[Java] Request Collapsing 전략을 도입하여 캐시중복적재를 방지 및 이를 통한 Redis 조회 부하를 감소할 수 있는 방안(*AOP를 중점적으로 활용하면서)
Java
1. 개요
현재 조회수 기능은 단건 데이터 및 이로 이루어진 목록에 대해 캐싱처리하여, Redis에 저장해두었다가 만료 후 원본데이터를 요청하여 반환 및 Redis에 다시 저장하는 로직으로 이루어진다.
이 상황에 대해 동시성 문제가 일어날 것이라고는 생각을 못하였는데, 좀 더 찾아보니 게시글에 대해 조회요청이 동시에 다수 발생할 경우, Redis에 캐싱데이터를 중복적재하는 문제와 데이터 만료 시점에 원본데이터를 중복 요청하는 등 성능 및 비용적으로 꽤 아쉬운 상황이 발생한다는 것을 알 수 있었다.
일전에서 Query side의 조회 성능을 극대화하기위해 Redis를 가용한 부분에 최대한 활용하는 등 안간힘을 써보았는데, 이번에는 여기에 더 나아가 시스템을 좀 더 효율적으로, 부하를 감소할 수 있는 방안을 깊게 이해하고 적용하게 되었다.
시스템을 조금이라도 더 효율적으로 구성할 수 있는 과정에 대해 정리해본다.
2. 문제상황
문제상황을 한마디로 요약하자면 동시성 문제이다.
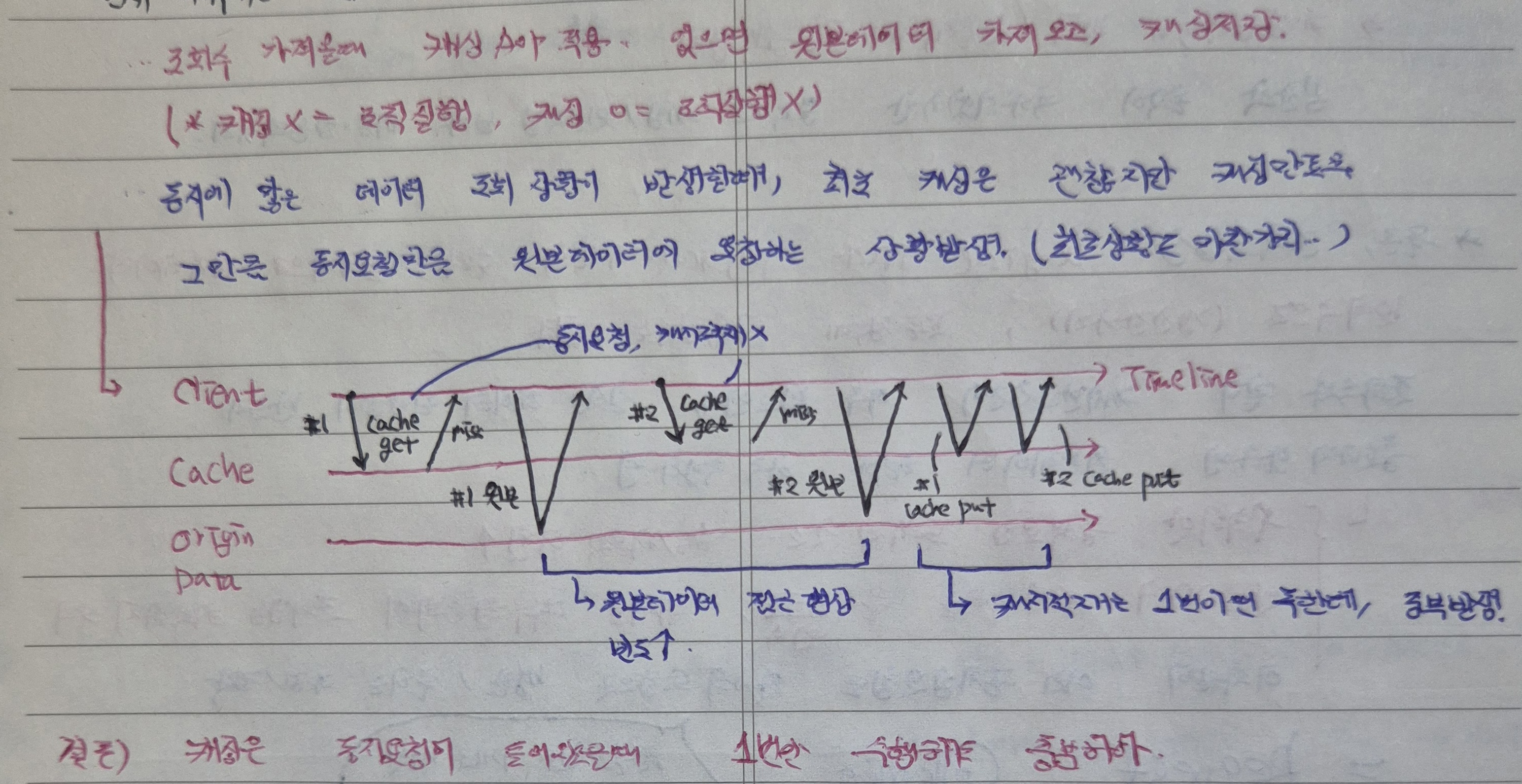
이 상황을 위와 같이 정리해보았는데, 이 문제 상황에 대해 쉽게 풀자면
- 특정 게시글에 대해 조회 요청이 동시에 발생한다.
- 캐싱데이터가 존재하지 않을 경우 이 요청들은 동시에 원본데이터를 요청한다.
- 또한 동시에 캐싱데이터를 적재한다.
이 원본요청 및 캐싱데이터 적재가 동시요청으로 인해 불필요하게 중복처리가 발생하는 것이 문제이며, 처리의 효율화와 이에 따른 Redis 부하를 감소하기 위해 어떠한 전략을 세울 수 있는지 고민해보았다.
