
Network 계층에서 제공하는 Service 를 Application 에서 요구하는 서비스로 변환해주는 애가 필요하다
이것이 Transport 계층이다.
Transport services and protocols
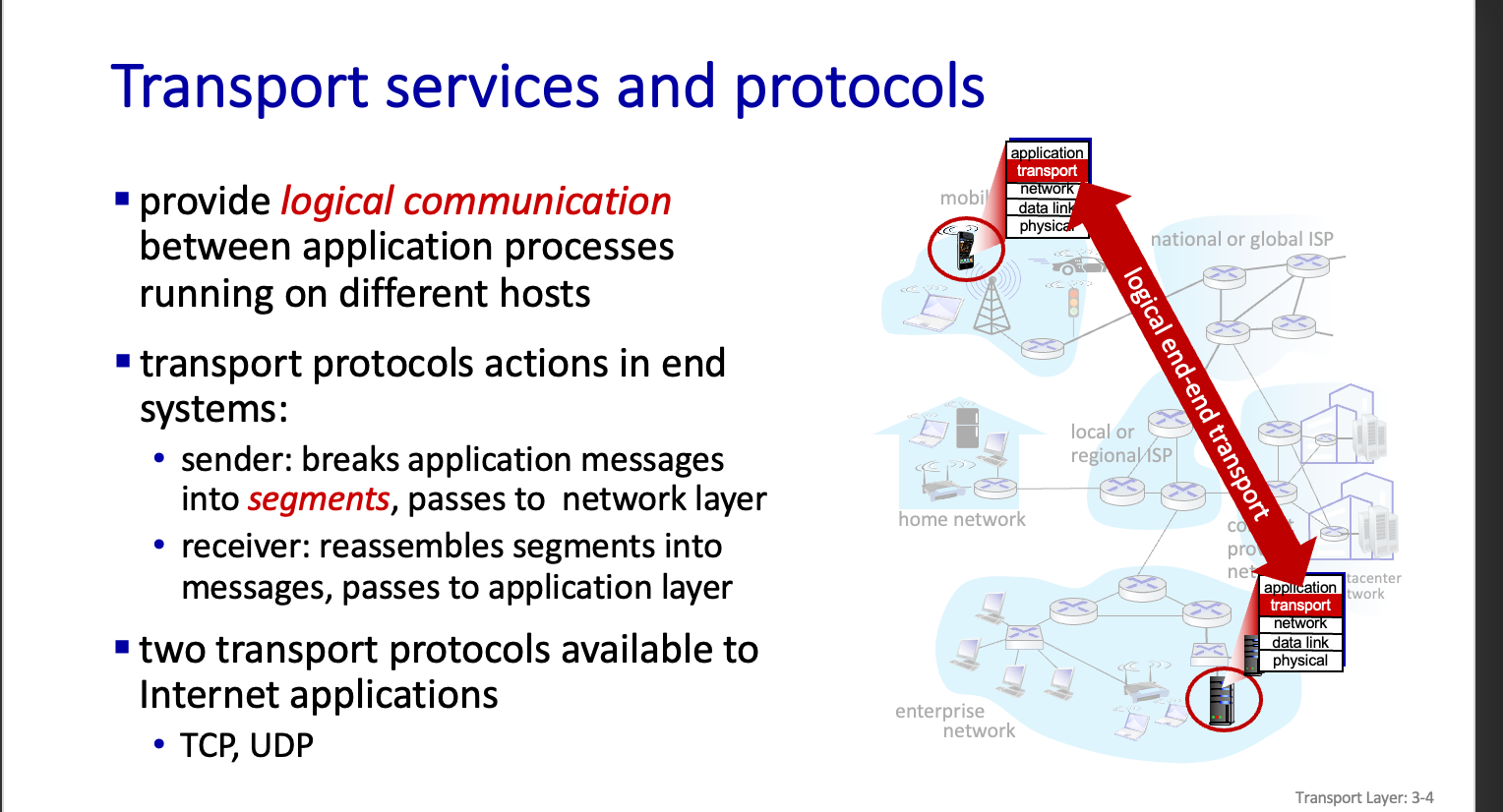
End to End 기능이다.
중간에 Transport 는 있을 수 없다.
중간에서 우편물을 뜯어보는건 말이 안되기 뺴문이다.
Two principal internet transport protocols
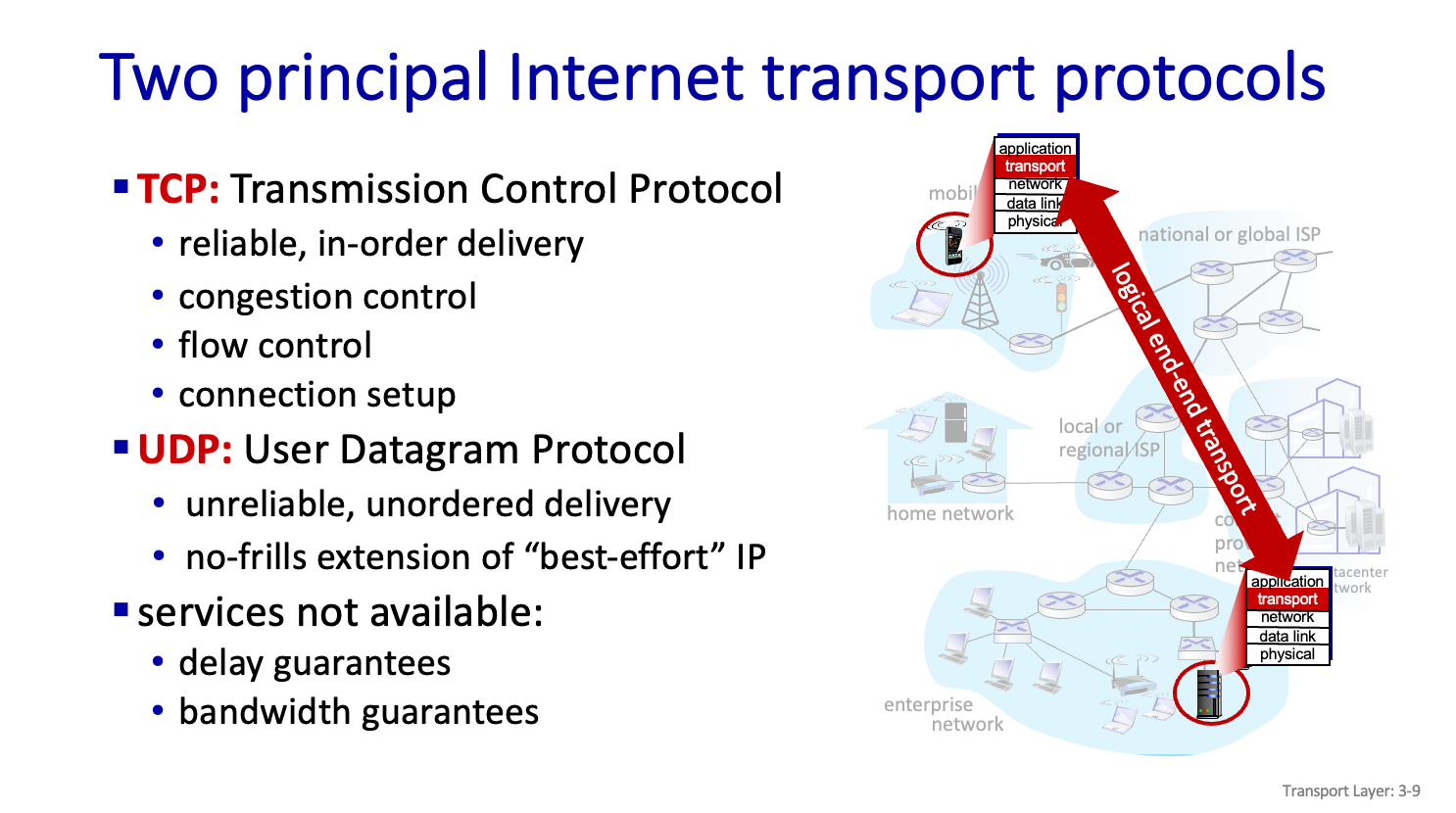
TCP
보내고,받는것이 같다 - realiable
순서 맞춰준다. - inorder
Network 혼잡해지면 알아서 조절해준다 - congestion control
상대방의 상태 모르고 무턱대고 보낸다 - flow control
UDP
UDP 는 아무것도 안한다...
데이터 보내달라고 했음.
그래서 우리끼리의 정보가 왔다갔다한다 한다.
그래서 추가정보를 붙인다
이떄 붙이는 정보를 PCI (Protocol control information) 이라고 한다.
Multiplexing/Demultiplexing
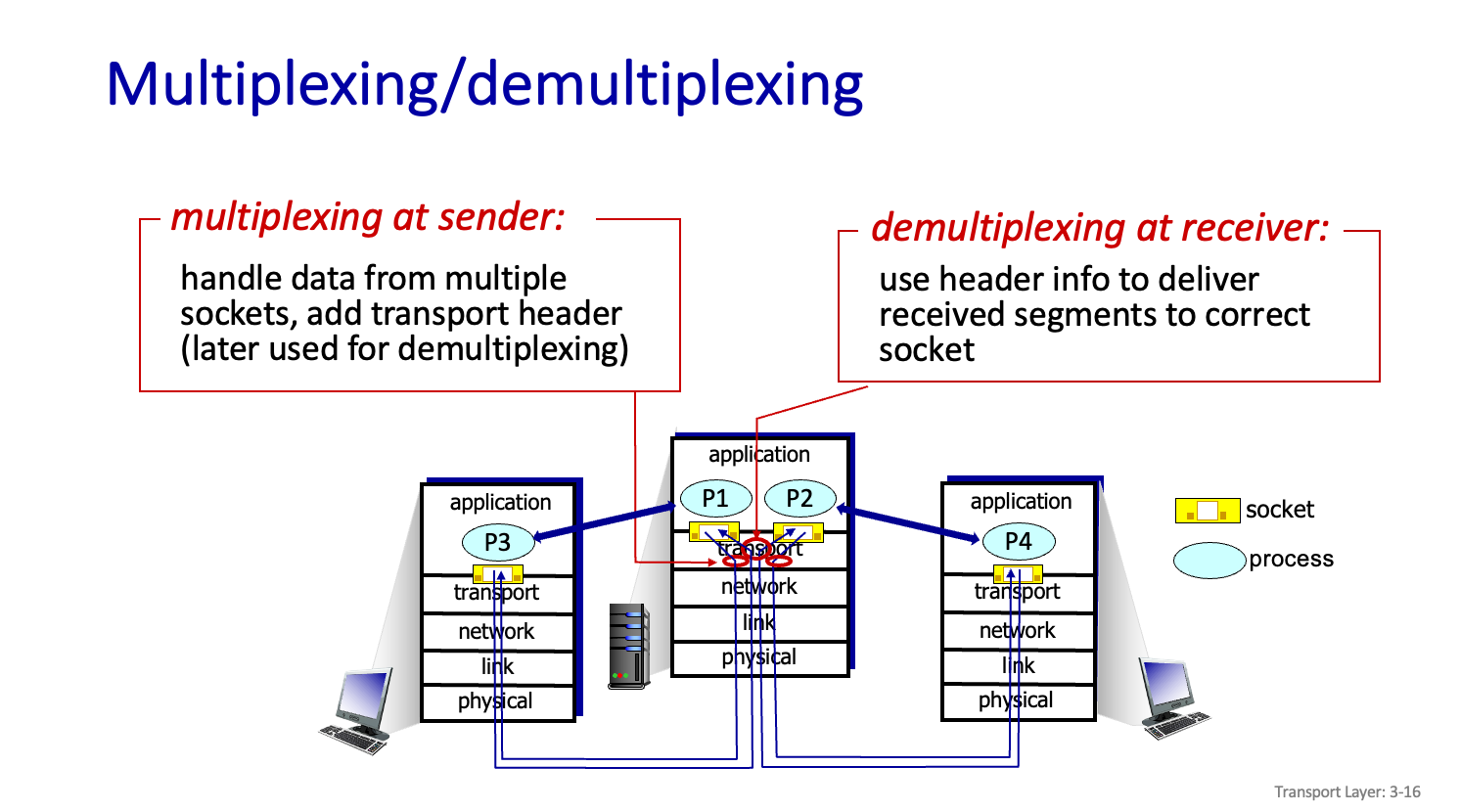
TCP 는 Process 마다 별도의 Buffer 를 관리해줘야한다.
데이터에 따라서 Buffer 에 구분된다.
Mux 는 Os 입장에서 Application이 다양하게 있는데 모듈에서 다 수용할수 있어야한다. 수신 측에서도 Process 가 Data 달라할때까지 Data 분류해야한다.
이때 Process 단위로 어떻게 구분할건가에 대한 고민을 해보자.
Server 가 서로 다른 Client 를 지원할수 있어야한다.
그것을 가능하게 해주는것이 Socket 이다.
How demultiplexing works

역다중화의 정보는 Header 에 담겨있다.
Source # 는 보내는 사람 Dest # 는 받는 사람이다.
또한 Port # 는 Mux 를 할수있게 해주는 중요한 정보이다.
다시 누구한테 줘야할지는 보내는 사람이 애초에 제공한다.
Connectionless demultiplexing :an example
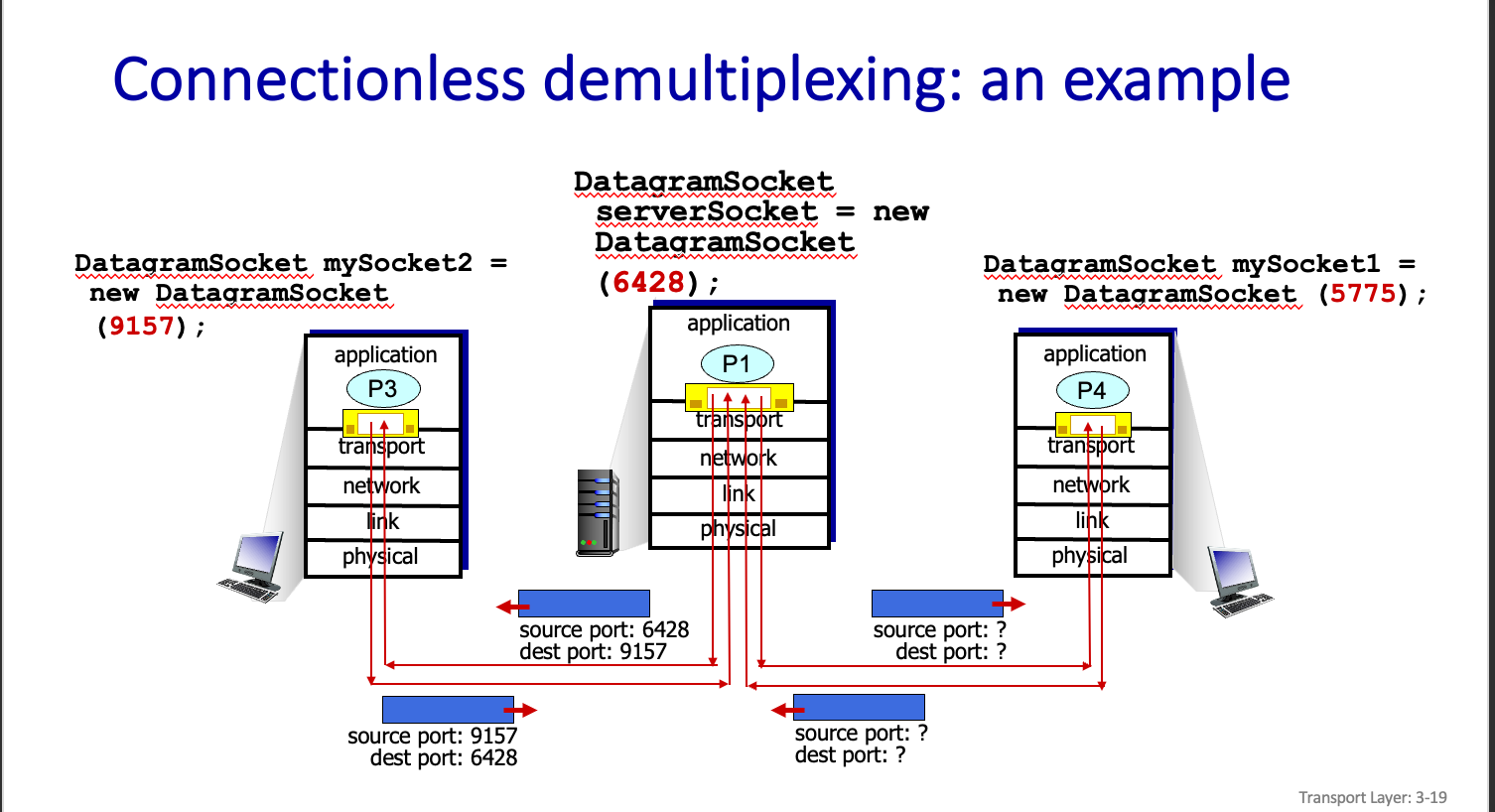
사진 처럼 보낼떄의 Src 가 받을떄의 Dest 가 되면 된다.
Connection-oriented demultiplexing

