1. 리눅스 exec() 함수
리눅스 exec() 함수는 프로세스의 내용을 다른 실행 파일의 내용으로 덮어씌우는 기능을 제공하며, 인자 및 기능에 따라 다양한 형태로 존재합니다.
1-1. 개요
리눅스 프로세스와 exec() 함수의 연관성은 shell 프로그램과 fork() 함수로부터 기반합니다.
리눅스 운영체제에서 프로세스가 생성된다는 것은, 가상메모리 공간에 Stack, Heap, BSS, DATA, TEXT 의 프로세스 구조를 만드는 과정을 의미합니다.
이러한 프로세스들은 기본적으로 리눅스 운영체제 실행시 최초 생성되는 init 프로세스의 자식 프로세스입니다.
- fork() 함수
fork()함수와 exec()함수는 내부적으로 또 하나의 shell 프로그램을 만들 때 반드시 활용되는 두가지 핵심 함수로, 위 내용에 대한 사전지식이 뒷받침되어야 원활한 함수 사용이 가능합니다.
fork() 함수는 부모 프로세스로부터 자식 프로세스를 생성하는 함수로, 위에 기술하였듯이 부모프로세스로부터 자식프로세스를 만드는 과정입니다.
즉 완전히 새로운 프로세스 공간을 만들어, fork()를 호출한 부모프로세스의 내용을 모두 복사합니다.
→내용만 같으며, pid는 서로 다른 완전히 새로운 프로세스입니다.
- exec() 함수
exec() 함수는 복사의 기능이 아닌, 덮어쓰기의 기능입니다.
다시 말해 exec() 함수를 호출한 프로세스 내에서 exec() 함수의 인자로 받은 실행파일(바이너리 이미지 파일)을 덮어 씌우게 됩니다.
이때 실행파일의 바이너리 이미지 파일, 즉 코드를 exec() 함수를 호출한 프로세스의 TEXT, BSS, DATA 영역에 그대로 쓰여집니다.
덮어 씌워지는 과정을 통해 기존 부모프로세스는 소멸된 것으로 이해할 수 있습니다.
1-2. exec() 함수의 종류
exec() 함수는 접미사에 따라 인자 및 기능에 약간의 차이가 있습니다.
이 접미사의 의미는 통용하여, 함수의 의미를 이해하는 데 도움이 됩니다.

- l
list형태로 인자를 입력한다는 의미의 l입니다.
인자의 끝(마지막 인자)은 항상 NULL 및 0으로 표기해야 하며, 리스트 인자를 순차적으로 대입하듯이 입력해주는 방식입니다.
- p
PATH Environment의 P입니다.
사용자가 운영체제 상에서 지정하여 시스템 전역에 영향이 미치는 변수 혹은 경로를 환경변수라 하는데, 이 환경변수는 보통 최초 설치시 디폴트값과 동일한 값으로 유지됩니다.
따라서 환경변수의 경로가 기존 설치 경로가 일치할 경우, execlp execvp execvpe 등의 함수를 사용할 수 있습니다.
- e
ENVP의 e입니다.
사용자가 설정한 경로를 통해 실행파일을 탐색하고 실행하는 의미입니다. 이때 ENVP(ENVironment Path) 변수에, 사용자가 list 형태로 권한이 있는 사용자(첫번째 인자), 지정 경로(두번째 인자), NULL(DEFAULT)를 각각 직접 설정하여 해당 함수에 마지막 인자로 전달하여 사용합니다.
execle execvpe 등의 함수가 그 예 입니다.
- v
vector의 v입니다.
함수에 인자 전달시 포인터 배열이 전달되며, 이때 포인터 배열은 char *const argv[] 의 형태입니다.
이는 l을 사용하는 함수에서 차이가 있는데, l(list) 사용 함수는 말 그대로 인자를 전달할 때 리스트 그대로를 전달합니다. 즉 각각의 인자를 함수 인자에 빠짐없이 넣어 할당을 해줘야 정상작동이 됩니다.
반면 v(vector) 사용 함수는 미리 포인터 배열을 선언하여 이를 설정해주는 방식입니다. 즉 선언한 배열을 인자에 그대로 사용이 가능하며, 인자의 구조는 함수가 사용하는 구조와 동일하게 선언이 되어야 합니다.
예를 들어, execl함수의 인자가 execl(“/bin/ls”, “ls”, “-al”, NULL)와 같이 선언되었다고 할 때, execv함수는 char *argv[] = {“ls”, “-al”, NULL}로 포인터 배열 변수를 미리 설정한 후 execv(“/bin/ls”, argv)의 형태로 사용이 가능합니다.
