Basic Definitions
what is "data"?
Fact들을 저장해야하고 None data 면서 기록이 되고 반드시 함축적 의미가 있어야 Data 라고 정의할수있다.
무언가가 들었는데 남아있지 않으면 data 라고 할수 없다.
what is "database"?
데이터들의 모음이다.
DB는 두개가 관련이 있어야한다.
그안에 소속 돼 있는 아이템끼리 뭔가 관련이 있어졌다하면 database 라 정의할수있따.
또한 data 들이 잘 조직화 돼 있어야한다.
Data Base Management System(DBMS)?
데이터 베이스를 관리하기 위한 소프트웨어 패키지 이다.
Database system?
DB 관리 시스템이다
Recent Developments
NoSQL DB

NoSQL 은 광범위한 데이터를 자기 만의 서비스를 하기 위해 만든 DBMS 이다.
Features
성능이 좋다.(일관성 or 유효성을 포기하고 성능을 높임)
확장성이 좋다.
또한 한 노드가 죽더라도 다른 노드에서 지원해서 서비스가 중단되지 않게 한다.

또한 Document 를 제공한다.
Self-describing
Hadoop
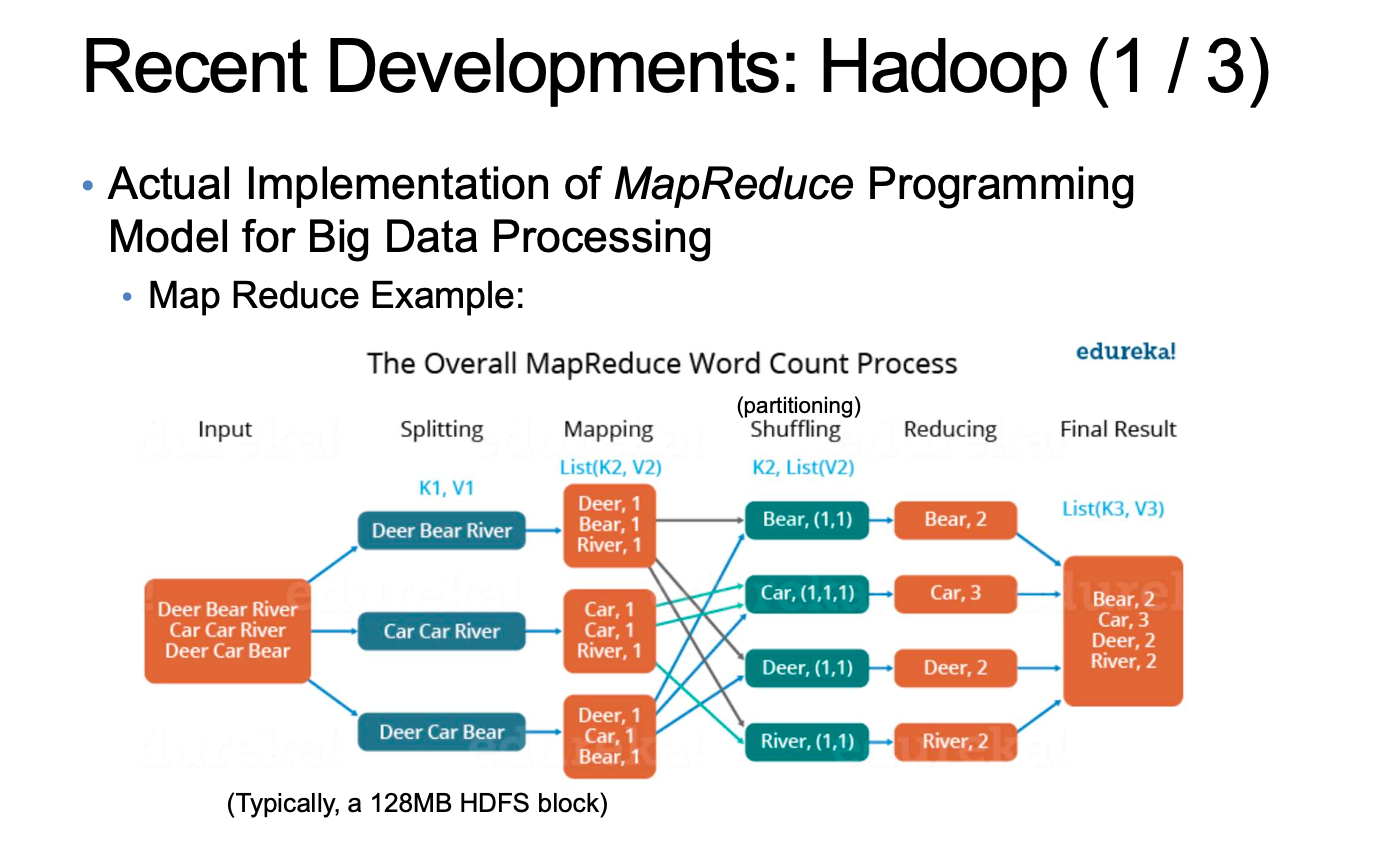
Hadoop 은 빅데이터를 위해 사용되며 MapReduce Programming 은 그림이다.
Database System Enviroment
