📒 RNN 첫걸음
RNN에 대한 강의였다. Sequence data는 크게 어렵지 않았다.
그 이후 BPTT 부분은 설명이 부족한 느낌이 들어 많이 찾아봤는데,
기존 역전파 알고리즘과 큰 차이는 없었지만 이후가 걱정된다.
점점 내용이 많아지고 어려워지는것 같은데 몸과 정신은 피폐하다.
얼른 주말에 충전하고 복습을 열심히 해야겠다.
📝 Sequence data
- 소리, 문자열, 주가 등 각 독립된 정보가 아닌 순서를 갖는 데이터
- 순서를 바꾸거나 이전 정보의 손실이 발생하면 데이터의 확률분포도 바뀐다.
- 베이즈 법칙을 사용한 조건부확률을 이용해서 데이터를 다룰 수 있다.

- 시퀀스 데이터를 분석할 때 꼭 모든 과거 정보들이 필요한 것은 아니다.
- 가변적인 데이터를 다룰 수 있는 모델이 필요하다.

- 과거 정보들을 잠재변수로 인코딩해서 활용하는 잠재 AR 모델도 있다.
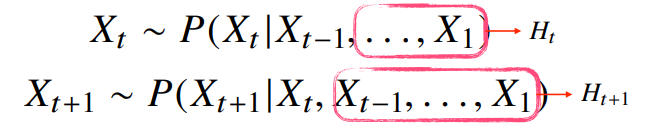
📝 Recurrent Neural Network
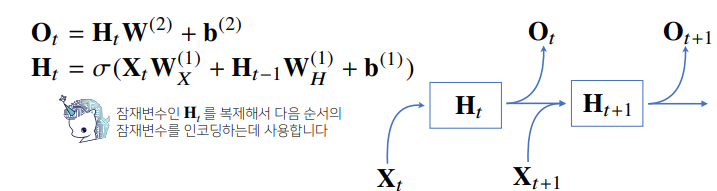
- 잠재변수를 신경망을 통해 반복 사용해 시퀀스 데이터의 패턴을 학습하는 모델이다.
- 이전 순서의 잠재변수와 현재의 입력을 활용하여 모델링한다.
✏️ BPTT
- RNN의 역전파는 t 시점에 잠재변수와 출력값을 이용해서 입력과 이전 잠재변수를 구한다.
- 모든 T 시점에 대해 예측하면, gradient 계산이 불안정해질 확률이 높다. (vanishing)
👉 긴 sequence에 대해서는 몇 개의 정보는 끊어내고 블록을 나누는 작업이 필요하다.
📒 Sequential Models
LSTM이 이런 플로우로 설계됐구나 정도는 알겠다.
하지만, 그 원리가 어떻게 되는지 설명이 적어서 이해가 너~무 어렵다.
하나의 강의를 듣는데 너무 많은 시간이 걸리는 것 같다.
다음주에 공부할 키워드들이 점점 늘어간다.
📝 Sequential Model
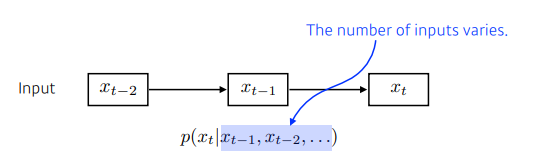
- Naive sequence model은 과거의 정보량이 점점 늘어난다.
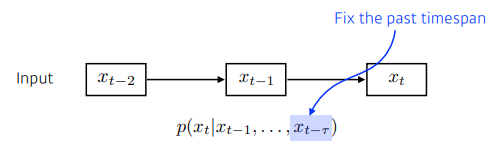
- Autoregressive model은 timespan을 두고, 몇 개의 과거만 확인한다.
- Markov model은 바로 이전의 정보만 이용한다. (generative model에서 사용)
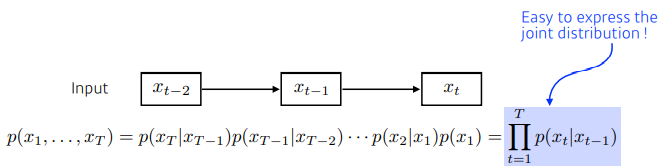
- Latent autoregressive model 과거 정보를 종합한 hidden state를 놓는다.

