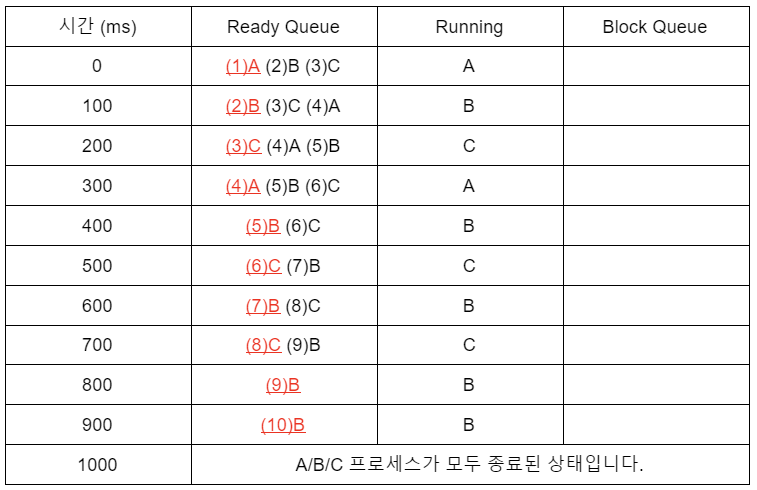
1. 스케쥴링
스케쥴링은 스케쥴러의 정책을 일컫는 용어로, 여러 프로세스가 실행중일때 CPU가 처리할 상태를 결정해주는 과정입니다.
아래 예시는 Round Robin(First In First Out) 기반의 스케쥴링 과정입니다.
[조건]
1. Round Robin 스케쥴링 정책
2. 100ms 마다 다음 프로세스로 교체
3. Ready Queue, Running Queue, Block Queue 존재
4. 각 Queue 는 FIFO 정책으로 동작함
5. 인터럽트로 선점 가능 (선점형 스케쥴링 기능 지원)
6. 타이머 인터럽트를 지원하며, 타이머 칩에서는 1ms 마다 인터럽트를 발생시킴
7. CPU에서만 실행하는 A, B, C 프로세스가 Ready Queue 에 A,B,C 순서대로 들어간 상태임
8. 각 프로세스가 총 실행해야 하는 시간은 다음과 같음
9. A 는 200ms, B 는 500ms, C 는 300ms
10. 파일 I/O는 발생하지 않음먼저 스케쥴링의 조건과 상황을 정리하여, 프로세스의 state가 어떻게 처리될 것인지 확인해봅니다.
-
스케쥴링은 CPU선점이 가능한 조건이며, 이에 따라 프로세스 running 중에 다른 프로세스로의 교체가 가능합니다. 이때 타이머 인터럽트는 1ms마다 인터럽트를 발생하며, 이에 따라 CPU는 1ms 간격으로 프로세스 교체여부를 판단합니다.
-
문제상 프로세스는 100ms 단위로 교체가 이루어집니다. 선점형 스케쥴러는 타이머 인터럽트가 주요 trigger로 작용하는데, 타이머 간격과 빈도가 충분히 작동하므로 본 스케쥴링은 이상없이 작동이 가능한 조건입니다.
-
파일 I/O가 발생하지 않으므로 CPU는 외부 저장매체 및 커널모드 작동 등의 추가적인 처리는 진행하지 않으며, 프로세스 처리에만 집중하는 조건입니다. 따라서 Block Queue에 들어가 실행보류되는 프로세스는 없고, Ready Queue와 Running Queue 처리를 반복합니다.
스케쥴러에 의해 프로세스 state가 변경되는 과정은 생략이 가능하다고 가정하겠습니다.
Ready state에서 Running state로 바꿔주는 주체는 스케쥴러이며, Ready state 프로세스를 대상으로 Running, 즉 실행 및 처리를 진행하게 됩니다.
스케쥴러는 타이머 인터럽트를 통해 state를 변경해주는데, 본 문제의 경우 타이머가 프로세스 길이에 비해 매우 짧은 시간에 인터럽트를 발생하므로 타이머 인터럽트에 의한 변경과정은 생략하겠습니다.
위와 같은 조건과 상태를 기반으로, 스케쥴링은 아래와 같은 과정으로 진행됩니다.
최초 실행요청은 A,B,C 순서대로 진행됩니다. 이때 모두 실행가능한 상황으로 Ready Queue에 적재됩니다.
