1. 정렬
sort, 데이터를 특정 기준에 따라 나열하는 것.
일반적으로 상황 및 조건에 따라 적절한 알고리즘이 공식처럼 사용된다.
- 데이터 개수가 적을때
- 데이터 개수가 많지만, 특정 범위로 한정되어 있을때
- 이미 데이터가 거의 정렬되어있는 경우
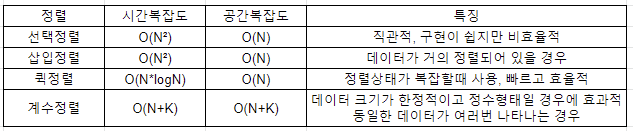
1-1. 선택정렬
처리되지 않은 데이터 중, 가장 작은 데이터를 선택하여 맨 앞으로 이동시키는(바꾸는) 알고리즘이다.
시간복잡도는 등차수열 공식에 따라 O(N^2)이다.
array = [7, 5, 9, 0, 3, 1, 6, 2, 4, 8]
for i in range(len(array)):
min_index = i
for j in range(i+1, len(array)):
if array[min_index] > array[j]:
min_index = j
array[min_index], array[i] = array[i], array[min_index]
print(array)1-2. 삽입정렬
처리되지 않은 데이터를 하나씩 골라 적절한 위치를 판단하면서 삽입하는 알고리즘이다.
이중 반복문을 사용하여 선택정렬과 마찬가지로 O(N^2)의 시간복잡도를 가지지만, 데이터가 어느정도 정렬되어있는 상태라면 선택정렬보다 더 효율적으로 적용가능할 수 있다.
array = [7, 5, 9, 0, 3, 1, 6, 2, 4, 8]
for i in range(1, len(array)):
for j in range(i, 0, -1): #인덱스 i부터 1까지 1부터 감소
if array[j] < array[j-1]:
array[j], array[j-1] = array[j-1], array[j]
else:
break #현재 반복문 종료, 다음 반복 강제 실행
print(array)1-3. 퀵정렬
기준데이터(pivot)을 설정해서 pivot값을 기준으로 작은 데이터와 큰 데이터를 탐색 및 자리변환을 하면서 pivot을 기준으로 데이터 묶음을 나눈다.
병합정렬과 더불어 일반적인 정렬 알고리즘에 많이 사용되는 알고리즘이며, 프로그래밍 언어 자체적으로 정렬 라이브러리로 활용되기도 한다.
기본적인 퀵정렬은 첫번째 데이터를 기준 데이터(pivot)으로 설정하고, 데이터묶음이 나눠지면 각 데이터묶음에 대해 퀵정렬을 재귀호출하여 진행하는 과정을 반복한다.
시간복잡도는 평균적으로 O(N*logN)이며, 이미 정렬이 어느정도 진행된 경우, pivot이 편중되어 정렬이 진행되므로 O(N^2)까지 복잡도가 늘어난다.
array = [7, 5, 9, 0, 3, 1, 6, 2, 4, 8]
def quick_sort(array, start, end):
if start >= end : #정렬원소가 1개일 경우 정렬완료, 재귀종료
return #정렬된 상태이므로 별도 반환 값이 없어도 됨
#전체 함수의 return을 유심히 살펴볼 것
pivot = start
left = start+1
right = end
while left <= right:
#피벗보다 큰 데이터
while left <= end and array[left] < array[pivot]:
left = left+1
#피벗보다 작은 데이터
while right > start and array[right] > array[pivot]:
right = right-1
if left <= right: #엇갈리지 않은 경우
array[left], array[right] = array[right], array[left]
else : #엇갈린 경우
array[right], array[pivot] = array[pivot], array[right]
quick_sort(array, start, right-1)
quick_sort(array, right+1, end)
quick_sort(array, 0, len(array)-1)
print(array)※ 파이썬의 코드가 간결하고, 간단하게 복수의 기능을 구현할 수 있다는 점을 활용하여 코드를 간결하게 나타낼 수 있다.
전체적으로 함수를 사용한다고 할 때, 함수의 return 값이 존재하는지 혹은 어떤 형태로 return하는지 판단해서 재귀탈출조건 등의 return 구문을 잘 설정해준다.
array = [7, 5, 9, 0, 3, 1, 6, 2, 4, 8]
def quick_sort(array):
print(array)
if len(array) <= 1:
#left_side에서 첫번째 원소가 0일 경우, array가 empty될 수 있음
#따라서 탈출조건은 empty경우를 고려하여 =< 1이 되는 것이 좋음
return array
pivot = array[0] #pivot값
tail = array[1:] #pivot을 제외한 리스트
left_side = [x for x in tail if x <= pivot]
#데이터묶음을 pivot보다 작은 값들로
right_side = [x for x in tail if x > pivot]
#데이터묶음을 pivot보다 큰 값들로
return quick_sort(left_side) + [pivot] + quick_sort(right_side)
print(quick_sort(array))1-4. 계수정렬
특정한 조건(데이터 크기 범위가 제한되고, 정수형태로 표현할 수 있을 때)에서 매우 빠르게 동작할 수 있는 정렬의 한 방버이다.
시간복잡도는 언제나 O(N+K)이다(N은 데이터 개수, K는 데이터 중 최대 값).
동일한 데이터가 여러 번 등장할때 효과적으로 활용할 수 있다.
1-5. 적용 예시
두개의 배열 A, B가 있다.
두 배열은 N개의 원소로 구성되어있고, 모두 자연수이다.
이때 최대 K번의 바꿔치기를 할 수 있는데, 바꿔치기란 배열A,B의 원소를 서로 바꾸는 작업을 의미한다.
최종적을 배열 A의 원소 합이 최대가 되도록 알고리즘을 구성하고자 할 때, 만들 수 있는 배열 A의 모든 원소값 합계의 최대값은?
- 첫번째 줄에 N, K가 공백을 기준으로 입력된다.
- 두번째 줄에 배열A, 세번째 줄에 배열B가 입력된다.
이때 핵심 아이디어는, 매번 배열 A에서 가장 작은 원소를 고르고 배열 B의 최대 원소와 교체한다는 점이다.
- A는 오름차순 정렬, B는 내림차순 정렬
- A의 원소가 B보다 작을 경우에만 교체를 진행
import sys
n, k = map(int, sys.stdin.readline().split())
a = list(map(int, sys.stdin.readline().split()))
b = list(map(int, sys.stdin.readline().split()))
a.sort()
b.sort(reverse=True)
for i in range(k):
if a[i] < b[i]:
a[i], b[i] = b[i], a[i]
else:
break #바로 다음 반복문 실행
print(sum(a))2. 정렬 간 비교