📒 Image Classification
Computer Vision을 배우기에 앞서 옛날에 배운 CNN을 복습했다.
개강까지 하니 점점 월요일이 너무 힘들다.
주말에 좀 더 쉬었어야 됐는데 그러지 못한게 후회된다.
마지막에 CNN Architecture에 대한 역사는 중복이라 생략했다.
📝 Computer Vision
실제 장면을 찍은 영상을 알고리즘을 통해 GPU에 대해 연산을 해서 장면에 대한 분석을 사람이 해석이 가능한 형태로 출력해준다.
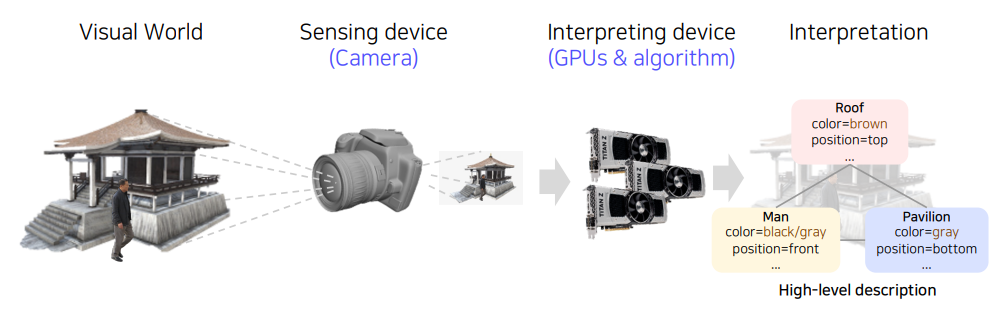
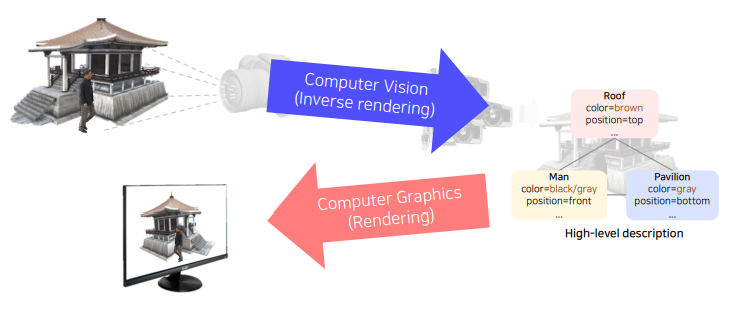
결국 Computer Vision은 Computer Graphics가 하는 일을 반대로 한다.
ML에서는 전문가가 특징 추출법을 설계했으나, 딥러닝에서는 처음부터 끝까지 End to End로 편리하고 성능 좋은 분류를 해결해주었다.

📝 Image Classification
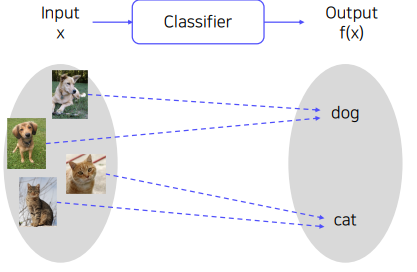
Classfier는 영상을 입력으로 받아 어떤 물체가 영상 속에 있는지 분류해서 출력하는 역할을 한다.
Single Fully Coneected Layer에서는 모든 가중치를 내적하고 Activation Function을 통과하여 분류를 진행한다.
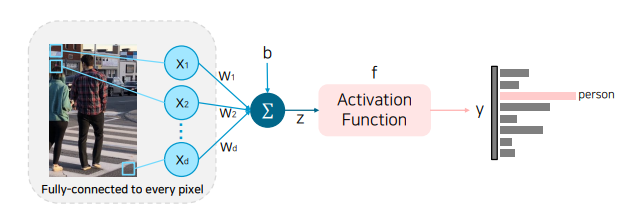
하지만 위 모델은 Layer가 한 층이라 단순해서 평균 이미지 외에는 표현이 안된다. 그리고 Test Time에서는 템플릿에 맞지 않는 데이터가 들어오면 다른 결과가 나올 수도 있다.
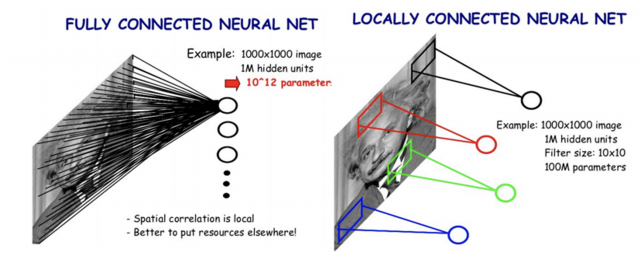
그래서 나온 Locally Connected Neural Network에서는 모든 픽셀을 고려하는 FC Layer와는 다르게 하나의 특징을 영상의 특성을 고려해서 국부적인 영역들만 Connection을 고려했다. 따라서 weight가 획기적으로 줄어들었다.
