Amazon Athena
S3에 저장된 데이터 분석에 사용하는 Serverless Query service 이다.
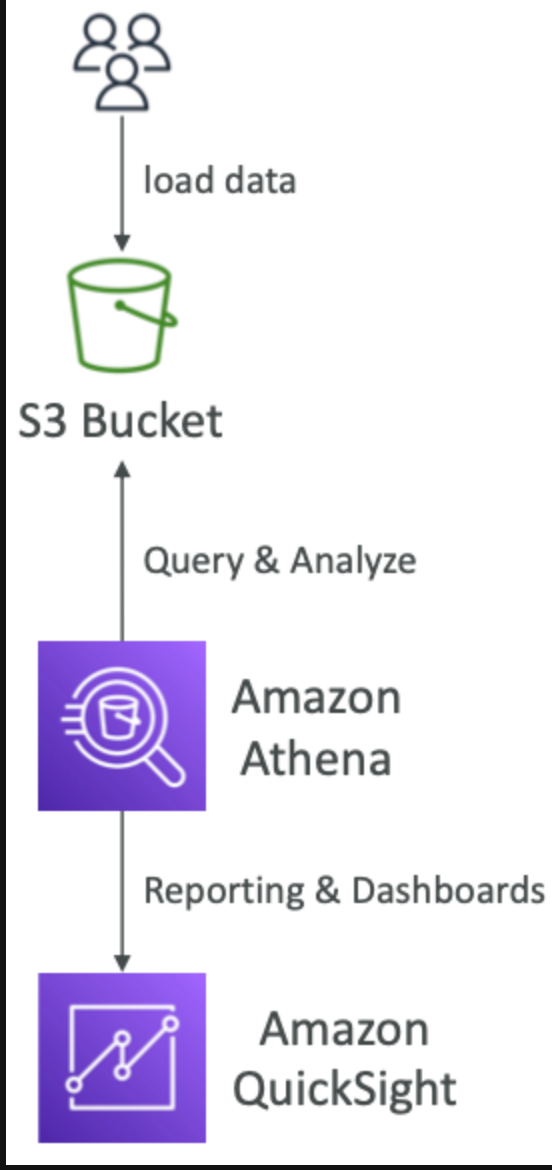
CSV,JSON,ORC,Avro,and Parquet,,, 등 다양한 형식을 지원한다고 한다.
Amazon Quicksight 와 함께 사용한다.
Amazon athena 로 이동하지 않고 바로 분석하다.
Performance Improvement
비용 절감을 위해서 열 기반 데이터를 사용한다고한다.
그리고 데이터를 압축해서 더 적은 검색을 한다.

특정 열을 항상 쿼라한다면 데이터 세트를 분할한다고 함.
Federated Query
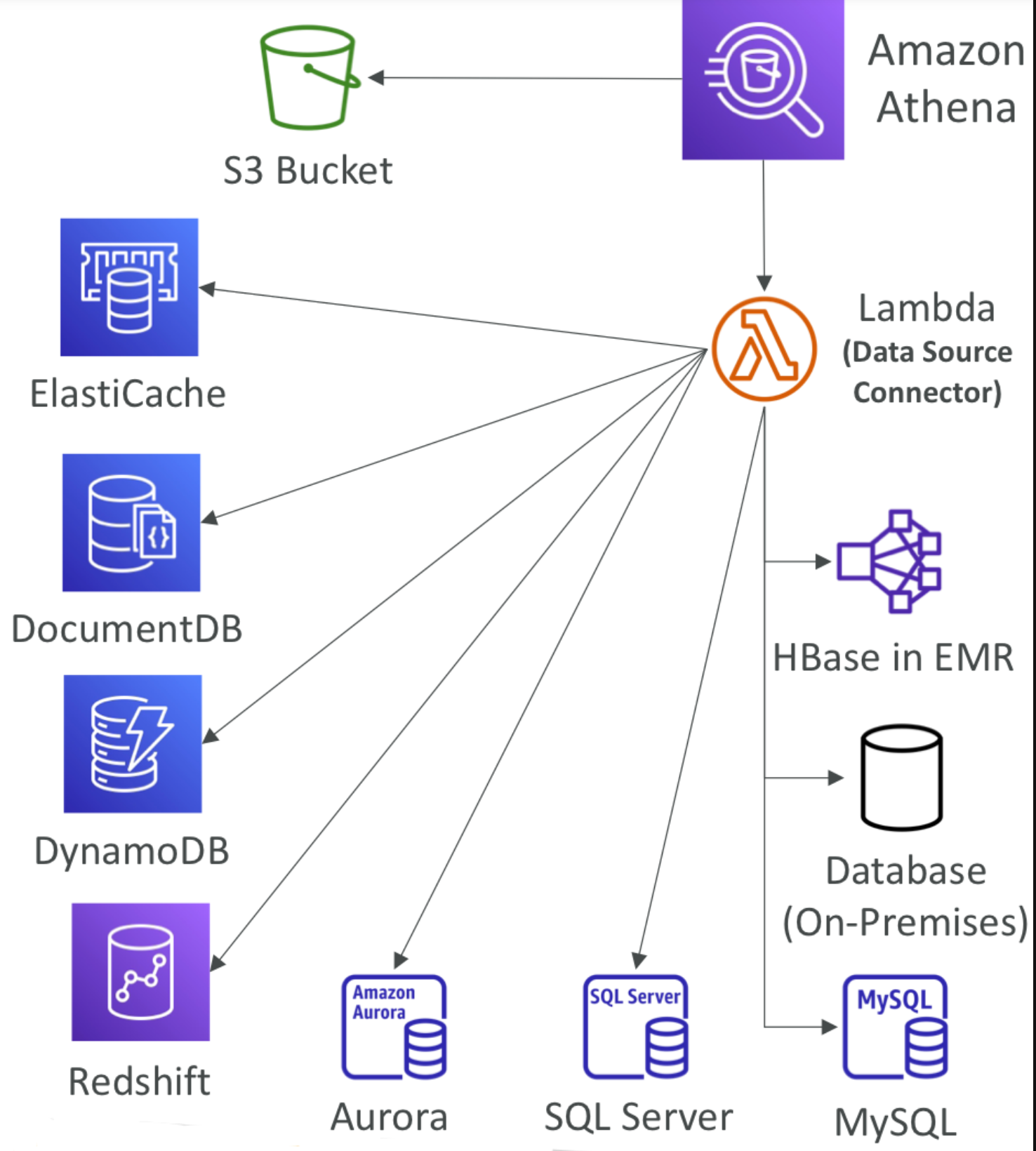
S3 말고도 어디든 가능하게 한다고 한다.
데이터 원본 커넥터(Lambda)를 사용해서 다른 서비스에서 연합 쿼리를 실행하게 해준다고 한다.
그리고 쿼리 결과를 다시 S3에 저장한다고 한다.
Redshift
DB 이면서 분석 엔진이라고 한다.
분석과 데이터 웨어하우징에 사용한다.
Athena 와 비교했을때 집중적인 데이터 웨어하우징,복잡한 쿼리,조인,병합이 가능하다고 한다.
