17. 플로이드-와샬 알고리즘
floyd-warshall, 모든 노드를 출발점으로 지정하고, 모든 노드에 대한 최소비용 경우의 수를 구하는 알고리즘이다.
다익스트라가 특정 노드를 출발점으로 지정한다면, 플로이드는 존재하는 노드 모두 출발점으로 고려한다.
17-1. 모든 노드에 대한 최소비용 경로를 구하는 과정
플로이드-와샬 알고리즘은 기본적으로 2차원 배열을 활용하며, 기준점이 되는 노드는 출발점이 아닌 거쳐가는 중간 지점을 의미한다(플로이드 와샬 알고리즘의 기준 자체가 중간 지점).
※ 다익스트라에서 행(기준점이 되는 노드)은 노드 출발점을 의미한다.
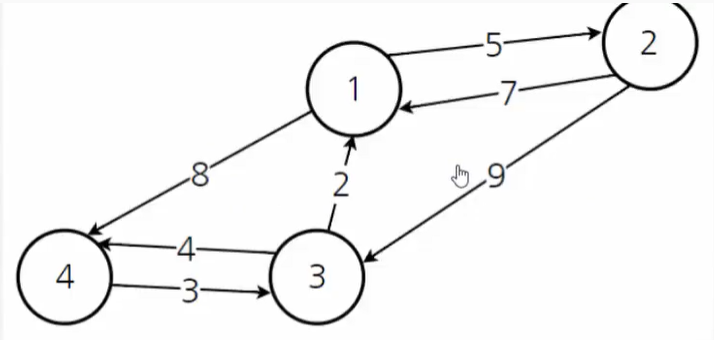
위 graph에서 기본적인 비용을 작성한 배열을 생성한다.
다익스트라에서도 마찬가지이지만, 노드가 인접하지 않은 경우엔 해당 비용은 무한으로 설정해준다.
graph = [
[0, 5, INF, 8],
[7, 0, 9, INF],
[2, INF, 0, 4],
[INF, INF, 3, 0]
]플로이드 와샬 알고리즘 구현 과정은 아래와 같다.
- 거쳐가는 노드를 설정한다.
- 노드 1을 설정하였을때, 노드1과 인접한 행렬 및 본인에 대한 비용이 아닌 나머지 부분에 대해 최소비용을 고려하면서 2차원 배열을 고쳐나간다.
- 노드 1을 거쳐가는 경로로 설정하였을때 탐색 대상이 되는 행렬위치는 아래와 같다.
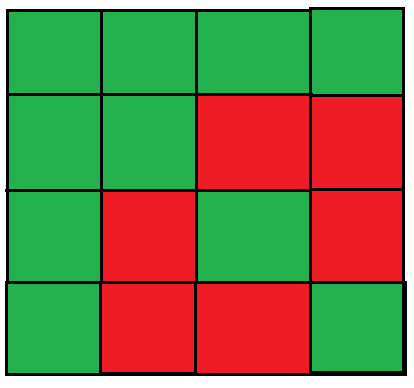
17-2. 시간복잡도
플로이드-와샬 알고리즘은 3중반복문을 사용하는 알고리즘이므로, 시간복잡도가 node개수의 세제곱만큼 비례하여 늘어난다.
따라서 기본적으로는 다익스트라 알고리즘을 활용하는 것이 훨씬 유리하다(시간복잡도가 O(N*log(N))).
다만 node개수가 많지 않고 간선의 개수도 너무 많지 않으면 플로이드 와샬 알고리즘을 활용하는 것이 유리할 수 있으므로 상황에 따라 잘 선별하여 사용하도록 한다.
17-3. 알고리즘 구현
최초 거리에 대한 배열을 생성할때 깊은 복사(얕은 복사시 각 요소값이 반영되지 않는다)에 유의한다.
node = 4
INF = 1000000
graph = [
[0, 5, INF, 8],
[7, 0, 9, INF],
[2, INF, 0, 4],
[INF, INF, 3, 0]
]
def floydWarshall():
d = [[0] * node for _ in range(node)]
for i in range(node):
for j in range(node):
d[i][j] = graph[i][j]
##k는 거쳐가는 노드
for k in range(node):
#i는 출발노드
for i in range(node):
#j는 도착노드
for j in range(node):
if d[i][k] + d[k][j] < d[i][j]:
d[i][j] = d[i][k] + d[k][j]
for i in range(node):
for j in range(node):
print(d[i][j])
floydWarshall()