UDP 는 Connectionless 이고 TCP 는 Connection-oriented 이다.
이떄의 Connection 은 물리적인 Connection 이 아니고 논리적으로 Connection 이 있다는 뜻이다.
그리고 TCP 는 4가지 정보로 Resource 를 별도로 관리한다.
Source Ip Address,Source port #,Dest Ip address,Dest port number 이 4개로 관리를 한다.
그리고 Buffer 는 크기에 제한이 있다. 통신을 할때 너무 많은 데이터가 들어가서 Buffer 에 들어가지못하고 Drop 하게 된다면 Buffer overflow 가 발생한다. 그렇기에 이러한걸 해결하기 위해 flow-control로 해결할수 있다.
또한 Connection 이 있다는 말은 순서에 맞게 간다는 말이다. 길이 있다는 말이다.
마지막으로 TCP 는 서로의 Setup 과정을 거치고 서로 인사하고 끝낸다.
example
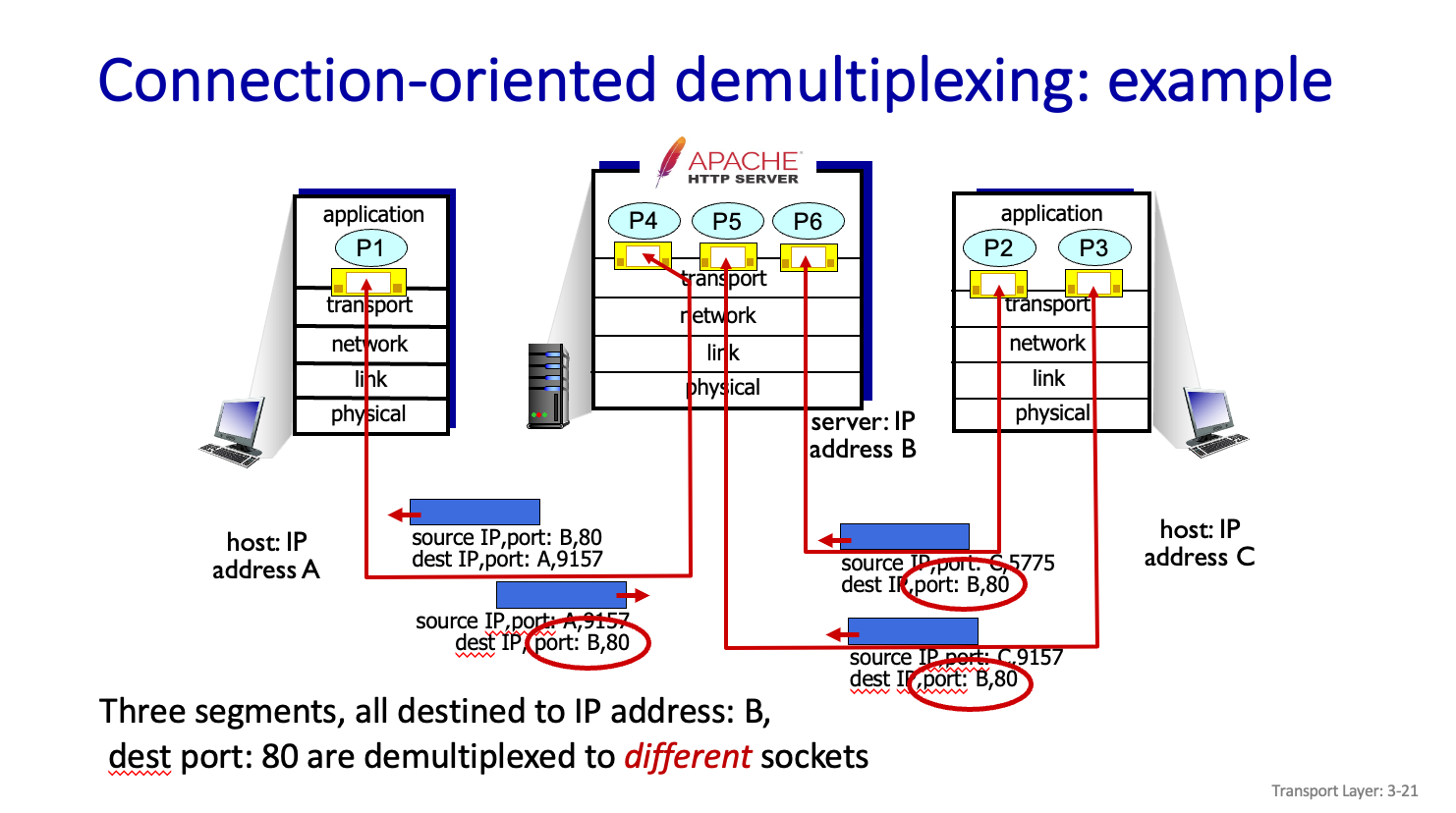
TCP Socket으로 demux 를 가능하게 한다. 상대방과 통신한다면 상대방도 Process 라는 것이다. Os 에서 Connection 관리를 해줘야한다.
OS에서 resource 를 한다.
이건 Buffer를 잡아준다는 건데, 어떤 기준으로 Buffer를 구분할것이냐?
Connection 기준으로 구분을 한다한다.
현재 사진처럼 Clinet 2개를 어떻게 구분할수있나? 현재 Process가 2개 동작중이라고 한다.
이떄 Client Process 의 Port # 로 구분한다.
두 Port # 는 다르다.
Mux,Demux 할때 Port를 활용한다 한다.
그렇게 두 Process 가 서로 다른 Connection 임을 구분할수있다.
UDP:User Datagram Protocol
UDP 는 Connectionless transport protocl 이다. Besf effort service 인 internet 을 그대로 Application 에 올려주는 것이다.
이렇게 아무 과정 없이 그대로 Application에 올려주기때문에 Loss 가 생길수도 있고, Data 의 순서가 엉망이 될수도 있따.
그리고 TCP 와는 다르게 Setup을 거치지 않고 그냥 바로 데이터를 보낸다.
또한 Segment가 독립적이라고 한다.
why is there a UDP?
Setup 시간이 없어서 시간을 벌수있다.
또한 Packet의 Header 가 간단하다.
마지막으로는 굉장히 간단하다.

UDP 는 간단하게 주고 받는것이다.
그래서 DNS,SNMP,HTTP/3 에 사용된다.
DNS 는 Domain Name 에 대한 IP 주소 내놔라 하는것이다. 간단한 Query 던지고 응답을 받는다.
SNMP 는 Access 할때 필요한거 내놔라 하는것이다.
또한 UDP 위에 Quick 그리고 위에 HTTP 를 놓으면서 HTTP/3 를 서비스한다.
여기서 quick 은 light weight 한 신뢰성 있는 Data 전송을 위한 transport 계층이다. TCP 와는 다르다.
만약 UDP 에서 신뢰성 을 제공하고 싶으면 어떻게 해야하나?
APplication 에서 알아서 해야한다..
Transport 에서는 할수가 없다.
UDP : Transport Layer Actions
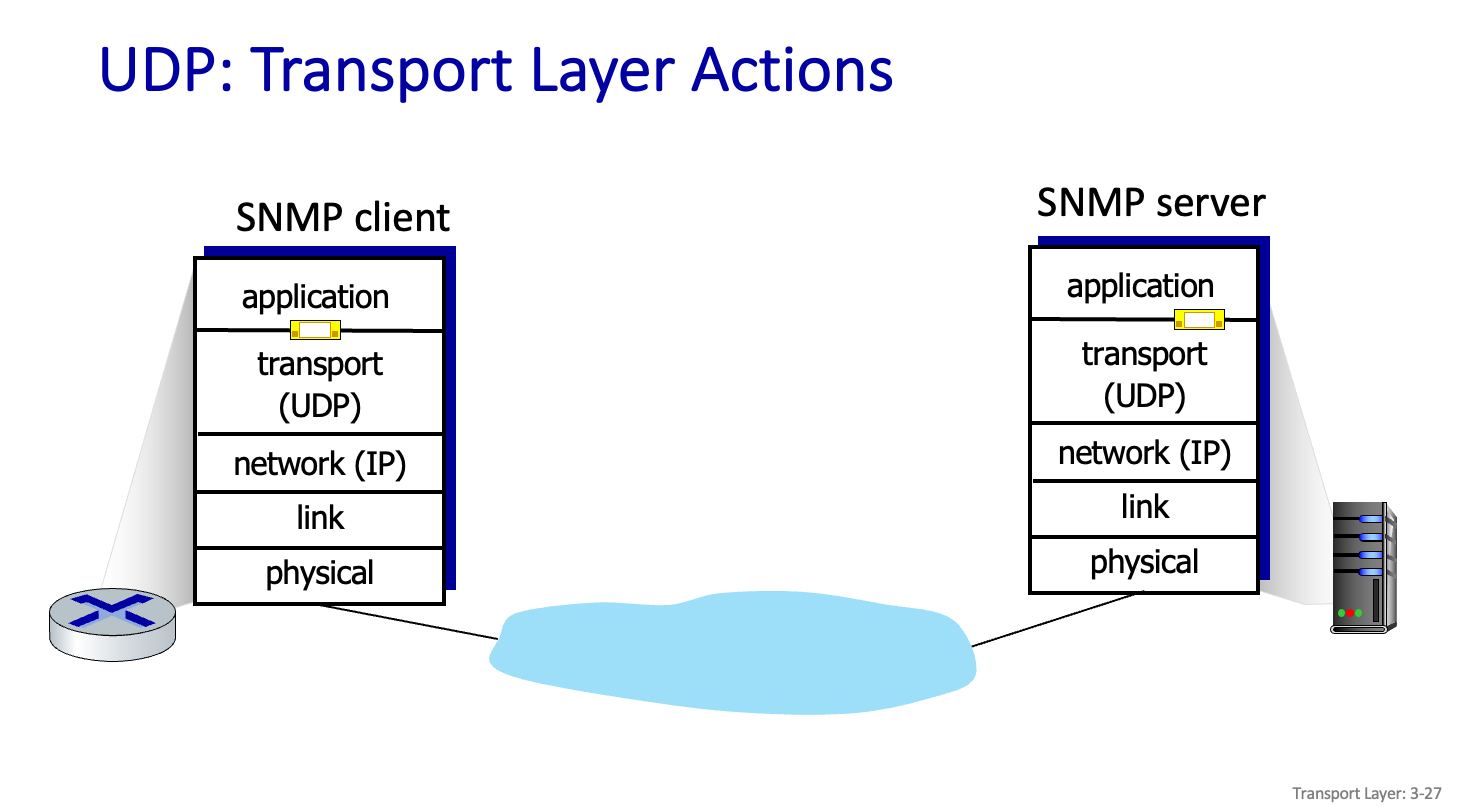
우편물을 직접 만들어서 보내는 것이다.
TCP는 여기서 여기까지 정해서 안정적으로 보내라 하는 것이고
UDP 는 Segment로 잘라서 보내야한다.
UDP segment header
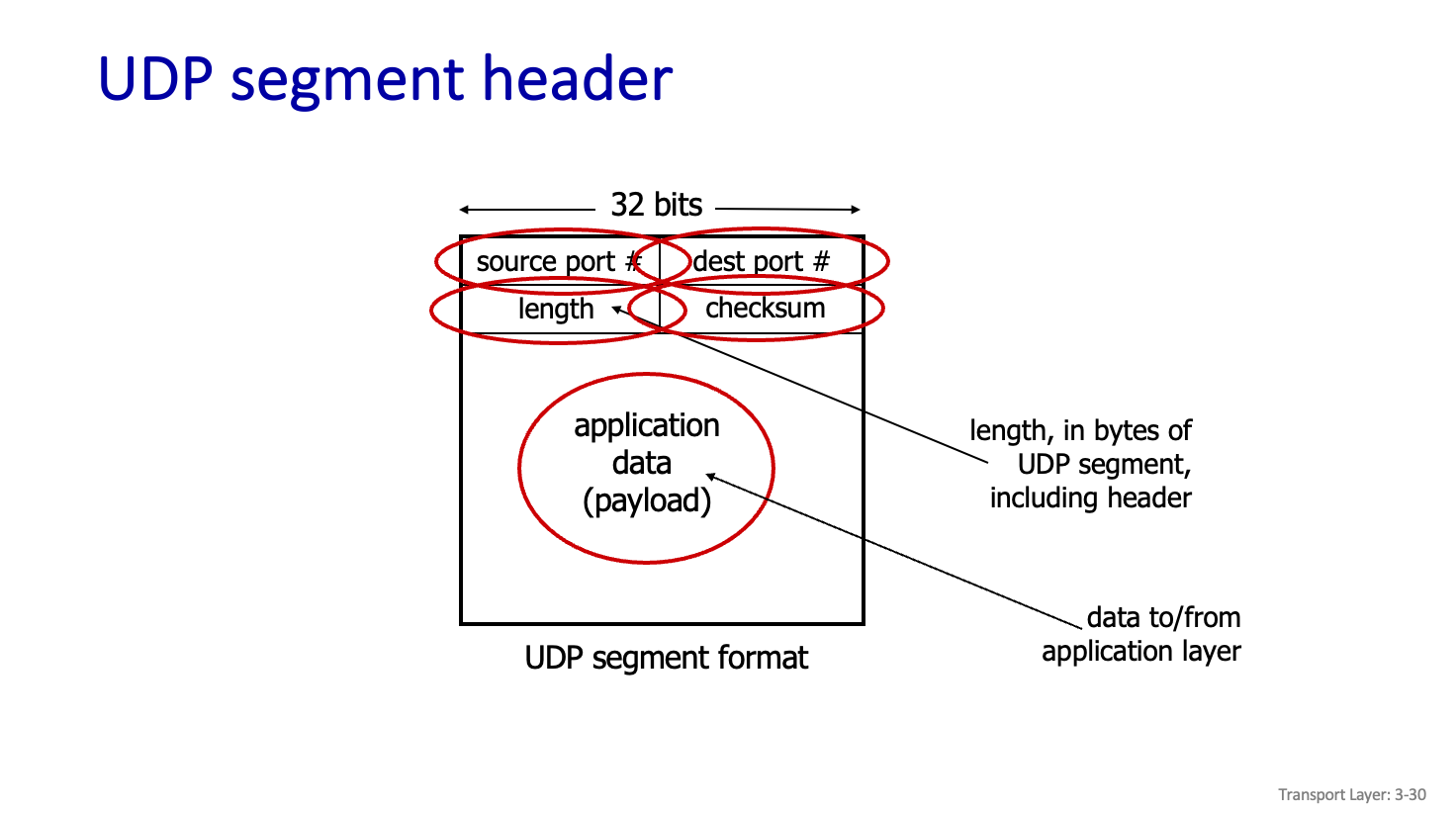
Kernel 에 Process가 있다면 각각 사용하고 있는 Port # 가 mapping 되어 있다. Port # 로 관리하면 된다.
하여튼 UDP segment의 Header내에 있는 것들을 확인해보자.
Source port # , dest port # 는 상대방의 MUX,DEMUX 를 위한것이다.
length 는 길이를 뜻하고 Header 를 포함해서 UDP Segment를 포함한 길이이다.
Checksum 은 오류 확인을 위한것이고 보내는것과 받는게 다르다라는것을 확인할수 있는것이다. 만약 데이터가 다르면 그냥 버린다.
UDP checksum