Redshift Cluster
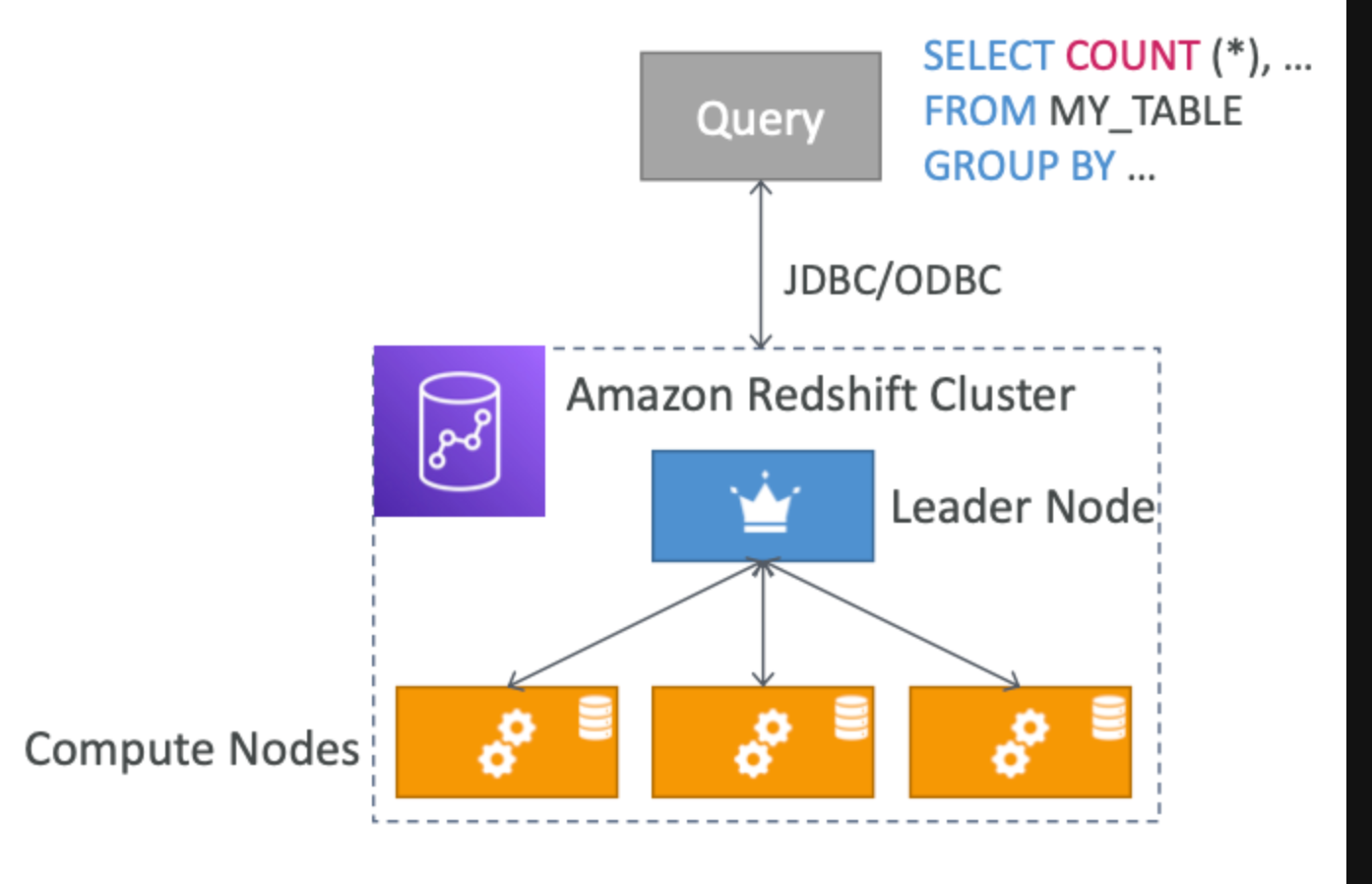
Leader Node 는 쿼리 계획 및 집계를 위한 노드이고
Compute Node 는 쿼리 실행 및 결과를 리더 노드로 전송하는 노드라고한다.
노드사이즈를 사전에 프로비저닝해야한다.
Snapshots & DR
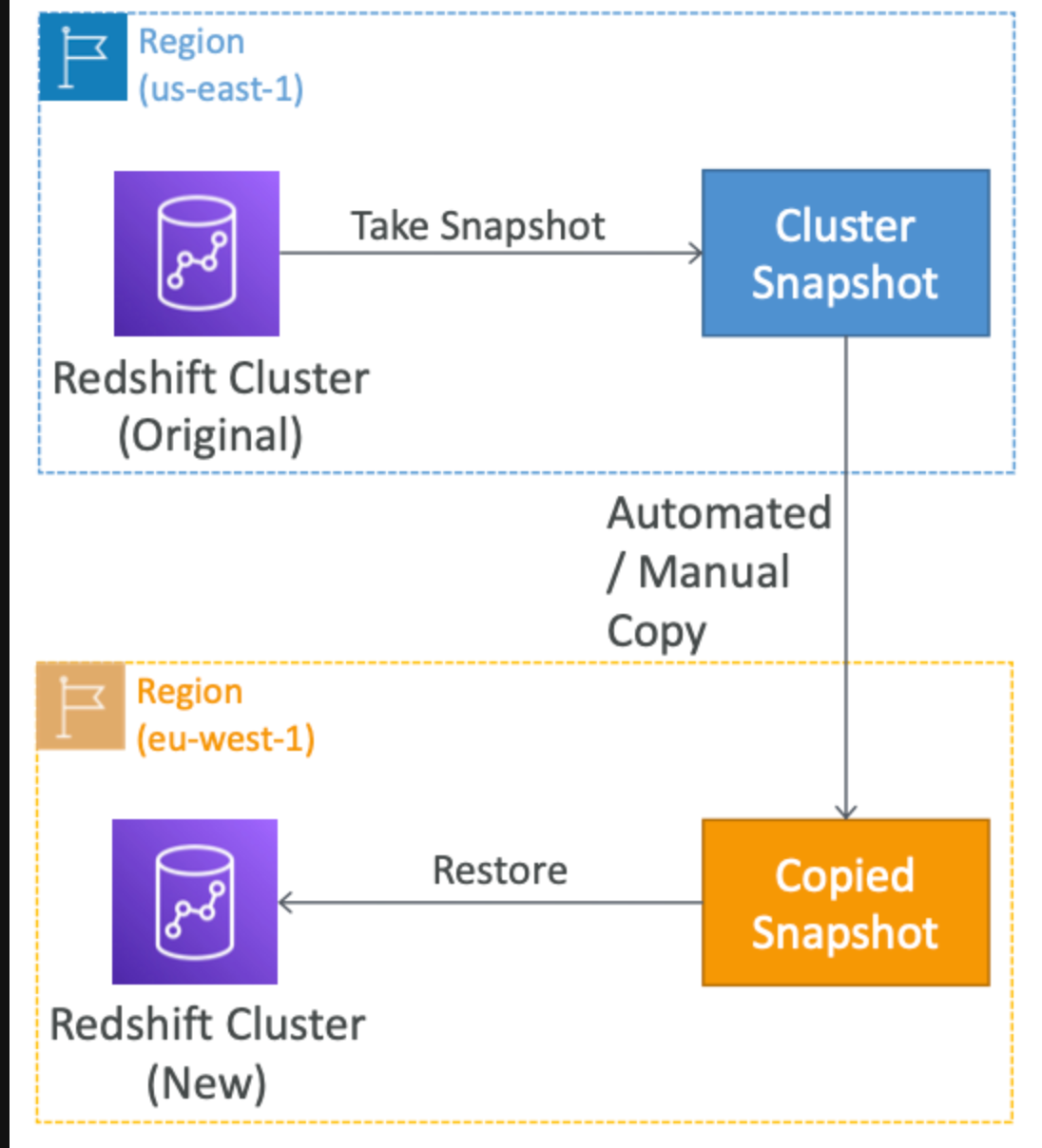
single Az 이면 snapshot
Loading data into Redshift:Large inserts are MUCH better

Redshift Spectrum
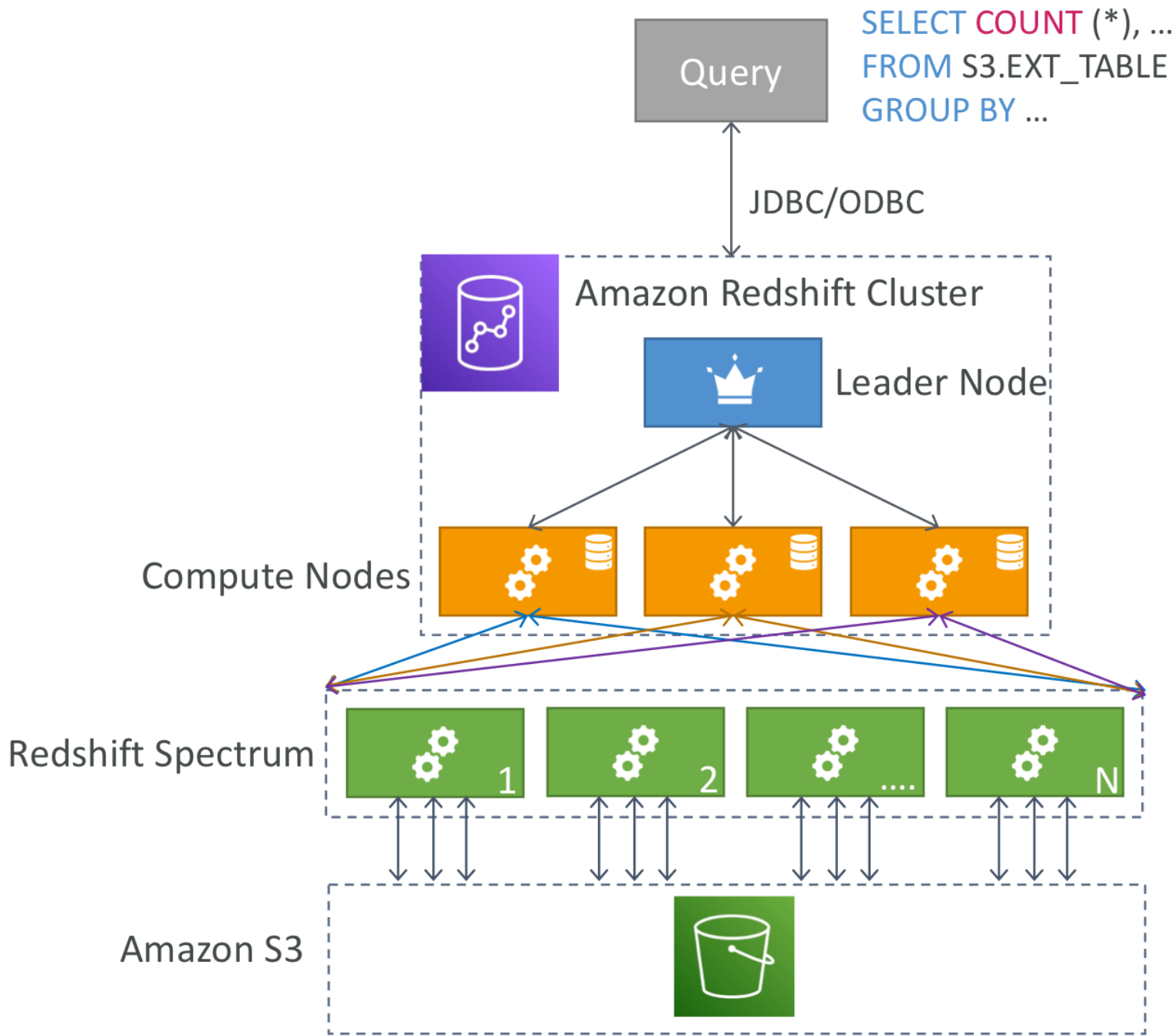
RedShift를 이용해서 분석하고 싶지만 Redshift로 로드하고 싶지 않을떄, 더 많은 처리 능력을 사용하고 싶을때 사용한다.