0ms) FIFO 알고리즘에 따라 Ready Queue중 가장 먼저 실행을 요청한 A 프로세스를 CPU가 최초로 실행하며, A는 Running state가 됩니다.
100ms) Round Ronin 스케쥴러의 정책에 따라 A는 아직 Running 중임에도 불구하고, CPU가 이를 선점하여 강제로 block 상태로 처리합니다. 동시에 Ready Queue중 먼저 실행요청을 한 B가 Running state로 바뀌며, A는 Ready Queue에 들어가 가장 후순위 처리 프로세스로 적재됩니다.
200ms) 동일한 이유로 B는 Ready Queue에 다시 적재되어 최후순위가 되며, 현재 Ready Queue에 실행대기중인 C 프로세스가 Running state로 바뀌게 됩니다.
300ms) 마찬가지로 C는 강제로 Ready Queue에 최후순위로 적재되며, 스케쥴링 정책에 따라 A가 다시 Running state로 처리가 됩니다.
400ms) A는 처리가 완료되어 Ready Queue에 적재되지 않으며, 프로세스 구조상 어디에도 할당되지 않고 종료됩니다. 현재 처리순서는 B이므로 B가 Running state로 바뀝니다. 이때 Ready Queue에는 C만 남습니다.
500~700ms) 다시 B는 Ready Queue로 적재되어 Ready state, C는 Running state가 되며 이 과정을 반복합니다.
800ms) C는 프로세스가 종료되어 프로세스 구조상 삭제되고, B가 Ready state / Running state를 반복합니다. Round Robin 구조상 프로세스 처리대상이 B가 유일하더라도, 100ms내 프로세스가 처리되지않으면 B는 반드시 Ready Queue에 적재됩니다.
900ms~1000ms) B는 900ms 시점에서 프로세스가 종료됩니다. 1000ms 시점에서 남아있는 프로세스는 없는 상태입니다.
2. 페이징시스템
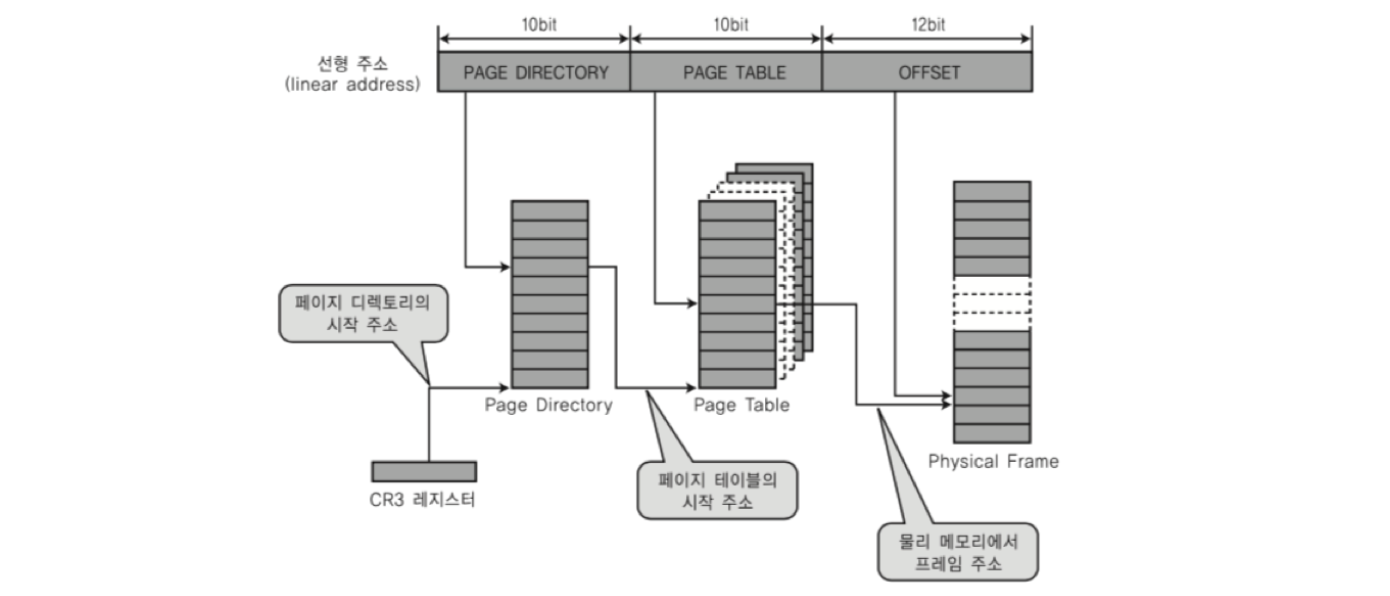
페이징시스템은 프로세스 구조에 적재된 여러 data 및 코드, stack 정보 등을 4KB 등의 일정 크기로 페이지화하여, 각 시점별로 필요할때만 페이지 정보를 저장하고 이를 물리 메모리에 할당하는 시스템입니다.