이렇게 checksum 비교했는데 같지 않으면 Error 이다.
어떻게하나?
그냥 Application에 올려주면 안된다. 그냥 버려라
Internet checksum:an example

checksum 은 16bit로 이뤄져있다.(앞의 header 확인 해보면 된다)
이렇게 두 데이터를 합하고 Carry 된것은 다시 더해주고 1의 보수를 해주면 Checksum 이 된다. 이러한 방식 그대로 수신에서도 똑같이 해보고 checksum 과 비교해서 같으면 Error 가 없는것이고 checksum과 결과가 다르면 Error 라는 것이다.
하지만 100% 검출은 아니다. 그래도 상당히 높은 검출률을 가지고 있고, 하드웨어로 검출을 하게 되면 비용,성능 면에서도 많은 Cost 가 들어서 간단한 Sw 검출로 한다고 한다.
Principles of reliable data transfer
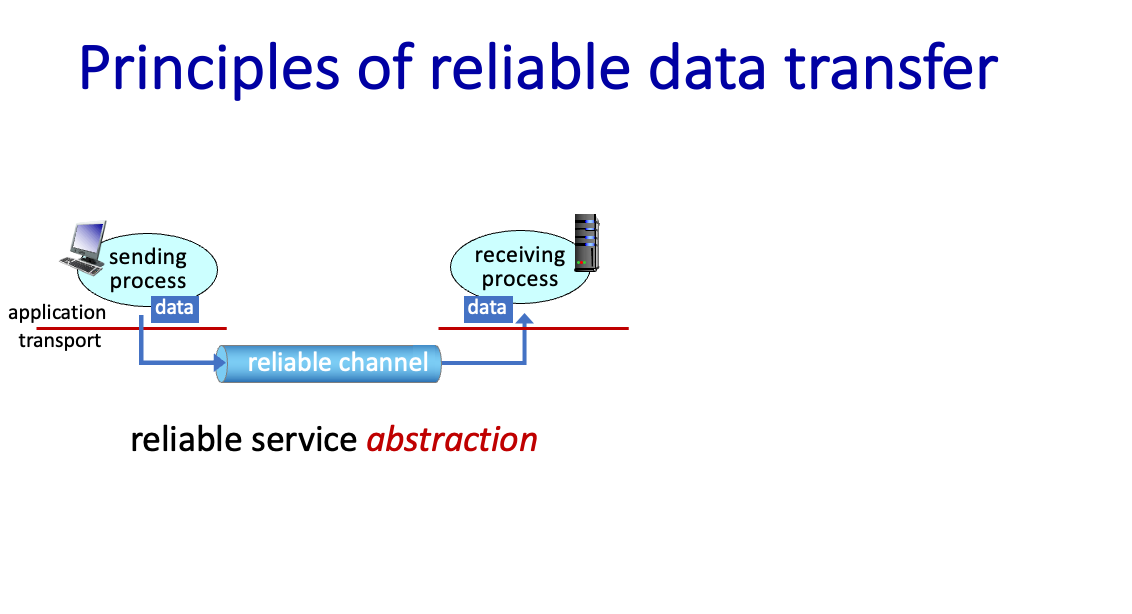
보내는 것과 받는게 같다라고 보면 그럼 그냥 읽을꺼임.
신뢰성 있는 channel 이 보장 됐기 때문!!
근데 이렇게 신뢰성 있는 channel 이 보장이 될까..?
현실에서는 unreliable channel 이다..
그래서 상대간의 protocol 이 필요한것이고 그게 TCP 이다.
문제는 Data를 보냈을때 상대 상황을 모른다. 그걸 감안해서 Protocol 이 만들어야 한다.
Reliable data transfer : getting started
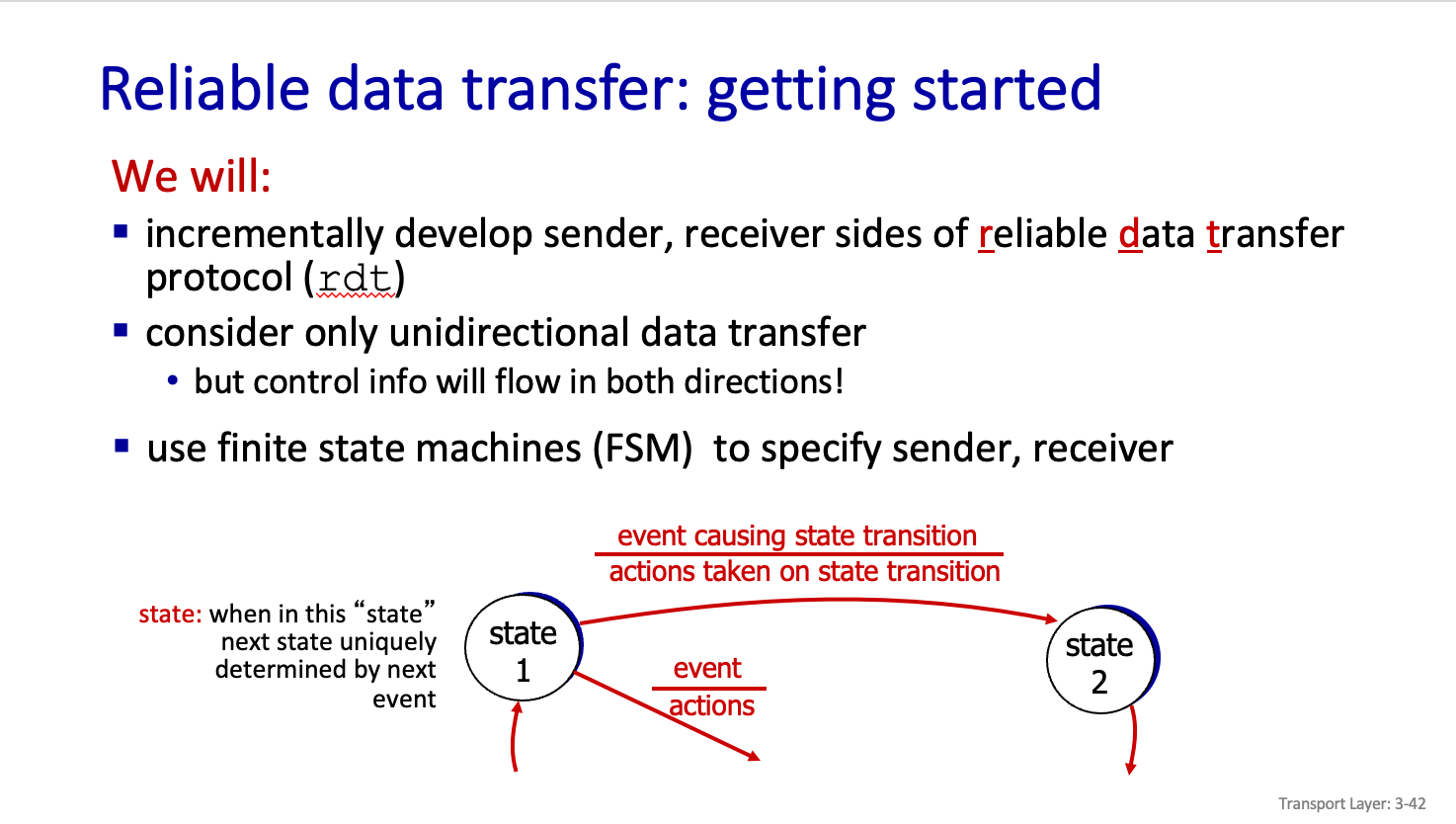
Protocol 을 기술할떄는 Finite state machine 을 사용해서 기술한다고 한다.
사진에서 확인 할수 있는것처럼 event 가 발생하면 action을 통해서 transition 이 이뤄진다.
rdt1.0: reliable transfer over a reliable channel

현재는 channel 이 reliable 하다는 가정이다.
channel 이 reliable 하면 당연하게 bit error, packet loss 는 발생하지 않게 될것이다.
그래서 Sender 의 입장을 보면 초기 상태는 위에서 부터 Data 를 보내라는 요청을 기다리고 있다. 이때 rdt_send() 이벤트가 발생하여서 packet을 만들고 udt send 하면 된다.
지금은 bit error,packet loss 를 겪지 않고 잘 갈꺼다. reliable channel 이니까.
그리고 receiver 는 그냥 Data를 받고 다시 보내주면 된다.
그렇기에 초기상태는 밑에서 부터 data 오는것을 기다린다.
그러다 rdt_rcv() 이벤트가 발생해서 packet을 뽑아내서 data 를 application 에 올려준다.
이때도 잘 갈꺼다... 위에와 같은 이유로,
rdt2.0:channel with bit erros

하지만 현실은 방금과 같지 않다.
Bit error 는 있을수 밖에 없다...

상대방이 error 가 있는지 없는지 검출하기 위해서 checksum 을 넣어야 한다.
그리고 ACKs과 NAKs 를 사용해서 ACK 는 너가 보낸거 잘 받았다! 라는 의미고 NAKs 는 너가 보낸거 error 다! 라는 의미다.
rdt2.0:FSM specifications
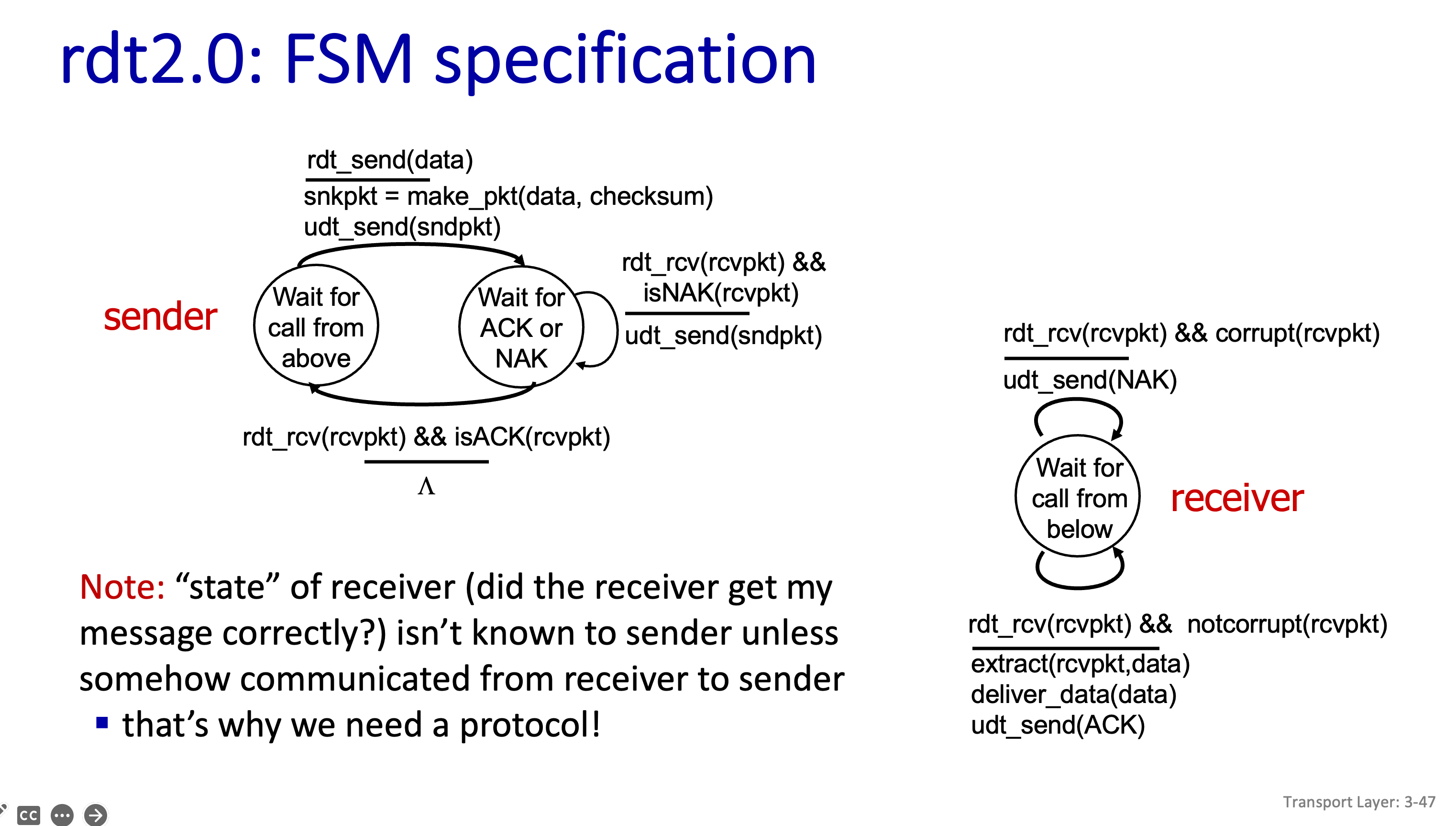
그래서 NAKs 를 받으면 재 전송한다고 가정하고 진행해보자.
현재 Sender 먼저 보면 똑같이 위에서 부터 Data 를 보내라는 요청을 기다리고 있다. 그러다 rdt_send() 이벤트가 발생해서 data 보내달라고 한다. 그러면 data 와 checksum을 구해서 packet을 만든후 보내주면 된다.
그런다음 Ack 이든 NAk 이든 기다려야한다. 뭔가가 왔을떄 Ack 이면 제대로 간것이고 다음 Data 를 보내면 된다. 하지만 Nak 이면 재전송 해야한다.
그리고 receiver 입장에서 보면 또 초기상태는 밑에서 부터 data 오는것을 기다린다. 그리고 corrupt 는 Error 가 있는것이고 NAK 를 보내면 된다.
그리고 Corrupt 가 없다는것은 Error가 없다는 것임으로 Packet 을 추출해서 Data 를 올려주고 자기는 ACK 보내면 된다.
근데 또 문제점이 있다.
ACK과 NAK 도 사실 사실 Message 인데 이게 제대로 간다는 보장이 없다.