※ vector 인자를 사용하는 exec() 함수의 종류는 아래와 같습니다.
execv() - execl()의 vector 형태의 인자 사용
execvp() - execlp()의 vector 형태의 인자 사용
execvpe() - execle()의 vector 형태의 인자 사용
1-3. exec() 함수 종류별 기능
exec() 함수들을 사용하기 위해 사용자 운영체제에서 별도로 설정한 환경변수나 설치경로 등을 파악한 후, 활용할 함수를 적절히 선택해야 합니다.
- execl, execl(const char *path, const char *argv[0], *argv[1], …, NULL)exec() 함수를 통해 실행파일의 바이너리 이미지(코드)를 현재 프로세스의 CODE, BSS, DATA 영역에 덮어쓰기를 진행합니다.
이후 새로 할당된 실행파일의 내용이 프로세스에 반영됩니다.
인자들이 list 처럼 나열되어 전달되며, 첫번째 인자인 path는 사용자가 직접 디렉토리 경로를 함수 인자 내에서 선정해주어야 합니다.
- execlp, execlp(const char *file, const char *argv[0], *argv[1], …, NULL)사용자가 운영체제 내 및 설치하면서 설정한 경로(환경변수, P)를 그대로 참조하여 실행하는 함수입니다.
따라서 설정한 환경변수에 맞게, 실행파일이 리눅스 운영체제 내 디렉토리에 위치하였는지 확인해야 합니다.
설정 환경이 동일하다면 위 구성처럼 실행파일의 이름만 기재해도 함수 사용이 가능해집니다.
- execle, execle(const char *path, const char *argv[0], *argv[1], …., char * const envp[])사용자는 환경변수를 함수내 지역변수로 설정한 후, 해당 지역변수를 함수인자로 전달하는 방식으로 실행파일을 실행하도록 하는 함수입니다.
char const envp[] = {“USER = ubuntu”, “PATH=/bin”, (char )NULL} 과 같이 지역변수(배열)에 인자 값을 설정해주고, 이를 함수 마지막 인자로 전달하여 해당 정보들을 참조할 수 있도록 해야 합니다.
- execv, execv(const char *path, char *const argv[]), execl()과 유사함수 인자를 list처럼 나열되어 전달하는 것이 아닌, 지역변수배열을 별도로 선언하여 해당 배열을 인자로 전달하는 방식으로 함수를 사용합니다.
char *argv[] = {“ls”, “-al”, NULL}과 같이 지역변수배열에 인자 값을 설정해주고, 이를 함수 argv[] 인자에 전달하여 해당 정보들을 참조할 수 있도록 합니다.
- execvp, execvp(const char *file, char *const argv[]), execlp()과 유사.위와 마찬가지로 지역변수배열을 별도로 선언하여 인자로 전달합니다.
- execvpe, execvpe(const char *file, char *const argv[]), execle()와 유사.위와 마찬가지로 지역변수배열을 별도로 선언하여 인자로 전달합니다.
※execvpe의 경우 char argv[] = {“ls”, “-al”, NULL, char const envp[]}의 형태로 선언해줘야 하고, 별도로 envp 배열에 대한 선언이 필요합니다.
2. IPC기법
2-1. IPC기법이란
Inter Process Communication, 프로세스간 소통을 위한 기법
리눅스는 수많은 프로세스가 실행 중인 환경이지만, 각각의 프로세스는 기본적으로 서로 접근을 할 수 없습니다.
이에 대한 대안으로 프로세스의 자원 및 공유 대상을 파일화하여 저장매체에 저장 후 이를 공유하고자 하였으나, 실시간 상황 공유가 힘들어 여러 기법들이 고안되었습니다.
IPC기법의 핵심원리는 커널공간에 있습니다.
프로세스가 생성되면 가상 메모리에 4GB 영역을 차지하는 프로세스 구조가 만들어지는데, 1GB 커널 영역도 필수적으로 같이 생성됩니다.
리눅스 환경에서 해당 가상 메모리 영역의 page table은 커널 영역에 만들어지며, 해당 page table에서 물리 메모리의 특정 주소를 가리켜 해당 data를 사용하거나 할당받을 수 있습니다.
이때 각각의 프로세스들이 해당 물리 메모리의 특정 주소의 동일한 지점을 가리킨다면, 해당 자원은 여러 프로세스들이 접근 및 공유가 가능해집니다.
이러한 과정을 바탕으로 해당 자원 주소에 접근한다면 프로세스들은 서로 실시간 소통이 가능해지며, 이것이 곧 IPC 기법의 원리입니다.