3. 전략수립과정
지금의 비효율적인 소모를 제거하기 위한 핵심 전략은 세가지로 나누어 볼 수 있겠다.
3-1. 캐싱중복적재를 방지하기 위한 분산락 활용
- 분산락을 이용하여 캐싱적재의 중복을 방지한다.
현재 분산시스템에서 캐싱 요청이 동시에 발생하였을때 분산락을 활용, 분산락을 획득한 1개의 요청에 대해서만 캐싱 데이터 적재를 진행한다.
하지만 단순히 분산락만을 활용하여 중복적재를 방지할 경우, 나머지 요청들은 락획득을 위해 무한대기를 해야하는 또다른 문제상황이 발생한다.
이러한 상황을 방지하기 위해 분산락을 획득하지 못한 요청에 대해선 특정 결과를 반환하여 요청을 병합하도록 한다.
3-2. 요청병합 - Request Collapsing
- Request Collapsing
굳이 캐시 갱신을 기다리지 않고 캐싱처리 이전의 데이터를 응답하여 대기하지 않고 즉시적인 요청처리를 진행한다.
이에 대한 전략구상은 조회수 데이터가 Eventually Consistency 형태로 실시간 처리보다는 데이터 일관성에 초점을 맞추고 있고, 이에 따라 캐싱데이터 적재 시에도 엄격한 실시간 처리보다는 조회성능을 높일 수 있는 방향으로 설계하는 것이 타당하기때문에 가능하였다.
3-3. logical TTL, physical TTL 별도 관리
Request Collapsing이 이루어지기 위한 핵심전략은 logical TTL, physial TTL 시간을 나누어 Redis의 실제 데이터 만료시간(physical TTL)과 캐싱 갱신시 필요한 논리적 기준인 logical TTL을 별도로 관리한다는 점이다.
이를 통해 분산락을 획득한 최초 요청은 캐싱데이터가 언제 갱신이 되어야하는지 정확한 시간적 기준을 알고 있기 때문에 무분별한 캐싱 갱신을 진행하지 않는다.