상대방은 ACK을 보낸다 근데 내가 NAK 으로 판단해서 재전송을 한다고 생각해보자. 그럼 Receiver 입장에서는 아까 Data 를 받았는데 또 새로운 Data가 오니까 이게 새로운 Data 인지 재전송인지 모른다...
이 문제를 해결하기 위해서 동일한 번호로 Data 를 수신 받으면 재전송을 하면 된다!
rdt2.1:(sender,receiver) handling garbled ACK/NAKs
그래서 0,1 의 번호를 두어서 한번은 0 한번은 1 이렇게 보내면 된다.
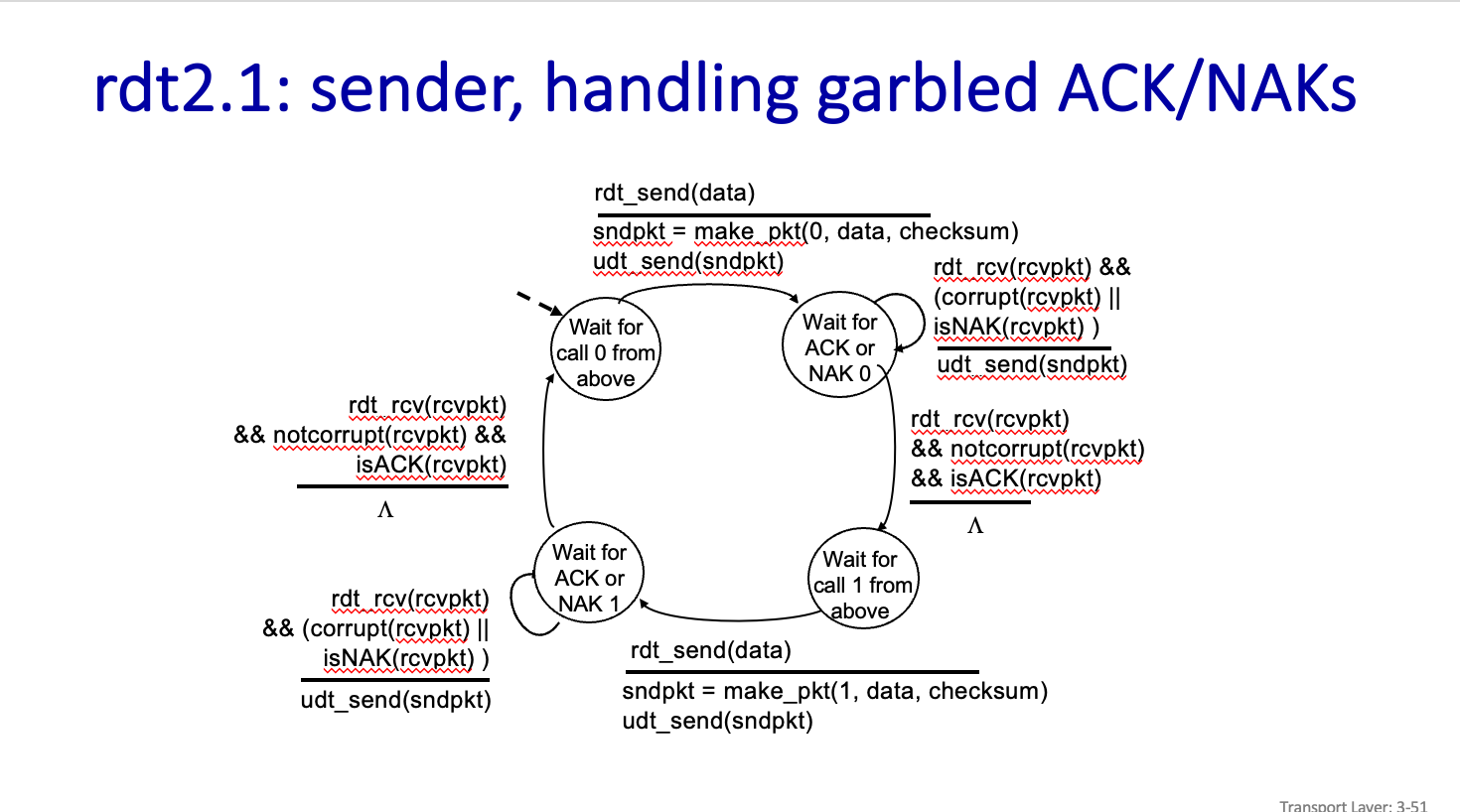
기존의 방식과는 같지만 초기 상태에서 rdt_send() 이벤트가 발생해서 Packet 을 만들때 이제는 Sequence #, Data, Checksum 으로 Packet을 만든다. 그리고 udt_send() 로 보내고 0 에 대한 ACk,NAK 을 기다리면 된다.
그리고 Corrupt 이거나 NAK 이라면 다시 해당 번호에 대해서 기다리면 된다.
근데 Notcorrupt 이거나 ACK 이라면 데이터를 Application 으로 넘기고 이제 1번에 대한 ACK 이나 NAK 을 기다리면 된다.
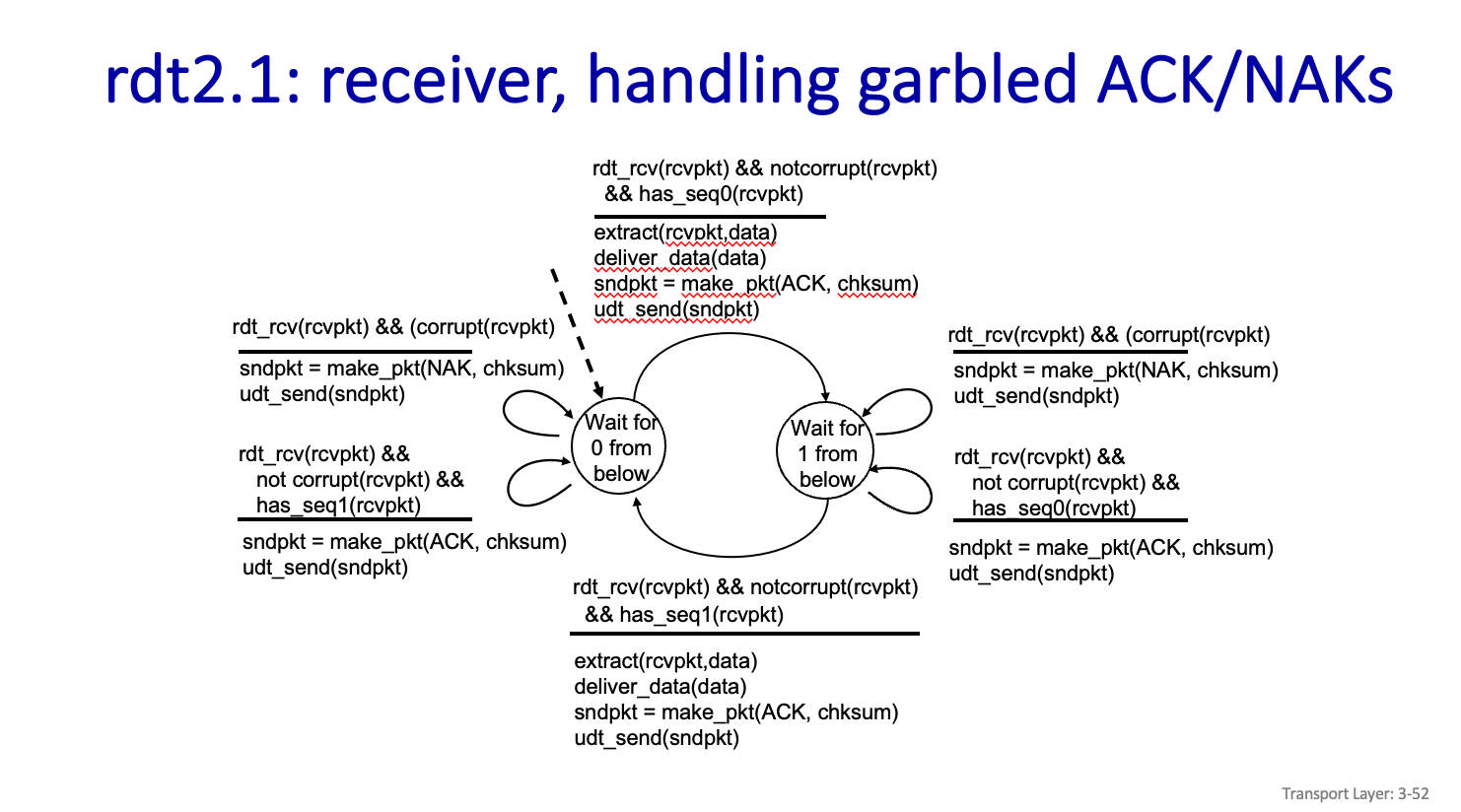
그 다음 receiver 에서는 초기 상태에서 rdt_rcv() 이벤트가 발생했고, notcorrupt 이고 0번에 해당하는 내용이면 Packet을 추출하고 data 를 Application 으로 보내면 된다. 그리고 ACK 또한 message 임으로 checksum 과 같이 Pakcet으로 만들어서 다시 보내준쪽으로 보내주면 된다.
그런다음 1번에 대해 기다리고있으면된다.
이때 rdt_rcv() 이벤트가 발생했고, corrupt() 이라면은 Nak과 함께 Checksum 으로 Packet을 만들어서 보내주면 된다.
하지만 not corrupt() 이고 1번을 기다리고있는데 0번에 해당하는 데이터가 오게 된다면 Duplicate Data 이다..
하지만 이또한 Data 가 잘 왔다는것은 맞아서 ACK과 checksum으로 Packet을 만들어서 다시 보내주면 된다.
discussion

0,1 로만 데이터를 주고 받는것이 충분하나...?
할떄 방금과 했던것 처럼 하나 보내고 잘받고,,, 그리고 하나 보내고 잘받고,,할때는 잘 된다고 한다.
이러한 방식을 Stop & Wait 방식이라고 한다.
효율은 좋지 않다고 한다.
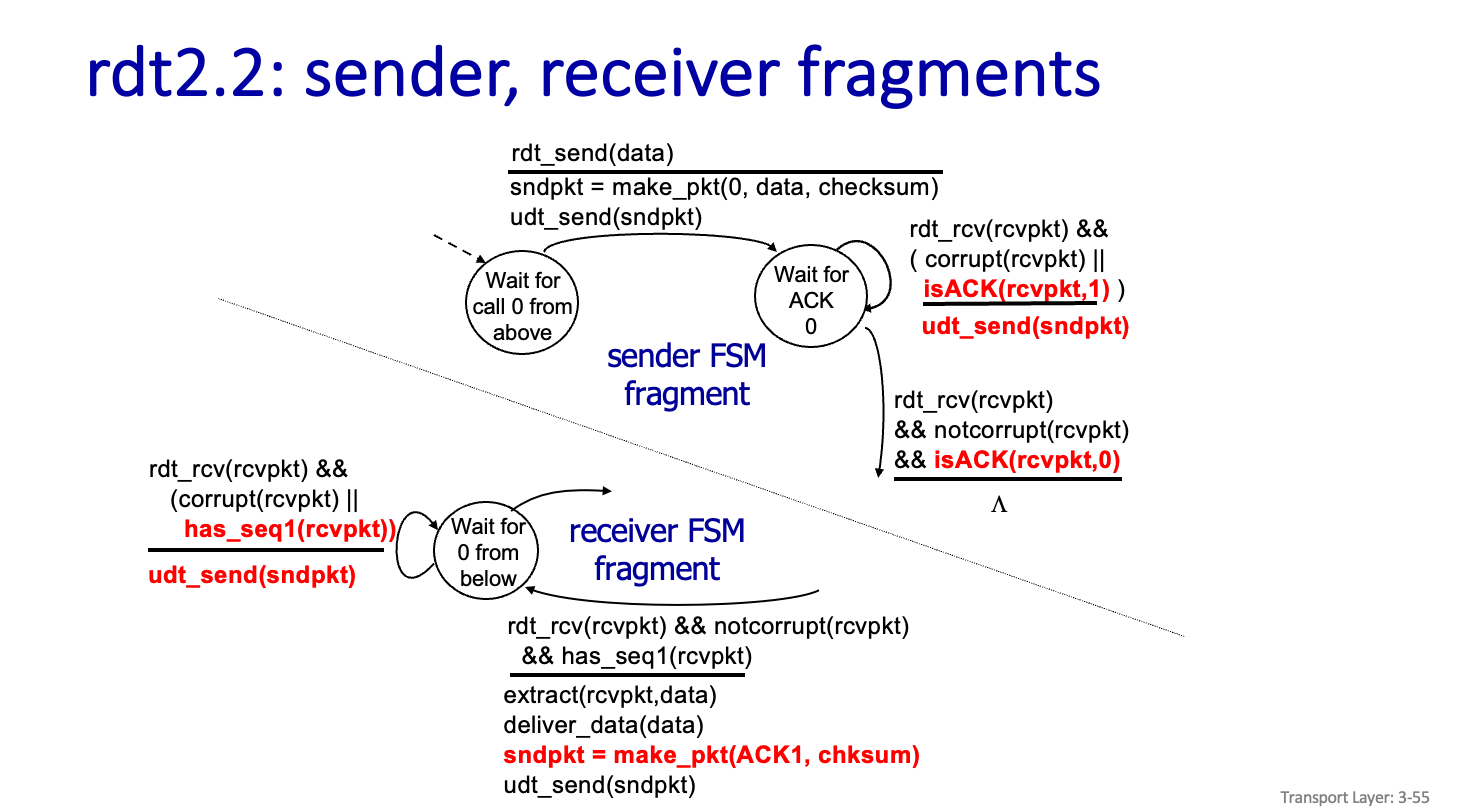
rdt2.2:a NAK-free protocol

Messeage 수를 줄이기 위해서 NAK 을 사용하지 말자라는 차원에서 나온 Protocol 이다.
rdt2.2:sender,receiver fragments
rdt3.0:channels with errors and loss

이전까지 했던것들은 Data 가 가긴 가는것이였따.
하지만 만약 Data 가 실제로 가지않는다면,,,?
Data 보내고 어느정도 기다리다가 ACK 이 안오면 재전송한다.