※IPC 기법을 사용하기 위해선 특정 함수들을 사용해야 하는데, 이는 대부분 시스템 콜을 사용해야 하므로 커널 영역에서 IPC기법이 구현됩니다.
프로세스가 생성되면서 항상 1GB 커널영역을 할당하는데, 할당하는 과정이 반드시 필요한 이유이기도 합니다.
2-2. IPC기법의 종류
- Pipe 기법
- 개념
프로세스간 통로(Pipe)를 만들어 일방향 통신을 할 수 있는 기법입니다.
- Pipe기법의 사용방법
부모 프로세스는 fd[1](파이프 입구 포인터 변수)에 데이터 쓰기(write)를 하면, 자식 프로세스는 fd[0](파이프 출구 포인터 변수)를 통해 받아 읽기(Read)하는 방식으로 소통합니다.
각 write 및 read 함수는 시스템 콜이며, 자식 프로세스의 read 까지 정상적으로 완료되었는 지 알기 위해 read 함수의 반환값(자식 프로세스가 읽은 데이터의 크기)을 확인합니다.
- Pipe기법의 제약사항
부모 프로세스와 자식 프로세스간 단방향 통신만이 가능한 기법입니다.
int fd[2];선언 후 pipe(fd) 등을 통해 pipe 통로 및 이에 대한 포인터 변수설정이 함께 필요합니다.
또한 fork() 함수를 통한 자식 프로세스 생성하고 write, read 함수를 사용하여 IPC를 구현할 수 있습니다.
- Shared Memory 기법
- 공유메모리 기법의 개념
커널 영역에 메모리 공간을 만들고, 어느 프로세스나 해당 공간 및 데이터를 마치 변수처럼 공유할 수 있는 기법입니다.
- 공유메모리 기법의 사용방법
Pipe 및 Message Queue처럼 한 공간이나 통로를 통해 프로세스 간 통신이 이루어지는 것이 아닌, 커널 영역에 형성된 공간을 프로세스의 변수에 mapping하여 언제 어디서나 접근할 수 있는 IPC 기법입니다.
최초 공유 메모리 형성시 shmid = shmget( (key_t)1234, 10, IPC_CREATE|0644); 명령을 사용합니다.
shmget을 통해 공유메모리를 형성하면 shmid 변수에 해당 식별자를 저장합니다.
이후 shmaddr = (char )shmat(shmid, (char )NULL, 0); 함수를 통해 해당 프로세스를 공유 메모리에 mapping하고 해당 메모리 주소값을 전달 받습니다.
메모리 해제시 shmdt( (char *) shmaddr ) 명령을 통해 진행합니다.
- 공유메모리 기법의 제약조건
Message Queue에 해당 Queue에 대한 식별자(key)가 있었다면, Shared Memory 역시 해당 메모리 공간에 대한 식별자(key)가 존재합니다.
shmget() 함수를 사용하여 공유메모리를 형성하고, 이에 대한 반환값인 shmid를 전달받아 메모리 식별자로 활용합니다.
다른 프로세스가 공유 메모리에 접근하고 싶다면 이 shmid 인자를 반드시 사용해야 합니다.
또한 프로세스마다 공유 메모리 변수를 mapping 해주어야 하므로, 프로세스 개수 만큼의 변수 선언이 필요합니다.
Signal 기법
- Signal기법의 개념
한 프로세스가 다른 프로세스에게 어떤 이벤트가 발생하였는지 알려주고, 미리 약속(정의)된 디폴트처리를 해주도록 하는 기법입니다.
- Signal기법의 사용방법
전통적인 IPC 기법 중 하나로, 흔히 알고 있는 ctrl + c(프로세스 종료)와 ctrl + z(프로세스가 background process화) 역시 Signal 기법 중 하나입니다.
이러한 Signal 종류 들은 kill -l을 통해 알 수 있습니다.

- Signal기법의 제약조건
signal을 동작하기 위한 특정 명령어들을 사용해야 하며, #include <signal.h> 헤더파일 선언이 필요합니다.
signal 사용을 위해선 위 signal No를 활용해야 하는데, kill(pid_t pid, int sig) 명령어에 해당 인자를 전달하여 사용할 수 있습니다.
signal(SIGINT, signal_handler) 명령을 통해 특정 signal에 대한 함수동작을 사용자가 재정의할 수 있습니다.
재정의할 경우엔 signal_handler에 대한 동작을 해당 signal 명령을 사용하기 전에 선언해줘야 합니다.
