CS50 2019 강의를 듣고 내용을 정리한 시리즈 글입니다.
학습목표
트라이의 원리와 구조를 설명할 수 있습니다.
핵심 단어
- 트라이
강의 내용
1. 트라이
트라이는 기본적으로 트리 형태의 자료 구조이다.
특이점은 각 노드가 배열로 이루어져 있다는 점이다.
알파벳으로 이루어진 문자열을 저장한다면 노드는 a부터 z까지의 값을 가지는 배열이 된다.
그리고 배열의 각 요소, 즉 알파벳은 다음 층의 노드(a-z 배열)를 가리키게 된다.
예를 들어 Hermione, Harry, Hagrid 세 문자열을 트라이에 저장한다면 아래의 사진과 같은 형태가 된다.
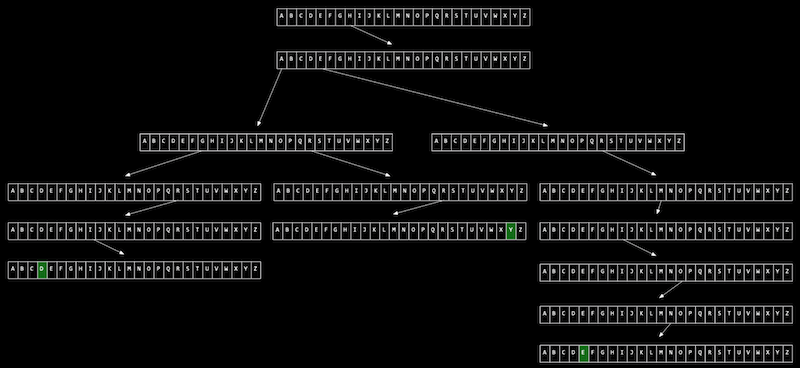
이처럼 트라이의 형태에서 값을 검색하는데 걸리는 시간은 트리의 높이 즉, 문자열의 길이에 해당한다.
따라서 검색시간은 문자열이 일반적인 상수 값일 때 O(1)이라고 볼 수 있다.
이번엔 예시 문제를 통해 python으로 트라이를 구현해보자.
(문제: https://leetcode.com/problems/implement-trie-prefix-tree/)
class Trie:
def __init__(self):
self.trie = {}
def insert(self, word: str) -> None:
tree = self.trie
for char in word:
if char not in tree:
tree[char] = {}
tree = tree[char]
tree['*'] = True
def search(self, word: str) -> bool:
tree = self.trie
for char in word:
if char not in tree:
return False
tree = tree[char]
return '*' in tree
def startsWith(self, prefix: str) -> bool:
tree = self.trie
for char in prefix:
if char not in tree:
return False
tree = tree[char]
return Trueapple이라는 문자열을 insert, search한다면 코드는 아래의 순서로 진행 된다
word = "apple"
obj = Trie()
obj.insert(word) # {'a': {'p': {'p': {'l': {'e': {'*': True}}}}}}
obj.search(word)
'''
char, tree를 반복문 내에서 print 하면
a
{'a': {'p': {'p': {'l': {'e': {'*': True}}}}}}
p
{'p': {'p': {'l': {'e': {'*': True}}}}}
p
{'p': {'l': {'e': {'*': True}}}}
l
{'l': {'e': {'*': True}}}
e
{'e': {'*': True}}
'''
print(obj.search(word)) # True생각해보기
트라이가 해시 테이블에 비해 가지는 장점과 단점은 무엇일까요?
해시 테이블은 조건에 따라 시간 복잡도가 O(n)까지 늘어날 수 있지만 트라이는 O(m)* m=문자열의 길이을 보장한다.
단점으로는 각 문자마다 메모리를 할당해야 하기에 더 많은 메모리 크기가 요구된다는 점이다.