Amazon OpenSearch Service
Amazon OpenSearch Service는 Amazon ElasticSearch의 후속 서비스이다. (라이선스 문제로 이름이 변경됨)
DynamoDB에서는 기본 키나 데이터베이스의 인덱스로만 데이터를 쿼리할 수 있지만 OpenSearch에서는 부분적으로 일치하는 필드를 포함해 모든 필드를 검색할 수 있다.
일반적으로 OpenSearch는 다른 데이터베이스를 보완하기 위해 사용된다.
OpenSearch를 생성하고 사용하기 위해서는 인스턴스의 클러스터를 생성해야 한다. (서버리스 서비스가 아님)
자체 쿼리 언어가 있어 SQL을 지원하지 않는다.
Kinesis Data Firehose, AWS IoT, and CloudWatch Logs, 사용자 지정 애플리케이션의 데이터를 주입할 수 있다.
Cognito, IAM과 통합해 제공하는 보안을 통해 저장 데이터 암호화와 전송 중 암호화가 가능하다.
OpenSearch에는 OpenSearch 대시보드 (시각화 도구)가 함께 제공된다.
OpenSearch patterns DynamoDB
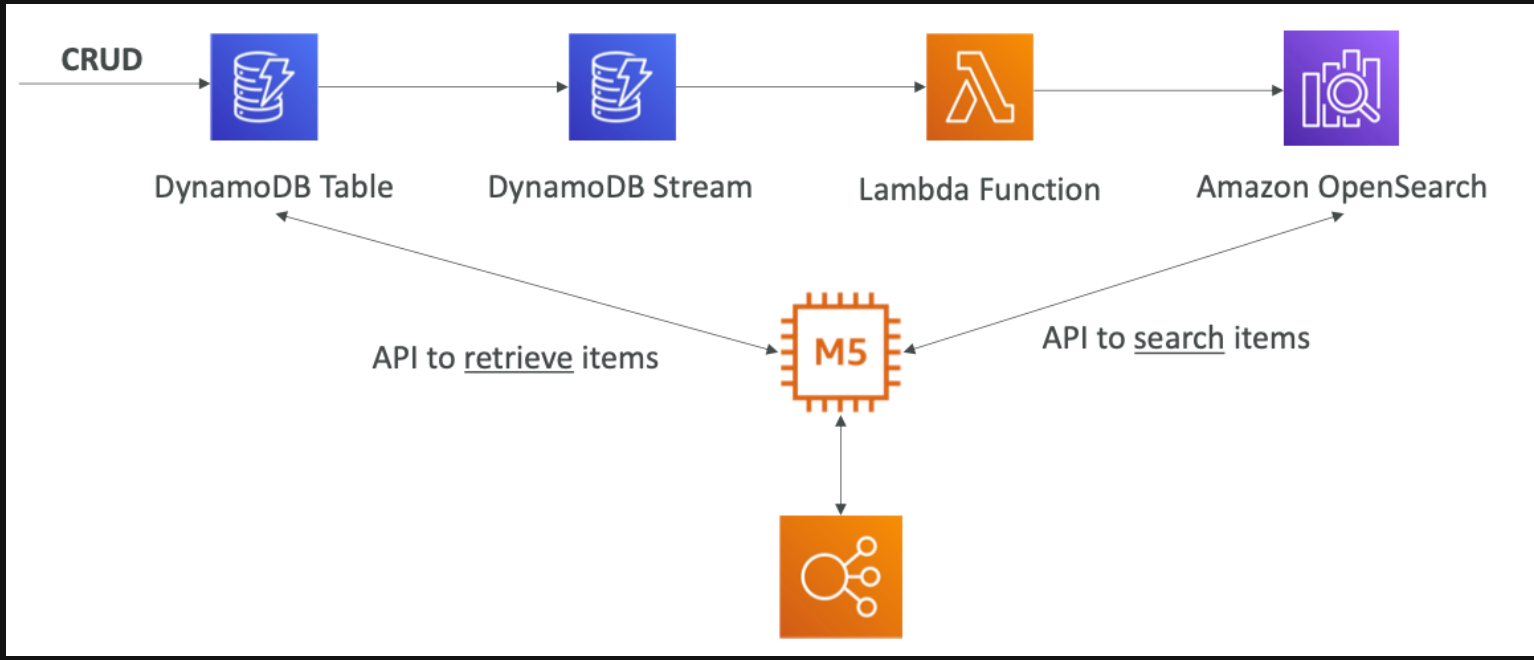
OpenSearch 로 특정한 항목을 검색할 능력을 갖게 된다. 그리고 항목 ID를 찾을수 있게 되고 항목을 DB에서 받게된다.