3. Copy on Write
프로세스의 생성속도를 높이기 위한 기술
3-1. Copy on Write의 개념
리눅스 프로세스는 복사의 연속입니다. 프로세스가 만들어지는 과정은 최초 init 프로세스를 복사하여 이루어집니다.
이때 프로세스가 만들어지면 4GB 크기의 가상 메모리가 할당됩니다. 이렇게 수많은 자식프로세스가 생성된다면 용량부담이 많아지고, 그만큼 프로세스 생성시간도 오래 걸릴 수 있습니다.
이에 대한 대안으로 Copy on Write 구조가 고안되었습니다.
Copy on Write의 주요 원리는 커널공간의 공유입니다.
프로세스 구조 내 가상메모리 4GB 영역 중, 1GB는 커널 영역으로 만들어집니다.
이 커널이미지는 웬만하면 동일하고, 동일한 커널 이미지를 사용할 경우 물리 메모리에 mapping된 커널 공간을 동일하게 접근할 수 있습니다.
즉 프로세스가 새로 생성되었을 때 동일한 물리 메모리 주소를 공유할 수 있으며, 일단 동일한 공간을 사용하겠다는 것이 Copy on Write의 주요 원리입니다.
3-2. Copy on Write의 핵심
Copy on Write의 핵심은 자식 프로세스가 생성되었을 때 동일한 물리 메모리 공간을 공유한다는 점, 부모 프로세스의 동일 물리 메모리 주소를 공유하여 해당 page table를 우선적으로 사용한다는 점입니다.
이때 자식 프로세스는 해당 page, 물리 메모리 공간을 읽기만 한다면(Read) 계속 사용할 수 있습니다.
쓰기(Write)를 하거나 자식 프로세스가 해당 데이터를 변경할 땐, 이 경우에만 해당 page를 복사하고 이후 동작을 진행합니다.
사실상 복사보다 정확히는 분리의 개념으로 이해로 할 수 있으며, 부모 프로세스는 자식 프로세스의 작업 내용에 바로 영향을 받지는 않습니다.
3-3. Copy on Write 과정
공유하는 메모리 주소에 해당되는 내용을 읽기, 쓰기에 따라 동작과정이 다릅니다.
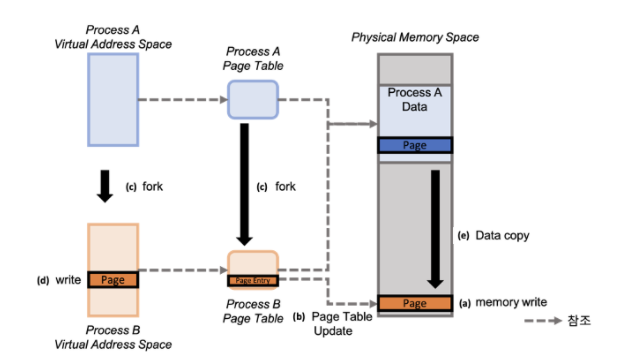
읽기 과정
- c
-
자식 프로세스가 생성되었습니다.
-
별도의 데이터 쓰기 및 변경없이 해당 메모리 주소를 그대로 참조하여 data를 읽습니다.
쓰기 과정
- c > d > e > a > b
-
자식 프로세스가 생성되었습니다.
-
자식 프로세스의 바이너리 이미지 파일에서 write 함수가 사용되어, write 요청이 호출되었습니다.
-
자식 프로세스는 부모 프로세스의 page를 복사하여, 새로운 물리 메모리 공간에 해당 데이터를 할당합니다.
-
복사한 데이터에 접근하여 write 요청을 수행하여 해당 data를 쓰기 및 변경합니다.
-
자식 프로세스만의 data 정보를 page table에 update 반영합니다. 새로운 page를 만들어 해당 포인터를 자식 프로세스가 write한 데이터 주소로 변경합니다.
4. mmap 함수(mapped file)
file 접근 방식 및 시스템 성능을 높여주는 기술
4-1. mmap 함수 개요
프로세스와 file의 연관성
프로세스와 file은 밀접한 관련이 있습니다.
기본적으로 리눅스 환경은 프로세스 내 파일의 접근을 통해 여러 동작이 이루어지는 체계라 할 수 있습니다.
우리가 무심코 사용하는 ls, pwd 등의 명령어들은 단순한 명령어가 아닌, 해당 실행파일에 접근하여 명령을 실행해주는 과정의 일부라고 할 수 있습니다.
mmap 함수의 배경
이처럼 프로세스가 file을 읽고 쓰는 과정은 리눅스 체계에서 수없이 일어납니다.