seq # 로 재전송 데이터인지 새로운 데이턴지 구분할수 있어야한다.
그리고 timer 를 두어서 그 시간내에 해당하는 ACK,NAK 이 안오면 재 전송을 한다.
rdt3.0 sender
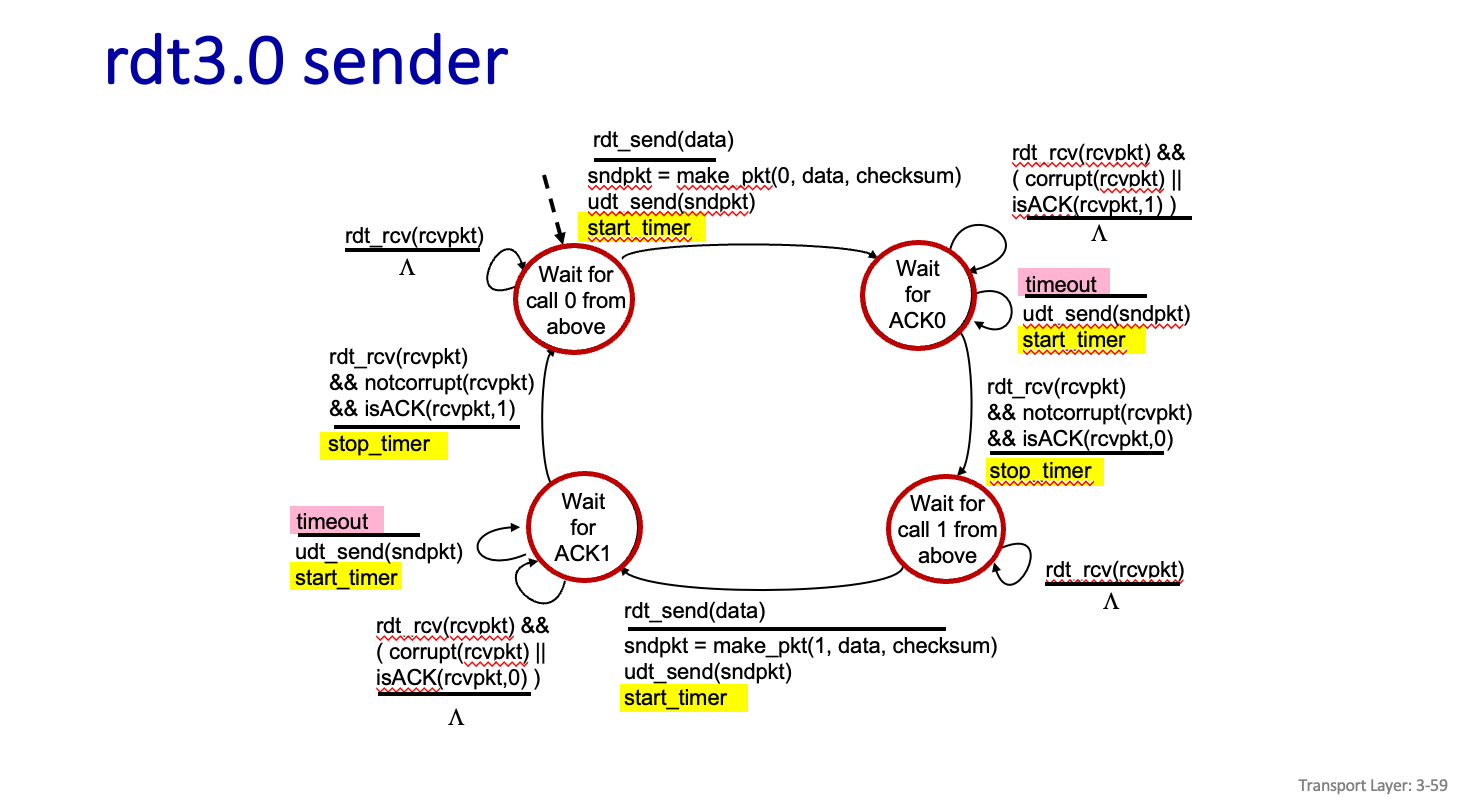
이전과는 다른점은 기다리다가 값이 오지 않으면 다시 재전송을 기다리는 것이다.
또한 not corrupt() 이벤트가 발생했고 그게 기다리고 있던 Data 의 seq # 라면 timer 를 종료하고 이제 Data를 보내주면 된다.
그리고 1번에 대한 Data를 기다리면 된다.
rdt3.0 in action
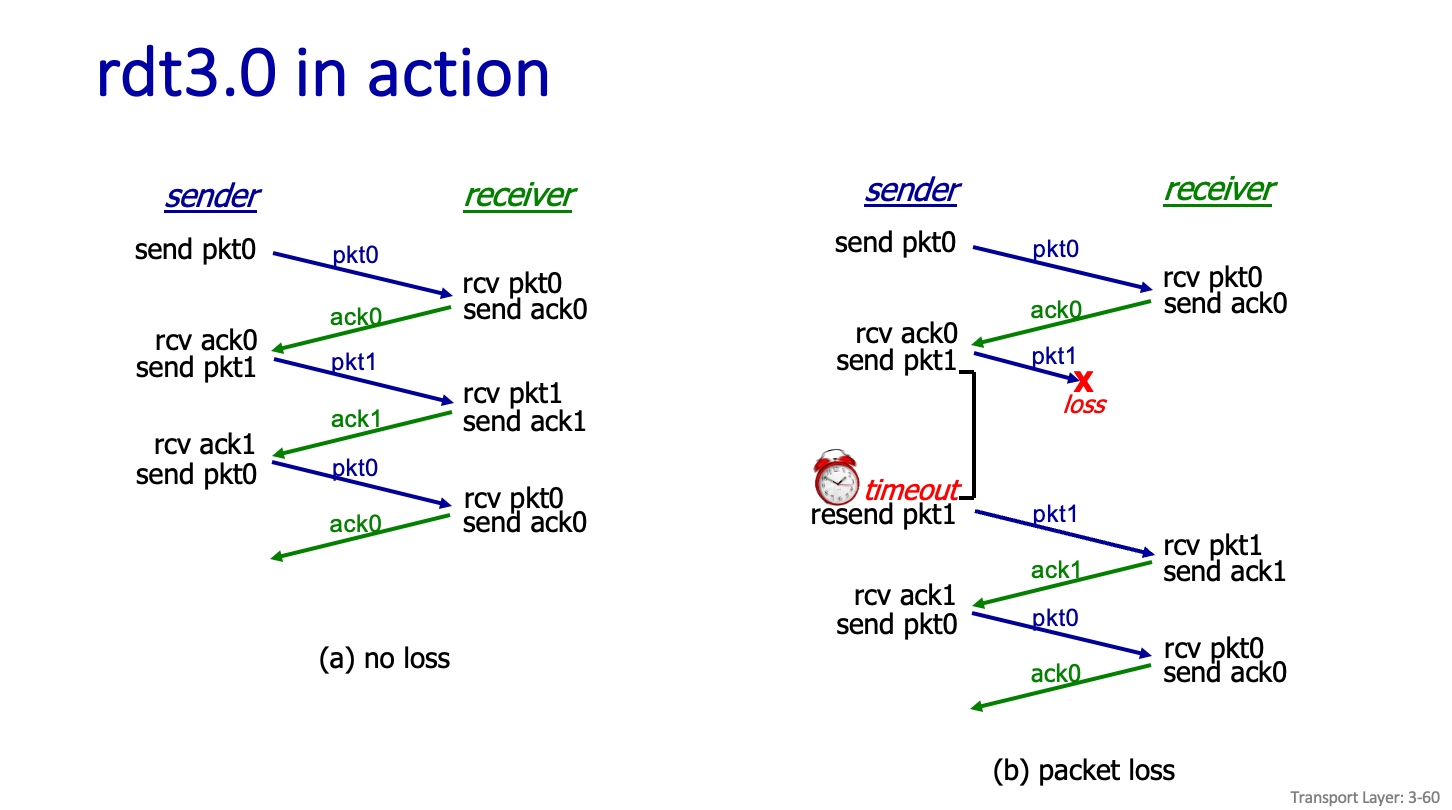
계속 Data 를 보내면 안된다.
Flow control 했다는건 상대방은 Buffer를 가지고 있다는것이고
Buffer 에서 감당 가능할 정도만 보내야한다. 이것을 flow -control 이라한다.
rdt3.0: stop and wait operation
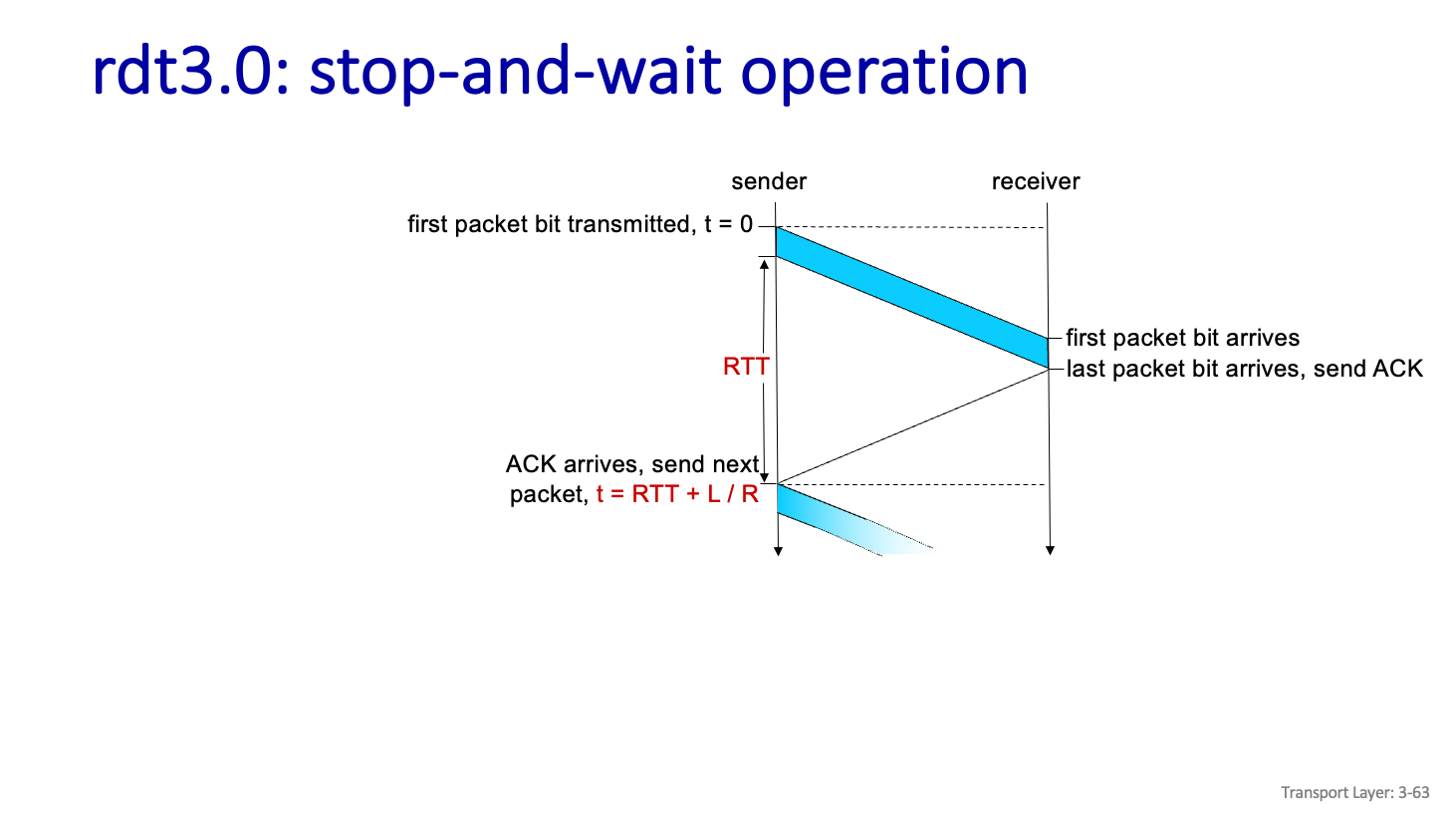
위에서도 말했던것 처럼 stop and wait 는 효율이 좋지않다.
first packet bit transmitted 부터 first packet bit arrives 까지를 Propagation delay 라고 하고 last packet bit arrives 부터 ACK arrives 까지 도 Propagation delay 라고 하고 이것을 Tp 라고 부르자.
그리고 First packet bit arrives 부터 Last packet bit arrives 까지를 Transmission delay 로 Tx 라고 부른다.
그럼 실제로 필요한 부분은 Tx 인데 Tx 하나를 제대로 보내기 위해 얼마나 쓰이나보면
Tx/2*Tp+Tx 를 하면 된다.
그걸 Tx로 나누게 된다면 1/2(Tp/Tx)+1 로 할수있고 (Tp/Tx)를 A라고 본다면 A는 연속적으로 Data 넣을때 몇개를 밀어 넣을수 있나를 뜻하게 된다.
Tx를 보내기 위해 2*Tp+Tx라는 시간을 쓰는게 너무 비효율 적이라는 말이다.
rdt3.0:pipelined protocols operation