그 중에서도 다중단계 페이징시스템은 페이징시스템을 페이지 디렉토리/ 페이지 테이블 등으로 세분화하여 공간 효율을 높이기 위한 세부적인 구성을 의미합니다.
(a) Page Directory: 우리가 알고있는 디렉토리처럼, 페이지 정보들을 모아놓은 하나의 그룹과 같습니다. 페이지 디렉토리의 맨 앞 번호는 페이지 번호의 맨 앞 번호와 매핑이 되어 관리되며, 각 시점에서 필요없는 페이지는 페이지 디렉토리내 정보에 없으며 관리되지 않습니다
(b) Page Table: CR3 레지스터에 저장된 페이지의 세부 정보를 나타내는 항목입니다. 물리메모리의 상단계층에 저장되어 있습니다. 페이지 번호에 따라 프로세스 구조상 가상주소와, 이와 연결된 실제 물리메모리 주소를 매핑하여 해당 정보를 나타내고 있습니다. 여기서 MMU라는 별도 하드웨어 장치가 CR3 레지스터를 참조하면서 페이지테이블 정보를 접근하는데, 페이지 정보외 해당 페이지가 물리 메모리에 valid, invalid 상태인지도 같이 확인하게 됩니다.
※사전에 TLB 하드웨어 장치를 통해 해당 페이지 정보의 물리 메모리 주소가 저장되어있는지 확인하여, 해당 정보가 없다면 페이지 테이블 정보를 통해 메모리 주소를 가져오는 과정을 진행합니다.
3. 다중단계 페이징 시스템
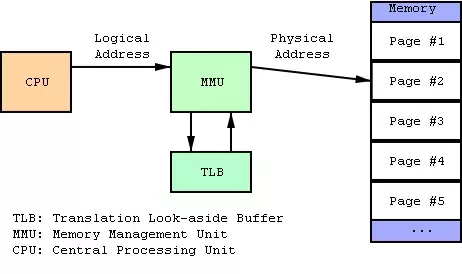
페이징시스템의 효율적인 관리를 위해 다중단계 페이징 시스템이 적용되었습니다.
페이징 시스템도 많은 수의 페이지 정보가 적재된다면 그만큼 CPU성능 및 처리속도 등 전체적인 컴퓨터 관리적인 측면에서 불리한 요소가 많게 됩니다.
이때 페이징 시스템을 효율적으로 관리하고 구성할 수 있도록 한 것이 다중단계 페이징 시스템입니다.
다중단계 페이징 시스템을 구현하기 위해 추가적인 하드웨어 장치, Chip이 필요합니다.
MMU : Memory Management Unit, 페이지테이블을 참조하여 가상주소와 물리주소를 매핑하고, CPU에게 해당 물리주소 및 데이터를 전달해주는 장치입니다.
TLB : Translation Lookaside Buffer, CPU에서 가상주소요청을 하였을때 해당 주소가 물리메모리에 일전 적재된 이력을 기록하는 장치로, 바로 물리 메모리 주소를 전달해주기 때문에 불필요한 과정 중복없이 바로 CPU가 데이터를 가져올 수 있도록 합니다.
CPU가 가상주소를 요청했을때 각 조건별 처리과정이 다르게 진행됩니다.
[CPU가 요청한 페이지가 메모리에 존재하며, 해당 정보가 TLB에 저장된 경우]
-
CPU가 가상메모리를 요청합니다.
-
MMU는 먼저 TLB를 통해 메모리에 해당 주소가 할당되었는지 확인하고, 현재 있는 상태이므로 바로 MMU에 해당 물리메모리 주소를 전달합니다.