OpenSearch patterns CloudWatch Logs
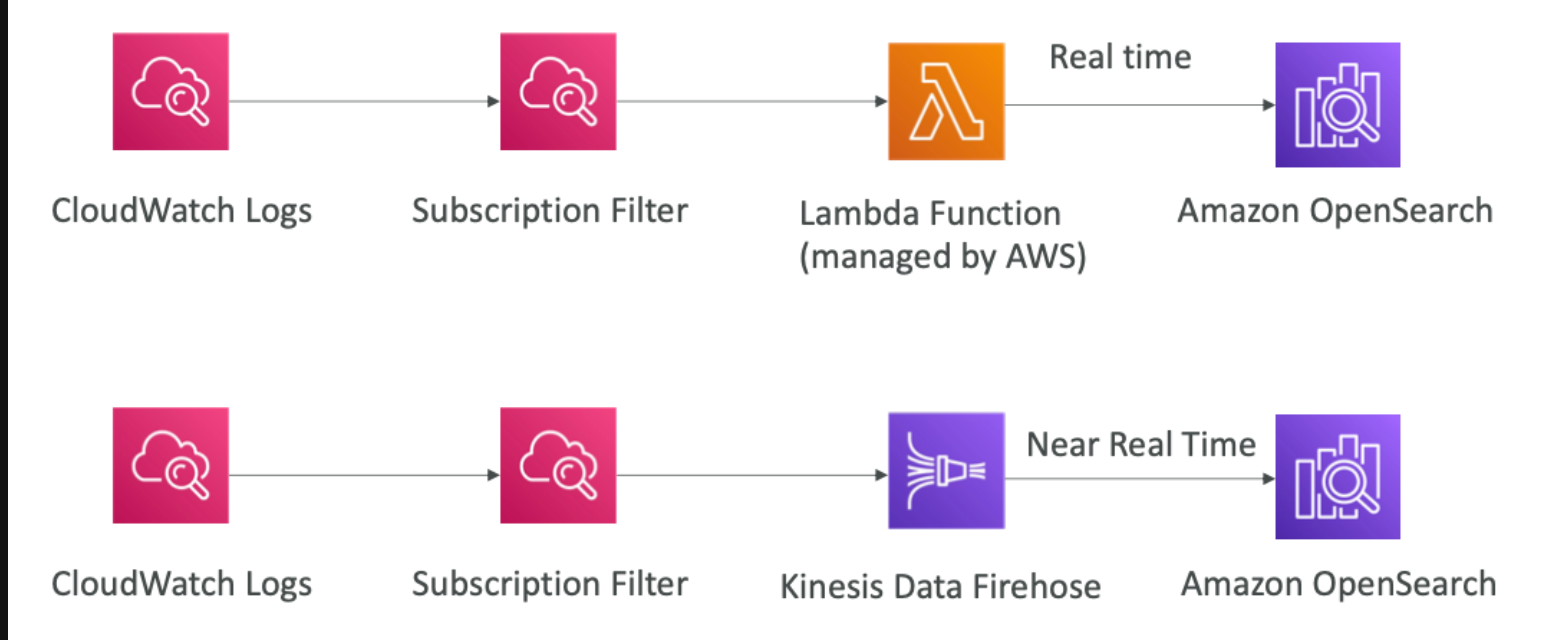
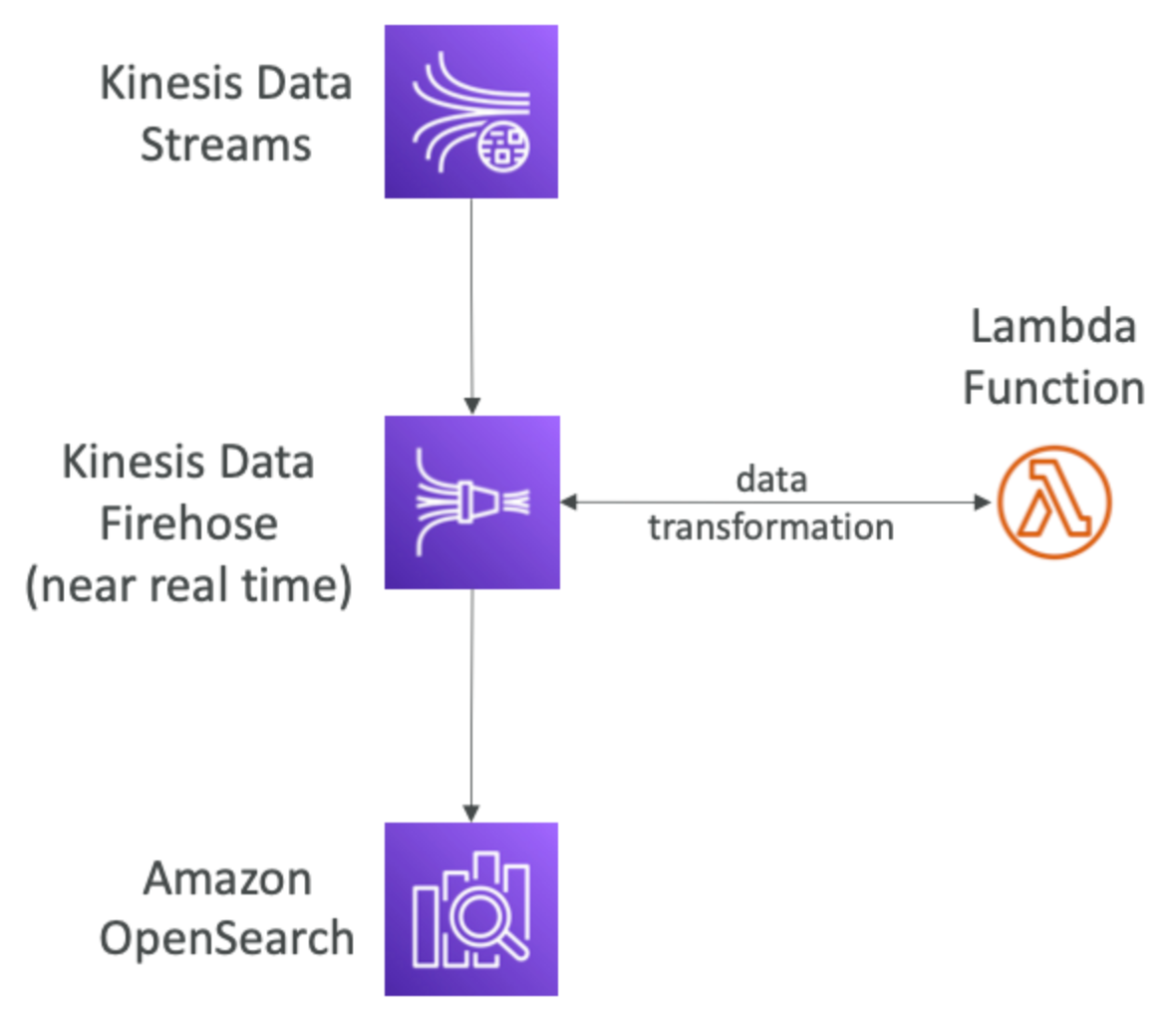
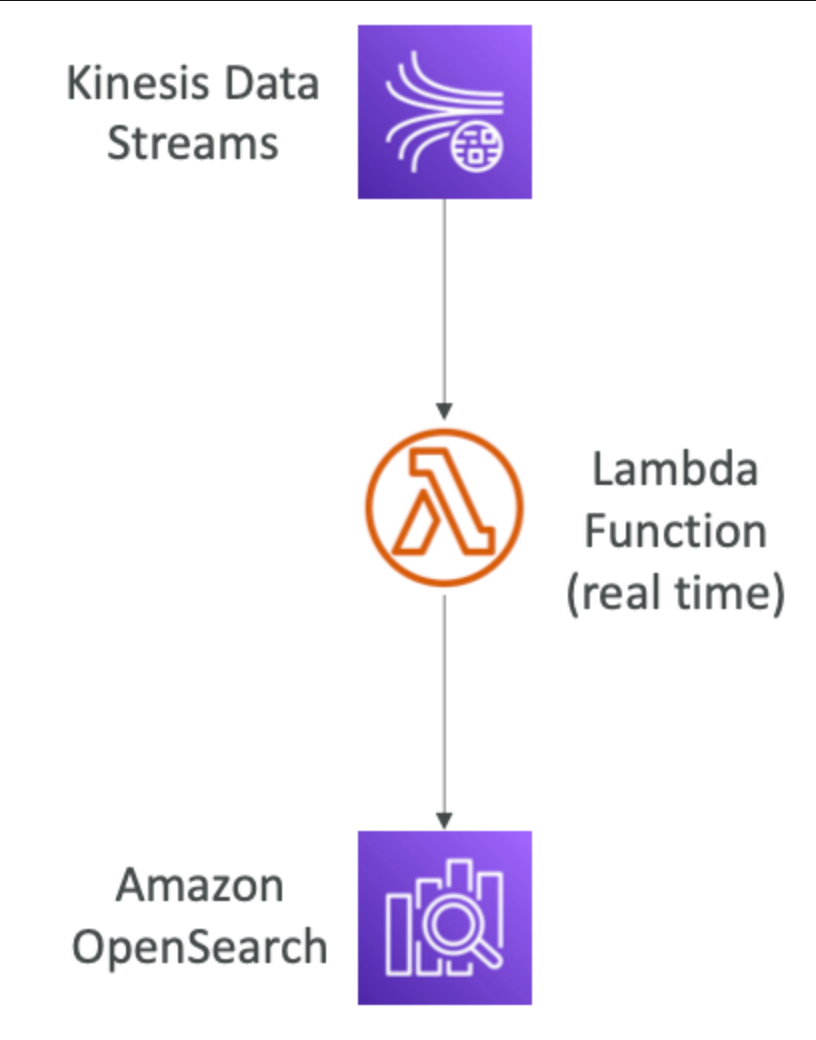
OpenSearch patterns Kinesis Data Streams & Kinesis Data Firehose
Amazon EMR
빅데이터 작업을 위한 하둡 클러스터 생성에 사용한다고 한다.
EMR은 상기 서비스에 관한 프로비저닝과 구성을 대신 처리해준다.
사용 사례: 데이터 처리, 머신러닝, 웹 인덱싱, 빅 데이터 등
Node Types & Purchasing
Ec2 Instance 의 Cluster 로 구성되어있다.