그래서 pipeline 을 사용해서 하나의 Packet이 아니라 여러개를 보낸다. 각각 데이터에 대해서 수신 받고 다 Ack 보내면 된다.
Link 계층에서도 하나 보내고 기다렸다가 하나보내고 하는걸 IDLE RQ 라고 한다 그리고 그 반대 말인 Continous RQ 가 있다고 한다.
RQ 는 Repeat Request 로 Continous RQ 에는 두개가 있는데 Go-Back N, Selective Repeat 가 있다고 한다.
Go-back-N : sender
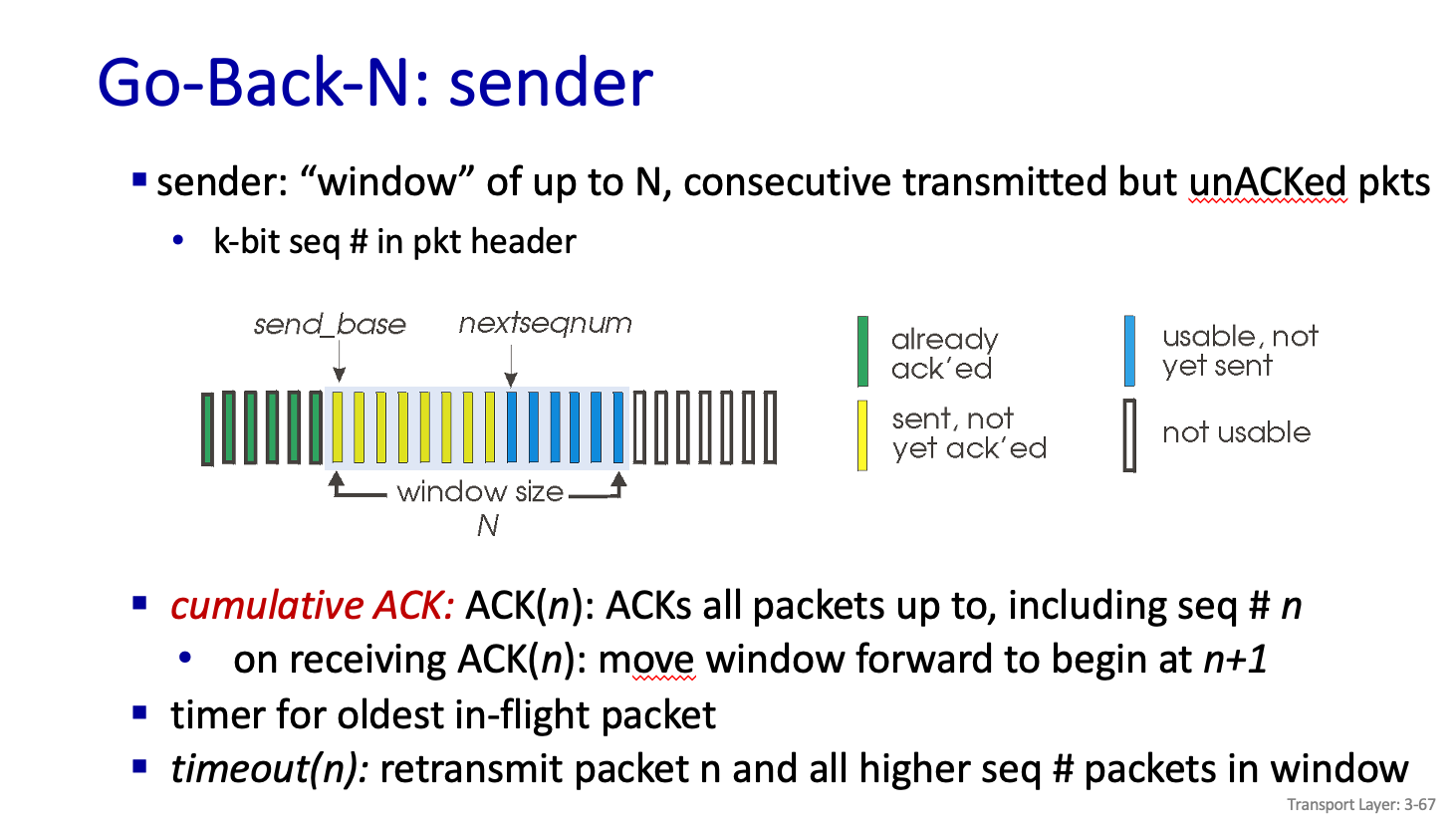
이름에서도 볼수있는것처럼 진행하다가 Error 가 있는 부분은 다시 그 부분으로 가서 거기서 부터 다시 보내는 것이다.
그리고 여기서는 Cumulative ACK 이라는 용어를 쓰는데 N번까지 다 잘 받았다 라는 의미로 쓴다.
그럼 1,2,3,4,5 를 순차적으로 보낼때 3번에 대한 ACK 이 안와서 기다리다가 재전송을 하는데 이떄 ACK(4)를 보내면 되나..? 안된다는것이다.
ACK(2)를 보내야한다.
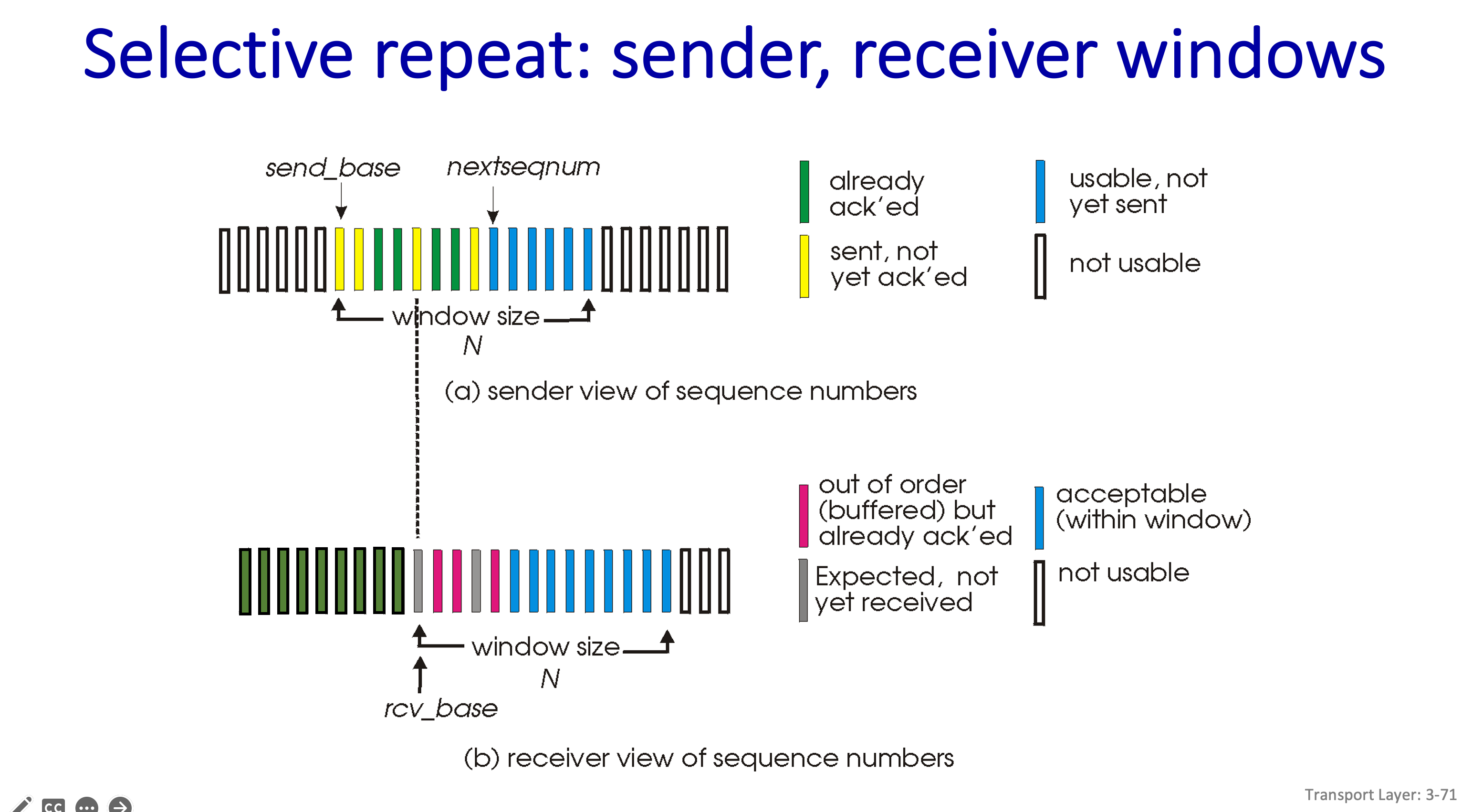
그리고 그림에서 보이는 window 는 내가 ACK 안받은 상황에서 Data 를 보낼수 있는 양이라고 한다.
send base 는 Data를 보냈는데 Ack 못받은 첫번쨰 Data 라고 하고
nextseqnum 은 data 번호 찍기위해서 필요한것이다.
노란색은 Data 보냈는데 ACK 을 못받은거다.
일단 여기서 1,2,3,4,5 Data 보내다가 3번 못받으면 다시 3번부터 재 전송한다고 했다. 그런데 4,5번 Data 는 이미 받았는데 이걸 저장할 필요가 있을까?
저장할 필요가 없다. 그냥 3번부터 보내면 된다.
Go-Back-N : receiver
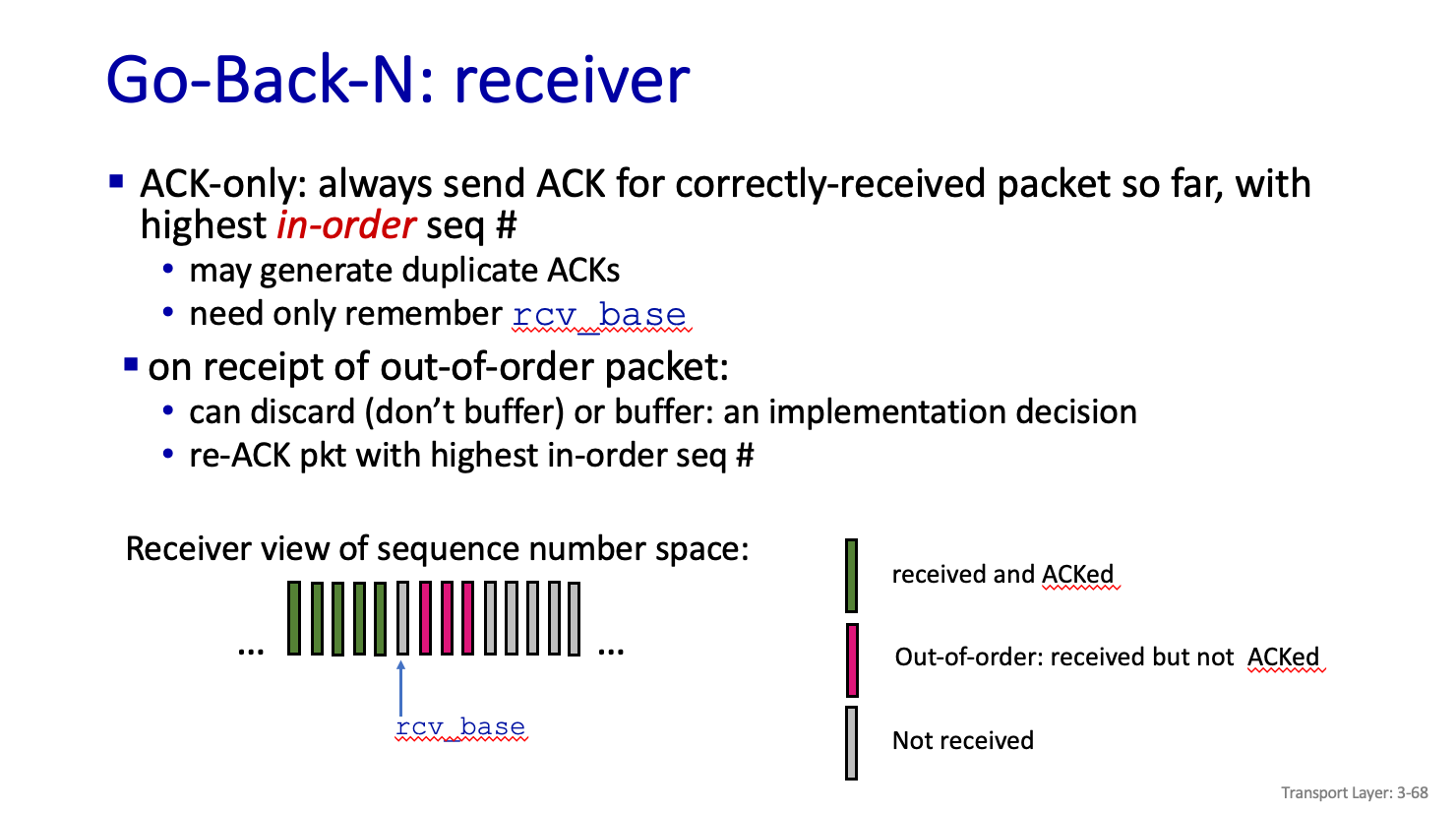
ACk(2) 번을 받으면 다시 3번부터 제전송한다.
아까 받은 4,5번을 저장할 필요가 없다.
어짜피 문제 발생부분부터 다시 보낼꺼기 때문에 위의 Data 를 저장할 필요가 없다.
순서 안맞게 오는 Data 에 빠진 Data 있으면 이후 Data는 Buffering 할 필요가 없다는 뜻이다.
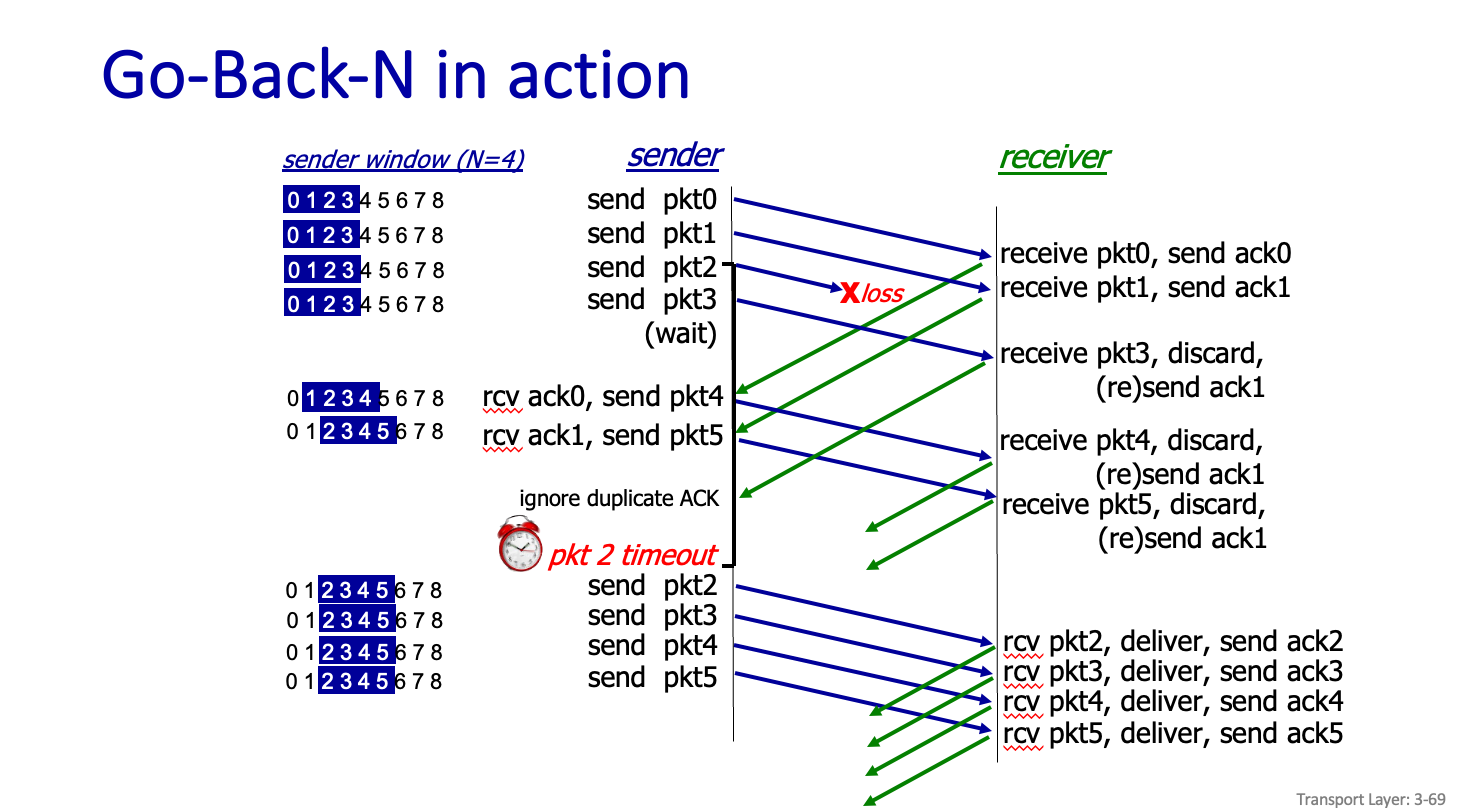
실제로 이렇게 작동이 된다.

3번만 빠지면 3번만 다시 보내고 나머지 4,5,번은 저장하는 것이다.
Buffer 로 관리가 잘 되어야한다.
individually acknowledges 라는 용어를 썼는데 뭘 받았는지만 알려준다는 뜻이다.
수신측에서는 Buffering 했기 때문에 재전송할 필요가 없다.
dilemma
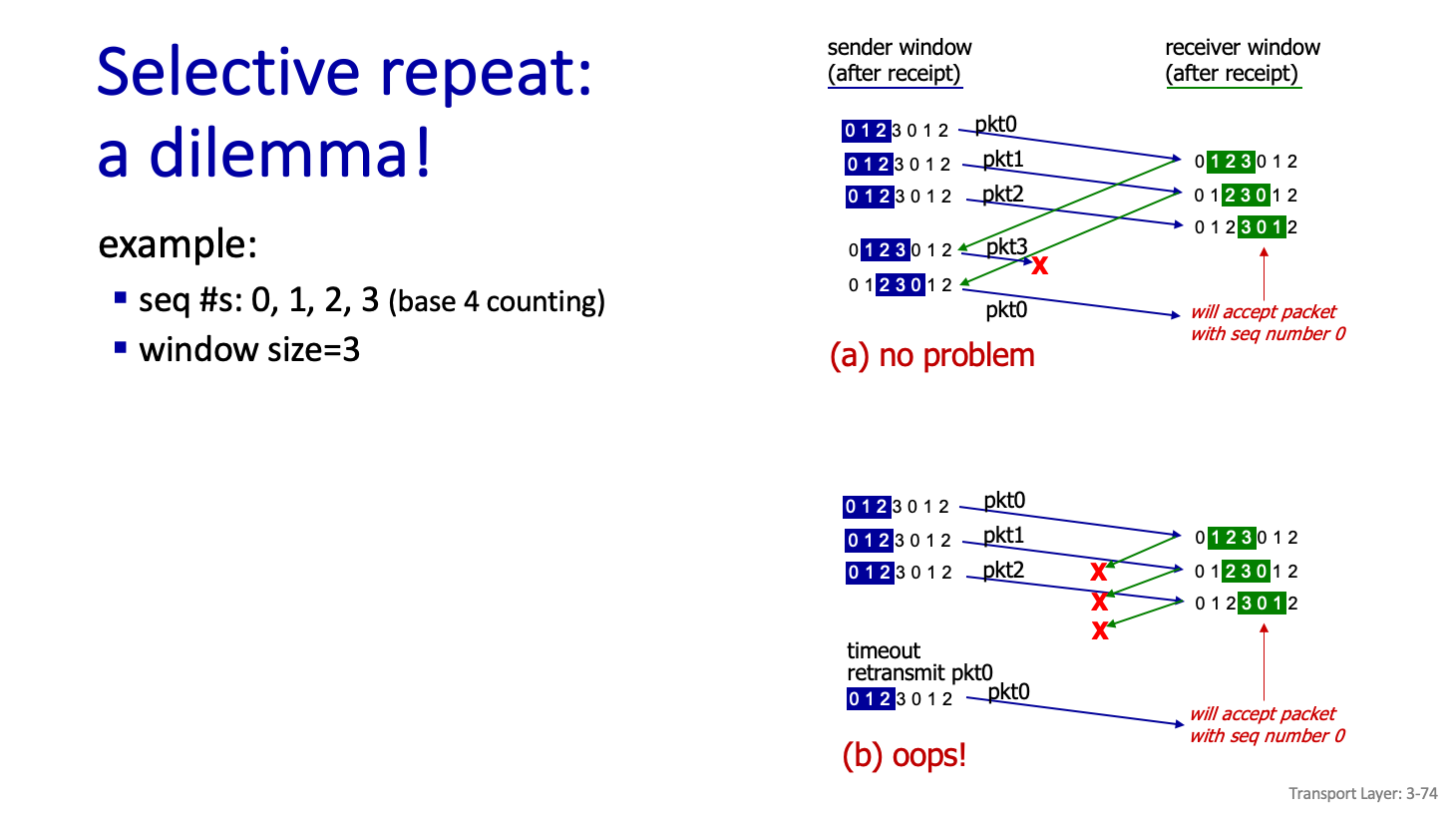

0,1,2,3,0,1,2,3,,,,, 순으로 Data 를 전송한다고 가정하자
그리고 window size=3 일때 사진과 같은 경우에 0에 대한 정보를 전송할때 이 0이라는 Data 가 새로운 Data 일수도, 재전송 Data 일수도 있다.
그렇기에 Seq # 와 Window size 를 잘 설계해야한다.
TCP: overview