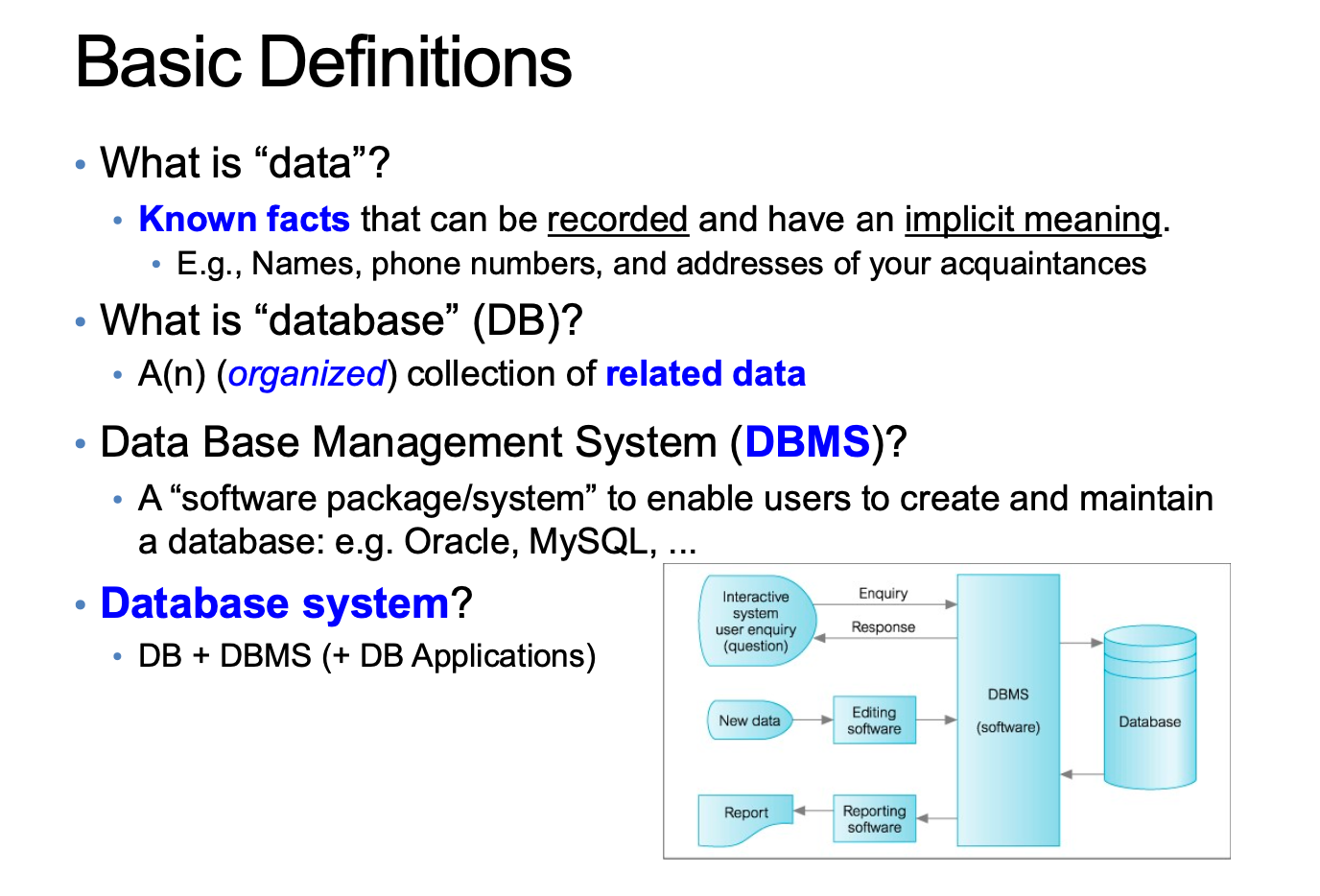
A "Simplified" Database System Enviroment
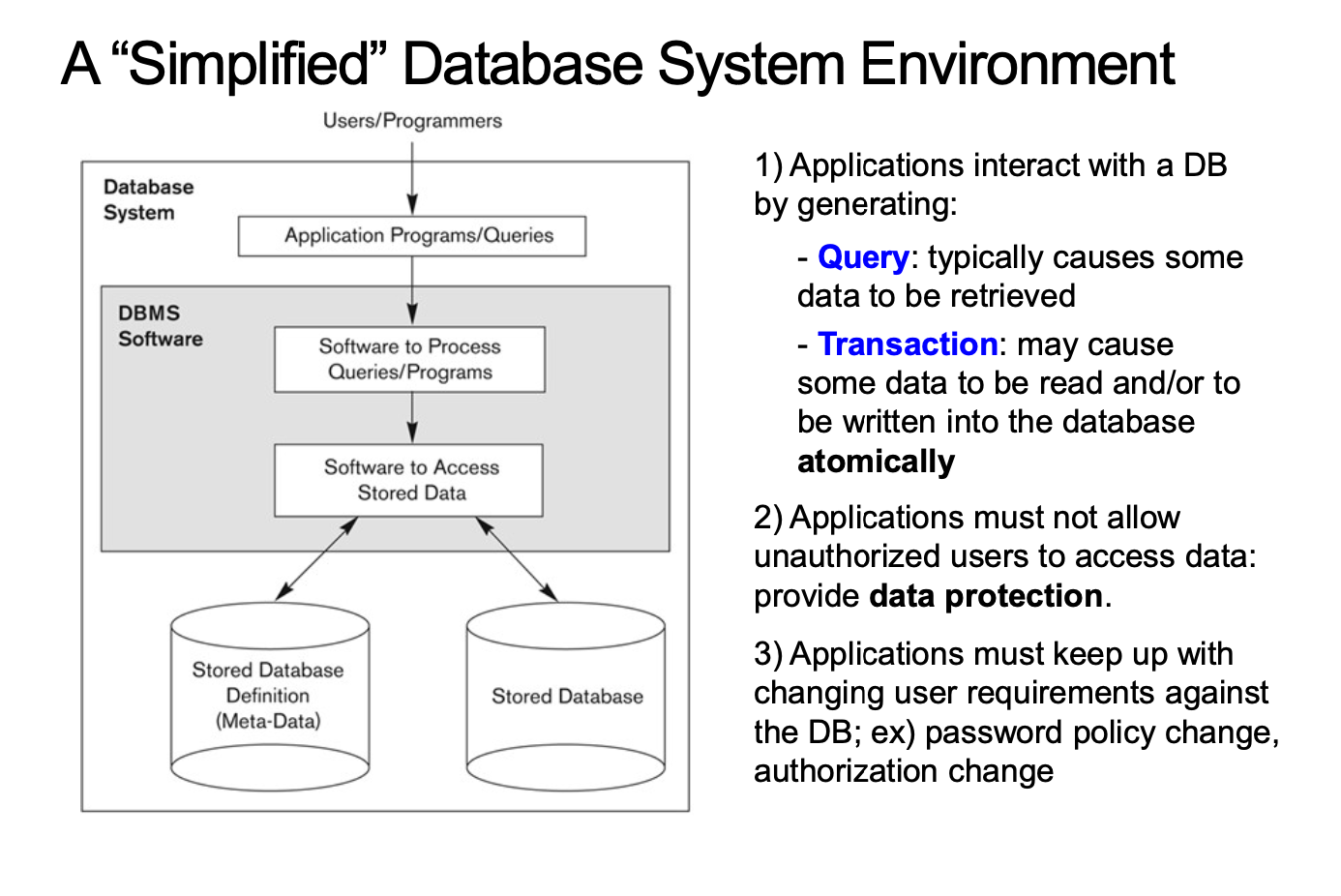
Applications 와 DB 는 두 요소를 생성함으로 상호작용한다
Query 는 검색하고 꺼내보는것
Transaction 은 Atomically 하게 발생되는 Single Task 이다.
Atomically 는 다 일어나거나, 아에 일어나지 않거나를 뜻한다.
또한 Data Protection 으로 인증되지 않는 사용자가 데이터에 접근하는 것을 허용하지 않으며
사용자의 요구사항에 대응해야한다.
Typical DBMS Functionality