마스터 노드: 클러스터를 관리하고 다른 모든 노드의 상태를 조정하며 클러스터의 상태를 모니터링 - 지속적으로 실행되는 노드
코어 노드: 태스크를 실행하고 데이터를 저장하는 역할 - 지속적으로 실행되는 노드
태스크 노드 (optional): 작업 실행에만 사용되는 노드. 일반적으로 저렴한 Spot 인스턴스로 구성됨
Amazon QuickSight
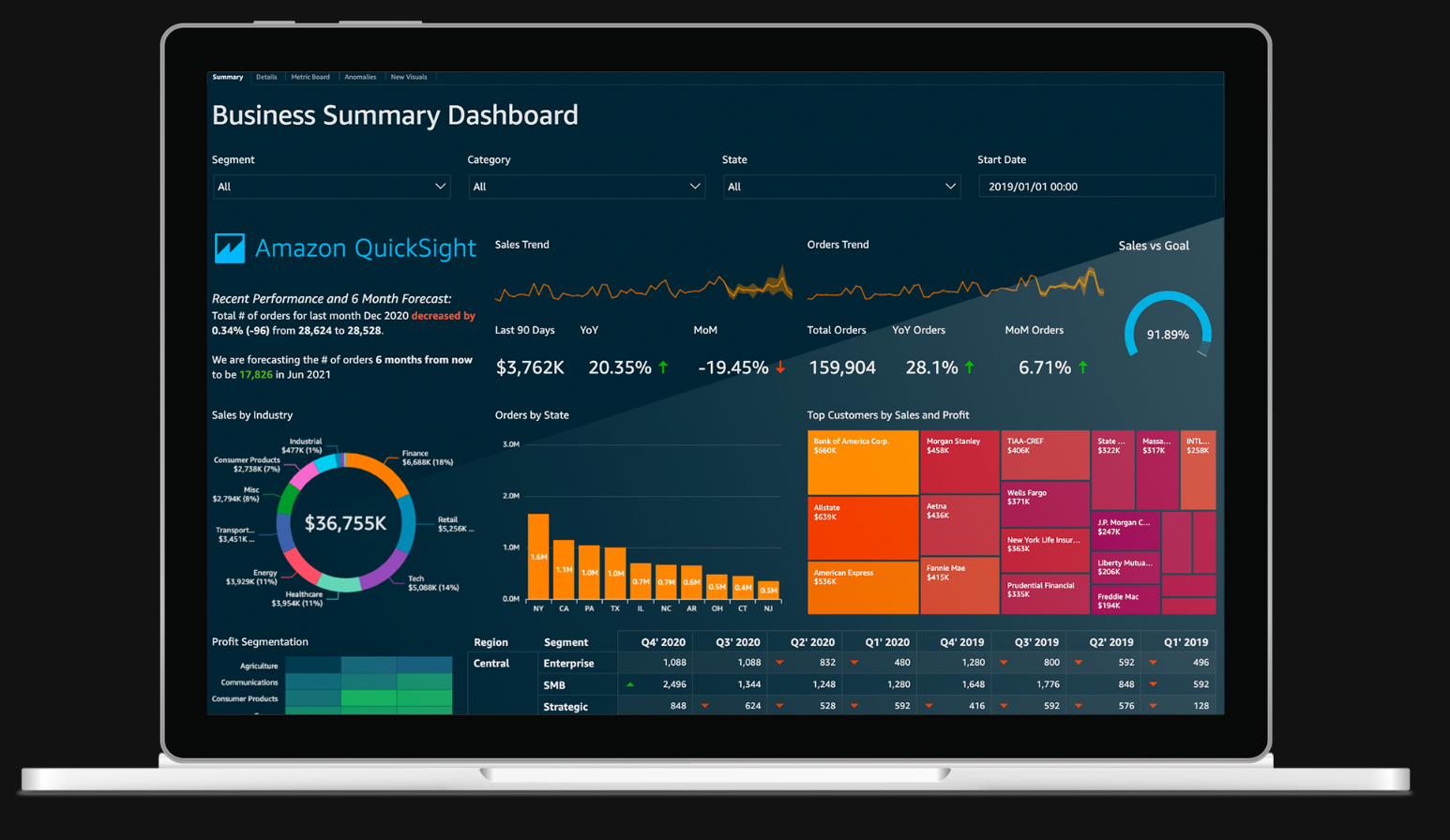
서버리스 머신 러닝 기반 비지니스 인텔리전스 서비스이다.
대화형 대시보드를 생성할수 있다고 한다.
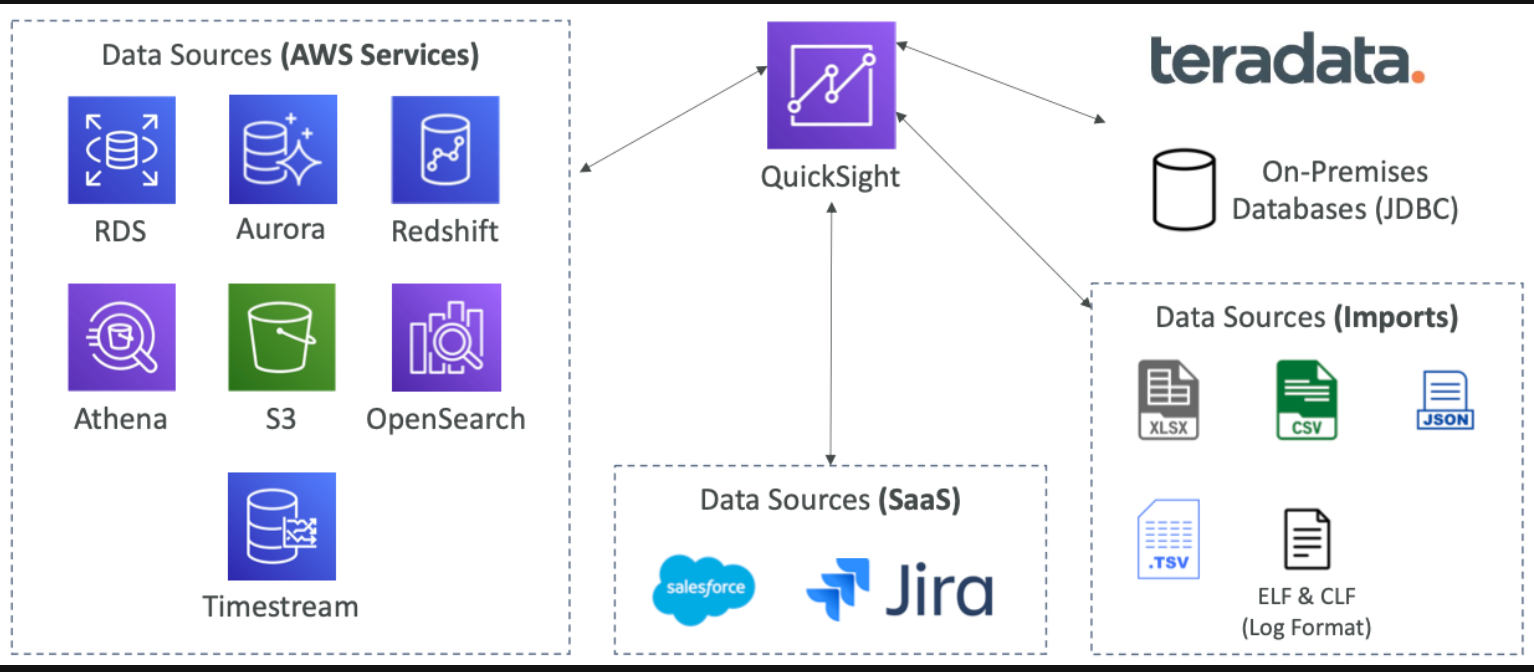
QuickSight Integrations
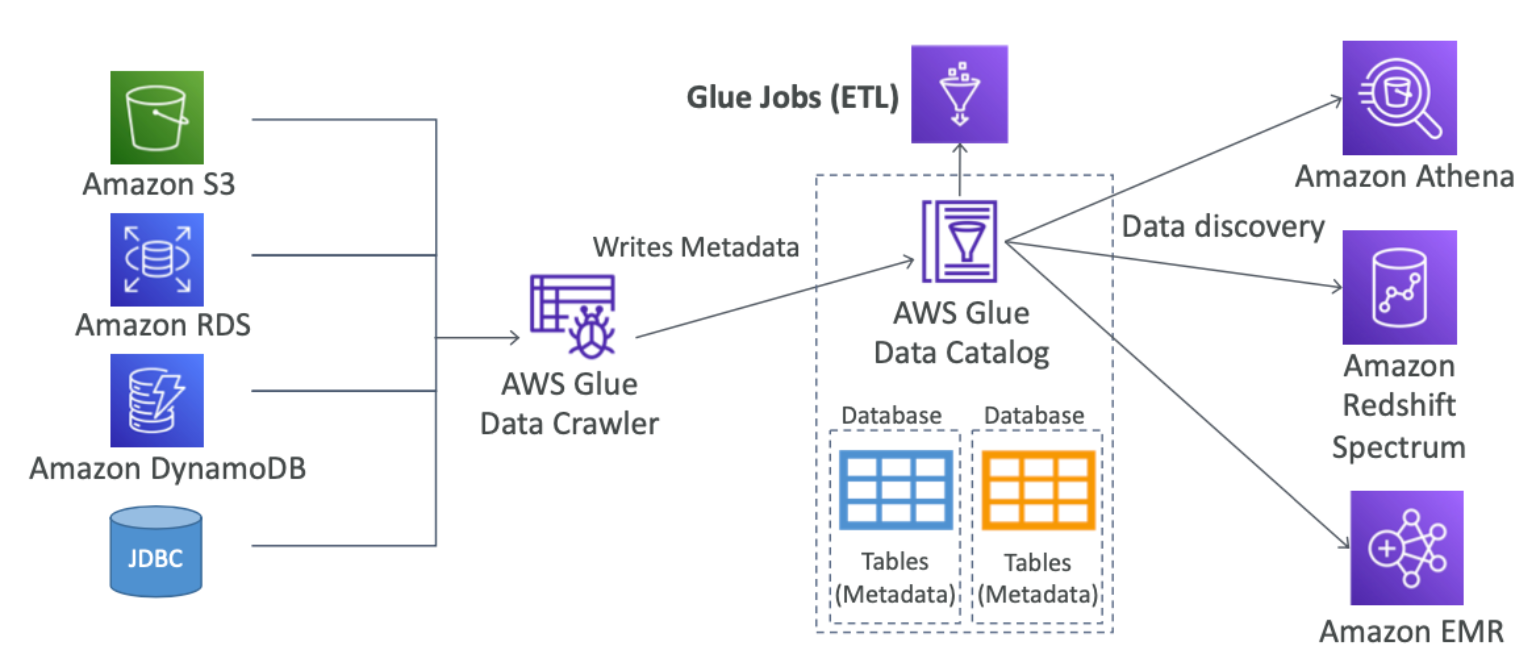
AWS Glue

추출과 변환 로드 서비스 이다.