TCP 는 Point to Point 라고 한다.
하나의 Sender 와 하나의 Receiver 가 있다고 한다.
그리고 reliable,in-order byte stream 이다.
사탕알맹이가 Byte 라고 생각해보자 그리고 순서 저장해서 놓았다.
2개 or 3개 먹을수도 있다는 말은 messeage boundary 가 없다는 말이다.
또한 full duplex data 는 보내고 있을때 상대방도 나한테 보낼수 있다는 말이다.
또한 Cumulative Acks 에서 한단계 더 나아서 Cumulative byte acks 라고 쓴다고 한다. 이거는 Byte 까지 잘 받았다라는 의미로 만약 ACK(1024) 이면 1023 Byte 까지는 잘 받았다 라는 의미다.
또한 Connection-oriented 는 FIN=1 을 보내서 통신을 끝내겠따라는 의미고 그에 해당하는 ACK 를 보낸다. 여기서 끝내면 안된다. 상대방이 나한테 보낼 DATA 가 있을수 있기 때문에 상대방 또한 FIN=1 을 보내고 내가 ACK 를 보내게 된다면 그렇게 통신이 마무리 된다.
TCP segment structure
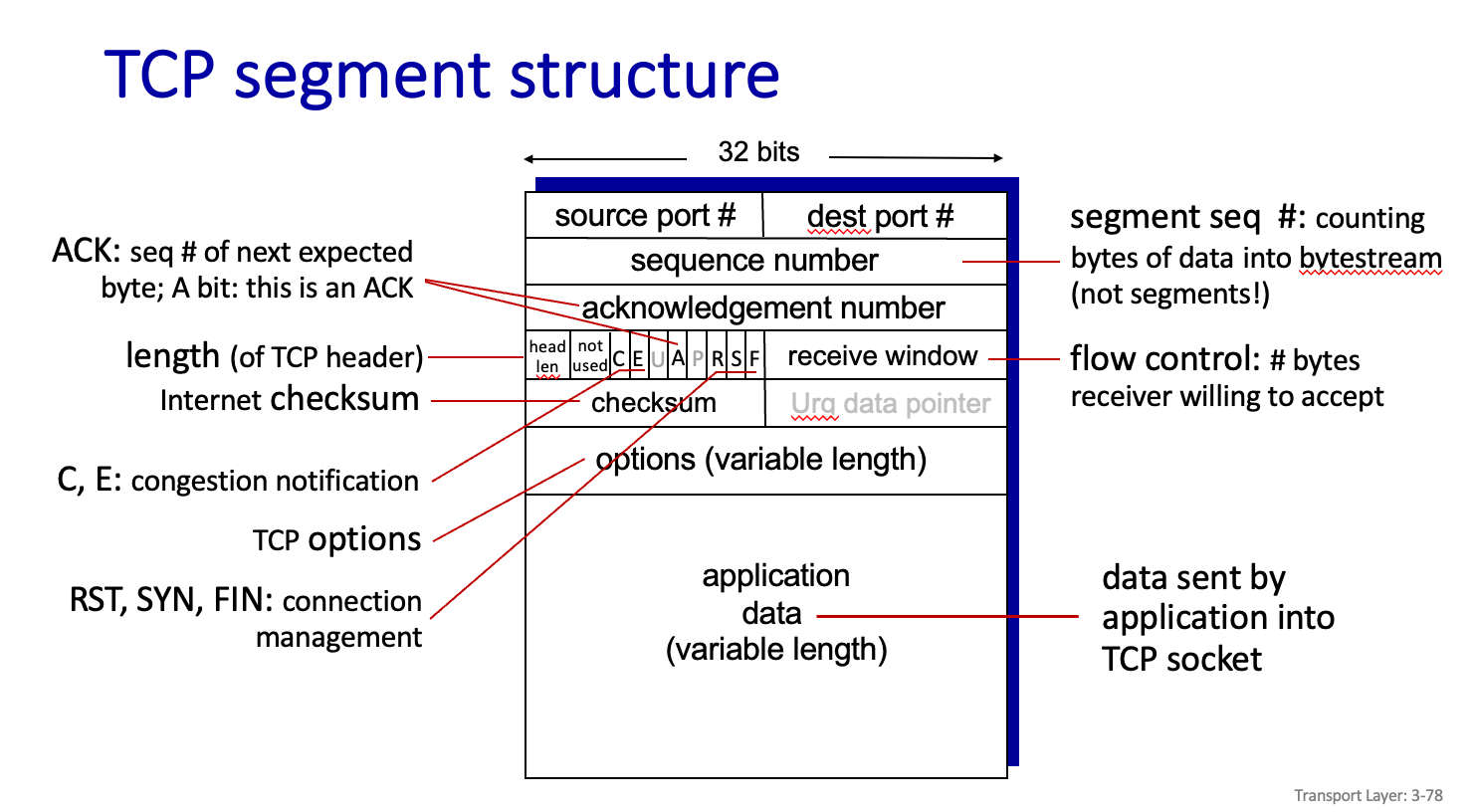
Source Port # 와 Dest Port # 는 상대방이 Mux,DEmux 하기 위해 필요하다
Sequence number 는 Data 보낼떄 번호로 보낸다는 의미이다.
Acknowledgement number 는 현재 번호 뺴기 1번쨰 까지 잘 받았다라는 의미다.
C,E 는 Congestion nofication 으로 수신측에서 Error 확인한다는 말이다.
RST,SYN,FIN 는 각각 통신을 준비하는 과정과 끝내는 과정속 필요한 것이다.
SYN=1 은 connection setup 을 한다는 뜻이고 FIN=1은 통신을 그만두겠다는 말이다 그리고 RST 는 REset 으로 통신을 새롭게 해라 라는 의미이다.
U,P 에 P는 Push 로 기존에는 적정 threshold 가 차게 된다면 Data 를 보내야 하는데 Threshold 가 차기 전에도 Push 로 보내라는 의미이다.
U는 urgent 라는 의미라고 한다.
receive window 는 window size 보다 더 받을수 있다는것을 알려준다.
option 을 보자. 지금 header 의 고정적 크기는 20byte 이다 option 은 필요에 따라 어디까지가 heder인지,,, 를 나타내준다.
TCP seqeunce numbers,ACKs
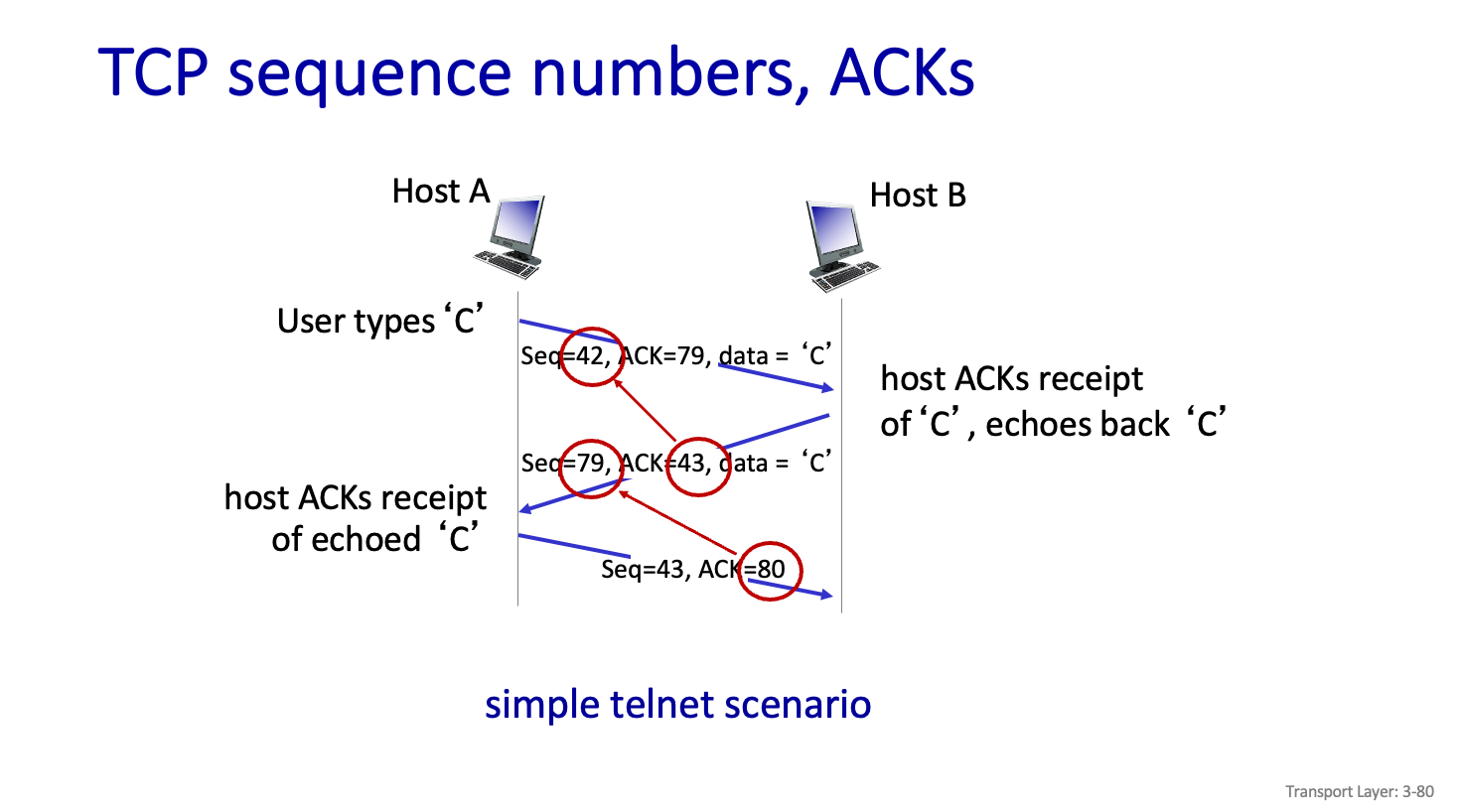
한번 보낼떄 Data 들을 Piggy mapping 해서 데이터도 보내고 ACK 도 보낸다.
TCP round trip time,timeout