📝 Recurrent Neural Network
- 순서도 데이터의 일부가 되는 sequential data를 위해 만들어졌다.
- 이전 입력 값의 처리를 반영하여 모델이 데이터의 순서를 이해한다.
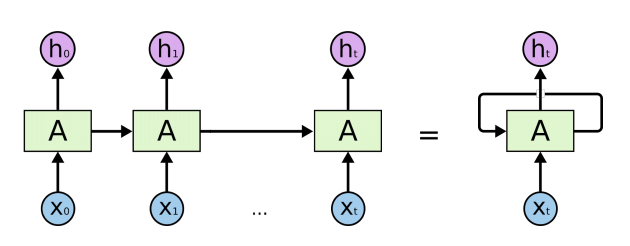
- 내부 구조는 다음과 같다.
- 긴 sequence가 들어와도 이를 처리할 A의 parameter만 알면 된다.
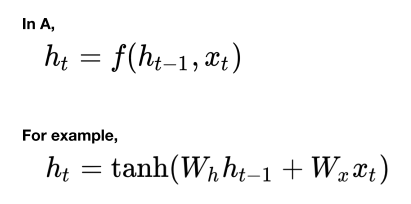
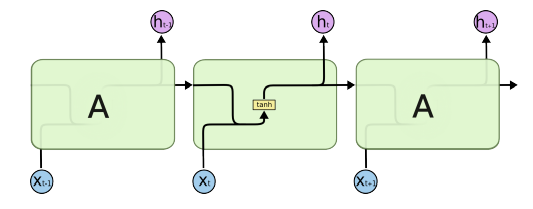
- step이 작은 과거는 적용이 잘 되는데, step이 커지면 가져오기가 힘들다.
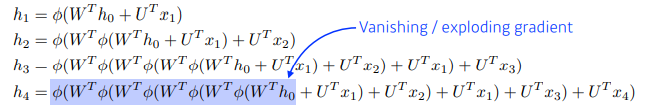
📝 Long Short Term Memory
- 더 멀리 있는 과거의 정보도 잘 활용하기 위해 만들어졌다.

- 하나의 hidden layer는 다음과 같이 구성된다. (3개의 input, 3개의 output)
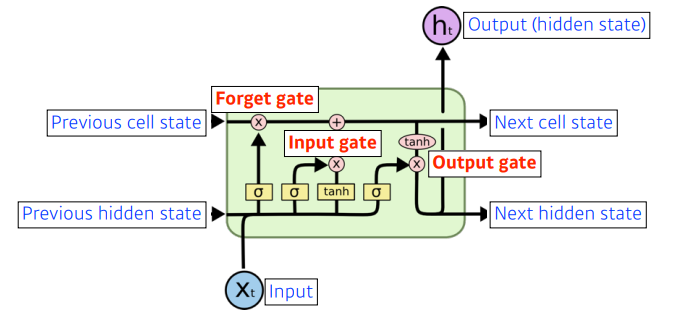
✏️ Cell State
- time step T까지 들어온 정보를 요약하는 일을 한다.
- 컨베이너 벨트처럼 정보를 잘 조작해서 올리는 공간이다.
- gate를 통해 어떤 정보가 유용하고, 유용하지 않은지 판단해서 올린다.
✏️ Forget Gate
- 어떤 정보를 버릴지를 결정하기 위한 gate이다.
- 현재의 입력과 이전의 output을 입력받아 ft를 만들어 버릴 정보를 정한다.

✏️ Input Gate
- 현재의 정보 중 cell state에 어떤 정보를 올릴지 결정한다.
- 다른 Neural Network를 통해 정규화된 Ct를 만들어 update cell으로 올린다.

