채용 정보를 저장하는 테이블을 대상으로 150개의 검색 쿼리를 날릴 때에도 여러 방법이 있다.
- 그냥 했을때
- 인덱스를 걸어서 날렸을 때
- 배치로 날렸을 때
- in절로 걸어서 날렸을 때
테이블의 크기가 크지 않기 때문에 큰 차이는 없을 것이지만 그래도 배치를 적용하였을 때 네트워크를 타는 횟수가 차이가 있기 때문에 이번 기회에 기록으로 남기려고 한다
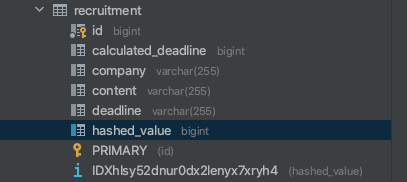
테이블의 구조는 다음 사진을 통해 파악할 수 있는데, 여기서 hashed_value는 문자열의 hashCode를 가공해서 만든 것으로, 동일한 공고에 대해서는 같은 해시값이 나오도록 설계되어있다.
시간 측정을 위해서 @Aspect에 around를 걸어서 메서드 실행시간을 체크
실제로는 로그백을 쓰는것이 좋고 aspect 범위도 조금 더 신경써서 걸 필요가 있다.
System을 직접적으로 부르면 혼나기 딱 좋다
@Aspect
public class TimeTraceAop {
Logger logger = Logger.getGlobal();
@Around("execution(* com.gummybearr.jai.domain..*(..))")
public Object execute(ProceedingJoinPoint joinPoint) throws Throwable {
long start = System.currentTimeMillis();
logger.log(Level.INFO, "Start: " + String.valueOf(joinPoint));
try {
return joinPoint.proceed();
} finally {
long finish = System.currentTimeMillis();
long timeMs = finish - start;
logger.log(Level.INFO, "End: " + joinPoint.toString() + " " + timeMs + "ms");
}
}
}측정을 위해서 좋은 방법은 아니지만 편의를 위해 단순하게 쿼리를 날려본다. in절을 활용하지 않는 케이스를 제외하고는 형태가 다음과 같다. in절을 활용하는 케이스에서만 hashValue를 추출해서 쿼리를 날린다.
@GetMapping(path = "admin/query-date")
public void queryData() throws IOException {
for(Recruitment recruitment:recruitments.recruitments()){
System.out.println(recruitmentRepository.findByHashedValue(recruitment.hashedValue()));
}
}측정은 3번으로 했으며 순서대로 시간을 기술한다.
첫번째 측정으로는 캐시를 타지 않았을 때, 두번째와 세번째 측정으로는 캐시를 어느정도 탔을 때의 속도를 측정하기 위함이다.
Naive하게 그냥 쿼리했을 때: 347ms 204ms 185ms
hashedValue에 인덱스를 걸었을 때: 320ms 188ms 190ms
batchSize를 1000으로 걸었을 때: 306ms 195ms 176ms
query를 in으로 걸어서 썼을 때: 90ms 11ms 9ms
in으로 묶어서 날리는 것이 애초에 쿼리가 1개밖에 날라가지 않기 때문에 가장 빠르다. 지금의 프로젝트에서는 in절을 사용하는 것이 가장 효과적이지만, 케이스에 따라서 index나 batchSize와 쿼리를 연동하는 것이 더 효율적일 수도 있다. 방법을 모두 알아두는 것이 좋다