분석을 위해 데이터를 준비하고 변환하는데 매우 유용하다고 한다.
추출하고/ 필터하거나 열을추가한다/최종 출력 데이터를 RedShift 데이터 웨어하우스에 로드한다.
Convert data into Parquet format
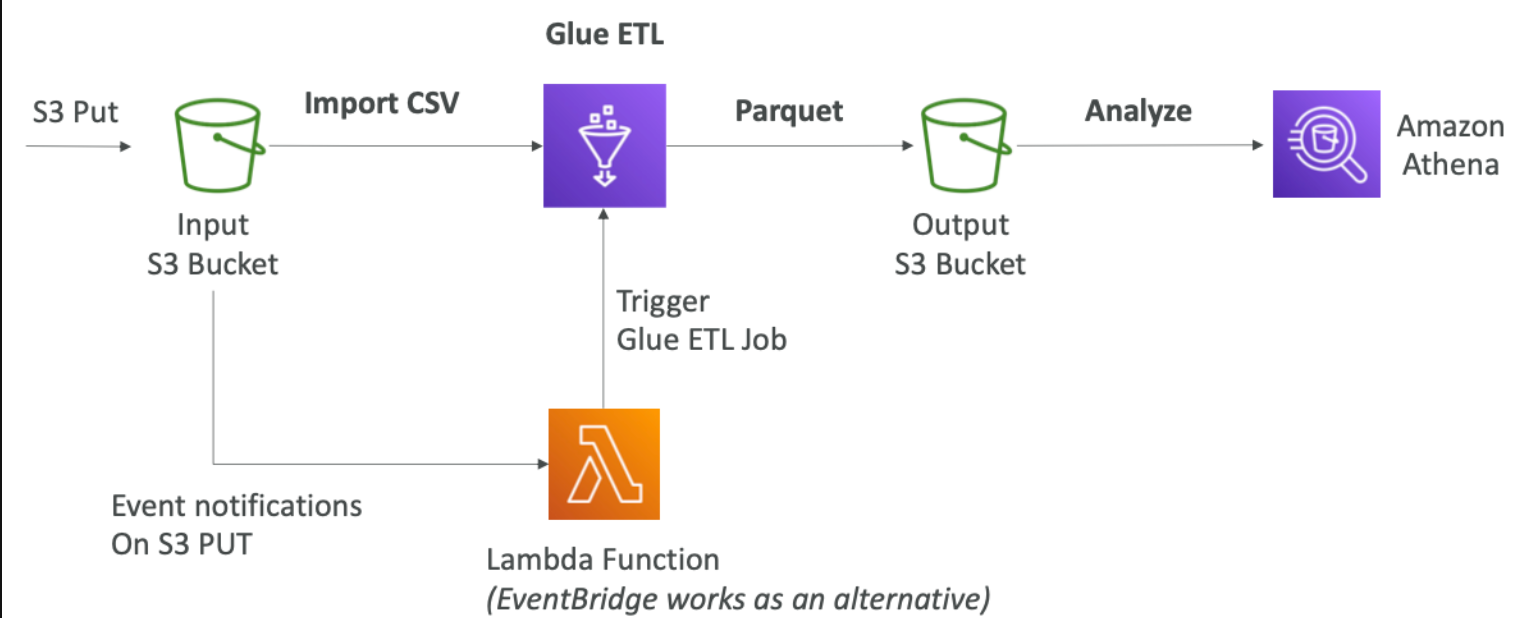
Glue Data Catalog: catalog of datasets
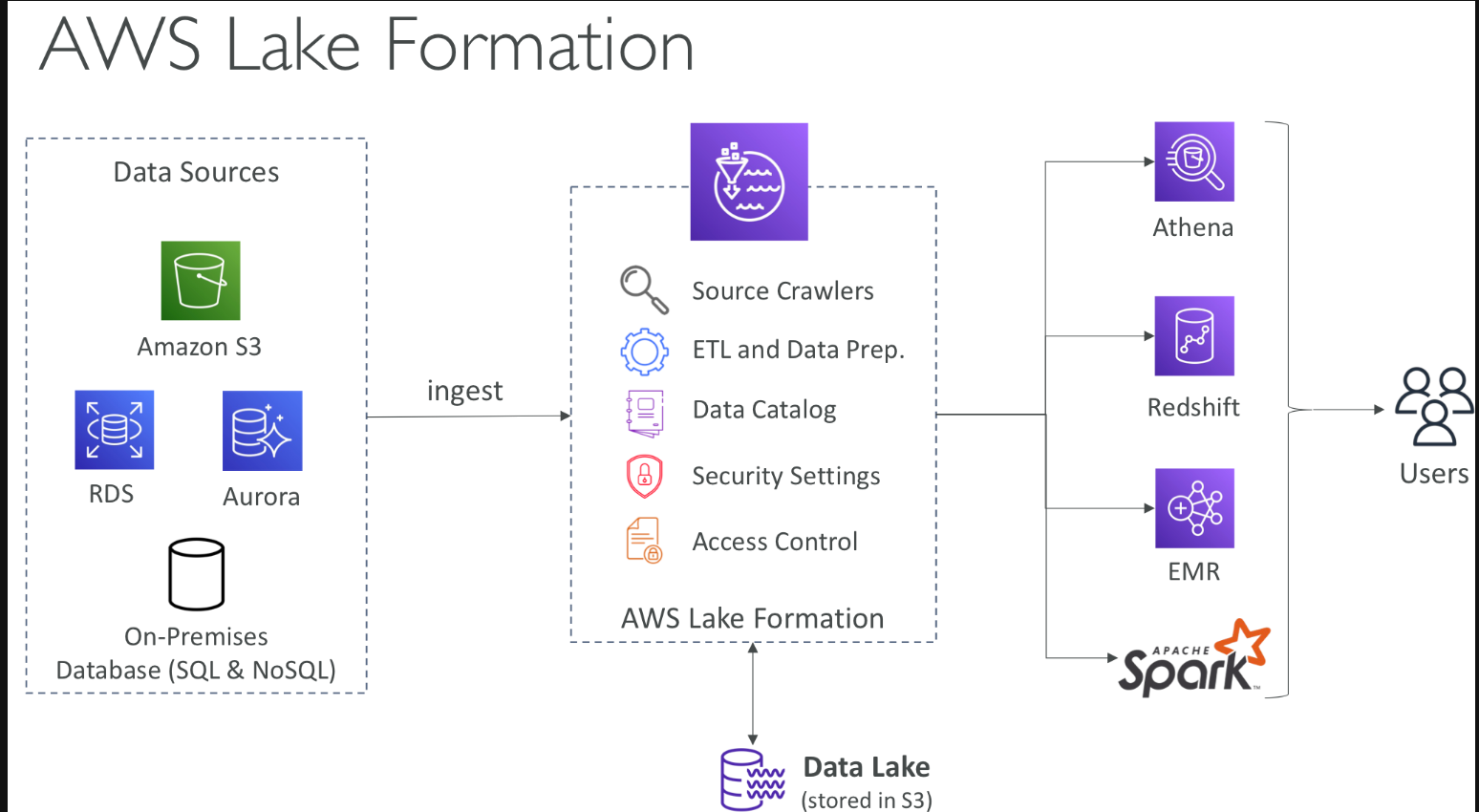
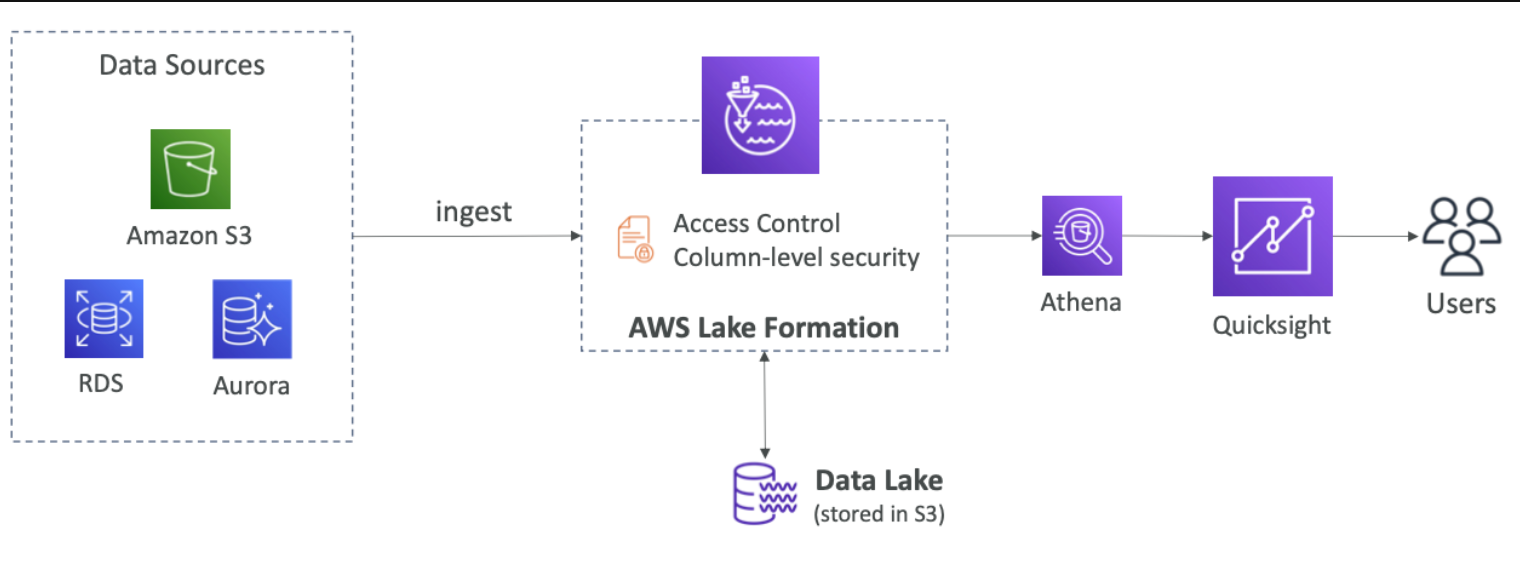
AWS Lake Formation
데이터 Lake 생성을 돕는다고 한다.
Lake 는 데이터 분석을 위해 한곳으로 모아주는 저장소이다.
ake Formation은 데이터 레이크 생성을 수월하게 해주는 완전 관리형 서비스 - 보통 수개월씩 걸리는 작업을 며칠 만에 완료할 수 있음
데이터 검색, 정제, 변환, 주입을 위한 데이터 레이크 구성
데이터 수집, 정제, 이동, 카탈로깅, 복제 등의 복잡한 수동 단계를 자동화하고 기계 학습(ML) 변환을 사용하여 중복 데이터를 제거함
데이터 레이크에서 정형 데이터와 비정형 데이터를 결합할 수 있음
사전 구성된 소스 블루프린트: S3, RDS, 관계형 및 NoSQL DB 등에서 지원됨