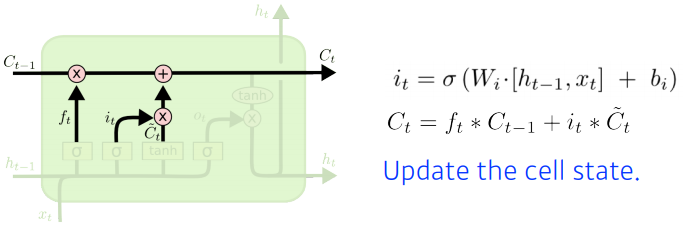
✏️ Update Cell
- 버릴 건 버리고, 어느 값을 올릴지 정한뒤 합쳐서 cell state에 update한다.
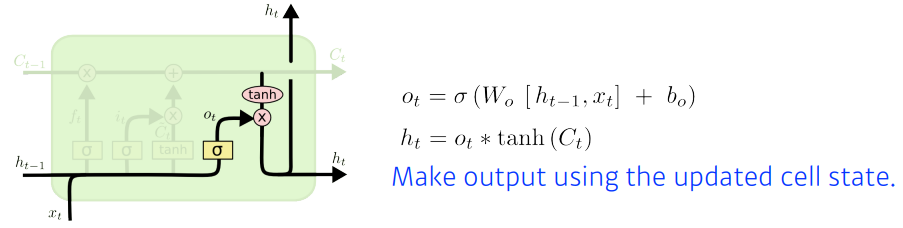
✏️ Output Gate
- 어떤 값을 밖으로 보낼지를 정한다.
📝 Gated Recurrent Unit
- reset gate, update gate 두개를 갖는다.
- cell state가 없고, hidden state 하나만을 갖는다.

📒 Transformer
어렵다고 경고문까지 적어놓은 강의였는데 정확한 팩트였다.
트랜스포머는 처음 듣는 개념이었는데, 역시나 flow만 이해했다.
여기에 query, key, value 값이 어떻게 만들어진건지 궁금하다.
강의의 마지막 부분은 하나도 머리에 들어오지 않았다.
깨끗한 정신상태로 다시 들어보도록 해야겠다.
📝 Transformer?
- RNN은 중간에 경로가 빠지거나, 순서가 바뀐 데이터들이 있으면 모델링하기가 어렵다.
- 트랜스포머는 재귀적인 구조 없이 attention 구조를 활용해 시퀀스를 다룬다.
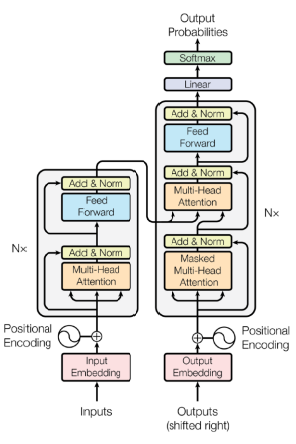
- 입력과 출력의 시퀀스는 다를 수 있고, 모델은 하나이다.
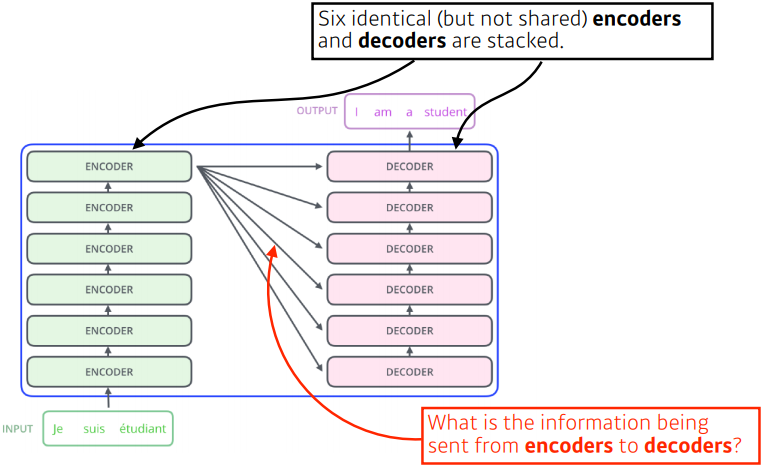
📝 In Transformer
- 인코더의 Self-Attention이 트랜스포머의 핵심이다.
- Feed Forward Neural Network는 MLP와 동일하다.
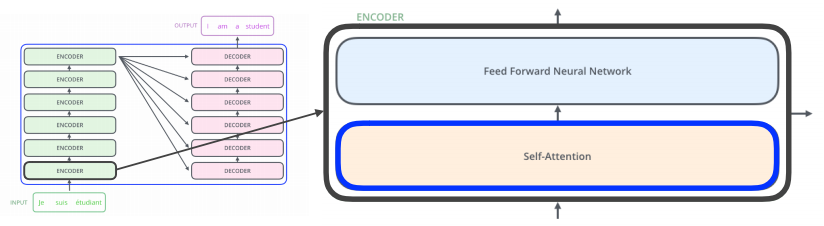
✏️ Self-Attention
- N개의 단어가 들어오면 각 벡터마다 N개의 벡터로 찾아주는 역할을한다.
- 벡터에서 벡터로 갈 때 다른 N - 1개의 벡터도 같이 고려한다.
👉 각 단어의 다른 단어들과의 관계성을 확인한다.