4. 전략세부화
이제 구상한 전략을 어떠한 방향으로 구현할지 그 과정과 방법을 세부화해본다.

정리하면,
- 동시요청이 들어온 요청 중 최초 하나의 요청에 대해서만 분산락을 부여한다.
- 분산락을 부여받은 최초의 요청은 캐싱 갱신의 책임을 지며, 원본요청 후 해당 데이터를 응답하고 캐싱 갱신까지 진행한다.
- physical TTL이 지나지 않은 캐싱 데이터의 logical TTL이 지났을 경우 캐싱 갱신 기준에 해당하며, 분산락을 획득한 요청은 이를 판단하고 캐싱 데이터를 갱신한다.
- 분산락을 획득하지 못한 다른 요청들은 기존 캐싱 데이터를 응답받고 로직을 종료한다.
이처럼 동시적으로 발생한 요청에 대해 최초 요청 1건에 대해서만 캐싱적재의 책임을 위임하고, 나머지 요청은 기존 캐싱 데이터를 전달만 받도록 하여 흐름을 단순화하고 효율화한다.
참고로 위 도식도는 캐싱데이터가 없는 최초 요청에 대한 과정이며, 최초 요청의 경우 원본 데이터 요청까지는 동시적으로 발생가능하나 그 이후 적재 및 캐싱데이터 요청은 중복 발생이 이루어지지 않는다.
다만 앞서 언급한대로, 이 전략은 Eventually Consistency를 만족하는 조회수데이터에 대해서만 도입가능하며 모든 경우, 특히 실시간 데이터 처리가 필요한 문제상황에 대해서는 적용이 불가능한 전략임에 유의한다.
5. 구현
이제 본격적으로 구현해볼 차례인데, 일단 어느 메서드에 어떤 구현전략을 가질 것인지 큰 그림부터 차례대로 구현해보도록 해보자.
5-1. 적용시점(jointpoint 지정)
일단 조회수를 redis에서 읽어올 시점에 전략을 적용해야겠고,
- 해당 데이터를 redis에서 읽어오기 전에 조회수 캐싱 데이터를 먼저 확인한다.
- 캐싱 데이터 존재 확인 시 바로 캐싱하여 읽어오고, 존재하지 않으면 락 획득을 성공한 요청에 한해 캐싱 갱신 및 응답을 허용한다.
- 락 획득 실패 요청은 이전의 캐싱 데이터를 응답하도록 한다.
이 전략을 적용하기 위한 가장 큰 핵심 동작원리는 해당 로직을 공통관심사로 처리하여 Aspect로 처리하는 것이다.
이를 위해 아래와 같이 먼저 jointpoint를 지정해준다.
//@Cacheable(key = "#articleId", value = "articleViewCount")
/*
* Caching Aspect의 적용 대상(포인트컷)
* */
@OptimizedCacheable(type = "articleViewCount", ttlSeconds = 1)
public long count(Long articleId) {
log.info("[ViewClient.count] articleId={}", articleId);
try {
return restClient.get()
.uri("/v1/article-views/articles/{articleId}/count", articleId)
.retrieve()
.body(Long.class);
} catch (Exception e) {
log.error("[ViewClient.count] articleId={}", articleId, e);
return 0;
}
}기존 원본데이터를 가져오는 메서드에 @Cachaeable를 사용하였지만, 이 경우 일괄적인 캐싱확인 및 갱신만이 이루어지므로 중복적재를 피할 수 없다.
참고로, 기존 조회수 데이터를 가져오기 위한 key값은 아래와 같다.
view::article::%s::view_count캐싱을 통해 조회수 데이터를 가져올 경우 key를 별도 운용하여 다음과 같다.
articleViewCount::%s5-2. 어노테이션 정의
위에서 정의한 Aspect를 어노테이션으로 정의해주기 위해 Customized 어노테이션을 정의해준다.
/*
* Cachable 이외 캐싱 어노테이션 활용을 위한 어노테이션 정의(명세)
* - 이 어노테이션을 사용한 메서드들은 Aspect 정의에 의해 Aspect를 실행한다.