애플리케이션에서 행, 열 수준의 세분화된 액세스 제어 가능
AWS Glue 위에 빌드되는 계층이긴 하지만 Glue와 직접 상호 작용하지는 않음
Centralized permissions Example
Kinesis Data Analytics
SQL application
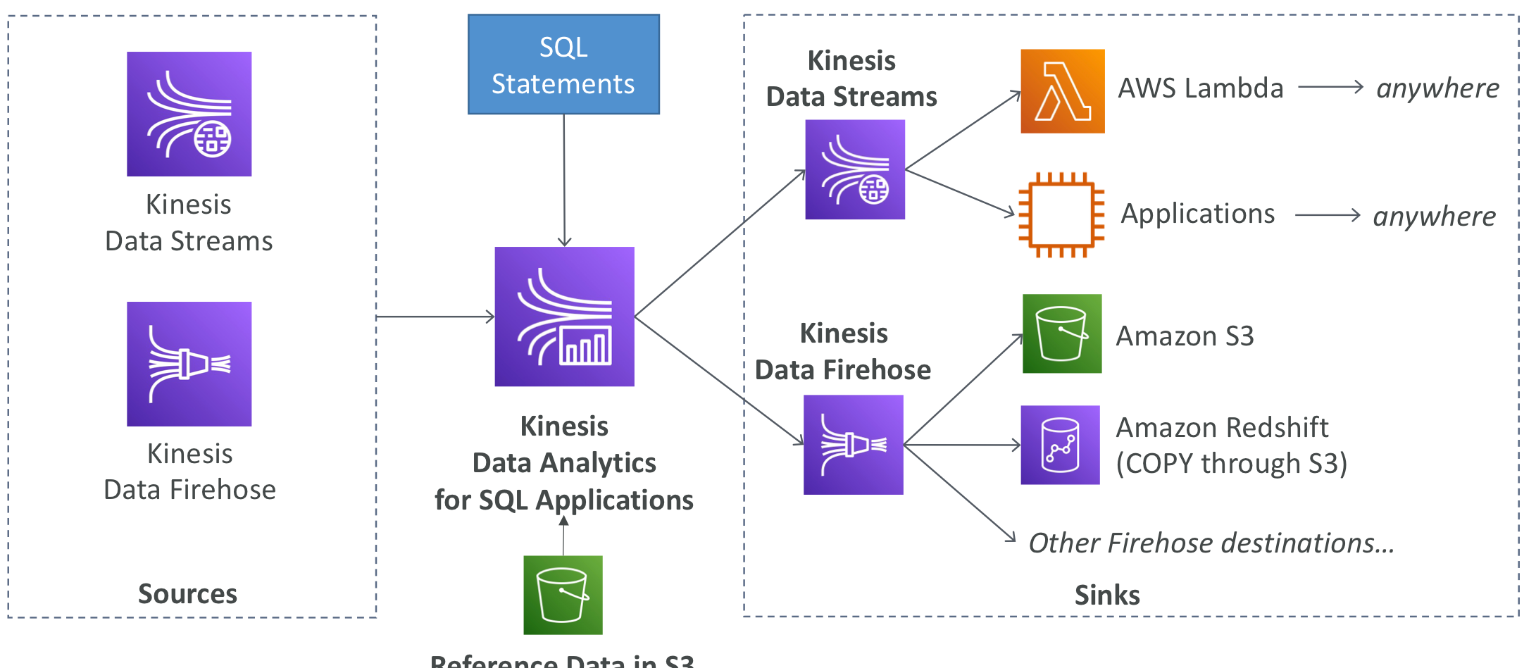
Kinesis Data Analytics는 SQL을 사용하여 Kinesis Data Streams 및 Firehose의 실시간 분석을 수행한다.
Amazon S3의 참조 데이터를 추가하여 스트리밍 데이터를 보강할 수 있다.
완전 관리형 서비스이므로 서버를 프로비저닝할 필요가 없다.
오토 스케일링이 가능하다.
Kinesis Data Analytics에 전송된 데이터만큼 비용을 지불한다.
Output:
Kinesis Data Streams: 실시간 분석 쿼리에서 스트림을 생성
Kinesis Data Firehose: 분석 쿼리 결과를 대상으로 전송
사용 사례:
시계열 분석
실시간 대시보드
실시간 지표
Apache Flink
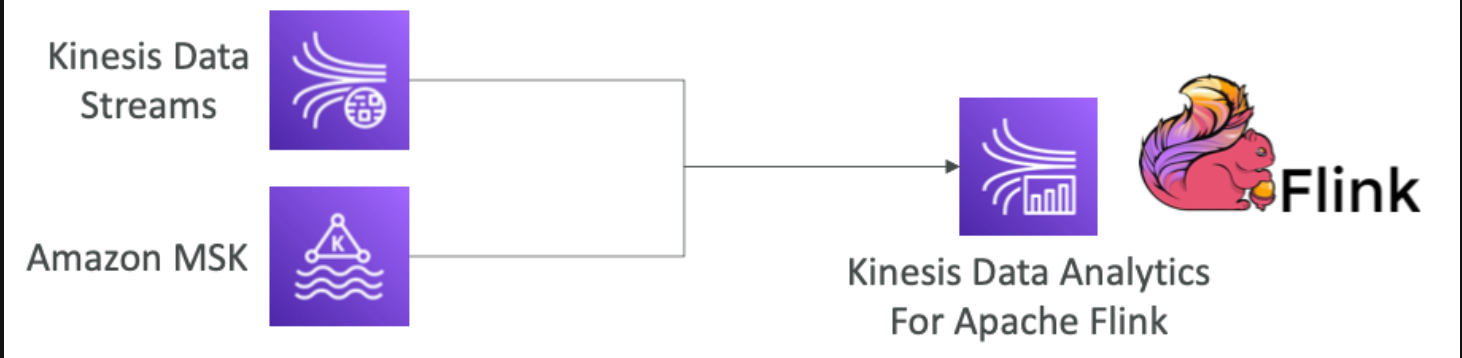
Flink 를 사용해서 스트리밍 데이터를 처리하고 부넛ㄱ한다.