✏️ Interaction
- 하나의 단어 벡터마다 Queries, Keys, Values 3개의 벡터로 나눈다.
- 각 벡터의 Query 벡터와 모든 N개의 단어의 Key 벡터를 내적해 Score를 구한다.
- Score 벡터에 Key 벡터의 차원의 sqrt로 나눠주고, Softmax를 취해준다.
- 각 value 벡터와 곱해주고 다 더해주면 encoding 벡터가 나온다.
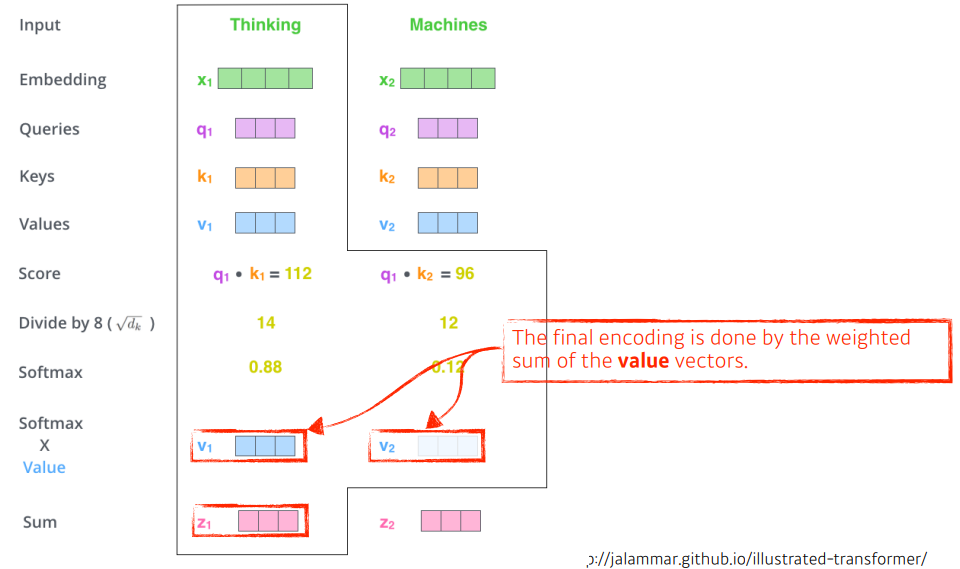
- query와 key를 여러개 만들면 Multi-headed attention(MHA) 이다.
👉 여러개의 인코딩된 벡터가 나오기에 출력 차원과 맞춰줘야 됨.
📝 Positional Encoding
공부하고 추가예정
http://jalammar.github.io/illustrated-transformer/

Beginner