* - 런타임 시점에
* - 메서드에 붙일 수 있도록
* */
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface OptimizedCacheable {
String type();
long ttlSeconds();
}말 그대로 명세이다. 실제 기능 동작을 위해 Manager를 정의해주어야 한다.
5-3. Aspect
이제 위의 Aspect를 어떻게 처리하고 동작하게 할 것인가, Aspect Advice와 이에 대한 Bean을 Spring Application context에 등록해주어야겠다.
동작과정을 구체화하고 면밀히 파악하기 위해 주석 그대로 기록한다.
/*
* AOP의 동작시점과 동작로직을 구체화
* */
/*
* Cahcing 처리를 Customized AOP(Aspect)로 처리하기 위함 = Aspect.
* Cache 어노테이션을 정의하고
* 어느 시점에 처리할 것인지(Jointpoint의 pre? post? 결정.)
* */
@Aspect
@Component
@RequiredArgsConstructor //for final
public class OptimizedCacheAspect {
private final OptimizedCacheManager optimizedCacheManager;
@Around("@annotation(OptimizedCacheable)")
public Object around(ProceedingJoinPoint joinPoint) throws Throwable {
OptimizedCacheable cacheable = findAnnotation(joinPoint);
/*
* AOP로 추출할 수 있는 정보는 type 정보와 ttl Seconds에 대한 정보.
* 이외 jointpoint로 가져올 수 있는 정보(메서드 시그니처)는 매개변수..
* 서로 추출할 수 있는 정보가 다르므로 어노테이션 명세 등과 비교하면서 로직 구성해줄 것.
* */
/*
* 동작 = process 동작.
* */
/*
* 원본데이터 추출 = DataSupplier의 get() = 람다 그 자체!
* 즉 get()의 구현부인 return부가 람다식으로 표현됨
* 여기서는 viewClient의 조회수가 그 경우.
* */
return optimizedCacheManager.process(
cacheable.type(),
cacheable.ttlSeconds(),
joinPoint.getArgs(),
findReturnType(joinPoint),
() -> joinPoint.proceed()
);
}
/*
* joinPoint는 AOP가 감지한 메서드 호출 정보를 담고 있어요.
* joinPoint.getSignature() → 메서드 시그니처 정보 가져오기.
* (MethodSignature) signature → MethodSignature로 캐스팅해야 메서드 반환타입, 파라미터, 어노테이션 등의 상세 정보에 접근 가능.
* getAnnotation(OptimizedCacheable.class) → 해당 메서드에 붙은 어노테이션 인스턴스를 가져오기.
* 즉, AOP가 동작할 때, 실제 메서드에서 어노테이션 정보(메서드 실행 정보)를 가져오기 위해 필요합니다.
* */
private OptimizedCacheable findAnnotation(ProceedingJoinPoint joinPoint) {
Signature signature = joinPoint.getSignature();
MethodSignature methodSignature = (MethodSignature) signature;
return methodSignature.getMethod().getAnnotation(OptimizedCacheable.class);
}
/*
* 어떤 return Type이 올지 모른다..컴파일 시점에서 강제하지 않기 위해 Class<?>
* */
private Class<?> findReturnType(ProceedingJoinPoint joinPoint) {
Signature signature = joinPoint.getSignature();
MethodSignature methodSignature = (MethodSignature) signature;
return methodSignature.getReturnType();
}
}여기서 살펴볼 점은 다음과 같다.
- 포인트컷의 advice를 around로 설정하여 메서드의 호출 전/후 모두 실행하도록 한다(캐싱중복 확인 및 갱신 등의 과정을 단기간 내 polling하는 것과 유사한 효과를 가지도록 하는 목적)
- 메서드 실행 정보(Aspect를 붙였을때의 type과 ttl 정보)는 jointpoint의 method signature 정보에서 추출해온다.
- 메서드의 매개변수 정보는 jointpoint의 args 정보에서 추출해온다.
- 메서드의 원본데이터 추출 로직은 jointpoint의 proceed 정보에서 추출해오고, 이에 대한 정보를 런타임에서 얻도록 하기 위한 함수형 프로그래밍을 적용한다.