-
MMU는 CPU에 해당 주소와 데이터를 전달하게 되며, 이 과정을 통해 CPU는 데이터를 받아올 수 있습니다.
[CPU가 요청한 페이지가 메모리에 존재하며, 해당 정보가 TLB에 없을 경우]
-
CPU가 가상메모리를 요청합니다.
-
MMU가 TLB를 통해 물리 메모리 정보가 있는지 확인하고, 없는 상태이기 때문에 CR3레지스터를 참조하여 페이지테이블에 접근하게 됩니다.
-
해당 페이지가 페이지테이블에서 valid인지, invalid인지 확인합니다. 지금 조건은 valid하므로 페이지테이블에 해당 페이지 정보가 있을 것이고, MMU는 해당 물리 메모리 주소를 알게 됩니다.
-
MMU가 해당 물리 메모리 주소로 접근하여 data를 받아오게 됩니다.
-
MMU는 자신이 받아온 data와 물리메모리 주소를 CPU에게 전달합니다.
[페이지테이블상 정보가 invalid일 경우]
MMU가 페이지테이블에서 해당 페이지 정보가 invalid로 나타났다는 것은, 일전 해당 페이지 정보나 데이터를 사용한 이력이 없어 물리 메모리 주소가 할당되지 않았음을 의미합니다.
즉 해당 페이지가 물리 메모리에 없는 상태입니다.
이때 memory에서 운영체제에게 인터럽트의 일종인 page default를 발생시키게 됩니다. 운영체제는 이 인터럽트를 받은 후, 프로세스 저장공간에서 해당 page 정보를 메모리에 할당해줍니다. 할당된 page 정보를 바탕으로 메모리내 CR3 레지스터에 저장중인 페이지테이블 정보가 업데이트 됩니다.
페이지테이블이 업데이트가 되면 CPU는 다시 가상주소를 MMU에 요청하게 되며, 위와 동일한 과정을 통해 CPU가 물리 메모리 주소와 data를 확보하게 됩니다.
3. 부팅
부팅은 사용자가 컴퓨터를 최초로 동작할 때 일어나는 과정입니다.
메모리에 어떤 데이터도 없는 상태에서, 컴퓨터는 어떻게 운영체제를 실행하게 되는지 확인해보겠습니다.
아래와 같은 조건이 있다고 가정하겠습니다.
• 컴퓨터는 BIOS를 지원하고, 부팅을 지원하는 bootstrap loader 가 별도로 설치되어 있음
• 운영체제 커널은 실행후, 최초 프로세스(init)를 운영체제 코드상에서 바로 실행시키며, 이후에는 fork() 기능을 지원함.
위 조건을 정리하면 리눅스 운영체제에서 일어나는 부팅이며, 세부적인 상황은 아래와 같이 파악할 수 있습니다.
두번째 조건은 최초 프로세스인 init을 생성하고, 이를 운영체제에서 실행하여 이후 프로세스 실행시엔 fork()를 통해 자식 프로세스를 만드는 것입니다. 이는 리눅스 운영체제의 동작방식이므로, 본 운영체제는 리눅스 운영체제입니다.
쉘은 간단히 말하면 운영체제와 사용자간의 인터페이스입니다. AWS에서 제공하는 우분투체제의 리눅스패키지를 바탕으로 한 서버를 실행한다고 가정하였을때, 사용자는 해당 AWS서버를 운영하기 위한 리눅스 CLI 환경을 맞이하게 됩니다.
위 리눅스 운영체제에서 프로세스 실행 및 쉘 실행까지의 과정은 결국 부팅과정으로 확인할 수 있습니다. 이에 대한 부팅과정은 아래와 같습니다.
-
최초 부팅시에는 메모리에 할당된 주소가 아무것도 없는 상태입니다.
-
부팅시 CPU는 ROM의 특정주소를 읽는데, 이때 BIOS 프로그램이 있는 곳으로 접근합니다.
-
BIOS 프로그램 일부가 실행하며, BIOS 프로그램 코드가 메모리 load 됩니다.
-
BIOS 프로그램 코드가 메모리에 load 된다는 것은, 부트코드가 load된다는 의미입니다. 이때 부트코드는 부트로더라는 특정 sector(메모리 앞공간인 MBR)에 저장, 운영체제는 이 부트로더에 접근하여 내부에 기재된 data 및 코드를 실행합니다.