📒 Annotation data efficient learning
실무에 도움이 많이 될 것 같은 내용들로 가득했다.
당장에 프로젝트를 진행할 때 도움이 될 수도 있을 것 같다.
📝 Data augmentation
우리가 실제 취득할 수 있는 데이터는 실제 데이터의 일부일뿐이다. 그래서 데이터 몇개가 주어졌을 때 그 데이터를 더 풍부하게 표현하기 위해서 다양한 방법을 사용하고 있다.
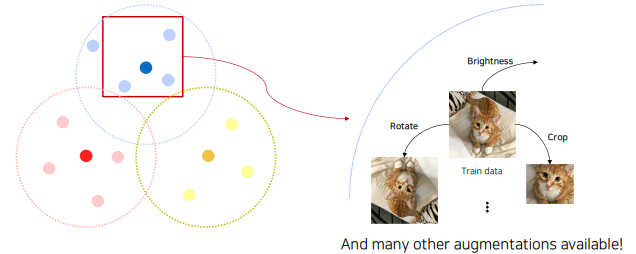
# numpy를 이용한 밝기 변경
def brightness_augmentation(img):
img[:,:,0] = min(img[:,:,0] + 100, 255)
img[:,:,1] = min(img[:,:,1] + 100, 255)
img[:,:,2] = min(img[:,:,2] + 100, 255)
return img
# OpenCV를 이용한 rotate, flip 변경
img_roatated = cv2.rotate(image, cv2.ROITATE_90_CLOCKWISE)
img_flipped = cv2.rotate(image, cv2.ROTATE_180)
# numpy를 이용한 Crop
y_start = 500
crop_y_size = 400
x_start = 300
crop_x_size = 800
img_cropped = image[t_start : y_start + crop_y_size, x_start : x_start + crop_x_size, :]
# OpenCV를 이용한 Affine Transformation
rows, cols, ch = image.shape
pts1 = np.float32([[50,50], [200,50], [50,200]])
pts2 = np.float32([[10,100], [200,50], [100,250]])
M = cv2.getAffineTransform(pts1, pts2)
shear_img = cv2.warpAffine(image, M, (cols,rows))RandeAugment를 사용하면 더 효율적으로 Augmentation을 사용할 수 있다.
📝 Leveraging pre-trained information
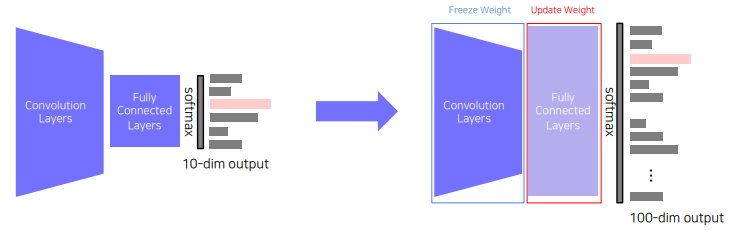
Transfer learning은 기존 학습시켜놓은 사전 지식을 활용해서 연관된 새로운 task에 적은 노력으로도 높은 성능에 도달할 수 있다.
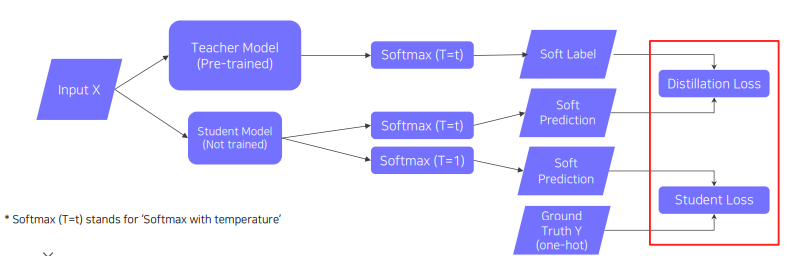
Knowledge distillation은 이미 학습된 Teacher Network의 지식을 더 작은 모델인 Student Model에 전달하기 위해서 쓰인다. model 압축에 유용하게 쓰인다. 최근에는 Teacher의 출력을 가짜 label로 자동 생성하는 메커니즘으로 사용하는데, 이를 더 큰 Student model에서도 Generating이 가능하다.