이를 통해, @Around("@annotation(OptimizedCacheable)")로 정의해준대로 OptimizedCacheable 어노테이션을 사용한 메서드는 메서드 호출 전/후로 해당 Aspect 동작을 진행한다.
5-4. 함수형 프로그래밍 동작을 위한 전략 인터페이스 정의
위에서 사용한 함수형 프로그래밍을 위해 전략 인터페이스를 지정해준다.
/*
* 원본데이터를 요청하기 위한 책임
* 원본데이터 = Generic Type(T)
* */
/*
* 단 하나의 추상메서드 보유 = FunctionalInterface
* 실제 구현 시 람다식으로 () -> ~~~~ 형태로 축약가능(return ~ -> () -> ...)
* */
@FunctionalInterface
public interface OptimizedCacheOriginDataSupplier<T> {
/*
* 전략패턴, 실제 구현시 람다식 대체 가능
* generic 사용하여 다양한 타입의 클래스를 일괄적으로 다룰 수 있도록 함(이를 T로 대체)
* */
/*
* class<T> interface<T> - 타입변수, 컴파일시점에 결정, 변수 그 자체.
* class<T> class - 타입객체, 런타임시점에 해당 객체를 참조하게되는 타입객체.
* */
T get() throws Throwable;
}함수형 인터페이스를 사용할 수 있는 이유는 위와 같이 전략 인터페이스의 추상 메서드를 1개로만 정의해주었기 때문이고, 위와 같이 람다식을 통해 간편하게 매개변수화해 줄 수 있다.
5-5. 실제 Aspect 동작의 진행 - OptimizedCacheManager
이제 실제 동작을 처리하기 위한 로직이 담겨져 있는 OptimizedCacheManager의 로직을 정리할 차례이다.
@Component
@RequiredArgsConstructor
public class OptimizedCacheManager {
private final StringRedisTemplate redisTemplate;
private final OptimizedCacheLockProvider optimizedCacheLockProvider;
private static final String DELIMITER = "::";
/*
* 캐싱처리 정의
* */
/*
* 참고
* Class<?> : returnType이라는 타입객체 사용시 컴파일 시점에 그대로 사용 가능
* CLass<T> : returnType 타입객체의 형태를 컴파일 시점에 반드시 특정하거나 캐스팅해주어야 사용 가능
* */
public Object process(String type, long ttlSeconds, Object[] args, Class<?> returnType,
OptimizedCacheOriginDataSupplier<?> originDataSupplier) throws Throwable {
/*
* cache가 어떤 type인가? 그 type의 indicator = type
* 컴파일시점에 강제할 필요가 없으며, 범용적 처리 로직을 생성하고자 Class<?> 처리.
* */
String key = generateKey(type, args);
/*
* key에 대한 캐싱객체가 존재하지 않는다면 refresh(갱신)
* 지금의 요청이 첫 요청이므로 바로 캐싱에 적재해주면 된다.
* */
String cachedData = redisTemplate.opsForValue().get(key);
if (cachedData == null) {
/*
* key가 없다는 것은 캐싱적재가 필요하다는 의미,
* 원본데이터를 요청해서 다시 캐시에 적재하는 것
* */
return refresh(originDataSupplier, key, ttlSeconds);
}
/*
* 캐싱객체가 존재한다면 역직렬화하여 받아온다.
* 이 요청이 첫번째 요청이 아님.
* */
OptimizedCache optimizedCache = DataSerializer.deserialize(cachedData, OptimizedCache.class);
if (optimizedCache == null) {
/*
* 역직렬화 안되었을 경우 대비 : 재역직렬화
* */
return refresh(originDataSupplier, key, ttlSeconds);
}
/*
* expiredAt = "언제" 캐시데이터가 만료되는가 그 시각에 대한 "특정"
* 현재시각 기준 + 5초 넘기지 않았다면 아직 physical TTL 이전으로
* 캐싱객체 존재..parse해서 받아온다.