Data 를 보내고 ACK 가 안오면 재전송을 한다.
이떄 재전송을 하는 시간을 어떻게 잡나?
그걸 Round trip 으로 설정하면 된다.
Round Trip 은 목적지를 왔다가 갔다 오는 시간이라고 한다.
RTT 가 너무 짧으면 불필요한 재전송이고,RTT 가 너무 길면 이런 Loss 에 대해서 너무 늦는 것이다.
그래서 이 RTT 는 어떻게 구하나?
갔다가 오는 시간이 구해질것이다. 그게 Sample Rtt 이고 Sample 들이 많아지면 이것들로 평균을 구하면 된다.
근데 1+2+3+4+5,,,+N/N 을 하는게 아니라 다른 방법이 있다.
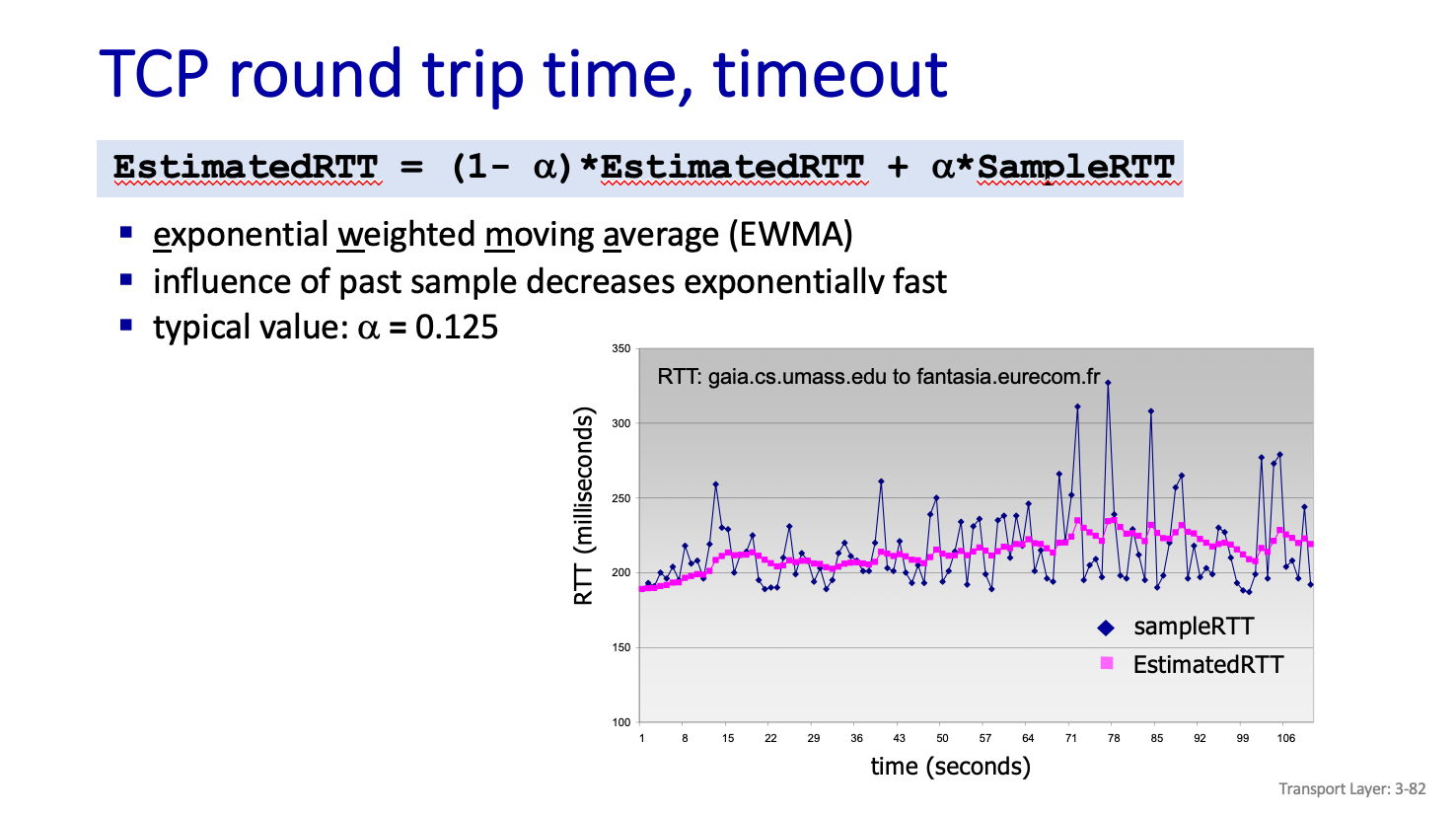
결국 Sample RTT 에 얼만큼 중요성을 들건가를 뜻한다.
이말은 과거의 값은 중요하지 않다는 말이다.
A 는 영향을 미치는 정도를 뜻한다. 0~1 사이의 값을 가지고 1-A 가 지금까지 영향을 미친 정도이다.
현재 인터넷은 A=0.125로 쓴다고 한다.
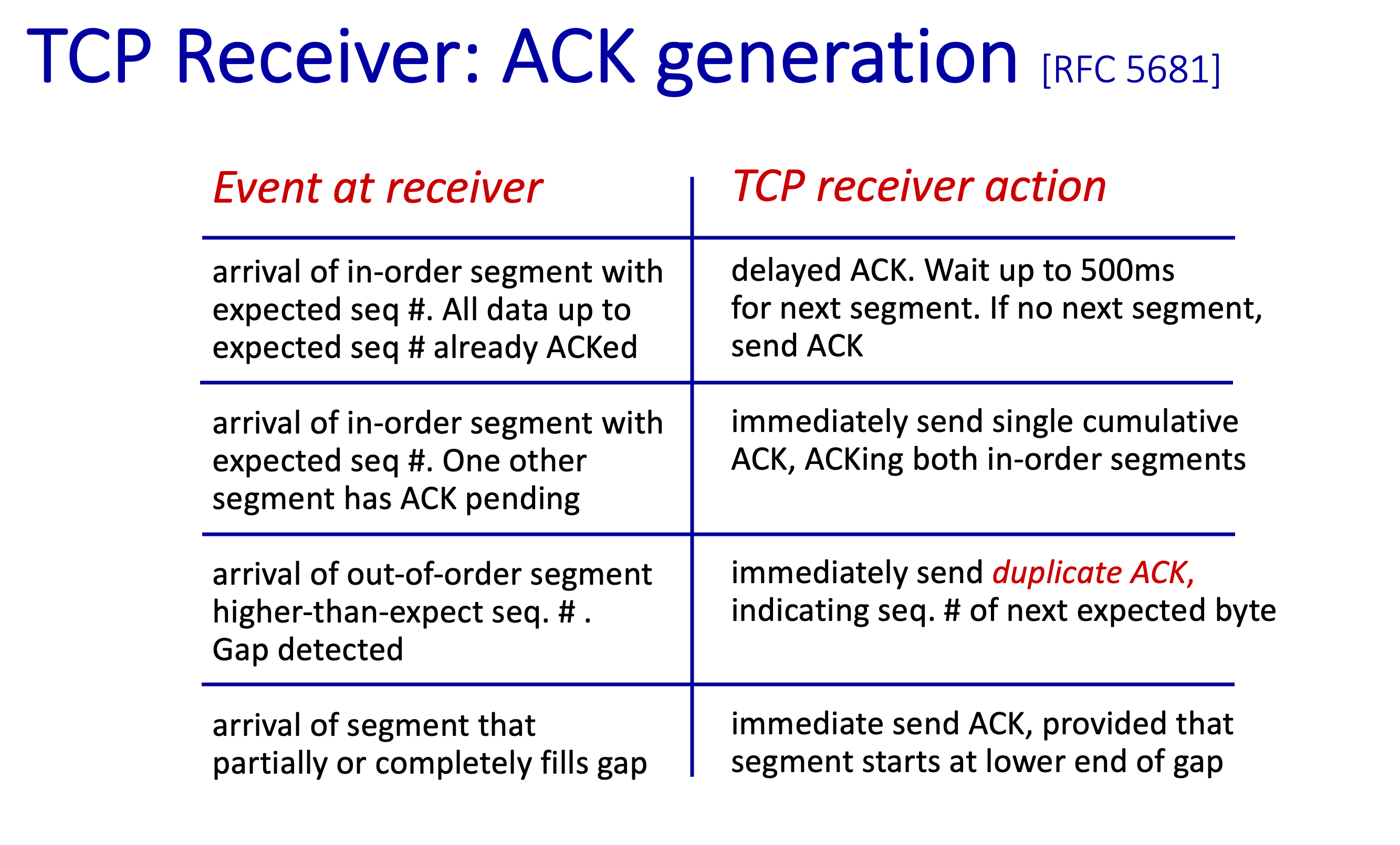
보낼떄 마다 ACK 보내면 너무 overhead 가 심한게 아닌가 해서 ACK 을 줄이자라는 의견이 나왔다.
그래서 데이터를 많이 받고 ACK 을 보내는 delayed ACK 을 쓰면된다.
TCP fast retransmit
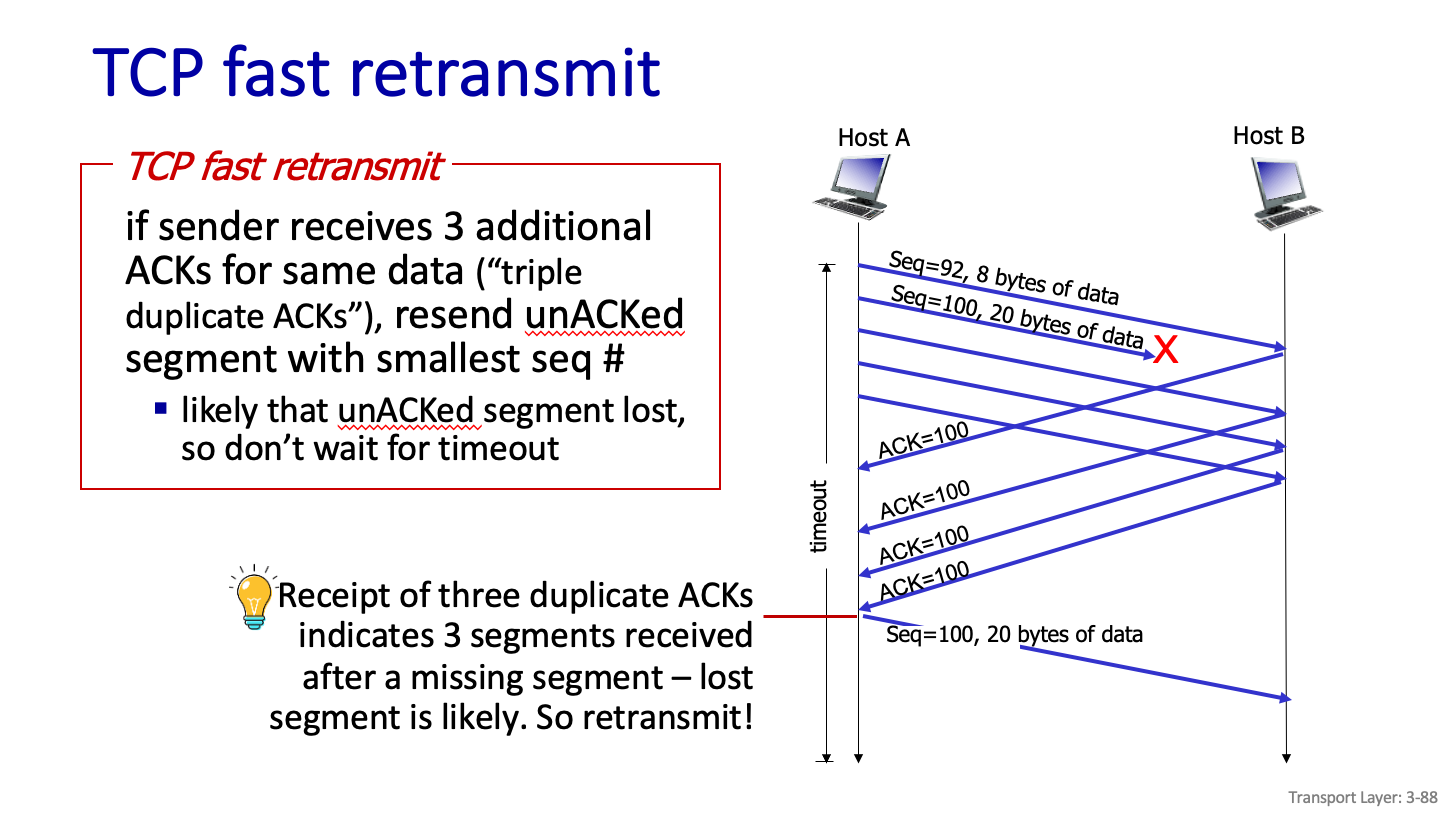
1,2,3,4,5,6,7,8을 보낼때 만약 3번에 대한 ACK 이 안왔을때 이 3번이 재전송 될떄까지 너무 오래걸린다고한다. 3번에 대한 ACK 이 계속 달라고 하니까 3번이 늦어지기 전에 재 전송을 해서 빨리 보낸다고 한다.
Principles of congestion control

Packet 을 보내면서 너무 많이 몰린다. 이걸 Congestion 이라고 한다.
Congestion 이 생기면 당연하게 손실이 생기고,Delay 는 당연하다.
Congetsion 은 어떤 행위에 대해서 너무 많이 ~해서 처리를 하지 못하는것을 뜻한다.
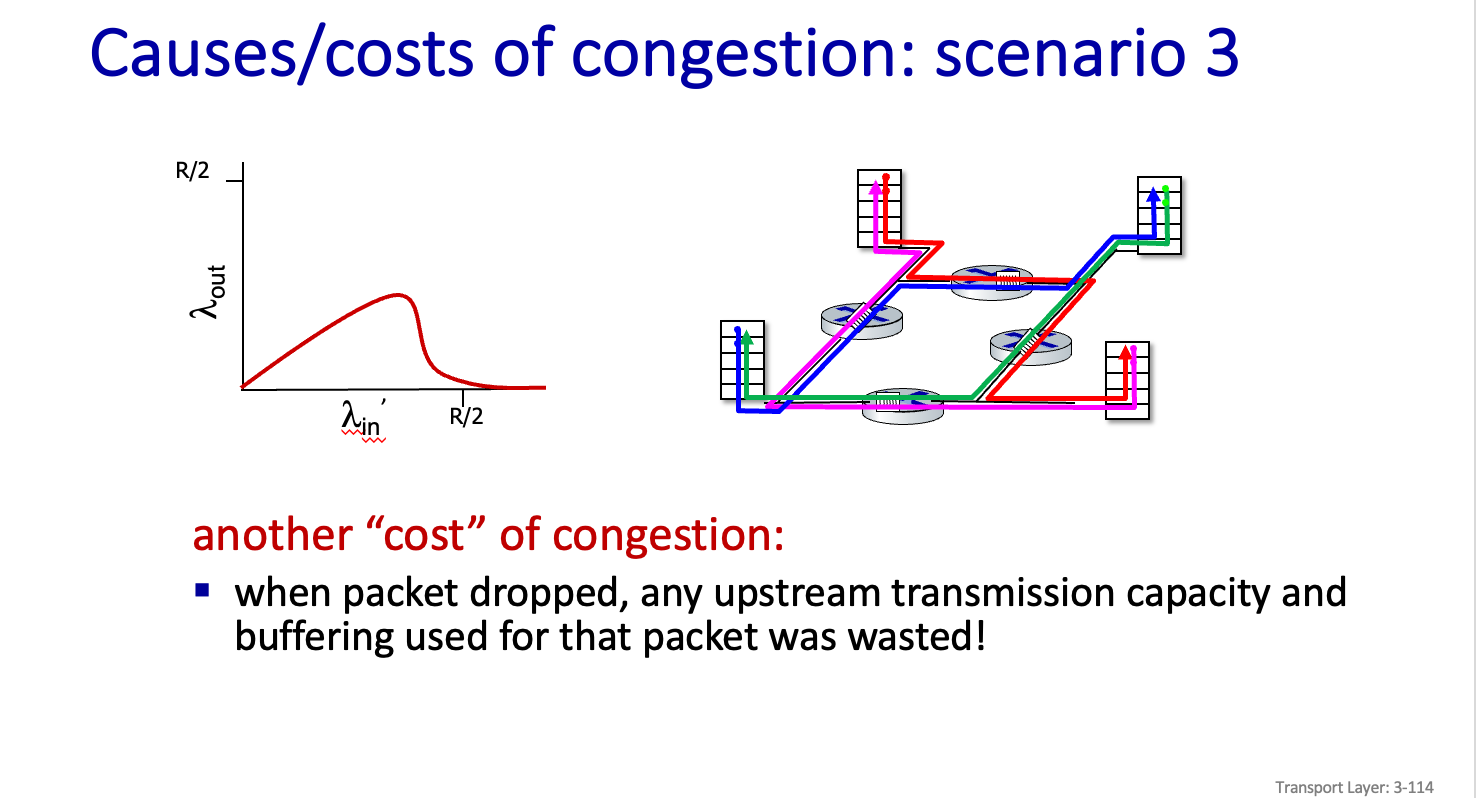
이렇게 x 축을 데이터 보내는양 y 축을 Data 도달양 이라고 하면 어느정도가 지나다 보면 Data 의 도달양이 준다. 그 부분이 Network congestion 이라고 한다.
TCP congestion control : AIMD
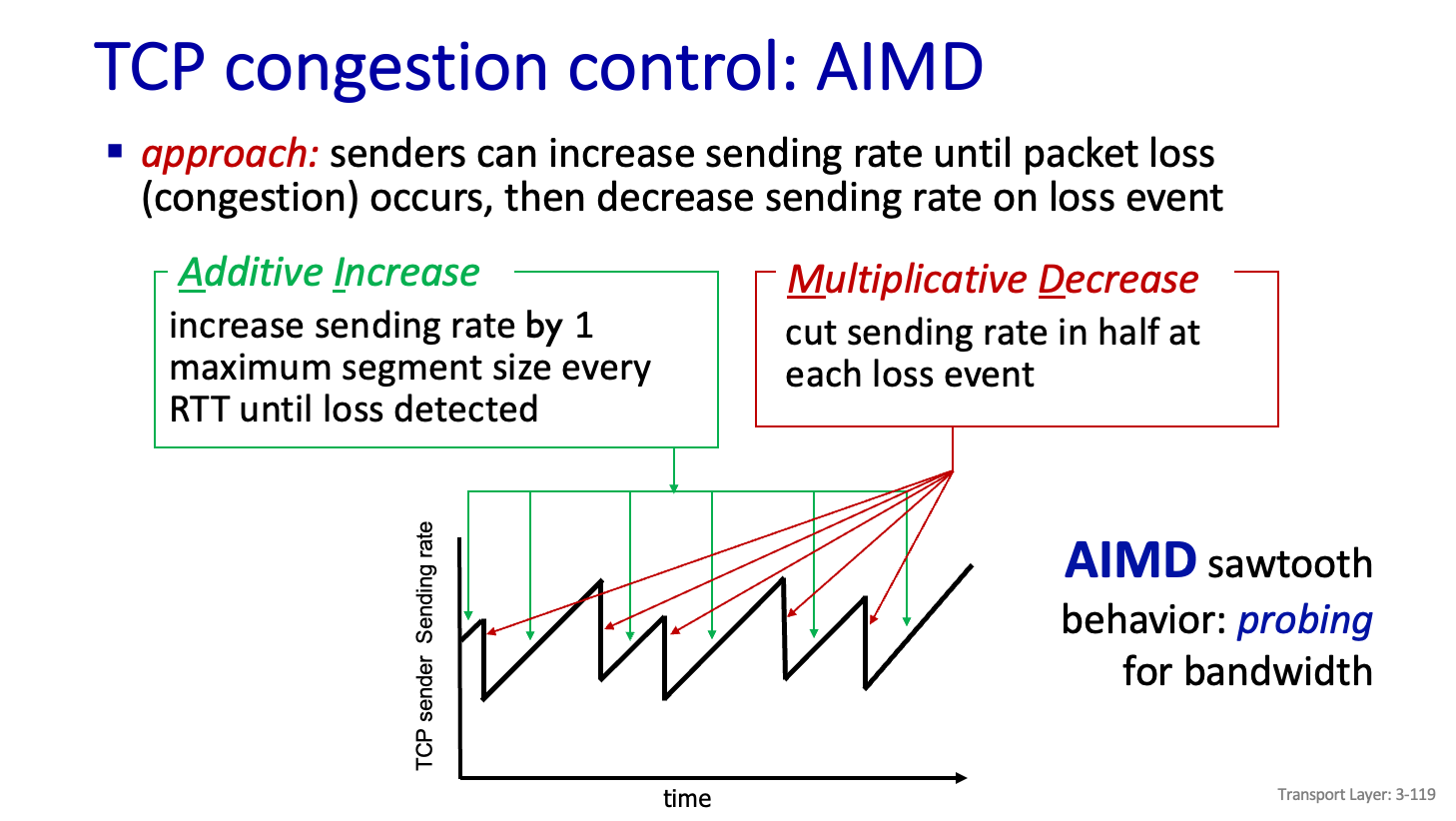
AI 는 Congestion 이 생겼던 이유는 많이 보냈기 떄문이다. TCP 는 Segment 로 보내니까 하나의 Segment 를 1로 보자. 처음에는 하나를 보내고 잘 받았다라는 Message 가 왔다. 어.. 하나 보냈을때 잘오네 그럼 다음에는 2개,, 보냄,,,다음엔 ,,4 개,,, 이렇게.
이렇게 되면 exponential 하게 값이 증가 하게 되버린다.
이렇게 보내면 너무 갑작스럽게 값이 증가하니까 threshold 값을 두어서 그 전까지는 exponential 하게 증가시키고 그 이후에는 linear 하게 증가시킨다.
그래서 threshold 전 까지의 구간을 slow start 라고 하고 그 이후는 congestion avoidance 라고 한다.
하지만 이렇게 해도 Congestion 이 생긴다.
그래서 network 가 Congestion 생겼는지 알아야한다.
2가지 방법이 있는데 하나는 누가 알려주면 된다.,(Network assisted congestion control) 이 알려준다 한다.
그리고 하나는 내가 스스로 알아내야한다.
congestion detection 을 알기위해선 Rtt 의 Pattern 을 보면 된다.
pattern 들을 보다가 어...? congestion 생기겠네,,? 하면 된다..
