가 어렵습니다(정적 데이터에 유용합니다).
미러 테이블 기법
-
사용 시점
온라인 트래픽 발생 시 한 테이블을 통해 의사결정을 하거나, 해당 테이블을 정기적으로 사용할 경우 똑같은 테이블을 생성하고 유지해야할 경우(테이블 복사)에 사용합니다. -
성능 이점
전경처리(foreground, 트래픽)와 배경처리(background, 미러테이블 구성 후 의사결정하는 과정)의 동시성이 보장되고, 실시간 진행이 가능합니다. -
주의 사항
미러테이블을 통한 역정규화시 데이터 타임아웃 및 교착상태(race condition 등)를 고려해야하며, 의사결정을 위해 임시처리 개념으로 활용하는 것이 좋습니다(장기적 접근이 필요할 경우 data warehouse 접근방식이 필요합니다).
병합 테이블 기법
-
사용 시점
두 테이블이 1:1(one-to-one) 관계유형을 가지고 서로 fully manadatory일 경우에 사용합니다. -
성능 이점
두 테이블이 동시에 활용되고, 모두 사용성이 높을 때 활용도가 높습니다. -
주의 사항
다른 한 테이블의 크기가 비교적 클 경우 성능 효율성을 검토해야 하며, 데이터 모델링 시점에서 결정하여 해당 기법을 사용할 건지 사전에 고민해야합니다.