* 다만 logcial을 넘겼다면 (이 아래) 데이터 갱신 필요하다.
* */
if (!optimizedCache.isExpired()) {
return optimizedCache.parseData(returnType);
}
/*
* 이 이후의 로직은 만료 이후의 시점..락 획득을 하고 캐싱 적재, 실패 시 그냥 기존 캐싱객체 반환
* 캐싱객체가 있지만 락획득실패 시 받아온 캐싱객체 그대로 반환
* */
if (!optimizedCacheLockProvider.lock(key)) {
return optimizedCache.parseData(returnType);
}
/*
* 락획득성공 -> 캐싱갱신 및 적재
* 최종적으로 락 해제
* */
try {
return refresh(originDataSupplier, key, ttlSeconds);
} finally {
optimizedCacheLockProvider.unlock(key);
}
}
/*
* 캐싱 갱신이 필요할 경우
* 원본 데이터 객체를 가져와서 캐싱적재.
* */
private Object refresh(OptimizedCacheOriginDataSupplier<?> originDataSupplier, String key, long ttlSeconds) throws Throwable {
Object result = originDataSupplier.get();
/*
* 전달 매개변수는 logical TTL
* 실제 redis에 반영하는 physical TTL은 위에서 정의한 logical TTL + 5sec.
* */
OptimizedCacheTTL optimizedCacheTTL = OptimizedCacheTTL.of(ttlSeconds);
OptimizedCache optimizedCache = OptimizedCache.of(result, optimizedCacheTTL.getLogicalTTL());
redisTemplate.opsForValue()
.set(
key,
DataSerializer.serialize(optimizedCache),
optimizedCacheTTL.getPhysicalTTL()
);
return result;
}
/*
* redis에 저장하기 위한 key 생성
* */
private String generateKey(String prefix, Object[] args) {
/*
* prefix = 'prefix'
* args = ['key0', 'key1'];
* prefix::key0::key1
* */
return prefix + DELIMITER +
Arrays.stream(args)
.map(String::valueOf)
/*
* Stream 각각의 요소를 ::로 concat하면서 이어붙여 collect(String)
* */
.collect(joining(DELIMITER));
}
}이에 대한 로직을 세부적으로 찬찬히 살펴보도록 하자.
5-5-1. 최초 캐싱이 없을 때에는 모든 요청들이 일단 원본데이터를 추출해야 한다.
최초 캐싱이 없는 상태에서 동시성 요청이 발생하였다면, 모든 요청들은 우선적으로 원본데이터를 추출해야 이 데이터를 그대로 응답값으로 반환할지 캐싱데이터를 적재할지 판단할 수 있게 된다.
판단기준은 분산락 획득이며, 중요한 것은 최초 요청 시에는 일단은 반드시 원본 데이터를 추출하여 가지고 있어야 한다는 점이다. 중요한 전제조건이다.
String cachedData = redisTemplate.opsForValue().get(key);
if (cachedData == null) {
return refresh(originDataSupplier, key, ttlSeconds);
}즉, Redis에 key가 없으면 바로 원본 데이터 조회 후 캐싱한다.
핵심 포인트는
-
분산락을 먼저 확인하지 않는 이유로, "캐싱된 데이터가 아예 없는 경우"라면, 락 없이도 refresh를 바로 수행해도 안전하다. 아무도 이 key를 캐싱하지 않았으므로 중복 적재를 피할 필요가 없고, 첫 요청자는 그냥 데이터를 가져와서 캐싱하면 되기 때문이다.
-
이 이후에 동시 요청이 여러 개 들어올 경우, 첫 요청자가 아직 캐싱을 완료하기 전 다른 요청이 들어오면 이 경우 원본 데이터 중복 호출 가능 → 이게 Request Collapsing 대상이다.
즉, 락을 먼저 걸면 물론 안전하지만 최초 요청이 발생하였을때 성능 상 오버헤드가 발생할 수 있다(불필요한 Collapsing).
또한 전략을 어디에 도입할 것인지도 중요한 관심사이다.