1.DB를 정의할수 있어야한다.
Structure 과 Constraints 관해서 DB 를 정의하는 기능을 제공한다.
2.생성할수 있는 기능 제공한다. - > Primary storage 에
3.조작이 가능하도록 지원(저장된 DB)
4.동시에 접근하게 해야한다.
Example of a Database(with a Conceptual Data model)

Entity
-> 서로 관련성이 있어야한다.
또한 자기 자신을 참조하는 관계가 있을수 있다. 이걸 Self-relationship 이라고 한다.
Database Design Phases

Database 를 Design 한다는것은
기존의 DB를 위해서 새로운 응용을 만든다는것,아에 새로운 DB를 만든다는것 을 의미한다.
Stage 1 : Data 에 필요한 Requirement 필요
Stage 2 : 개념적으로 어떤 놈이 개체인지, 어떤 놈이 Relation 인지.
Stage 3,4 : (Logical - > Physical) DB 가 System 적으로 구서오디어야한다.
Main Characteristics of this database approach
Self-describing nature of a DB system

설명을 스스로 할수 있는 기능을 뜻한다. Catalog 로 가능하다
Catalog 는 Data에 대한 식별정보를 저장 하고 있는 공간이다.
직접 만져보지 않아도 미리 알수있고, 정의한 DB의 구조,유형,제한에 대한 Complete 한 definiton 을 가지고 있다.
Insulation between programs and data

Program 과 Data를 분리한다. data independence 떄문에
data 의 조직과 구성이 바뀌어도 Program 이 구성에 영향받지 않는다면 바꿀 필요가 없다.
-> 오직 바뀌는 부분을 참조하고 있는 프로그램 부분만 바꾸면 된다.
// What if you try to insert a Birth_Date attribute in the STUDENT record?
추가 한다 해도 Program 을 바꿀 필요가 없다.
Data abstraction

data model 제공해서 모든 data 가 표현되도록 보여지도록 해주는 기능.
program 은 data의 추상회 된것만 엑세스하고 사용자는 어떻게,어디에 저장되는지 알 필요가 없다.
Support of multiple views of the data

많은 사용자들이 공유할수 있어야한다.
관심 있는 부분만 제공한다.
Sharing of data and multiuser transaction processing

concurrent users의 집합이 DB로부터 데이터를 검색하고 DB를 갱신하는 것을 가능하게 한다.
atomicity,consistency,isolation,durability 를 가져야하고 복구도 해준다.
OLTP 는 수천개 Transaction 을 smooth 하게 처리한다.
Advantages of using the DB approach

Controlling redundacny(중복을 제어함)
Logical 하게 하나만 존재한다면 물리족으로 하나만 존재하게끔 한다.
여러개가 있으면 일관성이 꺠지고 이것은 신뢰성 깨짐으로 이어진다.
여러 카피가 존재하지 않도록 아에 원천적으로 차단한다.
-> data normalize
Restricting unauthrized access(권한이 없는 접근을 제한함)
들어왔다해도 View 의 권한이 없으면 안보여준다.

Providing persistent storage for program objects(객체의 영속성 저장)
Program 개겣 정보를 영속적으로 제공
Providing storage structures for efficient query processing
효율적인 access 가 가능하다.
Advantages of using the db approach

그 외에도 많은 장점이 있따.
When not to use a DBMS

투자 비용이 너무 크면 안쓴다.
나만 쓰는데 5천만원 들면 누가쓰나?
database 가 너무 쉽고 잘 정의되있으면 안쓰고,multiple user 접근이 없을때는 필요없다.

또한 특수한 목적의 Data를 다루기에는 적합하지 않다.
엄격한 요구사항이 있는 응용,real time 에는 안쓴다. check 할게 너무 많아
특수 목적에 team 이 맞지 않다.
내가 다뤄야하는 응용의 연산이 일반 structure 을 다루지 않을떄도 안쓴다.