프로세스나 file 개수가 많아진다면 그만큼 접근, 읽기, 쓰기 등의 과정에 시간적, 공간적 소요 또한 같이 많아질 수 밖에 없고 시스템 성능적으로도 부정적인 영향을 미치게 됩니다.
특히 file이 저장되는 공간은 프로세스가 바로 접근할 수 있는 메모리 내 커널공간이 아닌, 별도의 저장매체입니다.
저장매체에 프로세스가 접근 시 필요한 시간은 프로세스가 내부 메모리 접근 시간보다 기본적으로1000배 가량 더 많습니다.
여기에 시스템콜을 사용하여 저장매체에 접근한다면 blocking, 인터럽트 등 시스템적으로도 많은 성능을 필요로 합니다.
이 시스템 성능이나 소요 시간을 줄이기 위해 고안된 기술이 mmap 함수입니다.
4-2. mmap 함수의 동작 과정
mapping file 및 물리 메모리 주소의 활용
프로세스가 file에 직접 접근하지 않습니다.
메모리 공간에 할당된 (file)주소를 참조하여 해당 file 내용을 간접적으로 참조하는 것입니다.
이를 프로세스에서 바로 참조할 수 있도록, 해당 물리 메모리 공간을 page system에 기재하기도 합니다.
위와 같이 mmap 함수를 사용하면, 바로 해당 file내용을 참조할 수 있는 물리 메모리 주소에 접근할 수 있게 됩니다.
이때 저장매체를 접근하는 시간 및 이에 수반되는 시스템콜 등의 번거로운 작업들을 모두 생략할 수 있습니다.
mmap 함수(file mapping)의 핵심 원리
이 file과 관련한 내용은 가상 메모리의 커널 공간에 형성되며, 이 커널 공간에는 page table 및 물리 메모리 주소 등 연관성이 깊은 정보들도 함께 존재합니다.
프로세스의 가상 메모리에 해당 file 이미지를 생성 및 실제 메모리 주소와 mapping하여, paging system에 그대로 적용할 수 있습니다.
즉 실제로 사용이 필요한 data를 page화, 물리 메모리 공간을 할당하는 과정에서 해당 file의 물리 메모리 주소 또한 paging system에 기재되어 관리할 수 있습니다.
실제 file data의 update 시점
mmap 함수를 통해 생성된 file에 대한 내용은 바로 update 되지는 않습니다.
해당 프로세스가 종료후 후처리하는 과정에서 해당 물리 메모리 내용을 file에 update 합니다.
즉 mmap 함수 완전 종료가 되었을 때 실제 file에 수정된 내용이 반영 됩니다.
4-3. mmap 함수의 특징
- 장점
read(), write()시 반복적으로 file에 직접 접근하는 과정을 상당 부분 간소화하여 성능을 획기적으로 개선할 수 있습니다.
seek() 함수를 통해 file 자체를 탐색하지 않고, mapping된 메모리 공간이나 page system 영역을 간단한 포인터 조작을 통해 탐색할 수 있습니다.
- 단점
mapping된 물리 메모리 주소는 page system으로 관리할 수 있으며, 4KB 크기의 page을 통해 접근 및 참조할 수 있습니다.
이 4KB 영역은 항상 고정이기 때문에, 이보다 작은 데이터를 mapping 할 경우 그 차이 만큼의 공간이 낭비됩니다.
- 참고사항
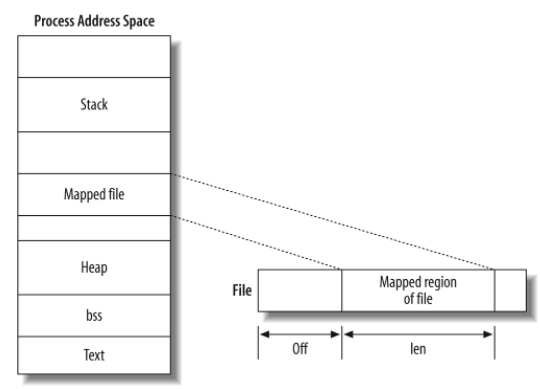
mmap 함수로 mapping 한 물리 메모리 주소는 munmap 함수로 해제할 수 있습니다.
mmap 함수에서 addr (=start) 지점을 설정하여 메모리 할당 시작점을 지정해줄 수 있으며, 일반적으로 NULL 및 0입니다.
이 할당 시작점에서 offset 지점을 시작으로 length(mapping 공간의 크기)만큼 메모리에 해당 data 주소 및 file descriptor를 할당해 줄 수 있습니다.
mmap을 통한 mapping 과정이 성공할 경우 해당 물리 메모리 주소값이 return 값으로 전달됩니다.