현재 전략에서는 캐시 존재 여부 → expired 여부 → 락 획득 순서로 하는데, 이미 존재하는 데이터만 동시 요청 병합(락) 대상으로 삼고 있음에 유의한다.
5-5-2. logical TTL과 physical TTL을 분리하여 캐시갱신의 기준을 제공한다.
캐시갱신이 이루어지는 시점은 캐싱데이터가 물리적으로는 남아있는데, 논리적인 기준을 지난 시점일 경우이다.
이에 대한 동작이 이루어지는 시점이 바로 아래의 분기이다.
if (!optimizedCache.isExpired()) {
return optimizedCache.parseData(returnType);
}| 구분 | 설명 |
|---|---|
| Logical TTL | 애플리케이션에서 보는 캐시 만료 기준. isExpired()는 이 TTL 기준으로 만료 여부 판단. |
| Physical TTL | 실제 Redis에 저장되는 TTL. Logical TTL + 5초 정도로 설정. |
참고로 캐싱 데이터 적재 기준이 1초이므로, 이 정책적 TTL이 logical TTL(=1sec), 물리적 TTL은 여기에 5초를 더한 6초이다.
세부적으로 살펴보면,
- cachedData == null이 아닌 경우, 캐시는 Redis에 존재하지만 이미 Logical TTL이 만료된 상태일 수 있기에, 원본 데이터 갱신 필요하다.
- Physical TTL은 Redis에서 삭제될 때까지 남아있지만, Logical TTL을 초과하면 락을 걸어 Request Collapsing 수행 후 갱신한다.
즉, isExpired() 검사는 Request Collapsing 대상 여부를 결정하기 위한 단계라 볼 수 있다.
5-5-3. Request Collapsing
최종적으로 Request Collapsing이 발생하는 시점은 락획득을 실패하였을때 기존 원본데이터로 응답해주거나, 락획득을 성공하였다면 캐시를 갱신해주는 것이다.
if (!optimizedCacheLockProvider.lock(key)) {
return optimizedCache.parseData(returnType);
}
try {
return refresh(originDataSupplier, key, ttlSeconds);
} finally {
optimizedCacheLockProvider.unlock(key);
}최종적으로는 optimizedCacheLockProvider.unlock(key);를 통해 락 해제를 한다.
5-5-4. Manager 처리로직 요약
위의 처리 과정을 최종적으로, 간략하게 나타내면 아래와 같다.
- Redis에서 key 조회
└─ 없으면 → 바로 refresh - 캐시 존재 → 역직렬화
└─ 실패하면 → refresh - 캐시 존재 & 역직렬화 성공 → Logical TTL 확인
└─ 만료 안됨 → 반환 - 캐시 존재 & Logical TTL 만료 → 락 시도
└─ 락 획득 실패 → 기존 데이터 반환
└─ 락 획득 성공 → refresh 후 락 해제
5-6. Optimized Cache 도메인 정의
Optimized Cache 도메인을 정의하여 해당 정책정보 등에 대해 정의해준다.
/*
* data를 Redis에 저장하기 위한,
* 일종의 Wrapper 클래스.
* */
/*
* 참고 : Getter -> 멤버변수를 getter 메서드화 할 뿐이고, 내부 메서드는 그대로 사용하는 것
* 이때 멤버변수를 getter 메서드화할 경우 getter 프로퍼티에 맞게 변형한다.
* */
@Getter
@ToString
public class OptimizedCache {
/*
* Redis에 저장할 문자열 데이터
* */
private String data;
/*
* Logical TTL
* 실제로는 Time API와 TTL을 더해서 만료시각을 저장
* */
private LocalDateTime expiredAt;
public static OptimizedCache of(Object data, Duration ttl) {
OptimizedCache optimizedCache = new OptimizedCache();
optimizedCache.data = DataSerializer.serialize(data);
//ttl만큼 유효..현재시각 + logical ttl = application에서 바라보는 expiredAt.
optimizedCache.expiredAt = LocalDateTime.now().plus(ttl);
return optimizedCache;
}
/*
* logical TTL 지났는지 확인
* Jackson 직렬화할때 is메서드로 getter 프로퍼티에 해당하여 직렬화대상,
* 하지만 객체화하기위한 조건 메서드로 사용하므로 Redis에는 필요없기에, JsonIgnore하여 직렬화대상에서 제외한다.