-
부트로더 내부에 기재된 data 및 코드중 파티션테이블 정보를 통해 메인파티션을 찾고, 메인파티션의 부트섹터로 접근합니다.
-
부트섹터로 접근한 운영체제는 다시 해당 부트코드, 즉 메인파티션의 부트코드를 메모리에 할당합니다. 이 부트코드가 로드된 후, 부트섹터내 커널이미지(바이너리 실행파일)의 주소를 받고 이 커널이미지가 메모리에 할당됩니다.
※이 커널이미지는 실행파일의 일종으로, 응용프로그램의 일환이기도 합니다. 리눅스 운영체제는 C언어로 된 코드를 컴파일링한 후, 이를 실행파일(바이너리 이미지)로 바꾸어 실행합니다. 이는 프로세스와는 다른 개념으로, 실행파일을 메모리에 할당하여 실행한다는 것은 응용프로그램을 실행하는 것과 같습니다. 프로세스는 응용프로그램 실행을 위하여 내부적으로 동작 및 연계가 필요한 코드들이 CPU가 프로세스 구조를 구성하여 처리하는 것을 일컫습니다.
- 메모리에 할당된 커널이미지, 즉 실행파일이 실행되면서 본래 컴퓨터 하드웨어가 초기화되고 저장매체의 특정공간에 접근하면서 window 등의 운영체제가 실행됩니다. 리눅스 운영체제의 경우 init 프로세스를 생성하고 쉘을 실행하게 됩니다.
※리눅스 운영체제는 최초 실행시 init 프로세스를 실행하며, 이 init 프로세스는 부모프로세스가 됩니다. 이후 모든 프로세스들은 fork() 시스템콜을 사용하여 init 프로세스의 자식프로세스의 관계로 생성됩니다.
- 부팅과정이 종료되었습니다(리눅스의 경우 CLI환경, 즉 쉘이 실행되었습니다).
4. 프레스와 스레드
스레드(Thread)는 프로세스와 유사하게 동작하지만 구조적으로 경량화된 구조로, 프로세스로부터 파생된 구조, 즉 서브셋으로 이해할 수 있습니다.
프로세스는 구조상 Stack, code, BSS, data와 더불어 data files, register 등의 영역이 있습니다. 이때 data file 공간은 Stack과 HEAP의 중간영역에 있는데, 이 중간영역에 Thread가 생성됩니다.
다시 말해 Thread는 Process 공간내 생성되는 하나의 경량화된 구조로, Process의 데이터나 코드 등의 데이터를 공유하고 활용할 수 있습니다.
다만 Thread는 각각 별도의 PC와 SP를 기반으로 실행되며, 동시 실행이 가능합니다.
프로세스와 스레드의 차이점은 아래와 같습니다.
-
프로세스는 각자 보유중인 데이터에 다른 프로세스 접근을 불허하며, 접근이 필요할 경우엔 IPC기법을 사용해야 합니다. 반면 스레드는 프로세스내 데이터를 공유하기 때문에, 프로세스 내에 있는 모든 스레드는 IPC기법을 사용하지 않고도 데이터를 공유하고 접근할 수 있습니다.
-
프로세스는 동시 실행이 안되며, 시분할시스템 처리를 기반으로 동시 실행되는 것처럼 보이게 하는 것입니다. 반면 스레드는 동시실행이 가능하며, 하나의 프로세스내 여러 스레드를 생성할 수 있습니다.
-
프로세스는 구조적으로 4GB의 영역을 차지하여, 다수의 프로세스가 존재해야 한다면 그만큼 많은 영역이 필요하게 됩니다. 반면 스레드는 한 프로세스의 자원을 공유하는 구조로, 프로세스 구조내에서 생성됩니다. 즉 프로세스보다는 구조적으로 자원을 효율적으로 공유하는 구조로 이해할 수 있고, 영역차지도 프로세스에 비해 적습니다.
-
프로세스는 각자 자신만의 주소영역을 가지며 독립적으로 실행되는 반면(프로세스간 영향이 없습니다), 스레드는 주소영역을 공유하게 되며, 한 스레드만 문제가 생겨도 전체 프로세스가 영향을 받습니다.
5. remind
Not sugar syntax but sugar logic!