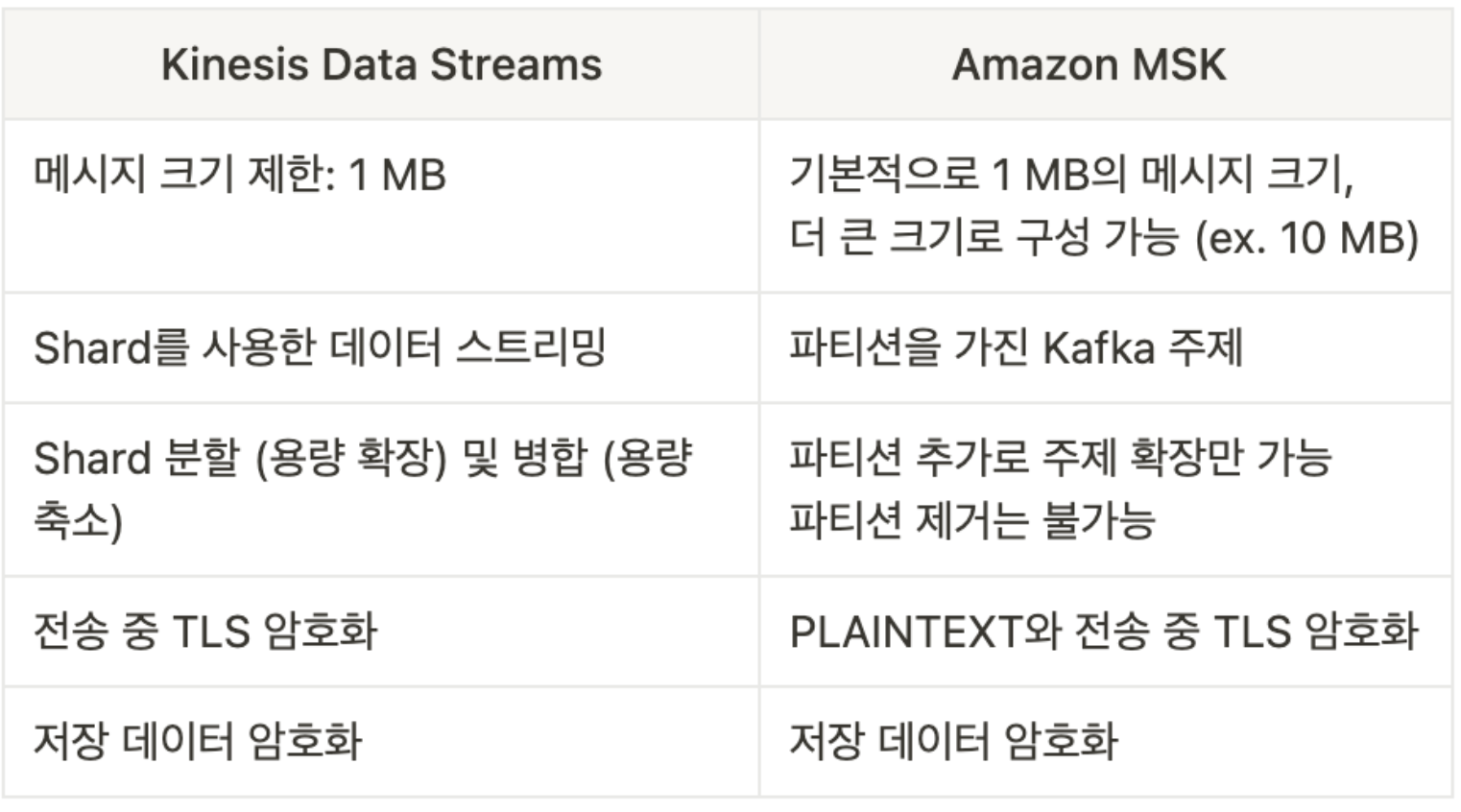
Amazon Managed Streaming for Apache Kafka(Amazon MSK)
Kafka는 Amazon Kinesis의 대안 - 두 서비스 모두 데이터를 스트리밍한다.
MSK는 AWS의 완전 관리형 Kafka 클러스터 서비스
클러스터 생성, 업데이트, 삭제 가능
MSK는 클러스터 내 Kafka 브로커 노드와 Zookeeper 노드를 자동으로 생성하고 관리
고가용성을 위해 VPC의 클러스터를 최대 세 개의 다중 AZ 전역에 배포
일반적인 Apache Kafka 장애로부터 자동 복구 기능
EBS 볼륨에 데이터를 원하는 기간 동안 저장할 수 있음
MSK Serverless
용량 관리없이 MSK에서 Apache Kafka를 실행할 수 있음
MSK가 자동으로 리소스를 프로비저닝하고 컴퓨팅 및 스토리지를 확장함
Apache Kafka at a high level
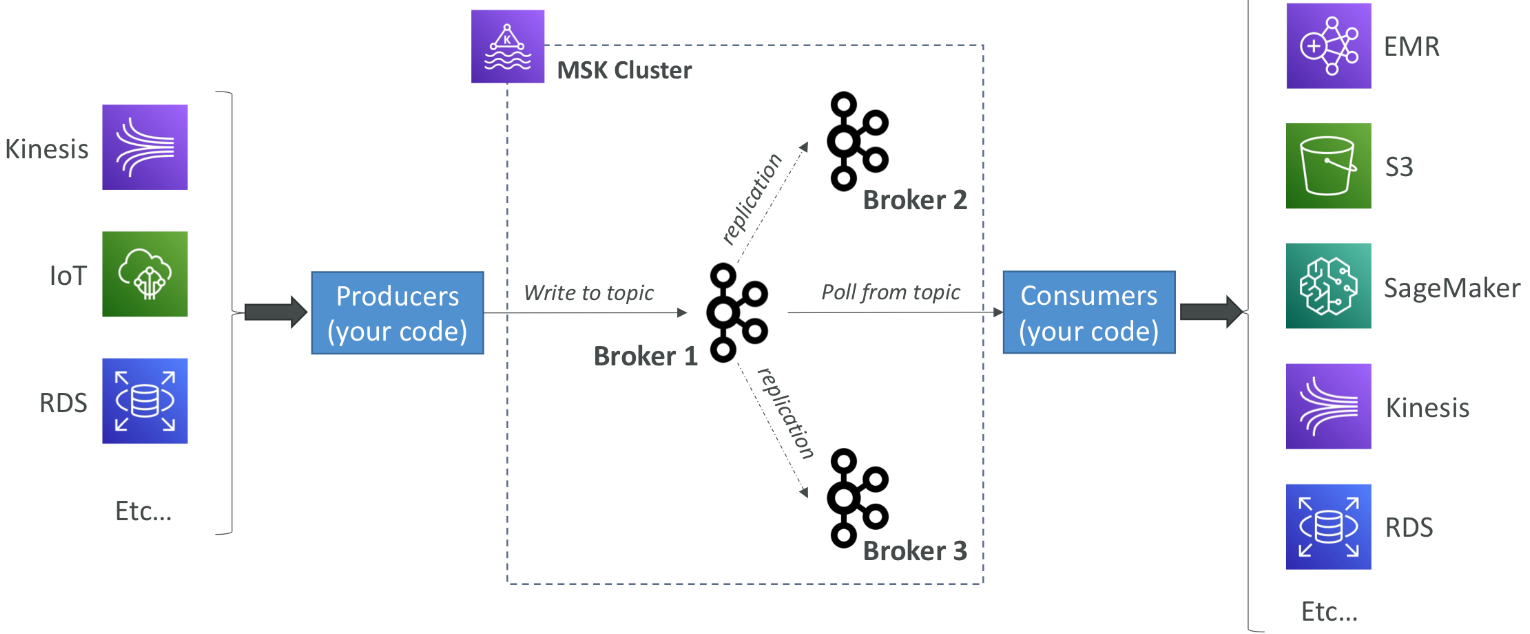
Kinesis Data Streams vs Amazon MSK