* */
@JsonIgnore
public boolean isExpired() {
return LocalDateTime.now().isAfter(expiredAt);
}
/*
* 데이터를 특정 dataType에 맞게, 객체형태의 데이터를 역직렬화.
* */
public <T> T parseData(Class<T> dataType) {
return DataSerializer.deserialize(data, dataType);
}
}5-7. 분산락 및 TTL 정책 정의
마지막으로 분산락과 TTL 정책을 정의해준다.
/*
* 캐시갱신 요청에 대해 분산락을 획득시도,
* 획득에 성공한 요청에 한해 캐시적재를 가능하도록 한다
* = 캐시 중복적재를 방지
* */
@Component
@RequiredArgsConstructor
public class OptimizedCacheLockProvider {
private final StringRedisTemplate redisTemplate;
private static final String KEY_PREFIX = "optimized-cache-lock::"; //key prefix
private static final Duration LOCK_TTL = Duration.ofSeconds(3); //TTL
/*
* 단순히 key가 있는지만 확인, 없을 경우 획득(=TTL 3sec, Redis String)
* 있을 경우 선점 불가(=false)
* */
public boolean lock(String key) {
return redisTemplate.opsForValue().setIfAbsent(
generateLockKey(key),
"",
LOCK_TTL
);
}
/*
* 분산락 제거(delete)
* */
public void unlock(String key) {
redisTemplate.delete(generateLockKey(key));
}
private String generateLockKey(String key) {
return KEY_PREFIX + key;
}
}/*
* 정책적으로 정한 logcial TTL보다
* 실제 데이터 존재시간인 physical TTL을 더 길게 설정하도록 해주는 클래스
* physical TTL = logical TTL + 5sec.
* */
@Getter
public class OptimizedCacheTTL {
private Duration logicalTTL;
private Duration physicalTTL;
public static final long PHYSICAL_TTL_DELAY_SECONDS = 5;
public static OptimizedCacheTTL of(long ttlSeconds) {
OptimizedCacheTTL optimizedCacheTTL = new OptimizedCacheTTL();
optimizedCacheTTL.logicalTTL = Duration.ofSeconds(ttlSeconds);
optimizedCacheTTL.physicalTTL = optimizedCacheTTL.logicalTTL.plusSeconds(PHYSICAL_TTL_DELAY_SECONDS);
return optimizedCacheTTL;
}
}6. 프로젝트 구성

참고로 이 Cache 도메인/Aspect 등은 모두 CQRS로 나눈 주 도메인인 article-read 도메인에 위치해주었으며, 그 산하 cache 레포지토리로 구성해주었다.
어찌보면 util성 도메인이지만, 필요한 곳이 명확하게 정해져있기도 하고 정책적으로 변경이 발생하여도 해당 도메인에 국한적 적용이 필요한 도메인이기에 위와 같이 프로젝트를 구성해주었다.
7. 결론
이와 같이 캐싱처리를 공통관심사로 처리하여, 이를 Aspect화하고 조회수 추출 메서드 호출 전/후로 캐싱처리 및 원본데이터 추출을 정책에 따라 각각 1회만 시행 및 Request Collapsing 하도록 구현하였다.
이를 통해 캐싱의 중복 적재를 방지하고, 불필요한 동시 요청들에 대해서는 일단은 과거의 캐싱데이터를 추출하도록 의도함으로써 분산락으로 인한 무한대기 상황도 미연에 방지해두도록 의도하였다.
개선을 위한 방안은 어디에서든 적용가능하고 구현해낼 수 있다. 다만 그것에 따른 트레이드 오프나 실무적 타당성이 적합한지가 중요한 문제일 것이다.
상황적으로 잘 판단하고 설계하고 구현하는 마음가짐을 잊지않도록 한다.
